Apache Flink и потоковая обработка данных для решения задач IoT
К 2021 году прогнозируется, что около 16 млрд из приблизительно 28 млрд подключенных устройств по всему миру, будут так или иначе связаны в рамках концепции интернета вещей. Интернет уходит в вещность, и надо как-то справляться с растущим потоком данных.
Разрабатывая облачные системы управления ресурсами в компании Миландр, мы, как никто другой, замечаем рост IoT сетей. Ниже схематически представлена архитектура разработанной нами платформы «Инфосфера», по которой можно оценить спектр решаемых ею задач.
 Архитектура платформы «Инфосфера»
Архитектура платформы «Инфосфера»
Требования пользователей в сочетании с объемом, скоростью и разнообразием данных, производимых сетями IoT, не оставляют времени на использование традиционных баз данных и конвейеров ETL, в значительной степени основанных на пакетных операциях. Сегодня необходимость быстрого принятия решений особенно важна, поэтому мы решили обратить внимание на потоковую обработку данных, способную обрабатывать непрерывно производимые данные в массовом масштабе и позволяющую пользователям реагировать на данные, как только они сгенерированы.
Потоковая аналитика или аналитика в реальном времени предполагает использование специальных технологий. В сети неплохой выбор инструментов распределенной обработки потоков Big Data. Это: Kafka Streams, Spark Streaming, Flink, Storm и Samza и т.д. Для решения задач IoT, самым комфортным нам показался Apache Flink. Он бесплатный, вышел из академический среды (TU Berlin). И для выбора именно Flink у нас нашлось пять причин.
 Пять причин использовать Apache Flink от Игоря Николаева
Пять причин использовать Apache Flink от Игоря Николаева
Низкое время задержки. Flink обеспечивает высокую производительность и низкую задержку без какой-либо сложной конфигурации. Его конвейерная архитектура обеспечивает высокую пропускную способность, в т.ч. за счет собственной подсистемы управления памятью и ее эффективного использования. Он обрабатывает данные с молниеносной скоростью, его также называют 4G Big Data.
Высокая производительность и надежность. Приложения Flink могут распараллеливаться в тысячи задач, которые распределяются и выполняются в кластере, одновременно используя практически неограниченное количество процессоров, основной памяти, дискового и сетевого ввода-вывода. Кроме того, Flink легко поддерживает очень большое состояние приложения. Его асинхронный и инкрементный контрольный алгоритм обеспечивает минимальное влияние на задержки обработки, гарантируя точную согласованность состояния за один раз. Flink гарантирует согласованность состояния приложений в случае сбоев, периодически и асинхронно проверяя локальное состояние на необходимость перемещения в долговечное хранилище.
Легкая масштабируемость. Flink скалируется в автоматическом режиме с возможностью ручных настроек. А его распределенная природа позволяет масштабироваться кластерами.
Концепция работы с данными. Данные в IoT сетях не отличаются высоким качеством, обычно приходят с опозданием, не по порядку, а то и пачками. Flink позволяет работать с фактическим временем происхождения события (Event Time), а не с временем прибытия сообщения, исключая влияние задержки на точность вычислений. Полезным механизмом для работы с неупорядоченными данными является управление окнами Stream Windows — концепция, которую можно рассматривать как группировку элементов бесконечного потока данных в конечные наборы для дальнейшей (и более простой) обработки на основе таких измерений, как время события. Фреймворк позволяет пользователям хранить данные прямо там, где выполняются вычисления, управляя ими как локальным состоянием, и сам заботится об отказоустойчивости. Также следует отметить, что Flink гарантирует строго однократную доставку сообщения. Отказоустойчивость и строго однократная доставка обеспечиваются использованием алгоритма называемого авторами Asynchronous Barrier Snapshotting.
Простая интеграция. Flink интегрируется с широким спектром систем развертывания, ввода и вывода данных. Есть мануалы по интеграции с большинством популярных технологий: Docker, Zookeeper, Kubernetes, Redis, Kafka, Postgres и т.д. Flink имеет свой web-интерфейс. Сам проект поставляется в комплекте со слоем совместимости Hadoop MapReduce, слоем совместимости Storm, а также библиотеками для машинного обучения и работы с графами.
Сфера применения широчайшая. Постоянно обрабатывая поток, можно почти в runtime менять состояние системы, реагировать на сбои и подозрительные активности, а также добавлять в поток команды по управлению устройствами в сети IoT.
Для апробации мы использовали Apache Flink для решение одной из задач в сфере Industrial IoT. Если коротко, мы предложили заказчику сервис, позволяющий настраивать обработку показаний с их устройств в формате конвейера. На каждое устройство свой конвейер.
Интерфейс редактирования конвейера обработки
Для настройки конвейеров обработки было решено написать отдельный web-сервис. Интерфейс можно увидеть выше. Для визуализации конвейеров обработки мы использовали библиотеку Drawflow, позволяющую рисовать графы. В конвейер обработки можно добавлять источники для потока (брокеры сообщений), различные блоки для фильтрации, блоки для логических и математических преобразований, а результат записывать в исходный поток данных. Сервис представляет из себя CRUD конвейеров обработки и умеет запускать и останавливать Job«ы Flinkа по REST API.
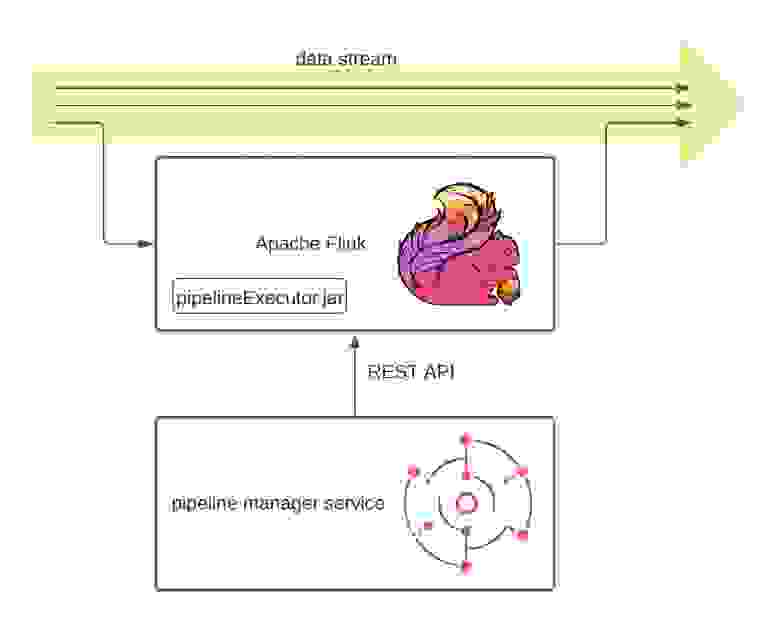 Схема взаимодействия Apache Flink с сервисом конвейеров обработк
Схема взаимодействия Apache Flink с сервисом конвейеров обработк
Конвейеры обработки хранятся в формате JSON и передаются во Flink вместе с командой на запуск. Flink же использует их как аргументы при выполнении Jobы. Мы, в свою очередь, подготовили Java executor для Flink, способный распарсить конвейер обработки в Flink DataStream, для обработки потока данных в соответствии с логикой описанной в конвейере. Ниже представлен java-код обработчика блока «Счётчик». Данный блок добавляет в поток данных новое сообщение счетчика, который инкрементируется при появлении в потоке сообщения с заданным типом и значением.
 Листинг кода обработчика блока «Счетчик»
Листинг кода обработчика блока «Счетчик»
Так мы дали пользователям возможность создавать свои сценарии обработки данных для своих же умных устройств. При этом оптимизацией обработки растущего количества сценариев, сохранением стабильного состояния и масштабированием под растущие нагрузки занимается Flink. Время обработки одного показания по конвейеру порядка миллисекунды. Такая скорость позволяет моментально реагировать на изменение состояния системы.
Немного отвлекшись от сосредоточенного поиска и обработки больших данных, мы сместили свой фокус на сторону максимально эффективного использования данных, находящихся в движении именно сейчас, выполняя необходимые вычисления заранее, с сокращением операций ввода / вывода.
Apache Flink легко встраивается в распределенную, микросервисную архитектуру. И нет сомнений, что мы продолжим разрабатывать наши решения, применяя Flink. Этот фреймворк обладает широкими возможностями, востребованными в IoT сетях как для анализа, так и для обработки потока данных. Не говоря уже о возможности направлять в поток команды для управления устройствами по заранее прописанным алгоритмам.
В вышеизложенной задаче поток данных наполнялся брокерами сообщений, однако хотелось бы отметить, что Flink способен обрабатывать и любой другой поток данных. Например, мы можем обрабатывать SQL скрипты БД или логи, что еще больше увеличивает спектр решаемых задач.
В наших планах и в дальнейшем использовать Apache Flink для решения таких задач как:
Управление системами освещения и комфорта;
Выявления нерационального потребления ресурсов и формирование рекомендаций;
Выявление подозрительных активностей;
Прогнозирование поломок и нештатных ситуаций;
Гибкое ценообразование и тарификация;
Анализ активности пользователей;
Анализа видеопотока.
В конце концов, обработка потока данных IoT, основанная на проверенной в боях среде, такой как Apache Flink, открывает очевидные преимущество для сценариев IoT — непрерывную обработку огромных объемов данных, которые непрерывно производятся. Flink дает возможность принимать, обрабатывать и реагировать на события в режиме реального времени с помощью масштабируемого, высоко доступного и отказоустойчивого подхода — при любых условиях и в любой момент времени. Flink может служить гибким вычислительным механизмом для большого разнообразия форматов данных, считывая их из различных источников, таких как распределенные файловые системы, базы данных и очереди сообщений. А конкурентоспособный набор функций, поддержка неупорядоченных потоков событий, обработка времени событий и гибкая механика управления временными окнами выделяют Flink среди решений для обработки потоков с открытым исходным кодом.
