Ansible идемпотентный. Алексей Соколов

Привет! Меня зовут Алексей Соколов. Я представляю компанию mail.ru. И сегодня мы с вами поговорим об Ansible.

Сначала маленький опрос. Кто хоть раз работал с Ansible? Чудно, почти все. И это очень показательная вещь. Ansible — это обычно тот инструмент, который начинают использовать, в первый раз придя в историю про DevOps.
А кто с Ansible ушел в пользу других инструментов? Например, в Salt, Chef? Почему?
На самом деле история в следующем. Обычно люди приходят в профессию, начинают заниматься с Ansible. Все им нравится, все хорошо. Да, действительно, работает. Да, действительно, просто и комфортно.

Потом хочется чего-то посложнее, помощнее. И они начинают лезть в другие истории: в Chef, в Puppet. Почему? Потому что считается, что это более мощные решения, централизованные и удобные решения. И создается мнение, что Ansible — это инструмент для новичков. Пришли, попробовали — вроде работает.
На самом деле очень многие не используют функционал Ansible так, как он задумывался изначально. И получается замкнутый круг. Люди приходят, люди думают, что это простой инструмент. Они начинают использовать его как простой инструмент. Забивают на большинство функций, а потом разочаровываются и уходят.
Люди приходят, фигачат что-нибудь, что потом ни фига не работает, что потом никто не может использовать. Это прямая цитата достаточно известного человека.

И он прав. Я сам столкнулся с такой же историей.

Я пришел в Ansible. Мне дали простую задачку. Сказали, что есть сценарии Ansible, нужно запустить, все сработает.
Не сработало.
И для человека, который только что пришел в эту историю, это сложная ситуация. Вроде бы есть какой-то инструмент, но человек не понимает, как он работает под капотом. Он не понимает, как его чинить, не понимает к кому обратиться.
На то, чтобы починить первый сценарий, который я в первый раз в жизни запустил на Ansible, у меня ушло несколько часов.

Низкокачественный код не пригоден для использования. Если человек не может, запустив что-то, сразу получить результат и начинает несколько часов копаться в этом коде, то это плохой код. Такого быть не должно.

Как выйти из ситуации? Простой пользователь просто забьет на это дело. Он сделает все руками. Ему не интересно копаться в инструменте, разбираться, как он работает и как его починить.
У разработчика терпения обычно побольше. Он полезет, посмотрит. Где-то накостыляет, где-то что-то подправит. Все запустится, и он забудет про это как про страшный сон.

А мы с вами поговорим про то, как сделать хорошо. Т. е. экспертный подход, как это все взять и починить.
Хорошо — это как?
- Хорошо — это когда достигается желаемый результат. Мы запустили сценарий, который должен что-то делать, и он должен это сделать.
- Пользователь хотя бы поверхностно понимает процесс, что происходит. Вот тут что-то копируется, вот тут что-то запускается и т. д. Пользователь понимает и инструмент ему коммуницирует информацию, что происходит.
- Хотелось бы, чтобы работа со сценарием не требовала экспертизы, чтобы пользователю не нужно было закапываться в недра и понимать, что там вертится.
- И хорошо, когда автор этого сценария, может ответить на какие-то вопросы. Может помочь починить, подправить. И на сценарий не забивает после того, как он написан.

Поговорим мы о том, как это сделать хорошо, но часть оставим за кадром.
- Во-первых, не будем говорить о стилистике написания, т. е. о том, как сам код должен выглядеть. Понятно, что эта тема важная, потому что, если человек не может прочитать, что там написано, то непонятно, как это поддерживать.
- Во-вторых, не будем упоминать хранение и версионирование. Понятно, что это должно быть. Понятно, что в случае чего: git blame + один телефонный звонок и мы как-то решаем проблему.

О чем поговорим?
- Во-первых, о декларативной модели в Ansible, про которую все почему-то упорно забывают.
- Во-вторых, про то, как создавать отказоустойчивый сценарий и про то, как сделать так, чтобы сценарий падал поменьше, а лучше не падал вообще.
- В-третьих, о том, как взаимодействовать с пользователем, как коммуницировать то, что мы делаем тому, кто этот сценарий использует.
Вот это, наверное, главный слайд во всей презентации:

Все люди, которые начинают работать с Ansible, должны это вбить себе в голову: Ansible — это не Shell.
В Ansible люди приходят обычно из администрирования, где все привыкли писать shell-скрипты. Ansible — это не про это. Ansible — это про декларативную модель, про то, что мы приводим систему в какое-то состояние.

И под капотом у Ansible есть огромный инструментарий для того, чтобы это делать.
- Казалось бы, обычный SSH. Имеем доступ на машинку по SSH, можем что-то Ansible«м сделать, можем руками.
- Но Ansible делает для нас гораздо больше. Это огромное количество кода на Python, который серьезно прорабатывает все, что вы хотите сделать.
- Код собирается в модули. И модули на каждый случай жизни. Большая часть того, что люди решают shell«ом, в модуле уже реализована. Не надо изобретать велосипед.

- К тому же, модули отслеживают состояние, т. е. мы можем понять не только то, что мы делаем, но и насколько качественно это приводит систему к желаемому состоянию. Мы хотим, чтобы на системе что-то было и модули как раз про то, чтобы убедиться, что там все так и есть.
- Модули коммуницируют изменения. Мы можем посмотреть вывод этого модуля и понять, что на самом деле произошло под капотом. Можем понять, что поменялось, что не поменялось.

Про декларативную модель чуть подробней. Общий смысл в том, что мы не делаем какой-то процесс, мы не выполняем какие-то команды, а мы хотим привести систему в желаемое состояние.
Мы хотим, чтобы там что-то лежало. Мы хотим, чтобы там что-то работало, что-то запускалось и т. д.
Мы приводим ее к состоянию, а не пытаемся сделать что-то руками.

И отсюда как следствие: необходимо избегать shell. Т. е. если вы пишите в Ansible просто обертку, чтобы запустить shell-сценарий или makefile, или что-то в этом духе, то вы делаете неправильно. Так не надо делать. Для всего есть модули.

Лучше избегать shell любой ценой. Почему? Мы об этом поговорим чуть позже.

А пока поговорим про результат.
- Мы убираем shell. Мы начинаем использовать модули и внезапно вывод Ansible начинает приобретать какой-то конкретный смысл.
- И вместо того, чтобы думать, что не упало и хорошо, мы понимаем, что вот тут что-то поменялось.
- А вот тут ничего не поменялось и это значит, что система в нужном состоянии уже была.
И мы можем понять, что сделал Ansible после того, как мы его запустили.

Как убедиться, что все настроено корректно? Как понять, что все так, как мы хотим? Через идемпотентные сценарии.

Что это такое? Википедия дает нам конкретное определение идемпотентности, но нам это не особо интересно. Мы интерпретируем его для себя.

В контексте Ansible это будет: запуск приводит систему в желаемое состояние в первый раз, а при повторном запуске делает то же самое только, если это необходимо. Т. е. мы на каждый запуск Ansible получаем один и тот же конкретный и ожидаемый результат.

Если совсем проще: не работает — почини, работает — не трогай.

С чего начать? Как начать разбираться, что Ansible делает?
- Во-первых, узнать, что на самом деле происходит под капотом.
- Во-вторых, сравнить с тем, что должно происходить. Т. е. вы хотите какой-то результат и смотрите, насколько Ansible все правильно делает.
- В-третьих, понять, что происходить не должно. Бывает, что вы пишите код, который потом что-то ломает, т. е. вы что-то не учли, где-то не подумали и т. д. Это тоже надо проверять.

Как это делать?
Есть самый простой способ. Мы просто берем вербозный вывод и начинаем смотреть, что происходит. Но там куча каши и не все из этого нам нужно.
Есть гораздо более простой способ. Это модули register, т. е. директивы register, которые позволяют нам зарегистрировать то, что модуль возвращает. Модуль там что-то сделал и сказал: «Я сделал вот это». И мы можем вот это посмотреть, выведя переменную, которую мы зарегистрировали.

И в этой переменной мы увидим целую кучу информации:
- Каков результат, что Ansible сделал на самом деле.
- Что изменилось.
- Что осталось неизменным.
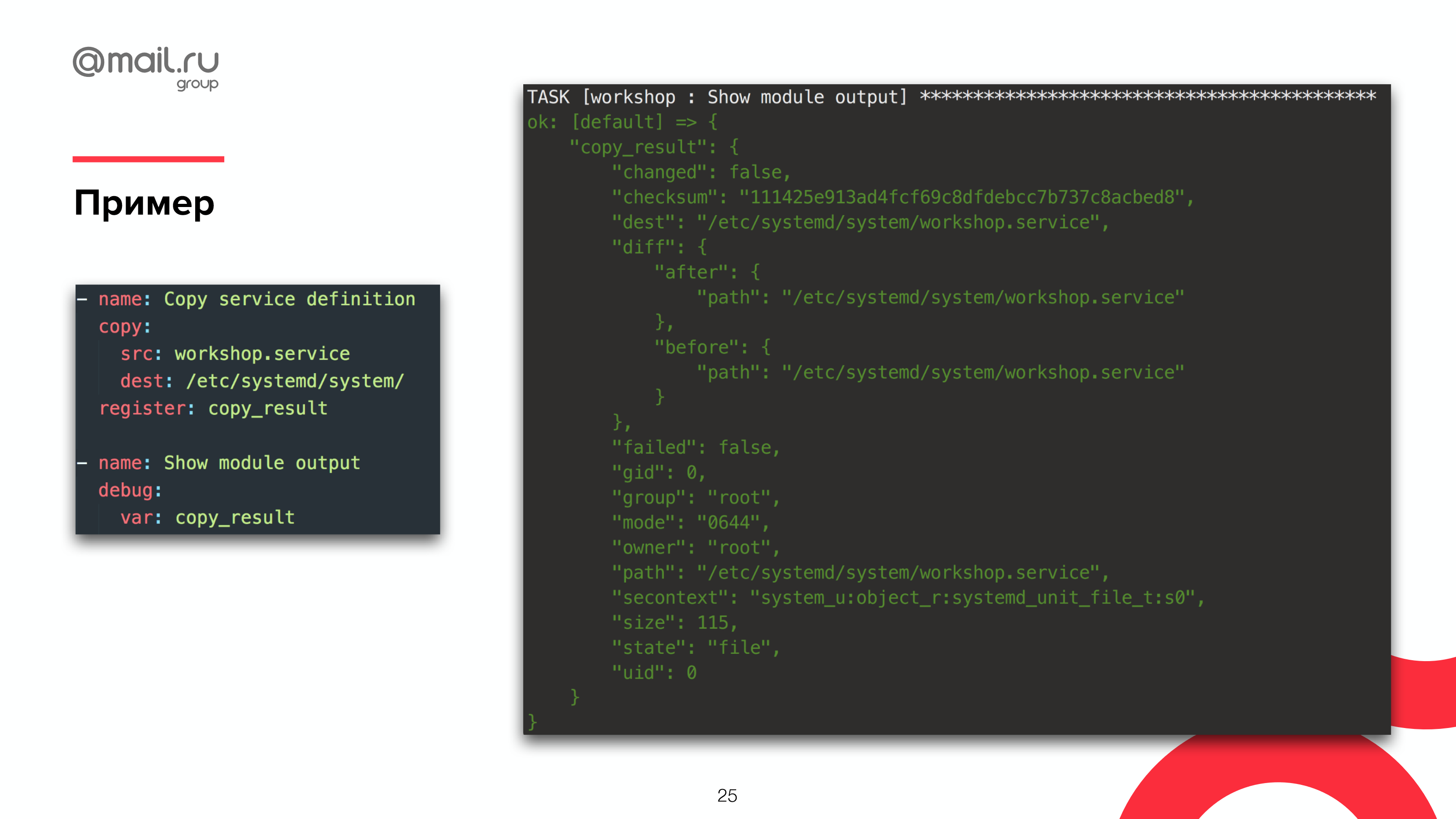
Это примерный вывод того, как даже самая простая команда копирования выводит нам кучу информации из-под капота. Это и diff, и контрольные суммы, и код вывода, если это команда, и права на файлы и т. д.
Все вот это вот мы можем сравнить с тем, что мы хотим. Хотим ли мы действительно такие права? Правильно ли мы скопировали файл? Та ли там чек-сумма?

Бывает, что приходится игнорировать ошибки. Ситуация неприятная, такие ситуации бывают. И зачастую мы игнорируем ошибки не там, где это нужно делать.
В целом мы пытаемся избежать того, чтобы сценарий работал не консистентно. Мы хотим, чтобы он просто не падал.
Придумали какой-то сценарий. Что-то там пошло не так. Вроде бы не страшно. Где-то что-то не проверилось и т. д. Ignore_errors — поехали дальше.
В итоге получается, что мы можем пропустить какие-то ошибки, которые мы совершенно не ожидали. Мы думали, что там сценарий может упасть, но это вроде для нас не страшно. А что если он упадет по другой причине, которую мы не ожидаем?
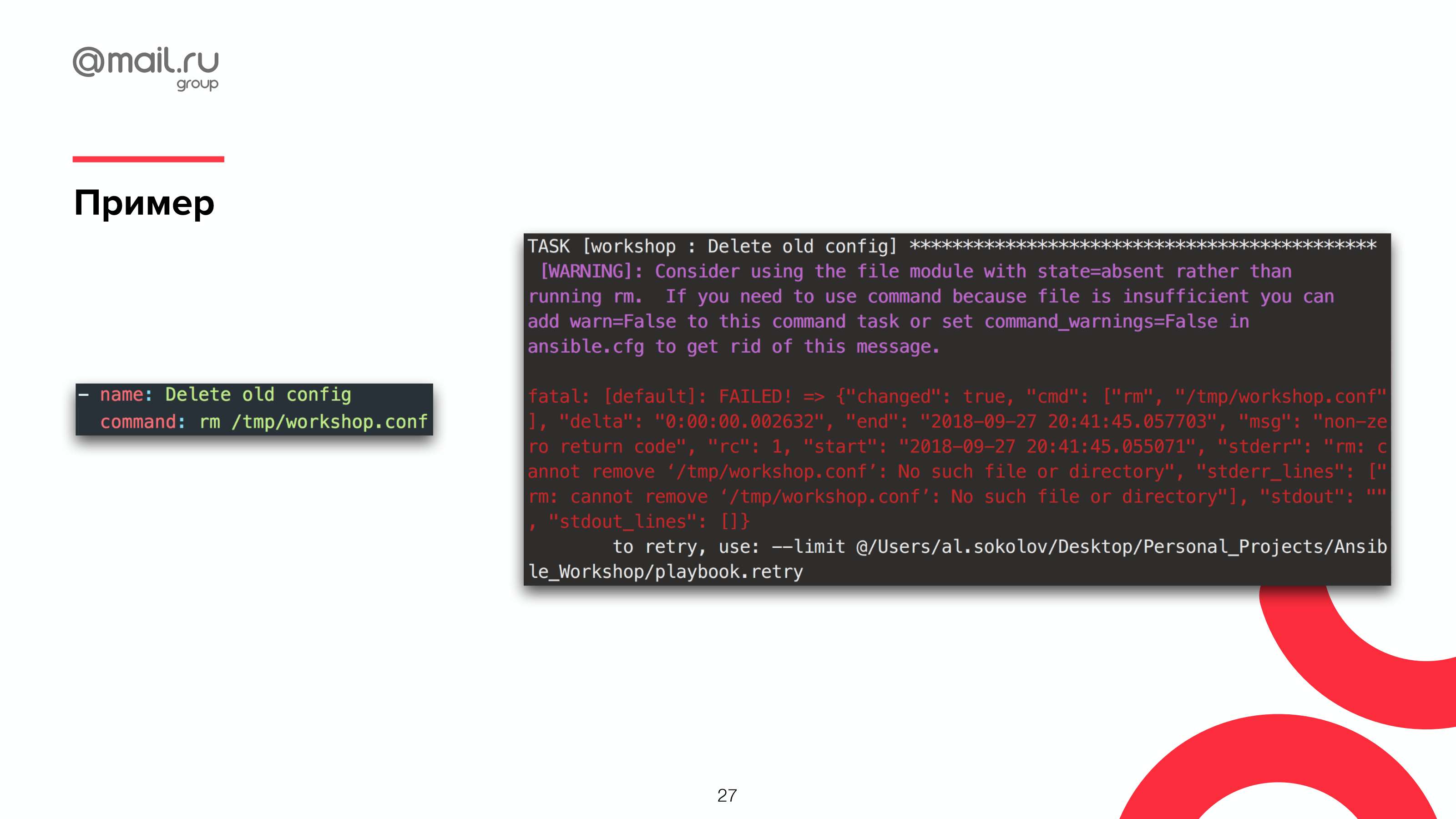
Пример того, как падает все это дело. Вот это полотно никому особо не нужно. Мы хотим пользователя от этого избавить.
И, кстати, лирическое отступление про предыдущую тему, про то, что не нужно использовать shell: даже Ansible нам иногда об этом подсказывает. Он прямо явно говорит: «Вы что делаете, ребята? Какой rm, какой shell-скрипт в Ansible? У нас есть модуль для этого. Пользуйтесь!»

Какая мораль? Знайте, что вы игнорируете. Старайтесь понимать для чего вы ignore_errors пишете.

И бывает три типовых ситуации:
- Во-первых, если мы запускаем какой-то сценарий. Действительно, бывают ситуации, когда без этого не обойтись. И есть какая-то специальная утилита, которую нам нужно запустить. Нам не хочется писать свой модуль. И мы решили сделать это командой. И если она не выходит с кодом возврата 0 по какой-то причине, мы решаем проигнорировать.
- Бывают ситуации, когда есть состоянии гонки (англ. race condition). Мы что-то хотим проверить. Оно должно было к этому моменту запуститься и не запустилось. Вроде не страшно, если не проверим. Ignore_errors — поехали.
- Избыточные действия. Допустим, у нас есть необходимость скачать что-то из одного места. Не получилось скачать из одного места, скачаем из второго. На первом мы делаем игнорирование ошибок, запускаем второй сценарий.

Как эти проблемы решать так, чтобы это было качественно и надежно?
Для первого есть register. Мы берем вывод команды, который выходит с exit code ненулевым. Регистрируем его вывод. И говорим, что она должна падать при определенных условиях. Для этого в Ansible есть директива failed_when. Мы можем самому модулю сказать, какое условие он должен считать таковым, чтобы думать, что он упал.
Мы обрабатываем вывод, либо просто код вывода. Смотрим, что на самом деле там произошло. И какую-то свою логику ему вписываем. Мы говорим: «Если вот это произошло, тогда ты свалился». А какие-то свои истории, когда он вроде бы с точки зрения системы свалился, а на самом деле нет, мы описываем, учитываем и просто пролетаем мимо.

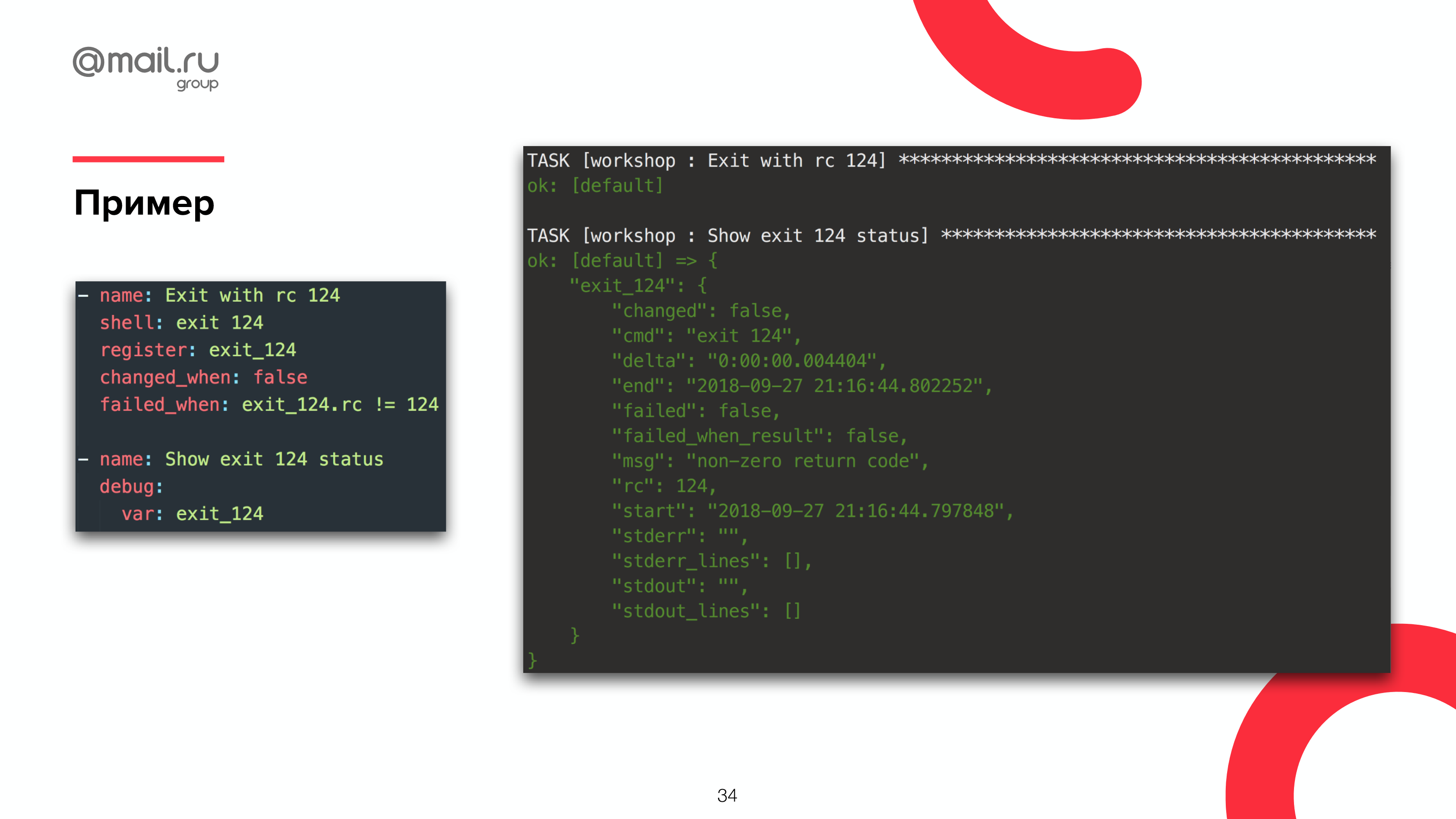
Вот один из примеров. Мы берем простую команду, мы выходим со 124-ым кодом. И говорим в явном виде: «Если код возврата не 124, тогда он сломался». Если 124, то все хорошо для нас, если не 124, то что-то упало. Выходим с кодом 124 и видим, что на самом деле Ansible считает, что все хорошо.
Вот он поменялся, поехал дальше, показал, что у нас все Ок. И мы можем дальше выполнять наш сценарий.
Но есть маленькая проблемка. Проблемка кроется наверху. Ansible считает, что что-то поменялось. А команда «exit 124» что-то меняет на системе? Очевидно, что нет. И нам это тоже надо учесть.


Для этого есть другая директива changed_when, т. е. мы можем сказать модулю, когда считать, что модуль что-то поменял. Если мы знаем, что команда ничего не меняет, мы можем сказать, что она никогда ничего не меняет: changed_when: false и Ansible всегда будет писать, что там ничего не поменялось, что все Ок.
Если мы работаем с файлами, то все может быть интересней. Есть директивы: creates и removes. Это директивы, которые позволяют нам сказать, что команды, которые мы выполняем, создают что-то, либо удаляют что-то.
И, соответственно, модуль будет обрабатывать это следующим образом: если мы создаем какой-то файл и там стоит creates для этого файла и этот файл на системе есть, то Ansible посчитает, что все Ок. Он даже не будет эту команду запускать, он ее пропустит и все.
Тоже самое с removes. Если файла на системе нет, команду он не будет запускать, пройдет мимо.
И, наконец, мы можем обработать вывод и код выхода. Мы можем поставить условную логику, которая будет проверять даже stdout, stderr команды. И на основе этого будет делать выводы — сломался на самом деле или не сломался.
Как это выглядит на практике? Почти та же самая история. Почти та же самая команда. Мы говорим, что changed_when: false. Эта команда у нас ничего не меняет. Ansible ее благополучно проскакивает. Он пишет: «Ок, там все хорошо».

Частенько бывают сценарии, когда мы чего-то ждем. Например, мы запустили сервис. Он стартует несколько секунд, несколько минут, что-то обрабатывает. Нам нужно подождать и не выполнять пока ничего.
Классический сценарий, когда мы используем для этого pause. Просто ставим на паузу на несколько секунд и надеемся, что за эти несколько секунд сценарий сделает то, что он хочет.
Гораздо правильней будет ждать конкретной ситуации. Для этого есть модуль wait_for. Мы можем сказать: «Подожди, пожалуйста, пока произойдет конкретное событие». И это событие благодаря Ansible может быть почти чем угодно. Это может быть появление файлов в файловой системе. Это может быть открытие какого-то сокета. Это может быть конкретное подключение по tcp, если оно с конкретным статусом, который нам нужен. Т. е. есть достаточно богатый функционал для того, чтобы проверять какие-то условия.
Если уж совсем не в терпеж и нам нужно пользователя дождаться, то мы тоже это можем сделать. Мы можем сделать паузу с выводом конкретной строки. И тогда вместо того, чтобы ждать какое-то определенное время, сценарий будет ждать ввода от пользователя. Сценарий будет ждать, пока пользователь кнопочку нажмет и все заработает.

Как это выглядит на практике? Это выглядит примерно следующим образом. Мы ждем, пока порт закроется. На самом деле мы понимаем, что он не закроется никогда в пределах запуска Ansible. Ansible послушно будет ждать, пока порт не закроется со стороны управляемой системы.

И для пользователя примерно так же. Мы говорим: «Pause», выводим какое-то сообщение пользователю. И пока пользователь кнопочку не нажмет, ничего дальше не поедет. Это очень удобно для сценариев, когда нам нужно подтверждения со стороны пользователя, например, на установку чего-то.

С избыточными действиями все еще проще. Мы просто говорим: «Если не выполнилось предыдущее действие, то делай это. Если предыдущее выполнилось, то делать не надо».

Пример тоже живенький. Мы говорим, что у нас запускается exit 0. Он никогда не фэйлится. И если вдруг предыдущая первая команда exit 0 не отработала, мы выполняем вторую. В первом случае мы, где второй пункт, просто пролетаем мимо, потому что условие не выполнилось. Во второй раз у нас первое условие не выполняется, соответственно, выполняется второе.
Это очень хорошо помогает не делать одну и ту же работу дважды.

Бывают особые и сложные ситуации, когда что-то пошло не так и мы хотим это скоммуницировать пользователю. Т. е. хотим объяснить простому пользователю, что что-то у нас пошло не так и его действия требуются в данный момент.
Для этого нам понадобится весь арсенал того, что я описал выше. Мы обработаем ошибку, которая у нас произошла. Проигнорируем ее, а пользователю выведем информацию в удобоваримом для него виде.
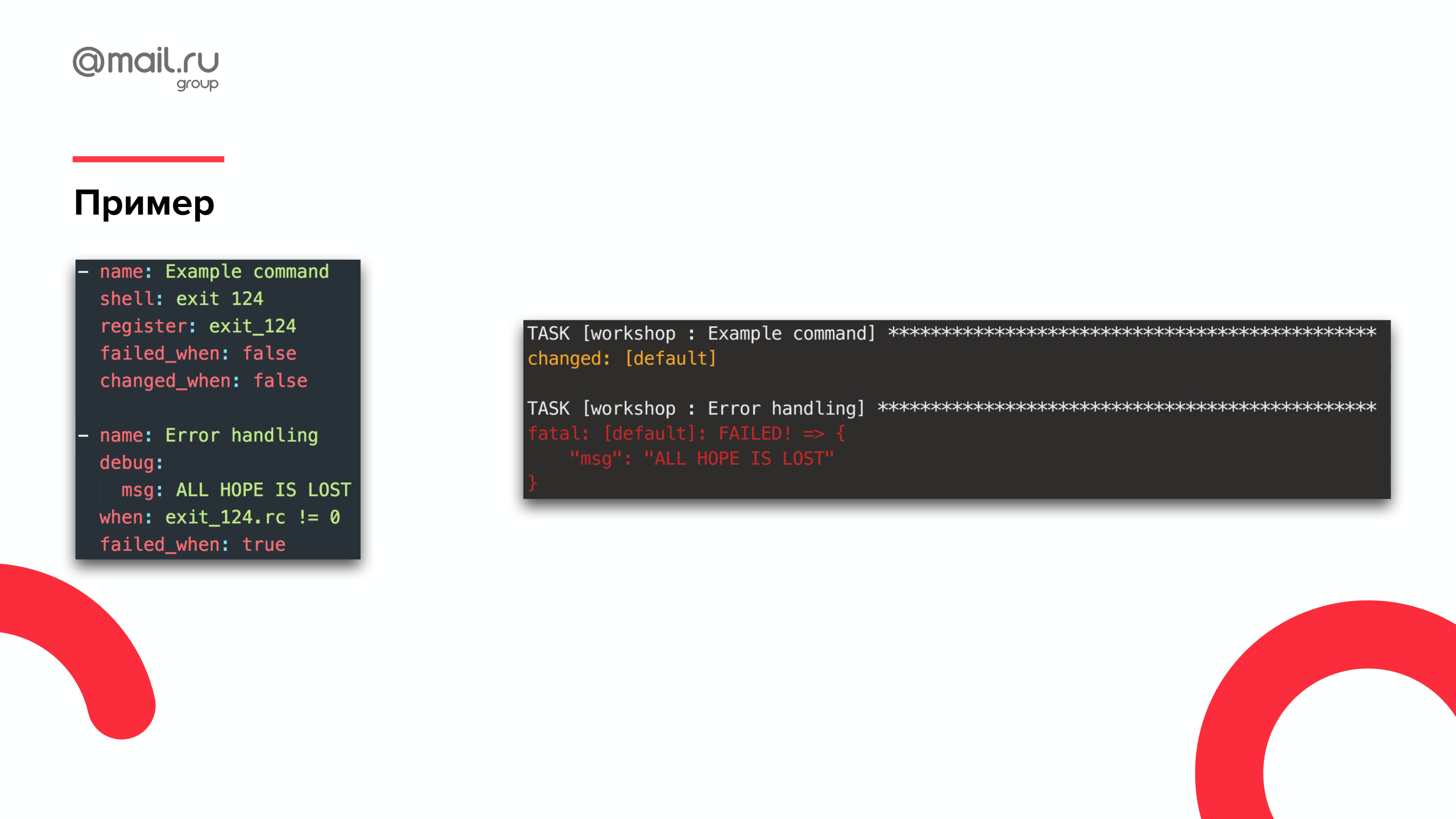
Выглядит это примерно следующим образом. Мы пишем какую-то команду. Мы знаем, что она упадет в данном случае. Мы полностью игнорируем ее ошибки, ее вывод. Говорим, что она никогда не падает, потому что мы будем сами обрабатывать ее результат.
И на следующем шаге говорим, что, если у нас предыдущая команда вышла не с нулевым кодом выхода, вывести пользователю вот такое сообщение.
Обратите внимание на самую нижнюю строчку: failed_when: true. Если мы этого не сделаем, то сценарий на этом шаге поедет дальше. Мы должны в явном виде сказать: «Выведи пользователю сообщение и свались». И тогда пользователь поймет, что здесь какое-то действие нужно. И вместо того, чтобы видеть вот это огромное полотно с ошибками, он прочитает и поймет, что надо «поплакать и залезть под стол».

О мелочах. Казалось бы, мелочи, но на самом деле бывают очень неприятные ситуации с этими вещами.

Во-первых, handler.
Handler — это удобный инструмент для какого-то отложенного запуска, но у него есть свои подводные камни. Подводные камни обычно пишутся другими авторами.
Вы берете какой-то playbook, в нем несколько ролей. И кто-то в одной из ролей захотел флашить handlers, т. е. просто захотел их принудительно запустить. Вы ждете, что у вас в самом конце запустится, а она берет и запускается в произвольный момент, когда захотел другой разработчик. Ситуации бывают неприятные из-за этого, поэтому старайтесь избегать handlers там, где они критично не нужны.
Учитывайте, что кто-то может вам вот здесь подгадить. И сами не гадьте другим, не флашьте handlers без крайней необходимости. Потому что тоже самое, что можно сделать flush_hundlers вручную, можно сделать другим способом — when: changed. Вы просто берете какой-то таск и говорите, что если тот шаг поменялся, то запусти.
Таким образом, вы никому подставу не делаете и сами выполняете в нужный момент все, что вам нужно.

Переменные. С переменными очень весело. Помните, что переменные — это глобальная вещь. Т. е. на весь запуск, на все роли, которые вы запускаете в рамках одного playbook, переменные всегда одни и те же. И если вы задаете простую переменную типа port, она и в этой роли port, и в другой роли port, если вы ее, конечно, там явно не переопределите.
- Здесь можно очень неприятно напороться. Старайтесь использовать имена переменных, которые содержат в себе название роли. Таким образом, вы защите себя от пересечения.
- И мое любимое — это слияние словарей.

Слияние словарей — это «прелестно». Вы берете один словарь в дефолтах, вы пишите какие-то переменные. И оп, и первые взяли и потеряли просто целиком. Почему? Потому что механика слияния словарей по умолчанию в Ansible подразумевает полную замену. Вы берете один ключ верхнего уровня, и все, что под ним он просто перетирает.

Есть способ это обойти. Есть hash_behavior. Это параметр конфигурационного файла Ansible, который позволяет сливать словари динамически и подтягивать все эти вещи.
Но даже разработчики говорят, что его не стоит использовать. И не стоит использовать не только потому, что он может как-то непредсказуемо работать, а потому что вы сами можете не учесть какой-то сценарий, в котором у вас попадет лишняя переменная. Например, с дефолтов. И это вам сделает больно.

Помните, что ваши сценарии зачастую могут запускаться в разных операционках, на разном железе, в разных условиях, с разными уровнями доступа. Где-то может быть интернет, где-то нет. Где-то есть какой-то сервис, где-то нет. Все что угодно может произойти.
И зачастую это неплохо было бы предусмотреть. Помните, что ваш сценарий может использовать кто-то другой в совершенно в других условиях.

И если все это учесть, прописать и грамотно сделать, и позаботиться о том, чтобы это стабильно работало, вывод будет прекрасен.

Вы будете видеть, что у вас система Ок по всем статьям, у вас ничего не поменялось, если вам не нужно было этого делать.
Подразумевается, что это вывод второго запуска. Первый — у вас что-то поменялось, что-то переделалось, все сделано так, как надо. Второй запуск — вы видите очень четко, что у вас система в нужном вам состоянии.
И если вдруг на этом моменте вы видите changes не 0, то вы сами понимаете, что что-то на системе поменялось, что мы не учли. Например, кто-то туда залез, кто-то ручками подковырял или там что-то упало.
И эта информация даст вам понимание о том, что с этой системой надо что-то сделать, где-то нужно за ней последить.
Помимо этого в Ansible есть очень хороший механизм, который позволяет запускать только проверки. И в этом случае подобный идемпотентный сценарий вам тоже поможет. Вы будете просто запускать сценарий и смотреть, насколько там все так, как вы хотите.

- Привыкайте к декларативной модели. Привыкайте к тому, чтобы не использовать в Ansible shell, а использовать Ansible на всю его мощь.
- Используйте модули везде, где только можно. Зачастую не нужно изобретать велосипед, все уже придумано до вас.
- Обрабатывайте свои собственные ошибки, которые можете как-то предугадать. И думайте над тем, где еще что-то может упасть. И о том, что где-то нужно подкостылять, чтобы оно держалось стабильней и как-то пользователю эту информацию возвращало.
- И помните про окружение. Сценарии могут запускаться где угодно и кем угодно.

Самое главное: вы пишите код не только для себя, вы пишите код для того, кто будет его использовать. Делайте его удобным не только для себя, не только для эксперта, но и для других, кто к этому совершенно не подготовлен.

Всем спасибо! Я буду рад ответить на вопросы.
Вопросы
Меня зовут Владимир. Мне интересна сфера применения Ansible. Что именно вы разворачиваете? Только ПО или, может быть, операционки еще при помощи него?
Чаще всего это инфраструктурные задачи, т. е. какие-то вещи, например, задача развернуть на нескольких серверах, например, типа Kubernetes. Это больше инфраструктурные задачи.
Привет! Спасибо за доклад! Какое количество ролей примерно вы сейчас поддерживаете? Я так понимаю, что все сейчас упирается в поддержку идемпотентных ролей. И как вы боретесь с версионированием этих ролей и с поддержкой разных версий?
Количество ролей измеряется десятками. Не так много.
Что касается версионирования, то обычно делается одна роль на конкретную версию ПО, которое разворачивается. И зачастую держится в branch. Отдельный branch — отдельная galaxy-роль = отдельный инфраструктурный элемент какой-то конкретной версии.
Привет! Меня зовут Лев. Есть вопрос: «Вы тестируете роли свои и используете линтеры: какой-нибудь YAML, Ansible-lint или фреймворки типа Молекулы?».
Тестировать YAML-lint — это обязательная вещь. Потому что, если там ошибку совершить, то все полетит.
Что касается тестирования функционала конкретной роли, то зачастую — это какие-то проверки, что что-то запустилось в самом конце этой роли. Мы ожидаем, что у нас запустится какое-то приложение на каком-то порту, мы этот порт проверяем. Опционально смотрим вывод на этом порту. Если все соответствует, то мы считаем, что — да, эта роль, скорее всего, запустилась.
Более детального тестирования мы не делаем. Там не такие катастрофически сложные роли, чтобы это реализовывать.
Спасибо за доклад! Вы еще по каким-то причинам против hash_behavior merge, кроме того, что его разработчики не любят? Как вы делаете, если у вас несколько окружений и вы хотите кучу одинаковых переменных, и хотите различие переменных помержить?
Проще эту задачу решать через defaults, через нормальные дефолты и переменные одного уровня, т. е. не плодить словари, а делать переменные в один список.
Так получается та же примерно логика. Да, немножко больше текста. Но зато она не менее удобочитаемая и гораздо более стабильная, потому что можно сразу понять, что там применилось, а что нет.
Если кто-то вдруг забудет про hash_behavior, то кто-то напорется на это очень сильно. Кроме того, hash_behavior — это вещь, которую нужно прописывать каждый раз в конфигурации, либо ключом.
Да, все время наталкиваются. А вы дефолты имеете в виду в ролях?
Да, дефолты для ролей.
Большое спасибо за доклад! Как вы соблюдаете безопасность от какого пользователя выполняются непосредственно Ansible-роли? Как распределяются ключи? И вы все роли от root запускаете или у вас отдельный пользователь под запуск Ansible-ролей? Как происходит дело с безопасностью?
Везде, где это не критично, если мы не говорим о запуске SystemD, хотя даже там можно обойтись sudo, обычно все сценарии не из-под root.
Привет! Вы, наверное, используете в своих ролях include_task, import_task? Если используете, то как к этому относитесь, потому что получается, что одна роль зависит от другой или от каких-то общих вещей? И есть ли у вас роль common?*
Роли common нет.
Что касается includes, то там история следующая. Бывают ситуации, когда какое-то действие, например, перезапуск сервиса, подразумевает несколько шагов, которые нужно выполнить последовательно. И это часто переиспользуется. В таких случаях берется отдельный таск-лист и импортится там, где нужно это действие выполнить. Вот это самый частый кейс.
Импортится через симлинки или как?
Через импорт таск отдельным файлом. Лежит рядышком файл.
Из роли в роль копируется этот файл?
Обычно он привязан к роли. Обычно это просто какой-то элемент этой роли.
Ты говоришь, что он переиспользуется …
Нет, переиспользуется в коде имеется в виду. Например, нам надо в этом месте кода перезапустить сервис или вот в этом. Т. е., допустим, нам нужно несколько перезапусков на генерацию каких-то файлов, потом на запуск самого сервиса.
Задам более точный вопрос. Где именно в структуре каталогов лежит этот общий файл?
Он, скорее, не общий. Он используется несколько раз в одной и той же роли.
А между ролями нет никаких?
Сейчас нет.
Спасибо за доклад! Используете ли вы одну версию Ansible или их несколько? И как вы решаете проблему с их обновлением? И как вы храните секреты в ролях?
Секреты чаще всего храним в Ansible-vault, хотя есть более удачное решение.
Что касается версий Ansible, то зачастую Ansible — это инструмент, который запускается самими разработчиками, поэтому мы учитываем, что версии могут быть разные. И зачастую какие-то проверки, если это возможно, встраиваются в сам сценарий, хотя это не особо надежный вариант.
Есть рекомендуемая версия Ansible для каждой роли. Если мы используем совсем новый модуль, который явно показан, что доступен в одной из последних версий, то просто коммуницируем.
Т. е. вы не управляете никак Ansible, который запускается? Грубо говоря, пользователь сам выбирает?
Да, чаще всего пользователь сам выбирает.
Здравствуйте! Спасибо за доклад! Что вы делаете со скоростью работы? Одна из главных проблем, почему мы отказались от Ansible, это как раз скорость его работы при большой инфраструктуре, где 300–400–500 серверов.
В наших условиях такого объема нет. Ansible покрывает далеко не всю инфраструктуру. Используется точечно. И если реально нужно какое-то высокопроизводительное решение, рассчитанное на большое количество серверов, то — да, наверное, стоит от Ansible отходить в пользу других централизованных решений, которые умеют все это разруливать гораздо более надежно. Ansible — не про то, чтобы разрулить несколько сотен, тысяч серверов.
P.S. Помимо этого доклада у автора есть воркшоп, выложенный на Гитхабе, который может пригодиться. https://github.com/zloyplohoy/ansible_the_idempotent
