Яндекс открывает Облако. Архитектура новой платформы

Сегодня Яндекс.Облако стало доступно всем. Теперь любой пользователь может зайти в Облако и развернуть необходимые ему ресурсы, получив доступ к технологиям Яндекса. Например, к машинному переводу и распознаванию и синтезу речи.
Сегодня я хочу познакомить вас с Яндекс.Облаком и рассказать, как оно устроено внутри. Под катом вы узнаете немного об истории, команде и архитектуре нашей платформы.
Немного истории
Несмотря на то, что облачная платформа Яндекса была впервые публично показана не так давно, проект развивается внутри компании уже долго и успел пережить несколько фаз, а многие технологии, которые легли в ее основу, прошли проверку временем во внутренней инфраструктуре Яндекса. Разработка началась в прошлом году, а первые внешние пользователи начали тестировать платформу в апреле 2018 года. Это был закрытый режим, в котором участвовало около 100 компаний — веб-сервисы разной величины, разработчики SaaS и корпорации. В сентябре мы открыли публичный сайт, но попасть в само Облако можно было только через лист ожидания, и вот теперь, в декабре, доступ стал открыт всем.
В самом начале, когда формировался план развития продукта, нужно было принять несколько стратегических решений о том, какими характеристиками должно обладать облако и на каких технологиях оно должно базироваться: какие опенсорсные решения было бы целесообразно использовать, что можно взять из внутреннего стека технологий Яндекса, а что придется разрабатывать специально для публичной платформы. Один из важнейших вопросов был связан с OpenStack.
К этому моменту в Яндексе уже несколько лет успешно работал кластер на OpenStack из нескольких тысяч хостов. Одним из возможных решений было бы использование этой технологии для создания Облака, тем более что это существенно ускорило бы выход платформы на рынок. Однако после множества обсуждений и горячих споров было принято решение в пользу собственной разработки. Высказывались доводы за и против, но решающими стали следующие аргументы.
В первую очередь, OpenStack — решение для частных single-tenant облаков. Оно исторически не создавалось для построения масштабируемых multi-tenant платформ. Второй момент: эта технология плохо совместима с гиперконвергентной архитектурой (когда все аппаратные ресурсы образуют один большой пул, и уже на базе него строится виртуальная инфраструктура). Ну и третье — мы на себе прочувствовали все сложности с поддержкой и модификацией OpenStack, выявленные в процессе эксплуатации кластера, и не хотели рисковать клиентским опытом наших будущих пользователей. Конечно, однозначных ответов на поставленные нами вопросы не было, но требовалось принять взвешенное решение. Выбор был сделан, и платформа пошла по собственному пути.
Тут стоит отметить сопутствующие архитектурные подходы, которые также были заложены в самом начале. Использование единого пула унифицированных аппаратных ресурсов — одно из принципиальных решений. Такой подход позволяет легко масштабировать платформу и безболезненно увеличивать количество доступных ресурсов. Кроме того, мы определили, что платформа будет строиться на принципе self-hosting. То есть все сервисы облака, включая служебные, должны «жить» поверх единой гиперконвергентной инфраструктуры. Это значит, что в Яндекс.Облаке нет выделенных серверов управления. Все сервисы платформы развернуты на таких же виртуальных машинах, как и у внешних пользователей.
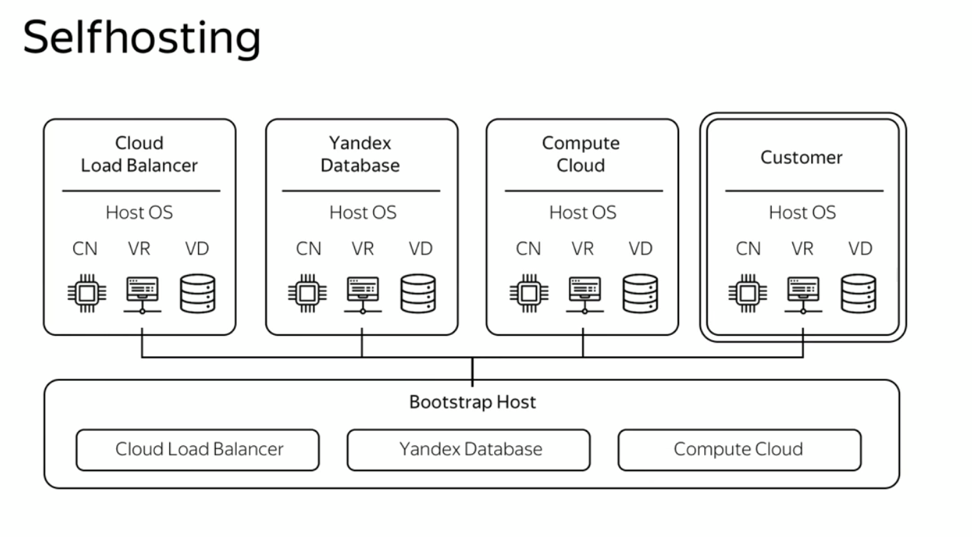
Self-hosting позволяет очень гибко управлять структурой облака и с минимальными затратами в автоматическом режиме подключать дополнительную инфраструктуру — от одного сервера до целого дата-центра с тысячами машин. Кроме того, мы работаем в тех же условиях, что и наши пользователи, а значит, можем на себе испытывать весь клиентский опыт.
И третий принцип, заложенный в основу платформы: наличие единого хранилища метаданных и системной информации для всех сервисов. Для этого используется внутренняя разработка — Yandex Database (YDB, не путать с ClickHouse), которая позволяет размещать данные очень надежно, эффективно и эластично. Таким образом, хранилище метаданных стало базовым внутренним сервисом для всех других сервисов Яндекс.Облака.
Вы, наверное, обратили внимание, что основные принципы организации платформы тесно связаны друг с другом и во многом определяют архитектуру и многие последующие технологические решения. Именно это и дало нам возможность создать масштабируемую платформу, которая позволит планировать развитие всех существующих и будущих сервисов Облака в долгосрочной перспективе.
Архитектура
В общем виде архитектура выглядит так:
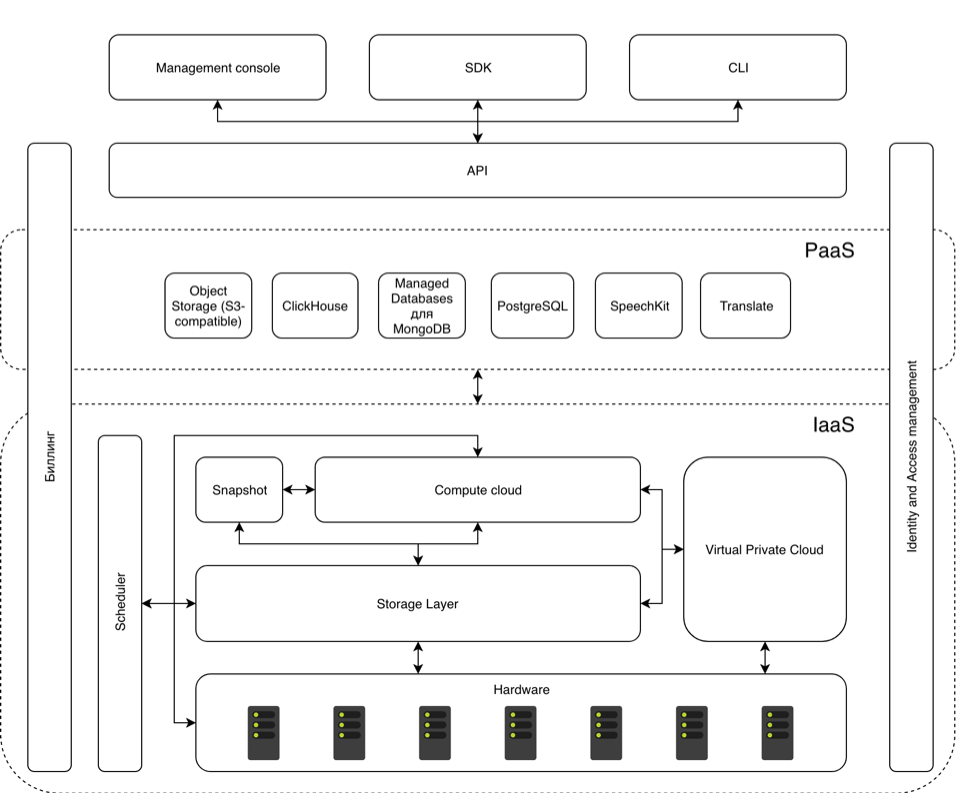
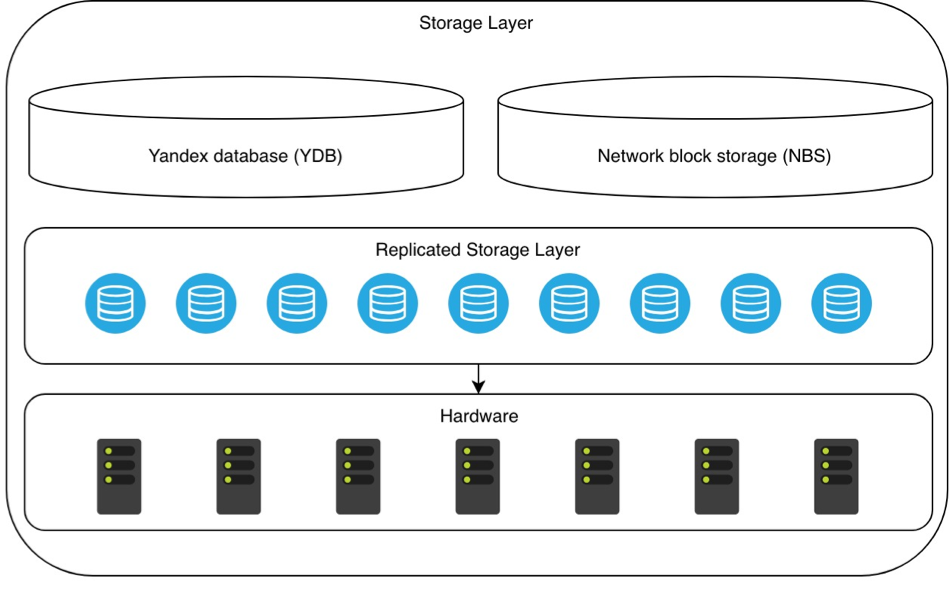
Основу облака составляет уже упомянутое общее хранилище метаданных (storage layer). YDB с помощью специального механизма репликации охватывает собой все аппаратные хранилища, доступные Облаку. Аналогичный механизм действует для network block storage (NBS). Вдвоем с YDB они образуют общую систему хранения данных, которая и используется всеми остальными сервисами в Облаке.
Поверх хранилища построен сервис Yandex Compute Cloud. Он дает возможность управлять виртуальными машинами, которые используются как внешними пользователями, так и внутренними компонентами платформы. Гипервизором служит KVM, а эмулятором — QEMU. Как следствие, для виртуализации устройств были выбраны VirtIO-драйвера. Важной частью связки виртуальных машин и аппаратной инфраструктуры является Scheduler. Именно он определяет, на каком физическом сервере будет развернута очередная виртуальная машина.

Все вместе эти компоненты являются IaaS-частью платформы, куда также входит сервис Yandex Virtual Private Cloud. В основе сетевого сервиса лежит опенсорсный проект OpenContrail.
Еще одним важным компонентом этого уровня является механизм Snapshot. Он позволяет делать снимки и образы дисков.

Уровнем выше — платформенные сервисы, в большинстве своем доступные всем пользователям Яндекс.Облака. Это сервисы для управления базами данных в Облаке, кластера которых разворачиваются на виртуальных машинах (ClickHouse, Managed Databases для MongoDB и PostgreSQL); совместимое с S3 объектное хранилище;, а также сервисы перевода и синтеза и распознавания речи.
Есть еще два важных сервиса, которые охватывают собой все слои облака. Это Биллинг и Identity and Access Management (IAM). Первый отвечает за все операции с тарификацией и оплатой потребленных ресурсов. Второй реализует управление доступом к ресурсам на базе ролей (role based access control): каждому пользователю могут быть назначены те или иные роли, описывающие разрешенные операции. Например, роль editor позволяет создавать, удалять и редактировать ресурсы, но не позволяет управлять доступом к ним.
Это достаточно общее описание устройства Яндекс.Облака, но оно позволяет понять, как различные части большой платформы взаимодействуют друг с другом. Если вы хотите более детально вникнуть в структуру платформы — советую вам посмотреть запись конференции about: cloud. Особое внимание на этом мероприятии было уделено сетям и Yandex Database.
Команда
Напоследок — пара слов о команде. За последний год она существенно увеличилась и продолжает расти. Сейчас она состоит уже более чем из 150 человек, не считая большого количество групп, которые напрямую не входят в состав Яндекс.Облака, но наработки которых также применяются в платформе. Существенная часть специалистов — конечно же, разработчики. Они поделены на подразделения, которые занимаются тем или иным направлением: виртуальными машинами, облачными базами данных, биллингом, сетями и т. д. Есть отдельная группа, специализирующаяся на вопросах безопасности облака и всего, что в нем хранится. Ну и, конечно же, поддержка, готовая быстро ответить на вопросы, возникающие у пользователей.
На этом у меня все. В ближайшем будущем мы опубликуем несколько статей, посвященных деталям работы с разными сервисами нашей платформы. А пока вы можете бесплатно познакомиться с Яндекс.Облаком. Каждый новый пользователь получит 4000 рублей на знакомство с платформой. Этой суммы вполне хватит на то, чтобы в течение месяца размещать в Облаке веб-проект среднего масштаба на базе стандартной связки LAMP с объектным хранилищем файлов на 1 терабайт; или для того, чтобы перевести массив данных размером более 9 млн символов, подключив машинный перевод к своему мобильному приложению или веб-сайту.
