Анализ заявок на обслуживание с помощью машинного обучения
В рамках поддержки продукта мы постоянно обслуживаем обращения от пользователей. Это — стандартный процесс. И как любой процесс, его нужно регулярно критически оценивать и улучшать.
Мы знаем о некоторых систематически проблемах, которые хорошо-бы решить и, по возможности, без привлечения дополнительных ресурсов:
- ошибки в диспетчеризации заявок: мы получаем что-то «чужое», другие команды иногда получают что-то «наше».
- сложно оценить «сложность» заявки. Если заявка сложная — ее можно передать сильному аналитику, а с простой — и начинающий справится.
Решение любой из указанных задач будет положительно влиять на скорость обработки заявок.
Применение машинного обучения, в приложении к анализу содержания заявки, выглядит как реальная возможность улучшить процесс диспетчеризации.
В нашем случае задачу можно сформулировать следующими задачами классификации:
- Убедиться, что запрос корректно отнесен к:
- конфигурационной единице (одна из 5 в рамках приложения или «другие»)
- категории обслуживания (инцидент, запрос информации, сервисный запрос)
- Оценить ожидаемое время на закрытия запроса (как высокоуровневый индикатор «сложности»).
С чем и как будем работать
Для создание алгоритма будем использовать «стандартный набор»: Python с библиотекой scikit-learn.
Для реального применения будет реализовано 2 сценария:
Обучение:
- получение «тренировочных» данных из трекера заявок
- запуск алгоритма для обучение модели, сохранение модели
Использование:
- получение данных из трекера заявок для классификации
- загрузка модели, классификация заявок, сохранение результатов
- обновление заявок в трекере на основании проведенной классификации
Все что относится к пайплайну (взаимодействию с трекером) можно реализовать на чем угодно. В данном случае были написаны скрипты powershell, хотя можно было и на python продолжить.
Алгоритм машинного обучения будет получать данные на классификацию/обучение в виде .csv файла. Обработанные результаты также будут выведены в .csv файл.
Входные данные
Для того, что бы алгоритм получился максимально независимым от мнения сервисных команд, в качестве входных параметров модели будем учитывать только данные, полученные от создателя заявки:
- Краткое описание/заголовок (текст)
- Развернутое описание проблемы, если есть (текст). Это — первое сообщение в потоке общения по заявке.
- Имя заказчика (сотрудник, категория)
- Имена других сотрудников, включенных в список уведомлений (watch list), по заявке (список сотрудников)
- Время подачи заявки (дата/время).
Набор данных для обучения
Для обучения алгоритмов были использованы данные о закрытых обращениях за последние 3 года — ~3500 записей.
Дополнительно, для обучения классификатора распознаванию «прочих» конфигурационных единиц, в тренировочный набор были добавлены закрытые заявки, обработанные другими отделами для других конфигурационных единиц. Всего дополнительных записей — около 17000.
Для всех таких дополнительных заявок конфигурационная единица будет установлена как «другое»
Предобработка
Текст
Предобработка текста — предельно простая:
- Переводим все в нижний регистр
- Оставляем только цифры и буквы — остальное заменяем пробелами
Список уведомлений (watchlist)
Список доступен для анализа в виде строки, в которой имена представлены в форме Фамилия, Имя, и разделены точкой с запятой. Для анализа будем преобразовывать его в список строк.
Объединением списков получим набор уникальных имён на основании всех заявок тренировочного набора. Этот общий список сформирует вектор имён.
Длительность обработки заявки
Для наших целей (управление приоритетами, планирование релизов) достаточно отнести заявку к определенному классу по длительности обслуживания. Это также позволяет перевести задачу из регрессии в классификацию с малым количеством классов.
Формируем признаки
Текст
- Объединяем «заголовок» и «описание проблемы».
- Передаем в TfidfVectoriser для формирования вектора слов
Имя составителя заявки
Поскольку ожидается, что человек, создавший заявку, будет важным атрибутом дальнейшей классификации — переведем его в one-of encoding индивидуально используя DictionaryVectorisor
Имена людей, включенных в список уведомлений
Список людей, включенных в watchlist заявки будут преобразованы в вектор в базисе всех имён, подготовленном ранее: если человек был в списке — соответствующий компонент будет установлен в 1, иначе — в 0. Одна заявка может иметь несколько людей в watchlist — соответственно, несколько компонент будет иметь единичное значение.
Дата создания
Дата создания будет представлена в виде набора числовых атрибутов — год, месяц, день месяца, день недели.
Это делается в предположении, что:
- Скорость обработки заявок меняется во времени
- Скорость обработки имеет сезонный фактор
- День недели (особенно заявки в выходные) может помочь в выявлении конфигурационной единицы и категории обслуживания
Обучаем модель
Алгоритм классификации
Для всех трёх задач классификации была использована логистическая регрессия. Она поддерживает многоклассовую классификацию (в модели One-vs-All), довольно быстро обучается.
Для обучения моделей, определяющих категорию обслуживания и длительность обработки заявок будем использовать только заявки заведомо принадлежащие нашим конфигурационным единицам.
Результаты обучения
Определение конфигурационных единиц
Модель демонстрирует высокие показатели полноты и точности при отнесении заявок к конфигурационным единицам. Так же модель хорошо определяет события когда заявки относятся к чужим конфигурационным единицам.
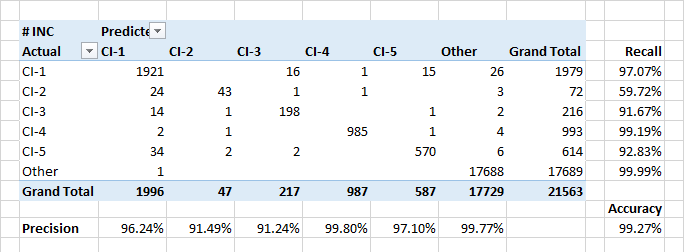
Относительно низкая полнота для класса CI-2 частично обусловлена реальными ошибками классификации в данных. Кроме того, CI-2 представляют «технические» заявки, выполняемые для других CI. Так что, с точки зрения описания и вовлеченных пользователей, такие заявки могут быть похожи на заявки других классов.
Самыми значимыми атрибутами для отнесения заявок к классам CI-? ожидаемо оказались имена заказчиков заявок и людей, включенных в лист оповещения. Но были и отдельные ключевые слова которые находились в первой 30-ке по значимости. Дата создания заявки значения не имеет.
Определение категории заявки
Качество классификации по категориям получилось несколько ниже.
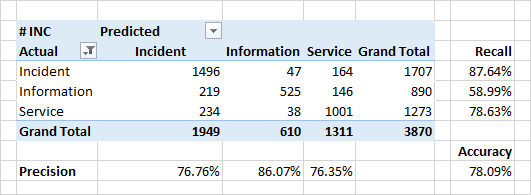
Очень серьезной причиной несовпадения предсказанных категорий и категорий в исходных данных — реальные ошибки в исходных данных. В силу ряда организационных причин, классификация может оказываться некорректной. Например, вместо «инцидента» (дефект в системе, неожиданное поведение системы) заявка может быть помечена как «информация» («это не баг — это фича») или «сервис»(«да, сломалось, но мы это просто перезапустим — и все будет ок»).
Именно выявление подобных нестыковок и есть одна из задач классификатора.
Значимые атрибуты для классификации в случае категорий стали слова из содержания заявок. Для инцидентов — это слова «error», «fix», «when». Также встречаются слова, обозначающие некоторые модули системы — это те модули, с которыми пользователи работают непосредственно и наблюдают появление прямых или косвенных ошибок.
Интересно, что для заявок, определяемых как «сервис» — топовые слова тоже определяют некоторые модули системы. Повод задуматься, проверить, и наконец-то их починить.
Определение длительности обработки заявки
Слабее всего удалось предсказать длительность обработки заявок.
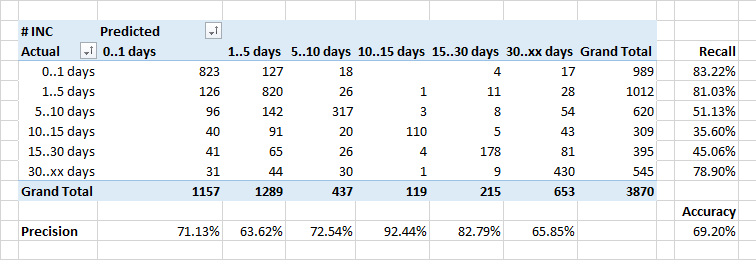
Вообще, зависимость количества заявок, которые закрываются за определенное время в идеале должна выглядеть как обратная экспонента. Но с учетом того, что некоторые инциденты требуют исправлений в системе, а это делается в рамках регулярных релизов — длительность выполнения некоторых заявок искусственно увеличивается.
Поэтому, возможно, классификатор относит некоторые «долгие» заявки к классу «быстрее» — он же не знает о сроках планируемых релизов, и считает, что заявку нужно закрывать быстрее.
Это тоже хороший повод для размышлений…
Реализация модели в виде класса
Модель реализована в виде класса, инкапсулирующего все используемые стандартные классы scikit-learn — шкалирование, векторизация, классификатор и значимые настройки.
Подготовка, обучение и последующее использование модели реализованы как методы класса, опирающиеся на вспомогательные объекты.
Объектная реализация позволяет удобно порождать производные варианты модели, использующие другие классы классификаторов и/или предсказывающие значения других аттрибутов исходного набора данных. Все это делается путем переопределения виртуальных методов.
При этом все процедуры подготовки данных могут оставаться общими для всех вариантов.
Кроме того, реализация модели в виде объекта позволили естественным образом решить задачу промежуточного хранения обученной модели между сессиями использования — через сериализацию / десериализацию.
Для сериализации модели был использован стандартный механизм Python — pickle/unpickle.
Поскольку он позволяет сериализовать несколько объектов в один и тот же файл — это поможет согласованно сохранять восстанавливать несколько моделей, включенный в общий поток обработки.
Заключение
Полученные модели, даже будучи относительно простыми, дают очень интересные результаты:
- выявлены систематические «промахи» в классификации по категория
- стало ясно, какие части системы ассоциируется с проблемами (видимо — не без повода)
- времена обработки заявок явно зависят от внешних факторов, которые необходимо улучшать отдельно.
Нам еще предстоит перестроить внутренние процессы на основании получаемых «подсказок». Но даже этот маленький эксперимент позволил оценить силу методов машинного обучения. А также, побудил дополнительный интерес команды к анализу собственного процесса и его улучшения.
