Анализ тональности с помощью Azure Machine Learning
В этом посте я расскажу, как можно использовать Microsoft Azure Machine Learning для анализа тональности текста, а также с какими проблемами можно столкнуться в процессе использования Azure ML и как их можно обойти.Что такое анализ тональности хорошо описано в статье «Обучаем компьютер чувствам (sentiment analysis по-русски)».Нашей целью будет являться построение веб-сервиса, который принимает на вход некоторый текст и возвращает в ответ 1, если этот текст носит позитивный характер, и -1 — если негативный. Microsoft Azure Machine Learning идеально (почти) подходит для этой задачи, так как там есть встроенная возможность опубликовать результаты вычислений как веб-сервис и поддержка языка R — это избавляет от необходимости писать свои костыли и настраивать свою виртуальную машину/веб-сервер. В общем, все преимущества облачных технологий. К тому же, совсем недавно было объявлено, что все желающие могут попробовать Azure ML даже без аккаунта Azure и кредитной карточки — необходим только Microsoft Account.Весь процесс сведется к двум пунктам:
Созданием и обучение модели Использование полученной модели Обучение моделиДля распознавания тональности мы будем использовать наивный байесовский классификатор. Для обучения нам необходима размеченная выборка, содержащая набор некоторых текстов и соответствующих им оценок. Далее для этого набора строится матрица документ-термин, где строкам соответствуют документы, а столбцам — термины, которые в них встречаются. Каждая ячейка содержит количество повторений данного термина в соответствующем документе. Таким образом, для двух документов «Сегодня хорошая погода» и «Я не очень хорошо себя чувствую, виновата погода» матрица документ-термин будет выглядеть следующим образом: сегодня хорошая погода я не очень хорошо себя чувствую виновата doc1 1 1 1 0 0 0 0 0 0 0 doc2 0 0 1 1 1 1 1 1 1 1 Обратите внимание, что в таблице присутствуют две формы одного и того же слова — «хорошая» и «хорошо». Этого можно избежать, если использовать стемминг (те обрезание окончаний по определенным правилам), но тогда результаты могут и ухудшиться. Подробнее про это, а также взвешивание терминов и N-граммы читайте в статье по ссылке в начале поста.
После построения этой матрицы её можно напрямую использовать для обучения байесовского классификатора. Но перейдем наконец от теории к практике.
Практика Мы будем оценивать тональность постов на стенах в ВК. Соответственно, для обучения классификатора нужна выборка постов с проставленной тональностью. Её можно скачать по этой ссылке (внимание, эта выборка была размечена во время нашего (я, ASTAPP и MKulikow) участия в хакатоне Big Data, и, соответственно, она не претендуют на высокую точность и может содержать ошибки, так как разметка делалась в большой спешке). В этой выборке порядка 3500 случайных постов со случайных стен ВКонтакте, из них 341 носят позитивный характер и 115 — негативный. Оценка постов проводилась по шкале от -10 до 10.Итак, давайте создадим эксперимент в Azure ML для обучения классификатора. Зайдите на домашнюю страницу ML и щелкните New → Experiment → Blank Experiment. Перед вами откроется чисто поле нового эксперимента. Сверху можно сразу сменить название на более приличное — habr_article_sentiment, например.
Теперь надо загрузить наш набор данных в Azure. В теории, для этого надо щелкнуть New → Dataset → From Local File, а затем в списке «Select a type for the new dataset:» выбрать Generic CSV File with a header. Однако, тут возникает проблема — если в строке присутствует символ новой строки (\n), пусть даже и экранированный кавычками, то импорт пройдет некорректно. А в постах на стенах ВК этот символ обязательно присутствует. Этот баг можно обойти, если загрузить CSV-файл в базу данных, а затем использовать блок Reader из раздела Data Input and Output для загрузки данных. Перетащите этот блок на поле эксперимента, настройте подключение к БД и задайте SQL-запрос для выборки данных (не забудьте поставить галочку «Accept any server certificate (insecure)». SQL-запрос будет похоже на такой:
SELECT score AS grade, text FROM tmp.big_data_hack Теперь можно запустить эксперимент и проверить, что будет на выходе блока Reader — для этого нажмите на кнопку Run внизу страницы, а после завершения выполнения щелкните на выходном узле правой кнопок мыши и выберите «Visualize». Должно получится что-то такое:
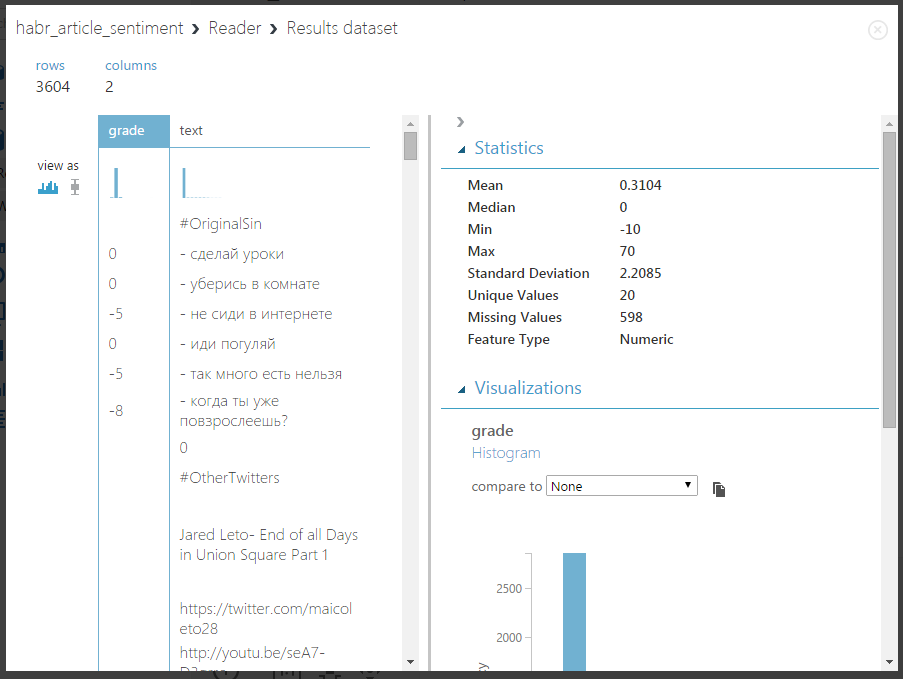
В блоке справа можно посмотреть некоторую статистику — видно, что максимальное значение 70, это очевидная опечатка в процессе разметки, а также присутствуют неразмеченные строки (строки с нейтральной тональностью).
Теперь давайте удалим пустые строки, а также приведем оценки из шкалы от -10 до 10 к категориальной оценке: -1, 0 и 1. Для этого воспользуемся блоками Missing Value Scrubber и Clip Values. Используя поиск в панели с блоками, найдите и перетащите на поле эксперимента блок Missing Value Scrubber и соединте его вход с выходом блока Reader:

Задайте настройки этого блока как на картинке выше — тут, я думаю, все понятно.
Теперь перетащите блок Clip Values — этот блок служит для обнаружения и замены выбросов и отлично подойдет для наших целей — просто установим мин. и макс. значение как -1 и 1 соответственно.

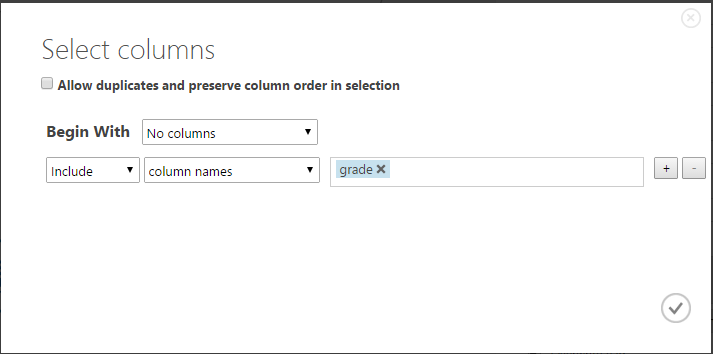
Обратите внимание, что этот блок имеет Columns Selector — следует выбрать, какие колонки он будет обрабатывать. По умолчанию — все цифровые. Давайте выберем нашу колонку grade — нажмите Launch Column Selector и установите следующие настройки:
Давайте попробуем запустить эксперимент и посмотреть, что получится — нажмите Run и визуализируйте выход блока Clip Values:
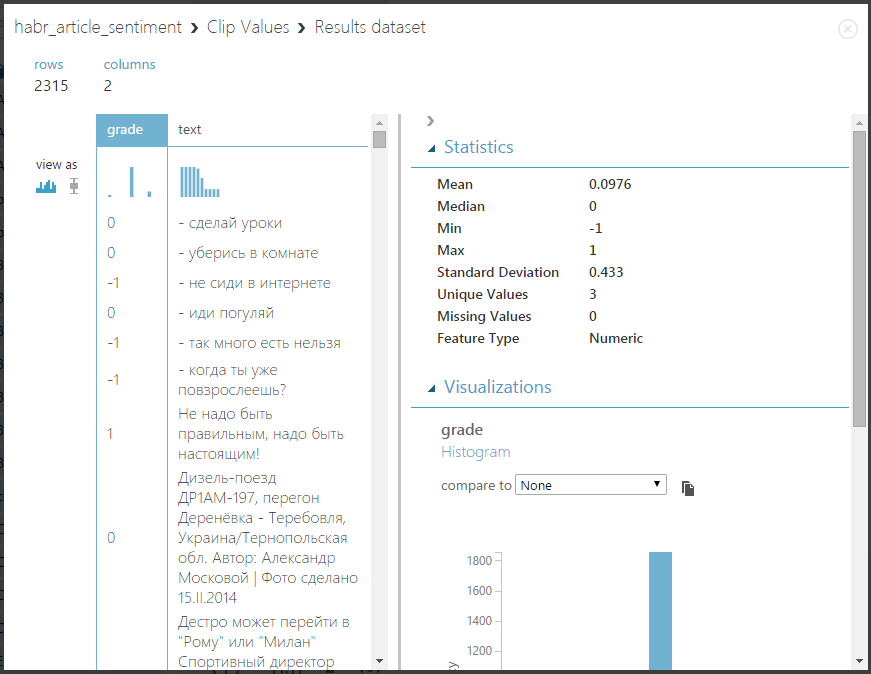
Замечательно! Как раз то, что надо — теперь мы можем перейти непосредственно к обучению классификатора. Так как Azure ML поддерживает выполнение произвольных R-скриптов, мы будем использовать наивный байесовский классификатор из пакета e1071 для R. Перетащите на поле эксперимента блок Execute R Script и соедините выход Clip Values с входной точкой Dataset1:

Тут следует сразу оговорится: в идеале процесс обучения модели и последующего её использования происходит следующим образом: мы создаем эксперимент, выбираем модель, которую мы хотим использовать, обучаем её и проводим проверку точности. Затем, мы просто кликаем правой кнопкой мыши на выходе модели и выбираем «Save as Trained Model». После этого обученная модель сохраняется в разделе блоков, и мы всегда можем её использовать — те, для того, чтобы опубликовать веб-сервис, мы просто создаем новый эксперимент, перетаскиваем туда нашу обученную модель и задаем выходные-выходные точки. Все очень легко и понятно. Однако, на данный момент возможность сохранять обученную модель у блока типа «Execute R Script» отсутствует. Я очень надеюсь, что это скоро исправят (проголосуйте, пожалуйста, за это вот тут). Однако, возможность сохранить и использовать в дальнейшем модель из R-скрипта все-таки есть: можно сериализовать объект в набор байтов, а затем подать его на выход блока (предварительно преобразовав этот набор в одноколоночный DataFrame, так как на выход можно подавать только DataFram’ы). После завершения эксперимента можно будет щелкнуть правой кнопкой мыши по выходной точке и выбрать Save as Dataset. В будущих же экспериментах можно будет выбрать этот датасет и подключить его к входу блока R-скрипта, а там загрузить его и десериализовать. Способ кривоватый, но работает :) Немного проще можно поступить, если у вас есть локально установленный R — обучаем модель, сохраняем в .RData, запаковываем в zip, а этот zip загружаем в раздел датасетов и подключаем к третьем входу блока R-script — «Script Bundle (Zip)». Вообще, в раздел датасетов можно напрямую загрузить файл типа .RData, но я не нашел ни одного блока, к которому он потом подключается — он не подключается даже к блоку R-script, что было бы вполне логично :(
С учетом вышесказанного, код на R выглядит следующим образом:
library («RTextTools») library («stringr») library («tm») library («e1071»)
# Загружаем данные с первого входа (нумерация начинается с 1) data <- maml.mapInputPort(1)
# Так как в наших данных имеется очень сильный перекос в сторону нейтральных постов, просто удалим их и будем классифицировать только на положительные/отрицательные data <- data[data$grade != 0,]
# Строим матрицу документ-термин с удалением чисел и ограничением на длинну слова dtm <- create_matrix(data$text , language="russian" , minWordLength = 2 , maxWordLength = 10, , stemWords = FALSE , removeNumbers = TRUE , removeSparseTerms = 0 ) mat = as.matrix(dtm) # преобразуем из класса DocumentTermMatrix просто в матрицу
# Обучаем классификатор classifier = naiveBayes (mat, as.factor (data$grade))
# Сериализуем его serClsf <- serialize(classifier, connection = NULL)
# Создаем DataFrame и отправляем его на выходной порт output <- data.frame(clsfr = as.integer(serClsf)) maml.mapOutputPort("output"); Теперь, наконец, можно запустить эксперимент! У меня его выполнение заняло где-то минуту. После завершения, если все прошло без ошибок, можно щелкнуть правой кнопкой мыши по выходному порту и сохранить классификатор как новый датасет:

На этом обучение модели закончено и можно приступить к следующей части — использование полученной модели, создание и публикация веб-сервиса.
Использование модели
Создайте новый эксперимент и назовите его, например, habr_article_sentiment_use. Перетащите на поле блок Execute R Script и подсоедините к его второму порту сохраненный ранее классификатор: 
А к первому порту мы подключим просто текстовый файлик с одной колонкой, содержащий 1 строчку — тестовое предложение для проверки модели. Это нужно по двум причинам — во-первых мы увидим, что классифкатор реально работает, но, самое главное, это даст Azure Machine Learning информацию о структуре входных данных веб-сервиса, который мы опубликуем — в данном случае он принимает на вход только 1 строковый параметр. Этот текстовый файл может выглядеть вот так, например:
«text» «Очень хороший курс по машинному обучению. Он попроще чем ШАДовский, и не предполагает, что слушатель в совершенстве владеет матаном, линалом и матстатом. Есть даже русский перевод в субтитрах.» В итоге получится вот так:

Убедитесь, щелкнув Visualize на выходе этого датасета, что в нем имеется только одна колонка с именем «text».
Теперь давайте напишем R-скрипт для использования классификатора:
library («RTextTools») library («stringr») library («tm») library («e1071»)
# Загружаем с первого входа данные для анализа, а со второго — обученный классификатор data <- maml.mapInputPort(1) serializedObj <- maml.mapInputPort(2)
# Десериализуем объект классификатора classifier <- unserialize(as.raw(serializedObj$clsfr))
# Cоздаем матрицу документ-термин из входных данных doc <- data$text dtm <- create_matrix(doc , language="russian" , minWordLength = 4 , maxWordLength = 10, , stemWords = FALSE , removeNumbers = TRUE , removeSparseTerms = 0 ) mat = as.matrix(dtm)
# Анализируем тональность predicted <- predict(classifier, mat)
# Преобразуем результат в DataFrame result <- as.data.frame(predicted)
# Выдаем на выходной порт maml.mapOutputPort («result»); Запустим эксперимент и визуализируем результат — у меня получилось -1, хотя текст в целом положительный. Это говорит о невысоком качестве выборки и необходимости использовать более сложные подходы. У нас на хакатоне точность получалась порядка 72%.
Далее необходимо установить входную точку веб-сервиса — кликните на первом входе блока R-script и выберите Set as Publish Input. Точно так же установите и выход: щелкните на выходной точке «Result Dataset» и выберите Set as Publish Output. Теперь можно наконец-то опубликовать веб-сервис — щелкните Publish Web Service на панели внизу (если эта кнопка недоступна, просто запустите эксперимент, после его выполнения она активируется). После подтверждения вас перебросит на страницу свежеопубликованного веб сервиса:
Отсюда можно перейти на сгенерированную страницу помощи веб-сервиса — для этого щелкните на API Help Page в строке REQUEST/RESPONSE. На этой странице содержится исчерпывающая информация по использованию веб-сервиса, даже примеры кода на разных языках. Давайте попробуем осуществить первый запрос — используя свой любимый REST-клиент, отправьте сервису JSON следующего вида:
{ «Id»: «score00001», «Instance»: { «FeatureVector»: { «text»: «С подругой проще в тыщу раз, смахнуть слезу с усталых глаз…С ней хочешь плач, а хочешь смейся, а хочешь…в стельку с ней напейся» }, «GlobalParameters»: {} } } В ответ нам придет:
[»-1»] Заключение Вот и все! Как видите, использовать Azure Machine Learning очень просто, хотя на данный момент и присутствуют некоторые проблемы. Но, как и Azure в целом, Azure ML очень быстро развивается, и, надеюсь, скоро не будет нужды во всех этих обходных трюках, а баги исчезнут.В заключение, вот две полезные ссылки:
Быстрый старт Azure Machine Learning: http://habrahabr.ru/company/microsoft/blog/236823/ Центр Machine Learning на сайте Azure: http://azure.microsoft.com/en-us/documentation/services/machine-learning/
