Анализ производительности запросов в ClickHouse. Доклад Яндекса
Что делать, если ваш запрос к базе выполняется недостаточно быстро? Как узнать, оптимально ли запрос использует вычислительные ресурсы или его можно ускорить? На последней конференции HighLoad++ в Москве я рассказал об интроспекции производительности запросов — и о том, что даёт СУБД ClickHouse, и о возможностях ОС, которые должны быть известны каждому.

Каждый раз, когда я делаю запрос, меня волнует не только результат, но и то, что этот запрос делает. Например, он работает одну секунду. Много это или мало? Я всегда думаю:, а почему не полсекунды? Потом что-нибудь оптимизирую, ускоряю, и он работает 10 мс. Обычно я доволен. Но все-таки я стараюсь в этом случае сделать недовольное выражение лица и спросить: «Почему не 5 мс?» Как можно выяснить, на что тратится время при обработке запроса? Можно ли его в принципе ускорить?
Обычно скорость обработки запроса — простая арифметика. Мы написали код — наверное, оптимально — и в системе у нас есть некоторое устройство. У устройств есть технические характеристики. Например, скорость чтения из L1-кэша. Или количество случайных чтений, которые может делать SSD. Мы всё это знаем. Нам нужно взять эти характеристики, сложить, вычесть, умножить, поделить и свериться с ответом. Но это в идеальном случае, такого почти не бывает. Почти. На самом деле в ClickHouse такое иногда бывает.
Рассмотрим тривиальные факты о том, какие устройства и какие ресурсы есть в наших серверах.

Процессор, память, диск, сеть. Я специально упорядочил эти ресурсы таким образом, начиная от самых простых и удобных для рассмотрения и оптимизации и заканчивая самыми неудобными и сложными. Например, я выполняю запрос и вижу, что моя программа вроде бы упирается в CPU. Что это значит? Что я найду там какой-нибудь внутренний цикл, функцию, которая чаще всего выполняется, перепишу код, перекомпилирую, и раз — моя программа работает быстрее.
Если тратится слишком много оперативки, то все чуть-чуть сложнее. Нужно перепридумать структуру данных, ужать какие-то биты. В любом случае я перезапускаю мою программу, и она тратит меньше оперативки. Правда, зачастую это в ущерб процессору.
Если у меня все упирается в диски, то это тоже сложнее, потому что я могу изменить структуру данных на диске, но придётся эти данные потом переконвертировать. Если я сделаю новый релиз, людям придётся делать какую-то миграцию данных. Получается, диск — уже существенно сложнее, и лучше думать об этом заранее.
А сеть… я очень не люблю сеть, потому что зачастую абсолютно непонятно, что в ней происходит, особенно если это сеть между континентами, между дата-центрами. Там что-то тормозит, и это даже не ваша сеть, не ваш сервер, и вы ничего не можете сделать. Единственное, вы можете заранее продумать, как будут передаваться данные и как минимизировать взаимодействие по сети.
Бывает, что ни один ресурс в системе не утилизирован, а программа просто чего-то ждёт. На самом деле это очень частый случай, потому что система у нас распределённая, да и всяких процессов и потоков там может быть много, и обязательно какой-то ждёт другого, и все это нужно как-то увязать друг с другом, чтобы правильно рассматривать.

Самое простое — посмотреть на утилизацию ресурсов, на какую-то численную величину. Например, вы запускаете какой-нибудь top, и он пишет: процессор — 100%. Или запускаете iostat, и он пишет: диски — 100%. Правда, зачастую этого недостаточно. Один человек увидит, что программа упирается в диски. Что можно сделать? Можно просто отметить это и пойти отдыхать, решить, что всё, ничего нельзя оптимизировать. Но на самом деле каждое из устройств внутри себя довольно сложное. У процессора куча вычислительных устройств для разных видов операций. У дисков может быть RAID-массив. Если SSD, то там внутри свой процессор, свой контроллер, который делает непонятно что. И одной величины — 50% или 100% — недостаточно. Основное правило: если вы видите, что какой-то ресурс утилизирован на 100%, не надо сдаваться. Зачастую все равно можно что-то улучшить. Но бывает и наоборот. Скажем, вы видите, что утилизация 50%, но ничего сделать не удастся.
Давайте рассмотрим это подробнее.

Самый простой и удобный ресурс — процессор. Вы смотрите top, там написано, что процессор — 100%. Но стоит иметь в виду, что это не процессор 100%. Программа top не знает, что там делает процессор. Она смотрит с точки зрения планировщика ОС. То есть сейчас какой-то поток программы выполняется на процессоре. Процессор что-то делает, и тогда будет показано 100%, если это усреднено за какое-то время. В то же время процессор что-то делает, и непонятно, насколько эффективно. Он может выполнять разное количество инструкций за такт. Если инструкций мало, то сам процессор может чего-то ждать, например, загрузки данных из памяти. При этом в top будет отображаться то же самое — 100%. Мы ждём, пока процессор выполняет наши инструкции. А что он там внутри делает — неясно.
Наконец, бывают просто грабли, когда вы думаете, что ваша программа упирается в процессор. Это действительно так, но у процессора почему-то понижена частота. Тут может быть много причин: перегрев, ограничение мощности. Почему-то в дата-центре бывает ограничение мощности по питанию, или просто может быть включено энергосбережение. Тогда процессор будет постоянно переключаться с более высокой частоты на более низкую, но если у вас нагрузка непостоянная, то этого не хватит и в среднем код будет выполняться медленнее. Настоящую частоту процессора смотрите в turbostat. Проверить, не было ли перегрева, можно в dmesg. Если что-нибудь такое было, там будет написано: «Перегрев. Частота понижена».
Если интересует, сколько внутри было кэш-промахов, сколько инструкций выполняется за такт, — используйте perf record. Записывайте какой-то сэмпл работы программы. Дальше можно будет это посмотреть с помощью perf stat или perf report.

И наоборот. Допустим, вы смотрите в top и процессор утилизирован менее чем на 50%. Допустим, что у вас в системе 32 виртуальных процессорных ядра, а физических — 16. На процессорах Intel так и есть, потому что hyper-threading двойной. Но это не значит, что дополнительные ядра бесполезны. Все зависит от нагрузки. Предположим, у вас хорошо оптимизированы операции какой-нибудь линейной алгебры или вы вычисляете хэши для майнинга биткоинов. Тогда код будет чёткий, будет выполняться много инструкций за такт, кэш-промахов не будет, branch mispredictions — тоже. И hyper-threading никак не помогает. Он помогает, когда у вас одно ядро чего-то ждёт, а другое одновременно может выполнять инструкции другого потока.
В ClickHouse встречаются обе ситуации. Например, когда мы делаем агрегацию данных (GROUP BY) или фильтрацию по множеству (IN subquery), то у нас будет хэш-таблица. Если хэш-таблица не помещается в процессорный кэш, возникнут кэш-промахи. Этого практически никак не избежать. В этом случае hyper-threading будет нам помогать.
По умолчанию ClickHouse использует только физические процессорные ядра, без учёта hyper-threading. Если вы знаете, что ваш запрос может получить преимущества от hyper-threading — просто увеличьте количество потоков в два раза: SET max threads = 32, и ваш запрос будет выполниться быстрее.
Бывает, что процессор прекрасно используется, но вы смотрите на график и видите, например, 10%. А график у вас, например, пятиминутный в худшем случае. Даже если односекундный, все равно там какая-то усреднённая величина. На самом деле у вас постоянно были запросы, они выполняются быстро, за 100 мс каждую секунду, и это нормально. Потому что ClickHouse старается выполнить запрос настолько быстро, насколько возможно. Он вовсе не старается целиком и постоянно использовать и перегревать ваши процессоры.

Давайте подробнее, немного сложный вариант. Есть запрос с выражением in subquery. Внутри подзапроса у нас 100 млн случайных чисел. И мы просто по этому результату фильтруем.
Видим такую картину. Кстати, кто скажет, с помощью какого инструмента я вижу эту замечательную картину? Абсолютно верно — perf. Я очень рад, что вы это знаете.
Я открыл perf, думая, что сейчас всё пойму. Открываю ассемблерный листинг. Там у меня написано, как часто выполнение программы было на определённой инструкции, то есть как часто там был instruction pointer. Здесь числа в процентах, и написано, что почти 90% времени выполнялась инструкция test %edx, %edx, то есть проверка четырёх байт на ноль.
Спрашивается: почему процессор может так много времени выполнять инструкцию простого сравнения четырёх байт с нулём? (ответы из зала…) Тут нет остатка от деления. Тут битовые сдвиги, потом есть инструкция crc32q, но на ней как будто instruction pointer никогда не бывает. И генерации случайных чисел нет в этом листинге. Была отдельная функция, и она очень хорошо оптимизирована, не тормозит. Здесь тормозит кое-что другое. Выполнение кода как бы останавливается на этой инструкции и тратит кучу времени. Idle loop? Нет. Зачем мне вставлять пустые циклы? Кроме того, если бы я вставил Idle loop, это тоже было бы видно в perf. Тут нет и деления на ноль, тут просто сравнение с нулём.
У процессора есть конвейер, он может выполнять несколько инструкций параллельно. И когда instruction pointer находится в каком-то месте, это вовсе не значит, что он выполняет именно эту инструкцию. Может быть, он ждёт каких-то других инструкций.
У нас есть хэш-таблица для проверки того, что какое-то число встречается в каком-то множестве. Для этого мы делаем lookup в памяти. Когда мы делаем lookup в памяти, то у нас кэш-промах, потому что хэш-таблица содержит 100 млн чисел, она ни в какой кэш гарантированно не помещается. Значит, для выполнения инструкции проверки на ноль эти данные уже должны быть загружены из памяти. А мы ждём, пока они будут загружены.

Теперь следующий ресурс, чуть более сложный — диски. Дисками иногда называют и SSD, хотя это не совсем корректно. В этот пример SSD тоже будет включены.
Мы открываем, например, iostat, он показывает утилизацию 100%.
На конференциях часто бывает, что докладчик выходит на сцену и говорит с пафосом: «Базы данных всегда упираются в диск. Поэтому мы сделали базу данных in-memory. Она не будет тормозить». Если человек к вам подходит и говорит так, можете смело его посылать. Будут какие-то проблемы — скажете, я разрешил. :)
Допустим, программа упирается в диски, утилизация 100. Но это, конечно, не значит, что мы используем диски оптимально.
Типичный пример — когда у вас просто много случайного доступа. Даже если доступ последовательный, то вы просто последовательно читаете файл, но все равно это может быть более или менее оптимально.
Например, у вас RAID-массив, несколько устройств — скажем, 8 дисков. И вы просто читаете последовательно без read ahead, с размером буфера 1 МБ, а размер chunk в вашем stripe в RAID — тоже 1 МБ. Тогда каждое чтение у вас будет с одного устройства. Или, если не выровненное, с двух устройств. Там куда-нибудь пойдёт полмегабайта, куда-нибудь ещё полмегабайта и так далее — диски будут по очереди использоваться: то один, то другой, то третий.
Нужно, чтобы был read ahead. Или, если у вас O_DIRECT, увеличьте размер буфера. То есть правило такое: 8 дисков, размер chunk 1 МБ, ставьте размер буфера минимум 8 МБ. Но это будет работать оптимально, только если чтение выровнено. А если не выровнено, то там сначала будут лишние кусочки, и надо побольше поставить, доумножать ещё на несколько.
Или, например, у вас RAID 10. С какой скоростью можно читать с RAID 10 — допустим, из 8 дисков? Какое будет преимущество? Четырёхкратное, потому что там есть mirror, или восьмикратное? На самом деле это зависит от того, каким образом RAID создан, с каким расположением chunks в stripes.
Если вы используете mdadm в Linux, там можно задать near layout и far layout, причём near лучше для записи, far — для чтения.
Я всегда рекомендую использовать именно far layout, потому что когда вы делаете запись в аналитическую базу данных, обычно это не так критично по времени — пусть даже там намного больше записи, чем чтения. Это делается каким-то фоновым процессом. Но когда вы выполняете чтение, нужно выполнить его как можно быстрее. Так что лучше оптимизировать RAID для чтения, выставив far layout.
Как назло, в Linux mdadm по умолчанию выставит вам near layout, и вы получите только половину производительности. Таких граблей очень много.
Ещё одни ужасные грабли — RAID 5 или RAID 6. Там все хорошо масштабируется по последовательным чтениям и записям. В RAID 5 кратность будет «количество устройств минус один». Это хорошо масштабируется даже по случайным чтениям, но плохо масштабируется по случайным записям. Делаете запись в какое-нибудь одно место, и вам нужно прочитать со всех остальных дисков данные, поксорить их (XOR — прим. ред.) и записать в другое место. Для этого используется некий кэш страйпов, ужасные грабли. В Linux он по умолчанию такой, что вы создаёте RAID 5 и он у вас будет тормозить. И вы будете думать, что RAID 5 всегда тормозит, потому что это ведь и так понятно. Но на самом деле причина в неправильной настройке.
Ещё один пример. Вы выполняете чтение с SSD, и вы купили себе хороший SSD, там в спецификации написано — 300 тыс. случайных чтений в секунду. А у вас почему-то не получается. И вы думаете — да врут они всё в своих спецификациях, не бывает такого. Но все эти чтения надо делать параллельно, с максимальной степенью параллелизма. Единственный способ сделать это достаточно оптимально — использовать асинхронный ввод-вывод, который реализуется с помощью системных вызовов io_submit, io_getevents, io_setup и т. д.
Кстати, данные на диске, если вы их храните, всегда надо сжимать. Приведу пример из практики. Один человек обратился к нам в чат поддержки ClickHouse и говорит:
— ClickHouse сжимает данные. Я смотрю, он упирается в процессор. У меня очень быстрые диски SSD NVMe, у них скорость чтения несколько гигабайт в секунду. Можно ли в ClickHouse как-то отключить сжатие?
— Нет, никак нельзя, — говорю я. — Вам нужно, чтобы данные хранились сжатыми.
— Давайте я законтрибьючу, просто будет другой алгоритм сжатия, который ничего не делает.
— Легко. Впишите в эту строчку кода эти буквы.
— Действительно, все очень просто, — ответил он через день. — Я сделал.
— Насколько изменилась производительность?
— Не удалось протестировать, — написал он ещё через день. — Данных стало слишком много. Они теперь не помещаются на SSD.
Давайте теперь посмотрим, как может выглядеть чтение с диска. Запускаем dstat, он показывает скорость чтения.
Вот столбец read — 300 МБ/с. Мы читаем с дисков. Много это или мало — не знаю.
Теперь я запускаю iostat, чтобы это проверить. Тут видна разбивка по устройствам. У меня есть RAID, md2, и восемь жёстких дисков. У каждого из них показана утилизация, она даже не доходит до 100% (50–60%). Но самое главное, что c каждого диска я читаю всего лишь со скоростью 20–30 МБ/с. А я еще с детства запомнил правило, что с жёсткого диска можно читать где-то 100 МБ/с. Почему-то это до сих пор почти не изменилось.
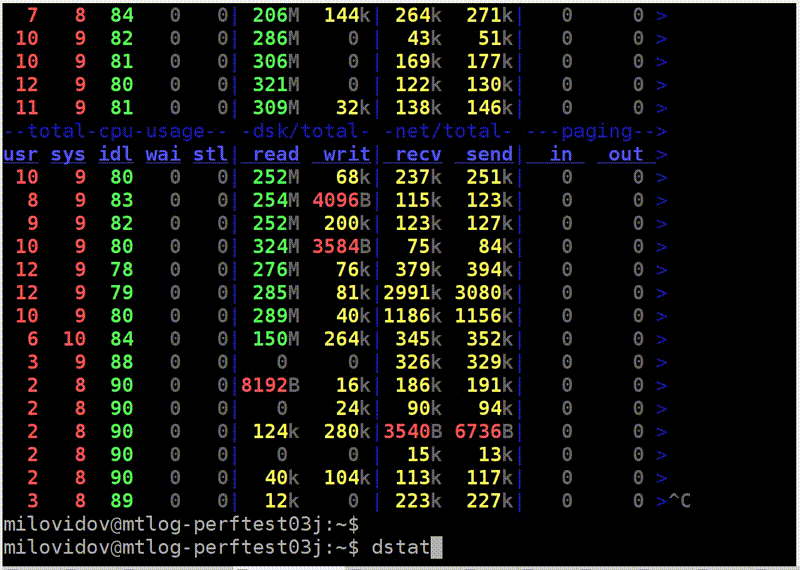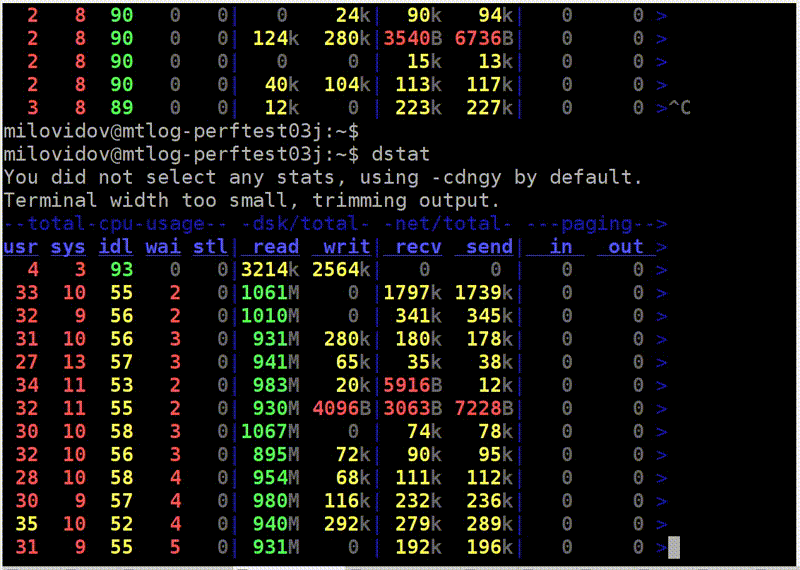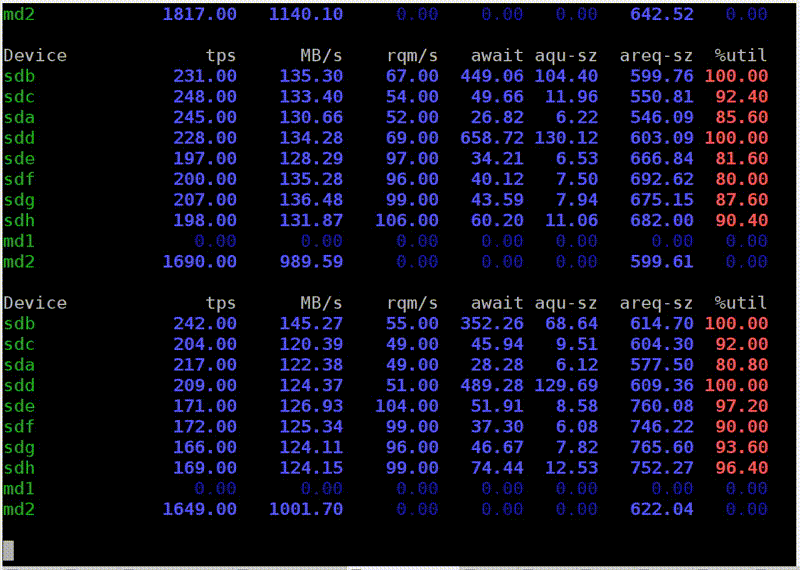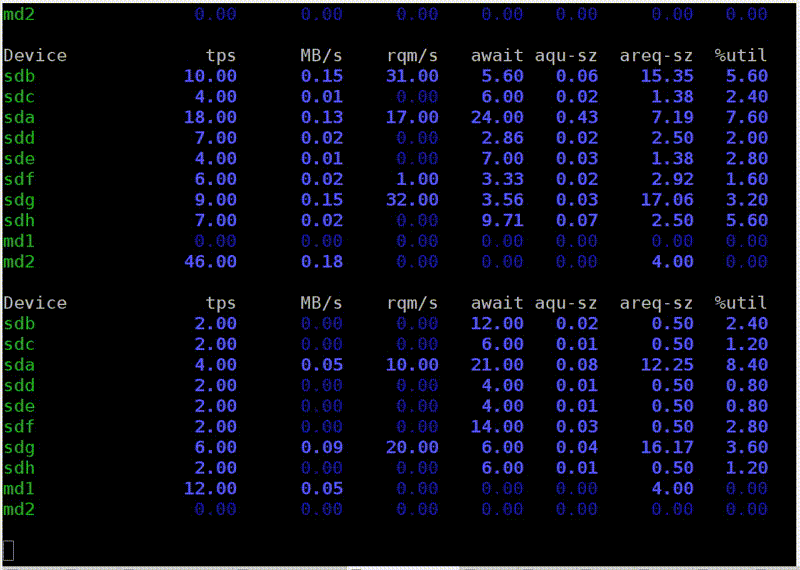
Вот другой пример. Чтение более оптимальное. Я запускаю dstat, и у меня скорость чтения с этого RAID 5 из восьми дисков — 1 ГБ/с. Что же показывает iostat? Да, почти 1 ГБ/с.
Теперь диски наконец-то загружены на 100%. Правда, почему-то два на 100%, а остальные на 95%. Наверное, они все-таки немножко разные. Но с каждого из них я читаю 150 МБ/с, еще круче, чем может быть. В чем разница? В первом случае я читал с недостаточным размером буфера недостаточными кусочками. Все просто, я вам рассказываю прописные истины.
Кстати, если вы думаете, что данные все-таки не нужно сжимать для аналитической базы данных, то есть доклад с конференции HighLoad++ Siberia (хабрастатья по мотивам доклада — прим. ред.). Организаторы решили самые хардкорные доклады в Новосибирске сделать.

Следующий пример — память. Продолжаем прописные истины. Во-первых, в Linux никогда не смотрите, что показывает free. Для тех, кто смотрит, специально создали сайт linuxatemyram.com. Зайдите, там будет разъяснение. На количество виртуальной памяти тоже смотреть не нужно, потому что какая разница, сколько адресного пространства выделила программа? Смотрите на то, сколько использовано физической памяти.
И ещё одни грабли, с которыми даже непонятно как бороться. Запомните: то, что аллокаторы зачастую не любят отдавать память системе — нормально. Они сделали mmap, а munmap уже не делают. Память в систему не вернётся. Программа думает — я лучше знаю, как я буду использовать память. Оставлю-ка я её себе. Потому что системные вызовы mmap и munmap довольно медленные. Изменение адресного пространства, сброс TLB-кэшей у процессора — лучше этого не делать. Впрочем, в ОС все-таки есть возможность освобождать память правильно с помощью системного вызова madvise. Адресное пространство останется, но физически память может быть выгружена.
И никогда не включайте swap на продакшен-серверах с базами данных. Вы думаете — не хватает памяти, включу swap. После этого запрос перестанет работать. Он будет трешиться бесконечное время.

С сетью тоже типичные грабли. Если вы каждый раз создаёте TCP-соединение, то требуется некоторое время, прежде чем будет выбран правильный размер окна, поскольку TCP-протокол не знает, с какой скоростью потребуется передавать данные. Он к этому адаптируется.
Или представьте — вы передаёте файл, а у вас в сети большая latency и ещё потеря пакетов приличная. Тогда вообще неочевидно, правильно ли использовать TCP для передачи файлов. Я думаю, что неправильно, поскольку TCP гарантирует последовательность. С другой стороны, вы могли бы передать одновременно одну половину файла и другую. Использовать хотя бы несколько TCP-соединений или вообще не использовать TCP для передачи данных. Скажем, если качать данные, фильмы и сериалы торрентами, там TCP может и не использоваться. И данные нужно сжимать.
Если у вас в пределах стойки 100-гигабитная сеть, можно не сжимать. Но если у вас 10 гигабит между дата-центрами, особенно между Европой и США, то кто знает, как ваши байты будут ползать под океаном. Сжимайте их. Пусть ползёт меньше байт.

Все видели эту картинку? Если в системе все тормозит — у вас есть необходимые инструменты. Вы начнёте их использовать, начнёте разбираться с проблемой и, по опыту, обнаружите 10 других проблем. Эти инструменты достаточно мощные, чтобы занять вас на очень долгое время.

Когда вам говорят: «с моей базой что-то не так» — вы заходите на сервер и запускаете подряд все эти инструменты. Из них особенно можно отметить iotop, он показывает, сколько каждый процесс на самом деле читает и пишет на диски, сколько там iops.
Но даже в таких простых инструментах есть маленькие хитрости, о которых не каждый знает. Давайте посмотрим.
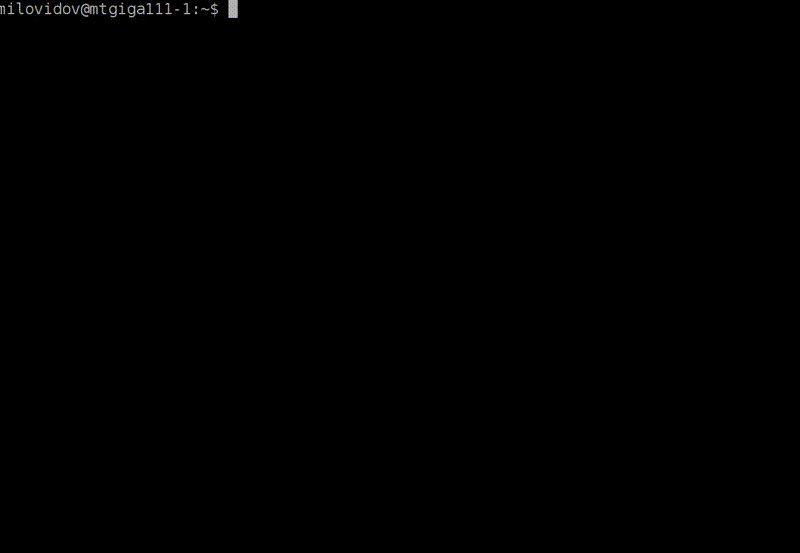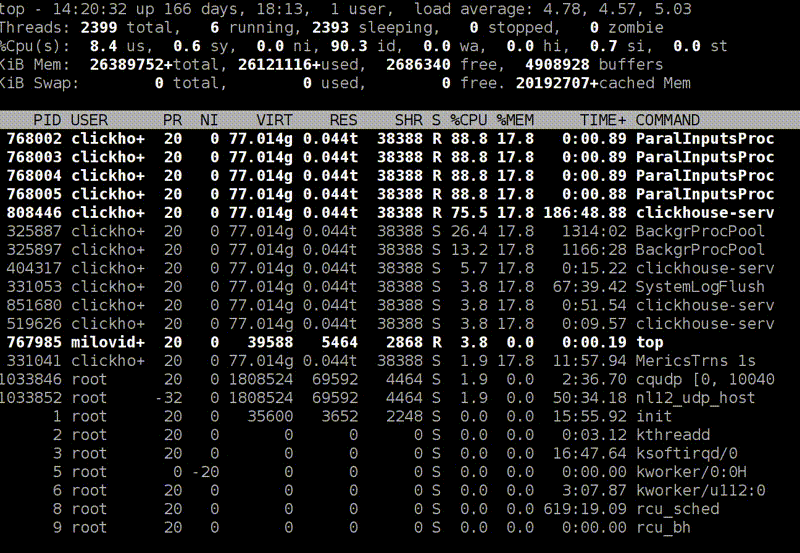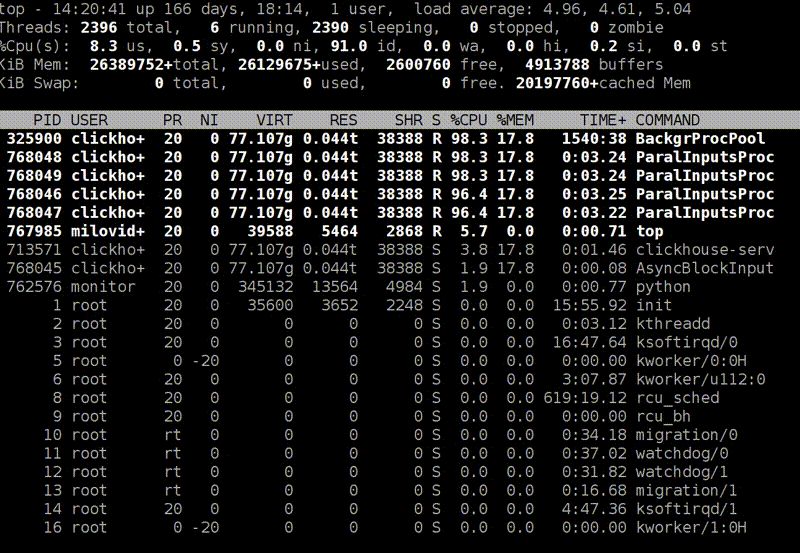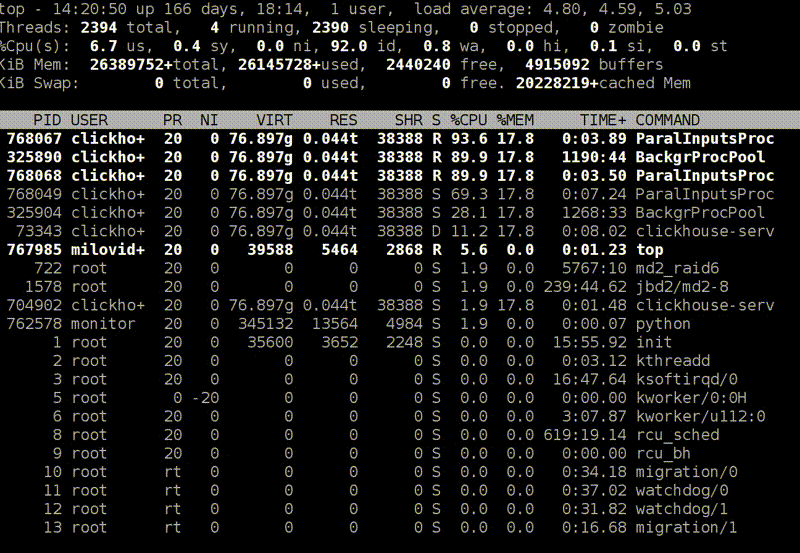
Я запускаю top на продакшен-сервере, и он показывает, что clickHouse-server использует сколько-то ресурсов процессора, сколько-то процессорных ядер. Я не знаю, что происходит внутри, но могу нажать Shift+H, и он покажет разбивку по потокам. Чтобы вам было удобнее, в ClickHouse потоки поименованы. Вот есть ParalInputsProc, параллельная обработка запросов. Или BackgrProcPool — то есть merges или скачивание данных для репликации. Теперь лучше понятно, на что тратятся отдельные процессорные ядра и что делают отдельные процессорные потоки.
Почему имена такие дурацкие? Если вы читали исходники ClickHouse, то знаете, что я такое не люблю. Я бы назвал BackgroundProcessingPool. Но тут максимум можно 15 байт. 16 минус 1, где 1 — это нулевой байт. Почему 16? Мне представляется, что разработчики ядра Linux — крепкие бородатые профессионалы, которые решили:»16 байт. Так лучше». :)
Вот другой пример с использованием замечательной программы clickhouse-benchmark. Она входит в обычную поставку вместе с clickhouse-client. Это не отдельный бинарник, а тот же clickhouse-client, только симлинк. С помощью него можно взять какую-нибудь ленту запросов или один запрос и устроить нагрузочное тестирование. Эти запросы будут непрерывно выполняться с использованием фиксированного количества соединений и выводить статистику.
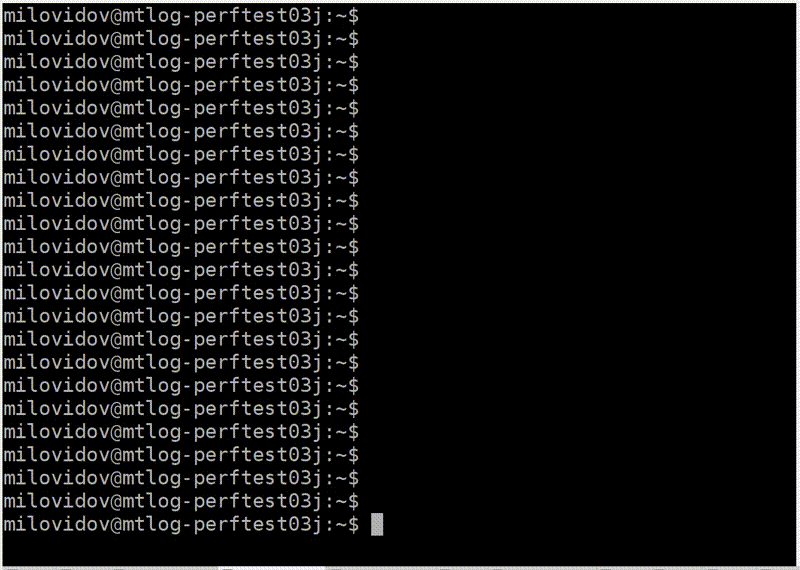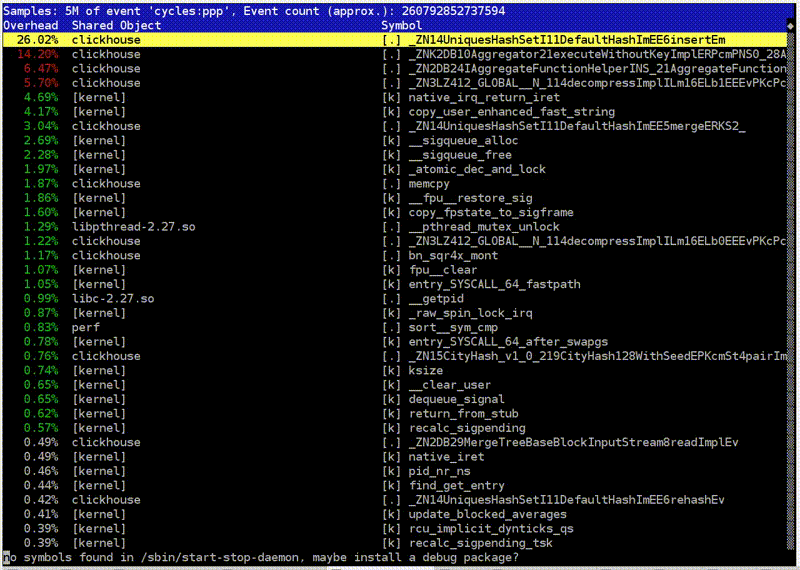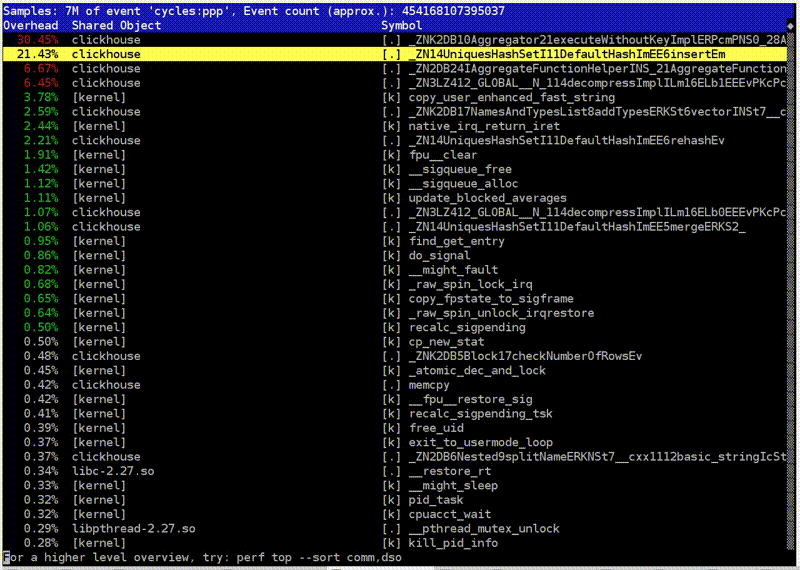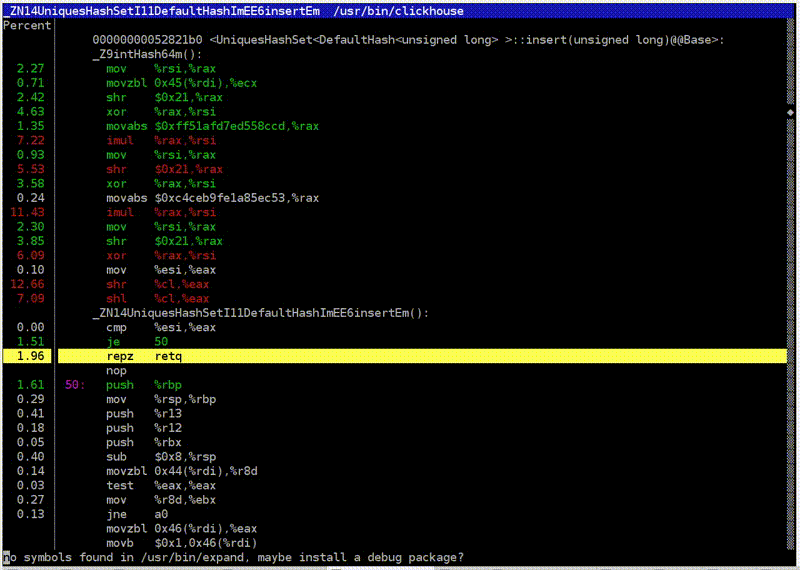
Я беру простой запрос с подсчётом количества уникальных посетителей. Запускаю clickhouse-benchmark, он пишет, сколько у меня запросов в секунду, какие перцентили выполнения, сколько обрабатывается строчек в секунду, и выводит скорость чтения данных после разжатия в мегабайтах в секунду. Я обычно использую его вместе с peft top. Захожу в peft top, и вот у меня разбивка по функциям. Тут видно, что в начале хэш-таблицы находится вставка в некий хэш-сет, предназначенный именно для подсчёта функции uniq: UniquesHashSet. И агрегация. Я могу зайти внутрь, посмотреть ассемблерный листинг. Обычно там абсолютно ничего не понятно, но развлечение хорошее.
Хотя вот, например, вызов функции по указателю. На самом деле я хотел посмотреть другое — вставку в хэш-таблицу. Тут есть целочисленные умножения, битовые сдвиги, XOR и какие-то длинные константы. Это вычисление хэш-функции. То есть я мог бы поставить туда какую-нибудь более простую хэш-функцию. Но я не могу так сделать, потому что именно в указанном куске кода это чуть ли ни самая простая хэш-функция.
Я мог бы поставить туда, скажем, crc32q. Но она уже используется в других местах в коде, и если я поставлю её ещё и сюда, то будет нежелательная корреляция хэш-функций друг с другом, что приведёт к чудовищным коллизиям в хэш-таблице и замедлению программы.
Я рассказал про разные ресурсы, но все перечисленное применимо не только к ClickHouse. Вы можете использовать те же самые правила для любой другой базы данных, смотреть, что происходит внутри. Я же хочу поговорить чисто про ClickHouse.

Начнём с самой базовой вещи. Чтобы посмотреть, какие запросы выполняются — никаких сюрпризов, просто набираете SHOW PROCESSLIST. Просто и понятно. Это то же самое, что SELECT * FROM system processes. Там куча столбцов со всякими системными метриками: потребление памяти, чтение, сколько байт считалось. Можно даже изобразить простой ClickHouse top.
А что вообще делает ClickHouse внутри? Базово он осуществляет выполнение запросов и background-операции. Background-операции — это в основном merges. Если нас интересует, какие merges выполняются, мы просто смотрим SELECT * FROM system.merges.
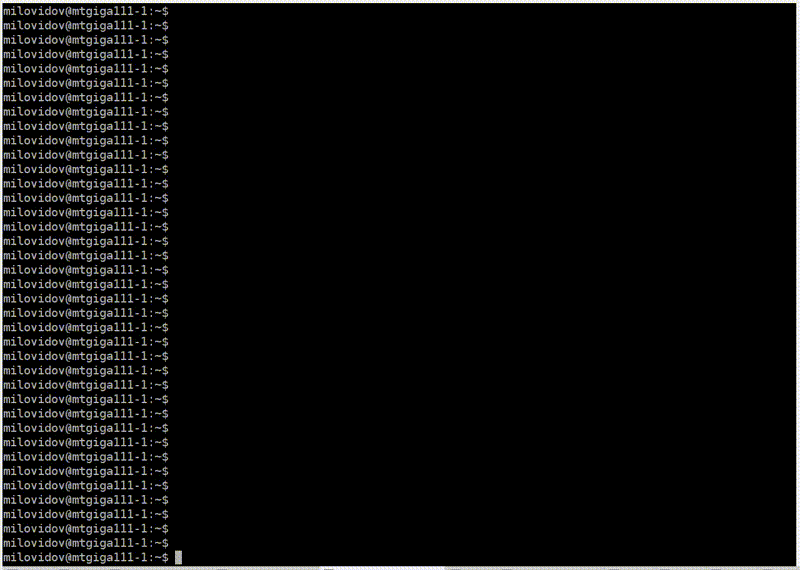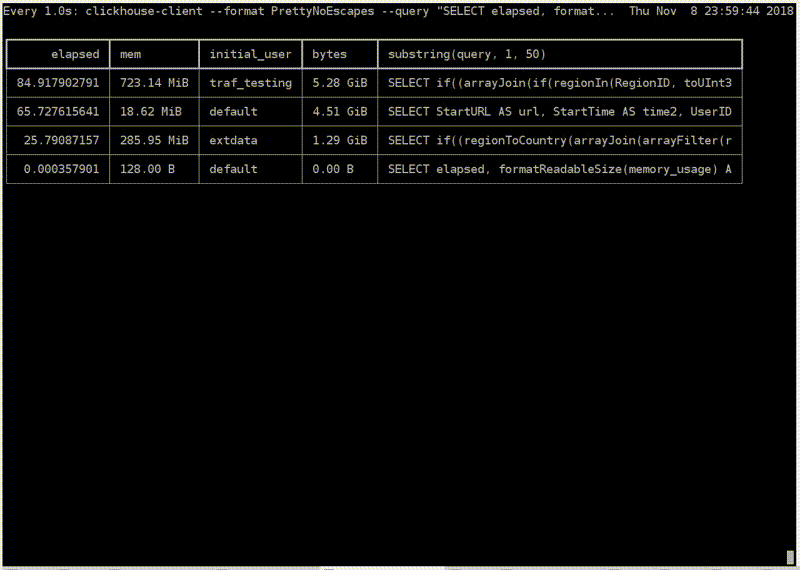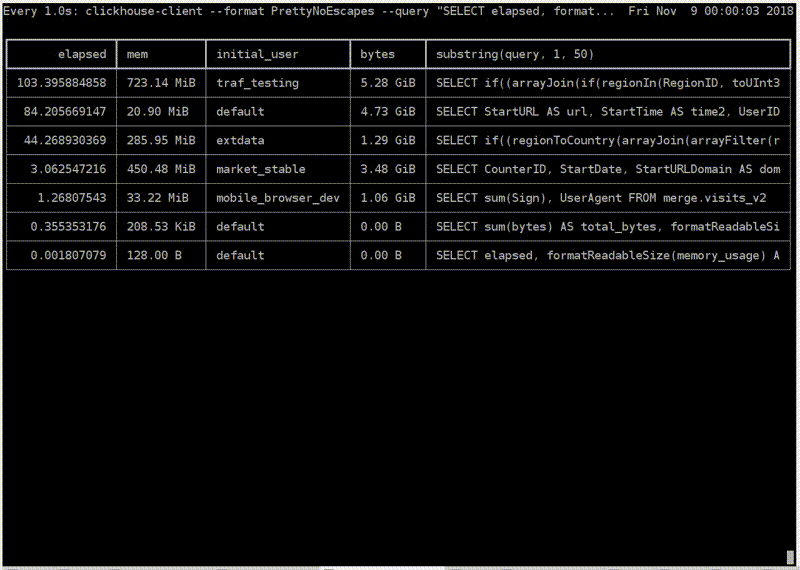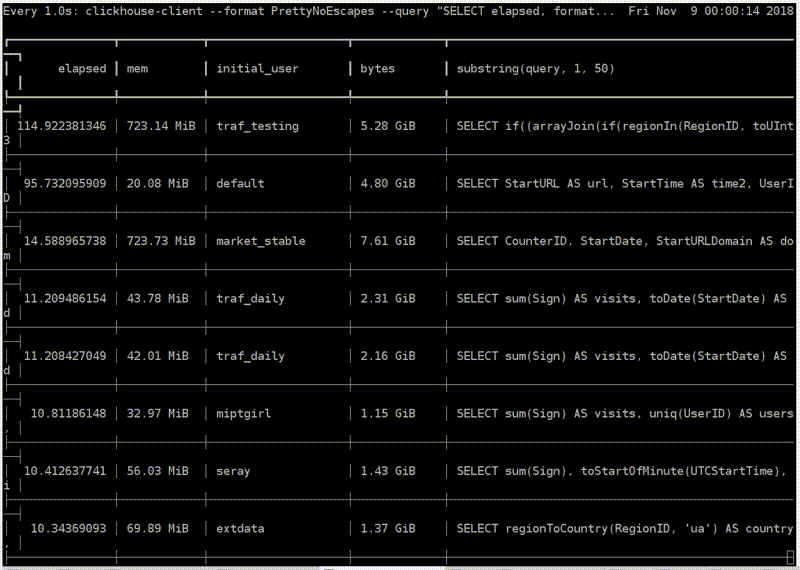
Посмотрим, как это выглядит. Вот продакшен-сервер. Я запускаю магическую команду. Пожалуйста — топ ClickHouse. Это реальный пользователь с реального аналитического сервера. Тут у них некоторые запросы выполняются, о ужас, больше минуты. Кажется, мне надо остановиться и пойти их оптимизировать. Какой-то traf_testing. Что это? На самом деле, эти запросы довольно сильно урезаны по ресурсам, специально чтобы аналитики не мешали интерактивным запросам. Такое в ClickHouse легко обеспечить.

Идём дальше. Хочется не только смотреть, что происходит в текущий момент времени. Допустим, у вас были проблемы, всё остановилось, и вам нужно понять, что в этот момент произошло. Достаточно включить query_log. По умолчанию он выключен по единственной причине — вы не должны беспокоиться о том, что с какого-то сервера вы только читаете, делаете SELECT запросы, но все равно какие-то таблицы записываются. Можно включить query_log на продакшене везде по умолчанию, здесь нет никаких проблем. На наших продакшен-серверах он в обязательном порядке включён. Если хотите отдельно — можно и на сессию, и на запрос включать. Каждый запрос логируется два раза: когда он начал выполняться и когда закончил.
Предположим, вас интересует, что происходит с кусками данных — merge, inserts, скачивание с реплик. Для этого есть системная таблица part_log. Ее можно включить в конфигурационном файле, и она тоже по умолчанию выключена.

Удобно использовать query_log вместе с clickhouse-benchmark. Вы делаете select ленты запросов, которые у вас были, а потом отправляете её в stdin в clickhouse-benchmark.
Или очень удобно по query_log найти какой-нибудь первый тяжёлый запрос, после которого система стала работать недостаточно хорошо.

Часто вам нужно прямо сейчас выполнить запрос, но непонятно, что он делает. Поэтому есть возможность трассировки запросов. Просто выставляете в клиенте SET send_logs_level = 'trace', и получаете логи выполнения со всех серверов, участвующих в обработке запроса.
Посмотрим, как это выглядит. Запрос выполняется, но быстро доходит до 98%. Я хочу понять, что он делает в оставшиеся моменты времени. Это очень просто. Набираю SET send_logs_level = 'trace', начинаю выполнять, и выводится куча мусора. Но наконец-то видно: merging aggregated data, я успел заметить. Именно это он делает в оставшийся 1% времени. Раньше вы о таком даже не думали, а теперь все понятно.
А ещё в этом логе выводится идентификатор запроса, который можно использовать, чтобы найти запрос прямо в query_log.
Давайте посмотрим. SELECT * FROM system.query_log для вот этого запроса. Две записи. Правда, теперь трассировка лишняя, я отключу ее и посмотрю, что вообще есть в этом query_log. Выбрал. Тут всякие метрики выполнения запроса — количество раз, когда файлы были открыты, количество сжатых блоков, количество попаданий в кэш засечек и т. д.

Прямо внутри ClickHouse есть счётчики ресурсов. Самое главное — они собираются глобально для всех запросов и доступны в таблицах system.events, system.metrics и system.asynchronous_metrics. Events — это просто инкрементальные счётчики, показывающие, сколько раз были открыты файлы. 100 раз. Или сколько запросов было выполнено с момента старта программы — 10 штук. А system.metrics — количество одновременных событий прямо сейчас. Например, прямо сейчас одновременно выполняется 10 запросов, которые в сумме используют 10 ГБ памяти.
Таблицу system.asynchronous_metrics я назвал так из вредности, потому что очень сложно набирать. Я принципиальный. Сейчас я сам с трудом каждый раз это набираю — тоже из вредности. Так вот, system.asynchronous_metrics — те метрики, которые просто собираются с какой-то периодичностью. Скажем, раз в минуту.
Все перечисленные счётчики доступны не только глобально, но и на каждый запрос. То есть вы можете посмотреть SHOW PROCESSLIST и найти там счётчики для конкретного запроса. Посмотрите query_log, и там тоже будут счётчики для выполненных запросов.

Посмотрим, какие они бывают. Есть те, которые собирает сама программа. Например, количество открытий файлов. Мы же знаем, когда мы открываем файл, и именно в этот момент инкрементируем счётчик. А есть те, которые собираются из ядра Linux, гораздо более продвинутые. Вот что ядро Linux думает про нашу программу. Я даже не хочу думать, что оно думает про нас. Оно считает, сколько байт мы прочитали. И тут есть совершенно разные метрики.
Скажем, OSReadChars и OSReadBytes. Чем они отличаются? Первая показывает, сколько мы прочитали байт из файловой системы, причём часть байт могла быть прочитана из кэша, а не с реального диска. Вторая метрика показывает, сколько реальных байт было прочитано с блочных устройств. Дело в том, что ОС старается реализовать кэш максимально прозрачно, чтобы мы просто читали из файлов и не знали, откуда оно читается. К счастью, из ядра все-таки можно напрямую получить более подробные метрики, которые нам просто так не дают.
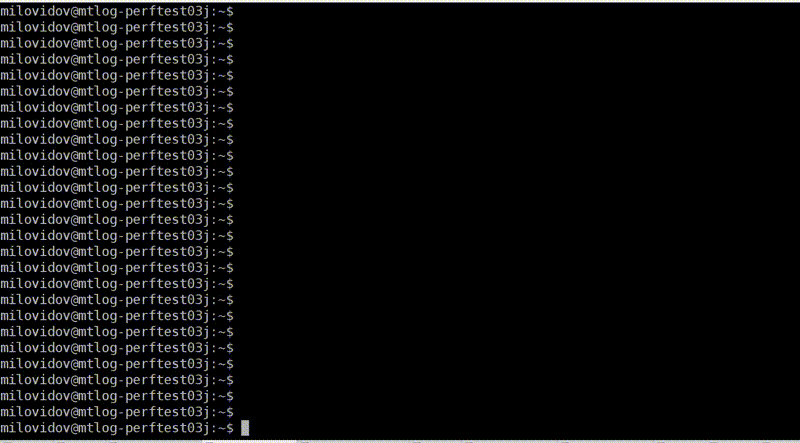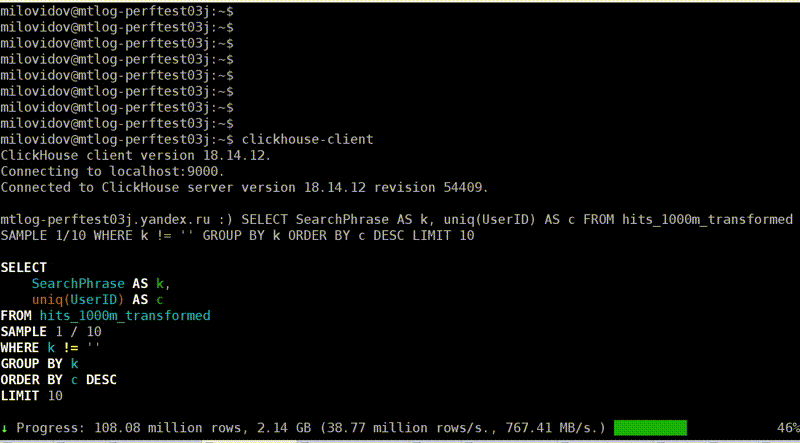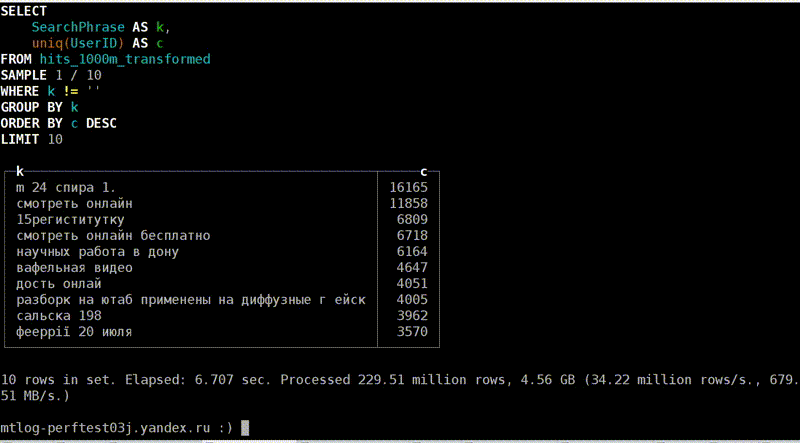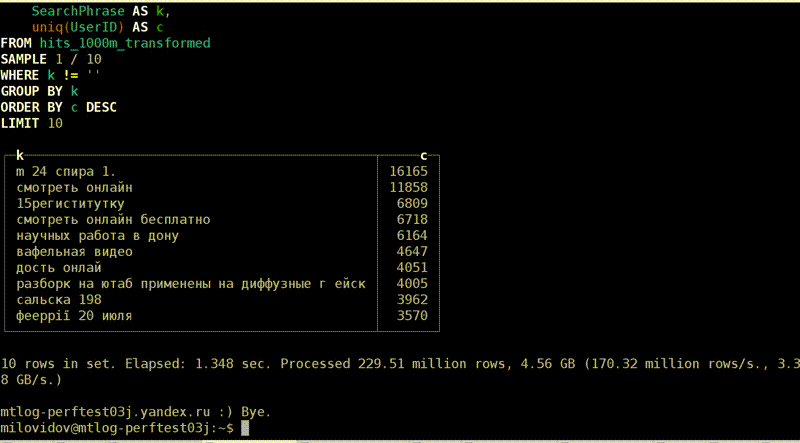
Посмотрим, как это выглядит. Вот мы выполняем какой-то запрос. Вроде ничего, почти 40 млн строк в секунду, 6,7 секунды. Нормально. Кстати, данные в тестовых таблицах фейковые, я их специально испортил. Выглядит, конечно, странно.
Выполняем то же самое второй раз, теперь всего лишь 1,3 секунды, в 5 раз меньше. Почему? Думаю, ответ очевиден для всех — потому что второй раз использовался page cache. Но как мы это можем понять из наших счётчиков?
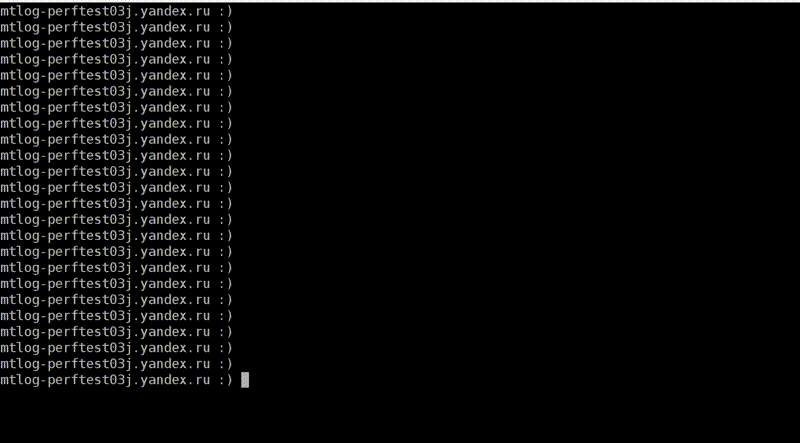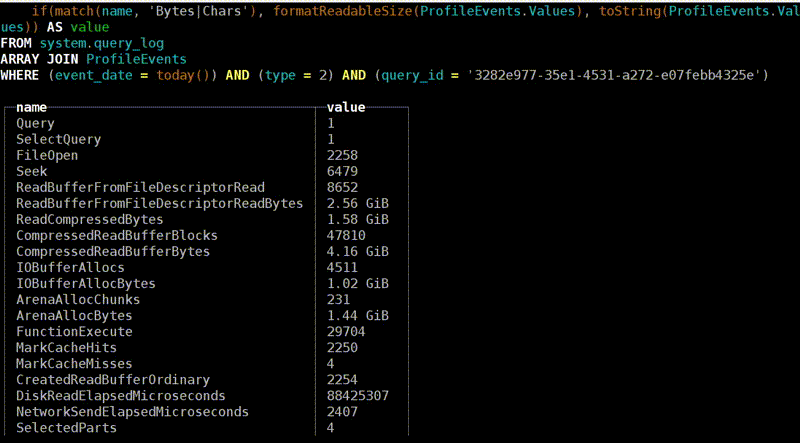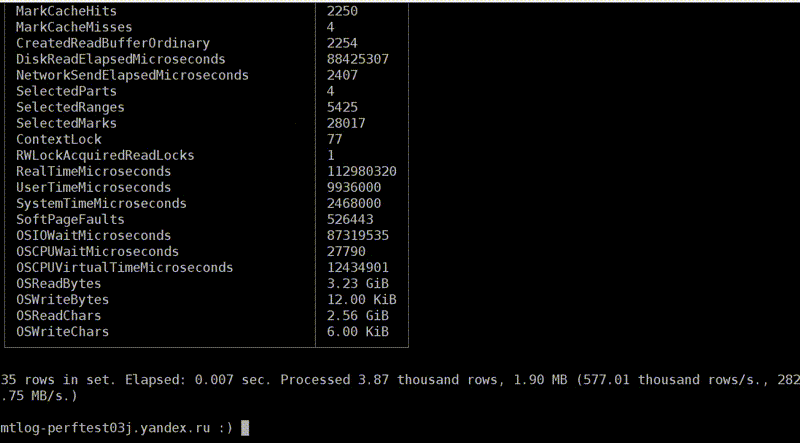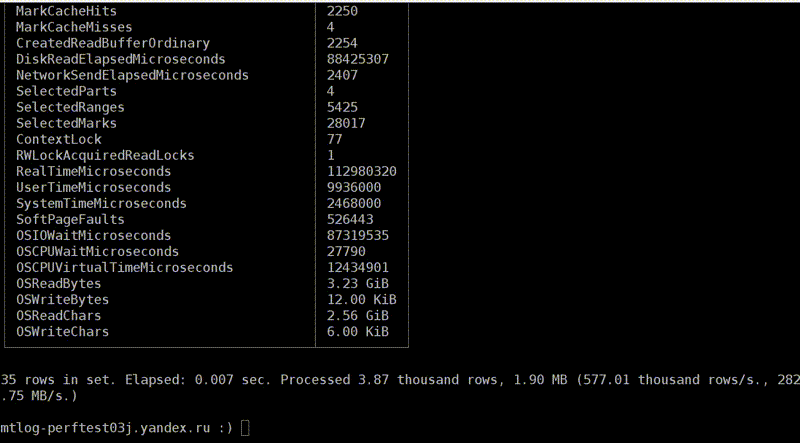
Выполним не очень простой запрос. Вот все наши метрики для первого запроса. Например, там было написано, что при выполнении запроса был выполнен один запрос. Это для полноты. Но есть и полезные метрики: с диска было прочитано 3,2 ГБ, из файловой системы — 2,5 ГБ. Кстати, интересно, что на этот раз с диска было прочитано больше, чем мы хотели. Почему? Во-первых, гипотеза: есть read ahead. То есть когда мы захотели прочитать мало данных, ОС на всякий случай прочитала больше — вдруг пригодится? Во-вторых, с диска мы можем читать некоторыми минимальными секторами — 4 КБ или, скажем, 512 KB. Точное значение зависит от настроек. И если не выровнено, то прочитается немножко лишних хвостиков. Но скорее всего, разница из-за read ahead.

Это у нас был первый запрос. Для второго запроса метрики будут другими. По этим данным чётко видно, что запрос стал выполняться быстрее. Отличается, например, ReadBytes — количество байт, которые реально прочитаны с диска. Было 3 ГБ, а стало всего лишь 3 МБ. Не знаю, почему не ноль, но это почти ноль.
Другая интересная метрика — IOWait. 87 секунд. Запрос выполнялся почти 7 секунд, а IOWait — 87. Почему? Верно — у нас много потоков. Метрика считается на каждый поток. Каждый поток ждал, пока ему дадут данные с диска, и в сумме получилось 87 секунд. Во второй раз мы почти не ждали, прошли какие-то миллисекунды.
Ещё одна метрика — CPUWait. Это не время использования процессора, а время, когда наш поток был готов к тому, чтобы ОС начала его выполнять на процессоре. ОС почему-то не давала ему выполняться — возможно, было больше потоков. То есть мы видим голодание CPU. Но в данном примере потоки не голодают по CPU. Всегда когда они готовы выполнять какие-то инструкции, они будут их выполнять. В качестве дополнения ещё есть простые метрики — например, процессорное время, потраченное в user space. Они почти не отличаются, но во второй раз почему-то больше. Ну и ладно.
И — процессорное время, потраченное в ядре Linux. Если вы делаете системные вызовы и там внутри что-то сложное, это все будет учтено. При чтении с диска, естественно, немножко процессора тоже тратится на вспомогательные операции.
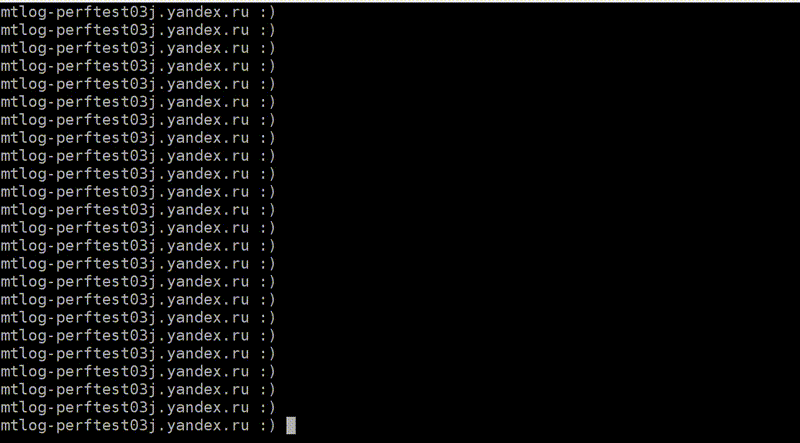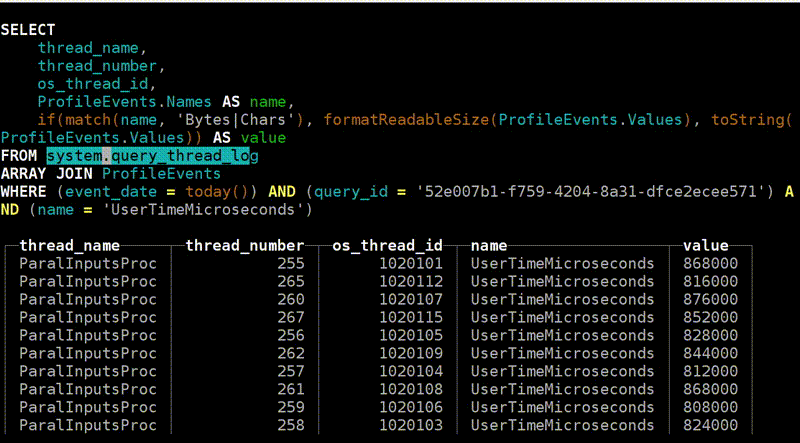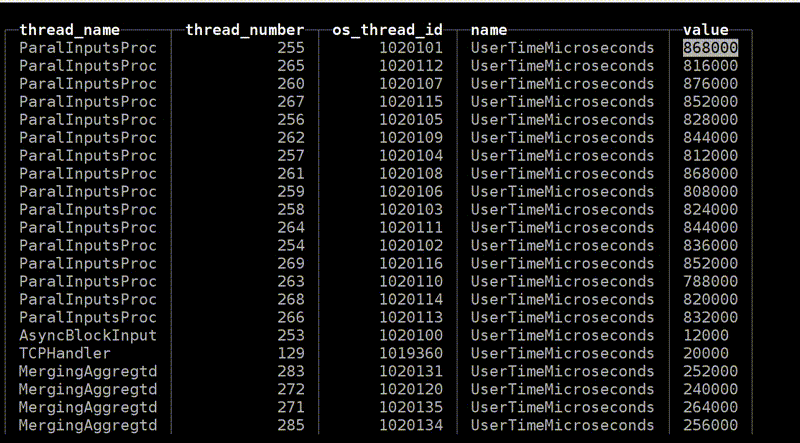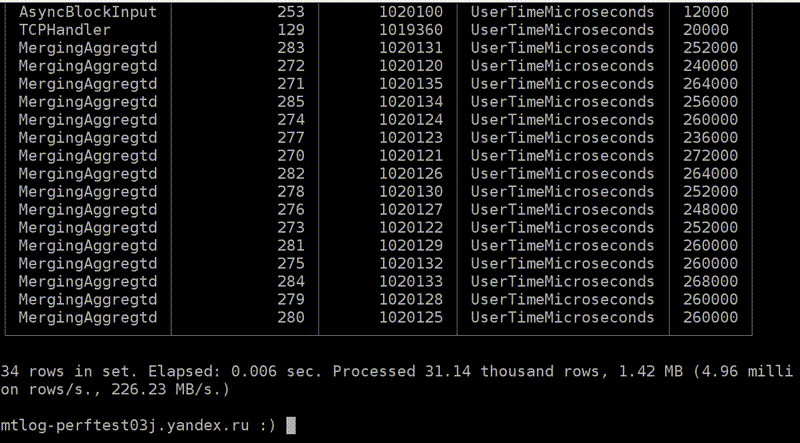
А теперь самое продвинутое, что у нас есть: query_thread_log. С его помощью вы можете понять, на что тратил время каждый поток выполнения запроса.
Я смотрю для моего запроса, выбираю по query_id и указываю метрику «Количество процессорного времени, потраченного в user space». Вот наши потоки. Для параллельной обработки запроса было выделено 16 потоков. Каждый из них потратил 800 мс. А потом ещё 16 потоков было выделено для мёрджинга состояния агрегантных функций, на каждый из них было потрачено 0,25 с. Теперь я могу точно понять, на что потратил время каждый запрос.
