А слабо сделать нормального чат-бота для банка? — challenge accepted
Сначала оказалось, что простые эвристики не работают. Ну вот совсем. То есть тупой чат-бот, который умеет распознавать с десяток жёстких тематик или показывать клавиатуру вроде «Нажмите 1, чтобы узнать свой баланс», несильно экономит время контакт-центру. Люди как не читали инструкции, так и не читают, а при виде такого сразу стремятся выйти на живого оператора.
То есть бот должен быть реально полезным. Таким, чтобы пользователь чувствовал, что диалог с ним — это не конкурс «обойти железного идиота», а что-то всё же даёт.
Здесь ждут следующие грабли: предположим, вы собрали всю базу диалогов контакт-центра с 2002 года. Разметили её и даже обучили на ней бота. Дальше произойдёт следующее:
- Либо актуальность этого обучения будет падать, и так же будет падать процент автоматизации. С каждым месяцем меняются тематики и запросы.
- Либо же вы можете переобучить модели слишком подробными выборками, которые имеют пересечения по категориям.
Речь идёт про то, что если обучать базу на всех диалогах без исключения так, как это подразумевает философия полной автоматизации, то очень быстро база начнёт забиваться откровенным мусором, снижающим точность классификации. Про это вендоры вам не скажут, но нужно либо постоянно что-то подкручивать, либо чистить выборку для обучения, либо обучать не на всех диалогах, которые закончились каким-то удовлетворительным ответом. Иначе очень быстро у вас перепутаются ответы для кредитных и дебетовых карт, например, потому, что клиенты либо путают их в своих стартовых запросах тоже, либо вообще не видят между ними разницы.
Ниже я хочу рассказать про те не совсем очевидные вещи в поддержке чат-бота, которые могут очень сильно уронить качество его работы. Ну или не дать до этого качества дорасти вообще, если архитектура не совсем правильная.
Почему бот всё же нужен
Живой человек, конечно, куда лучше бота. Он и телепат, и сразу подберёт нужный ответ, и ему можно рассказать про семью и внуков, да и клиентам он больше нравится, потому что вздыхает не по скрипту. Но когда мы говорим про банковский контакт-центр, операторы загнаны в скрипт почти так же сильно, как боты: слово влево или слово вправо могут очень сильно исказить финансовые данные или нарушить чью-то приватность, поэтому даже типовые фразы чаще всего нельзя переформулировать. Два фактических преимущества операторов — это возможность покрывать 100% тематик диалога, а также эффективнее распознавать изначальный запрос клиента.
Боты в текущем виде — это необходимое зло. Точнее, это переходный этап от «железных идиотов» к нормальным системам помощи, которые работают быстрее и точнее операторов. Не использовать автоматизацию в том или ином виде современный банк уже не может себе позволить: начиная от контакт-центра на 50 операторов экономика с ботами и без начинает отличаться как небо и земля.
Суть челленджа — сделать как можно более полезного бота. Наша философия такая:
- Бот встречает клиента в чате и пытается распознать его первую фразу (классифицирует обращение). Если получается понять вопрос достаточно точно — отвечает сразу по сути (чаще всего предлагает ещё какой-то персонализированный выбор с уточнениями).
- Если скоринг ансамбля моделей по попыткам понять, чего же хочет клиент, низкий, то можно либо переспросить, либо сразу отправить к оператору.
То есть должно получаться так, что клиент задаёт первый вопрос «в никуда» и либо получает ответ по делу от бота (и уже всё равно, от кого он его получил, ведь ответ — по делу), либо же бот переключает его на оператора и говорит о том, что надо немного подождать.
Повторюсь: вопрос не в том, будет там встречать бот или оператор. В современном мире будет встречать только бот без вариантов. Вопрос в том, насколько этот бот будет мешать и бесить или помогать.
Именно в этом состоит челлендж.
Как оценить, что бот работает качественно
В 2018 году мы решили практически по фану создать небольшого самописного бота для «Телеграма» — просто разобраться в теме. Параллельно пробовали облачное решение для голосового бота (потому что классический древовидный IVR нас уже перестал устраивать). Как вы понимаете, эти проекты после прототипов обросли командой и доказали, что они полезны. Постепенно развитие голосового и чат-ботов стали большими стратегическими проектами банка и в итоге экономят сейчас сотни миллионов рублей в год на автоматизации. Естественно, с учётом поддержки и разработки. При этом чат-бот — полностью наша внутренняя разработка, а для голосового бота мы купили вендорское решение. У нас два параллельных решения с разными подходами, но решают они, по сути, одну и ту же задачу. А различия довольно заметные.
Первое, что было нужно понять, — как оценивать качество работы бота.
Просто «доля автоматизации» не подходит. Понятно, что бот может закрыть часть каких-то тематик. Понятно, что можно создать такую ситуацию, когда пользователи от безысходности научатся с ним общаться. Но правильнее считать ещё как минимум качество диалога, долю решений вопроса с первого обращения, оценку от клиента и так далее. Но даже это не даёт достаточного результата.
В итоге через полгода работы мы привлекли дополнительных сотрудников в команду контент-менеджеров. В их задачи входило как готовить обучающие выборки для бота, так и читать диалоги, понимать, где что-то пошло не так. При этом важно, чтобы контроль качества работы бота находился в независимом подразделении, иначе будет риск «подгонки» выборок для завышения показателей.
Когда стали понятны критерии качества бота, закончились наши пилотные проекты. Тогда же стало ясно, что имеющиеся вендорские архитектуры нас не очень устраивают с точки зрения соответствия достижению идеала. Нам нужен был умный адекватный чат-бот, которого можно было бы поддерживать и развивать, и при этом всё шло к тому, что нельзя просто взять и купить готовое решение.
Стэк
Сейчас бот работает на следующем техническом стэке.
У нас микросервисы, элементы процесса вынесены в отдельные единицы. Сервисы, к примеру, отвечают за трансформацию данных, хранение расширенной истории интеракций с чат-ботом, отправку сервисных push-уведомлений. Непосредственно для ядра искусственного интеллекта вся интеграционная оболочка также сделана в этой концепции. Центральное место занимает сервис, который является буфером между платформой чата и ядром АI. В нём уже достаточно много функций. Он ведёт сложные сценарноориентированные диалоги, кэшируя ответы клиентов, осуществляет запросы по клиентским счетам и транзакциям, шаблонирование ответов с клиентскими данными. Большинство сервисов общается друг с другом, используя rest api, но там, где это позволяет бизнес-логика, мы используем интеграционную шину данных для взаимодействия. Стэк технологий — javascript, spingboot, react, kubernetes.
Микросервис ансамбля моделей — Python, в моделях глубокого обучения используется фреймворк Keras. Ядро переписывается на фреймворк PyTorch для использования новых моделей. Также для этих целей и расширения функциональной части в ближайшей перспективе рассматривается переход на новый стек — Faust + Cassandra + Kafka.
Перед добавлением в обучающую выборку фраза клиента проходит множество этапов: её ищут в истории обращений с помощью алгоритмов машинного обучения, далее — валидация наличия необходимой информации разметчиками, сопоставление с тематикой, удаление ненужной информации (приветствия и т. п.). Если она содержит в себе несколько тематик, то разбивается на несколько кусков, каждый из которых идёт в свою тематику. Далее даже проходит проверка скриптами, сколько тематик определяется ботом на потенциально новую фразу, на основе чего принимается решение, нужно ли перепроверить обучающую выборку пересекающихся классов.
Что может пойти не так в долговременной перспективе
Упрощая, принцип работы выглядит так: пользователь пишет фразу, далее ансамбль моделей извлекает из неё «намерения», то есть некий базовый смысл, с которым можно сопоставить ветки диалогов из обучающей выборки. Если намерение находится достаточно точно, то можно говорить о запуске той или иной ветки диалога. Внутри ветки обычно всё проще: выборы делаются из нескольких вариантов либо пользователя просят ввести конкретные данные:

Продолжения диалогов обычно выглядят как простые ветвления, но таких веток может быть очень и очень много, например, когда нужно показать магазины-партнёры
Сегодняшний топ тем выглядит примерно так:
- Нужна справка для заполнения декларации о доходах.
- Вопросы про кредитные каникулы.
- Нужна выписка по счёту.
- Досрочное погашение кредита.
- Рефинансирование кредита.
- Убедиться, что кредит точно погашен.
- Список магазинов-партнёров (это больше про программу лояльности «Польза»).
- Уточнить срок возврата денег при отмене покупки.
Естественно, что обучающая выборка не может покрывать 100% тематик. Сейчас мы покрываем около 90%. Какие-то узкие запросы дешевле переводить на оператора, чем обучать робота. Какие-то запросы появляются прямо в моменте, потому что изменились обстоятельства. Какие-то запросы начинают мигрировать из группы в группу, из тематики в тематику. Какие-то тематики объединяются, какие-то — разделяются.
Вот ситуация марта — июня 2022 года: ЦБ ввёл лимит на снятие наличных долларов. Если раньше запрос «Сколько я могу снять баксов?» с высокой вероятностью означал ветку запроса долларового остатка на счету, то сейчас важен не сам баланс валютного счёта, а сколько ещё наличных можно снять в сравнении с лимитом ЦБ.
Соответственно происходит следующее: намерение «снять доллары» разделяется на два или мигрирует из тематики в тематику. Затем мы должны накопить где-то базу диалогов с операторами (не меньше 50 разных диалогов, а лучше 200–500), чтобы обучить на них бота правильно отвечать в такой ситуации. Как только у нас появится такое количество диалогов — можно создавать новую ветку.
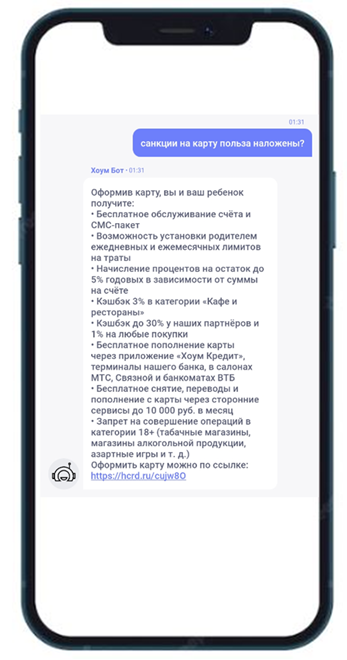
Пример неудачного диалога, который потом отсеяли контент-менеджеры. Вот тут пользователь явно путает санкции и блокировку, а модели не считают, что токен «санкции» ключевой.
Если изменение происходит очень быстро, например, после изменения какого-то норматива все вдруг начинают запрашивать какую-то конкретную справку, то сама автоматизация выдачи такой справки в боте делается очень быстро, а вот база диалогов копится медленно. Чтобы ускорить этот процесс, мы просим команду контент-менеджеров написать несколько десятков типовых диалогов с различными вариациями, сленгом, разными формулировками и т. п., чтобы получить базу для обучения. Далее, когда бот уже сможет выявлять намерение и отвечать на него, мы начнём постепенно обогащать его обучение новыми и новыми диалогами из граничных случаев.
Таким образом, база знаний постоянно обновляется при каждом новом диалоге с ботом или оператором: сейчас у нас 150 тысяч фраз в обучающей выборке, а всего год назад было 60 тысяч. Это около 800 тематик, по которым бот может помочь клиенту банка. Модели переучиваются с нуля на этой выборке три раза в день, соответственно релиз может выкатываться также с такой скоростью.
В отсрочке платежа в зависимости от причины и даты есть 85 возможных вариантов ведения диалога.
Всего не охвачено около 2% тематик по количеству звонков: в «длинный хвост» попадает очень много редких единичных запросов.
По каждой тематике скоринг успешности работы бота считается отдельно. Условно, если уровень нашей оценки падает ниже 95%, то нужно начинать разбираться, что произошло с запросами клиента. Это тот же процесс, что и при добавлении новой тематики: сначала нужно разобраться, что то, что клиент сформулировал, и то, чего он хотел, — одна и та же вещь (то есть он понимает разницу между продуктами, ну либо создать ветку так, чтобы эта разница уточнялась по ходу диалога). Затем подготовить диалоги для загрузки в обучающую выборку: мы корректируем опечатки по словарям и проводим ряд других преобразований, что превращает человекочитаемые фразы в наборы токенов с разным весом. То есть работает разметчик, который точно показывает структуру диалога и важные моменты для обучения. Без такой разметки качество ответов будет очень резко падать. Далее есть ещё один обработчик, который оценивает, насколько новые добавляемые диалоги в нашу тематику пересекаются с диалогами из других тематик: может оказаться так, что есть конфликт, и это снизит в итоге точность работы бота. Конфликты обрабатываются вручную всё на той же разметке. Это значит, что мы можем не добавлять какой-то диалог в обучение, убрать из базы знаний какой-то набор уже устаревших фраз или как-то поменять процесс. И база знаний, и ветки диалогов — динамические системы, которые меняются в зависимости от того, как меняются внешние обстоятельства. Просто оставить их без поддержки нельзя.
Например, у нас есть дебетовая карта «Польза», а есть кредитная. Вопросы по ним на 90% идентичные, разница — в один токен. Если не разделить тематики очень жёстко, то и бот, и оператор могут наделать ошибок.
В голосовом боте, например, сейчас в обучающей выборке — 50 тысяч фраз, и каждый месяц при наращивании базы пересечений тематик становится всё больше и больше. Вендор на своей стороне постоянно меняет приоритеты тематик и доразмечает, на какие слова делать акцент при пересечениях. Мы же размечаем их изначально при пополнении базы.
К состоянию практического непересечения тематик мы пришли не сразу. В 2020 году, когда у нас было около 60 тысяч фраз в обучающей выборке, стало понятно, что появляется всё больше и больше терминальных случаев. Контент-менеджеры просто разбирали ветки диалогов бота и переразмечали тематики. Когда база стала достаточно хорошо размеченной и достаточно чистой — без случайных ответов клиентов, без абырвалгов и котов на клавиатуре, без перепутанных продуктов, без фрагментов биографии клиентов, без фраз на полстраницы с пятью разными проблемами (в итоге мы вообще очень сильно понизили приоритеты фраз длиннее 250 символов), когда поправили опечатки, объединили или разделили много намерений, — качество распознавания тематик очень сильно выросло.
Заодно мы тогда узнали много нового про то, как клиенты формулируют вопросы. Например, образ мышления клиента с кредитной картой отличается от образа мышления клиента с дебетовой достаточно, чтобы по формулированию вопроса уже сделать предварительный вывод о продукте, и такие наблюдения позволяют ещё точнее определять тематики.
Итог
С семи тысяч слабо размеченных фраз в обучающей выборке марта 2019 года мы выросли до 150 тысяч очень хорошо размеченных фраз сегодня. Доля полностью решённых запросов выросла с 17% с релиза бота до 58% в прошлом году. Из них от 76 до 80% решается с первого обращения. В 80–86% случаев пользователи ставят боту «пятёрку» за качество ответа. Бот в чате трудится так же, как трудились бы 200–250 операторов: в поддержке на пике над разбором базы работали пять контент-менеджеров (они же занимались разметкой). Сейчас работают три (ещё два занимаются голосовым ботом). Плюс в команде — три дата-сайнтиста.
Средняя скорость от получения фразы клиента до ответа бота в чате — порядка одной секунды (если не требуется получать дополнительную информацию о продуктах клиента из других сервисов банка), минимальное время ответа — 0,1 секунды.
