5 грязных трюков в соревновательном Data Science, о которых тебе не расскажут в приличном обществе
Привет, чемпион! Возможно, ты сейчас участвуешь в соревновании по анализу данных или просто решил погрузиться в мира Data Science. Тогда эта статья будет тебе очень полезна!
Сражу скажу, что трюки, о которых мы сегодня поговорим, я не просто так назвал »грязными». Речь пойдет о вещах, которые в каком-то смысле нечестные или просто вводят в заблуждение других участников соревнований. Долго думал, стоит ли про эти техники вообще рассказывать, ведь в борьбе за призовые всегда велик соблазн начать хитрить. Решил, что все-таки расскажу про некоторые, дабы вооружить честных людей, которые играют по правилам.
Будем разбирать приемы по ходу увеличения уровня их «грязи» в трюках — поехали!
Обратная вероятность или 1 — P
Начнем с достаточно безобидного трюка, который очень легко реализуется в задачах классификации. Суть такая. Допустим, перед вами стоит задача классификации, и в качестве оценки качества вашей модели взята площадь под ROC кривой (AUC). Вы обучили модель, получили ответ и вместо того, чтобы отправить на лидерборд свои честно полученные ответы, вы их искажаете. А именно, если требуется отправить вероятности прогнозов, то вы каждый из них вычитаете из 1. А потом уже отправляете свой ответ в систему. Да, вы получите низкое значение AUC, но зато, если вычесть это значение снова из единицы, то вы узнаете свой истинный скор.
Зачем это все, спросите вы? Суть в том, что настоящий скор знаете только вы, а остальные участники на лидерборде даже не примут его во внимание.
 Те, кто слышал что-то про RAC-AUC кривую, сразу поймут как это работает.
Те, кто слышал что-то про RAC-AUC кривую, сразу поймут как это работает.
Теперь вы можете до последнего момента не показывать свой скор другим, тем самым усыпляя их бдительность. Надо ли говорить о преимуществах такой тактики?!
Слив теста или чё там по тесту?
Более сложный, но, тем не менее, «грязненький» трюк. Именно из-за этого способа сейчас на Kaggle запуск ноутбуков на приватных данных осуществляется без доступа к интернету, но некоторые платформы все еще дают возможность запустить докер контейнер с вашим кодом, что позволяет делать следующее:
Если платформа, на которой вы соревнуетесь дает право использовать интернет для установки необходимых библиотек, то почему же тогда не выкачать приватный тест?
Тогда, если у вас есть принимающий сервер, то в пару get/post запросов, вы можете легко слить приватную выборку.
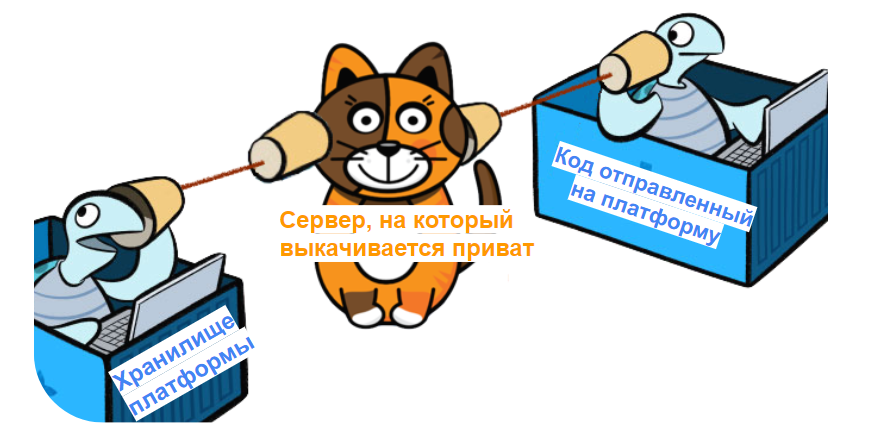 Очень условная схема выкачивания данных с платформы
Очень условная схема выкачивания данных с платформы
Как бы банально не звучал этот способ, часто это срабатывало на моих глазах. Последним примером был хакатон Rosneft Challenge по распознаванию оленей на аэроснимках. Только знайте, если вы все же провернули эту аферу, то не забудьте поделиться этим датасетом с остальными! Реализацию по соображениям безопасности выкладывать не буду.
Слив размера теста
Что ж, бандит, если предыдущий пункт оказался тебе не по зубам, или код на платформе запускается все же без интернета, то это еще не повод отчаиваться. Ведь что-то можно узнать про приватную выборку из без доступа в сеть. Ты уже понял как? Нет?! Тогда читай этот код.
test_data = pd.read_csv('test.csv')
assert test_data.shape()[0] > 1000
Как ты думаешь, что будет с этим кодом, если размер test’а меньше 1000? — Очевидно, код упадет с ошибкой. А раз так, то ты узнаешь, что размера теста больше 1000.
Не буду додумывать за тебя, что можно сделать с помощью такой техники дальше. Таким нехитрым способом, ты можешь легко «пощупать» приватные данные. И интернет тебе для этого вовсе и не нужен. Помни, приватная/валидационная выборка существует не просто так, и, если уж ты все же решился оверфититься на нее, то хотя бы поделись полученной информацией с другими!
Индусский блендинг
В основу этого метода заложена, с одной стороны, очень крутая техника — блендинг, Эта техника дает соперникам обычно хороший прирост в точности, а, если вы участвуете командой, то у вас появляется возможность объединять свои слабые решения в одно сильное. Такой способ обычно дает прирост в точности.
 Мой личный пример, где блендинг увеличивает скор
Мой личный пример, где блендинг увеличивает скор
С другой стороны, этот же метод в ненадежных руках индусов обуславливает неспортивное поведение. Суть такая — часто на чемпионатах, в том числе на платформе Kaggle, люди делятся своими решениями. Точности этих решений, как правило, недостаточно для попадания в медальные места. Однако таких публичных решений в доступе много. Что мешает просто сблендить все эти решения? Ведь много слабых решений в сумме дают одно сильное!
Увы, есть некоторые участники, которые именно так и делают. На мой взгляд, нет ничего плохого в том, чтобы почерпнуть новые идеи из чужих публичных решений, но вот просто брать ответы и блендить их это уже «грязновато». :(
Подмена датасета или ох уж этот baseline?!
Ох, ну это уже самый «грязный из грязных» способов. Сразу к делу. Вот вы вписались в соревнование, где вам выдали датасет. Вдруг один из особо добродушных участников решает поделиться своим решением в чате, которое выдает достаточно сильные значения целевой метрики на лидерборде. При этом, оказалось, что датасет скачивать не надо, ведь он автоматически подгружается по ссылке с GittHub внутри. Вы скачиваете со слезами на глазах и принимаетесь активно тюнить это решение, чтобы получить еще больший скор.
Спустя какое-то время понимаете, что не можете превзойти определённый порог точности, хотя видите, что автор этого решения высоко в топе. Причин, почему так могло произойти, — масса. Тут важно быть скептичным и задать себе один вопрос — вы уверены, что данные в этом решении именно те, что выдали организаторы?
Прикол в том, что данные могли быть специально испорчены. Вам просто подсунули половину данных, раздутую дублями до изначального размера. Я и сам несколько раз видел такие «приколы» на Kaggle. Остается только догадываться, сколько доверчивых DS’ов попадались на такую уловку и потом застревали где-то на дне лидерборда. Сам теперь внимательно проверяю, какие данные подаются на вход.
 Будь скептичен к тому, что тебе дают как базовое решение!
Будь скептичен к тому, что тебе дают как базовое решение!
Начав работать с таким датасетом, вы заведомо в проигрыше. Советую смотреть на данные, которые берете. Проверить можно хотя бы с помощью df.describe(), но и это не панацея, данные бывают очень разные. Элементарного «шафла» значений целевой переменной хватит, чтобы выбить вас из игры до конца соревнований или на некоторое время. Вы даже можете не понять, в чем дело. Скорее всего, вы будете искать проблему в вашей модели.
Заключение:
Ты убедился, что получать преимущество в соревновательном Data Science можно не только честной обработкой данных и построением сильной и устойчивой модели. Однако, не спеши использовать эти техники в реальной жизни. Я рассказал тебе об этом, чтобы вооружить тебя против них, а не чтобы ты их использовал. Получение преимущества с помощью таких методов — это дело «грязное». Если об этом узнают твои оппоненты или внешние зрители, то почета от твоего успеха будет мало. Да и рассказывать потом о таком будет стыдно. Помни, сильный тот, кто играет честно!
Еще больше классных трюков можно найти у меня в канале. Буду рад поделиться с тобой крутыми, а главное честными способами побеждать на чемпионатах по анализу данных.
