3. Дизайн сети предприятия на коммутаторах Extreme
3-е приближение — каждый из модулей дробится на более мелкие модули или уровни. Например в campus-сети:
- 3-х уровневая сеть делится на:
- уровень доступа
- уровень распределения
- уровень ядра
- ЦОД в более сложных случаях может делиться на:
- 2-х или 3-х уровневую сетевую часть
- серверную часть
Все вышеописанное я постараюсь отобразить в следующем упрощенном рисунке: 
Как видно из рисунка выше — модульный подход помогает детализировать и структурировать общую картину на составные элементы, с которыми в дальнейшем уже можно работать.
В рамках данной статьи я остановлюсь на уровне Campus Enterprise и опишу его поподробнее.
Виды IP-CAMPUS сетей
В бытность работы в провайдере и особенно позднее — в работе интегратора, я сталкивался с разной «зрелостью» сетей заказчика. Я не даром применяю термин зрелость, так как довольно часто встречаются случаи, когда структура сети растет с ростом самой компании и это в принципе закономерно.
В небольшой компании, располагающейся в пределах одного здания, сеть предприятия может состоять всего-лишь из 1 граничного маршрутизатора, выполняющего роль межсетевого экрана, нескольких коммутаторов доступа и пары-тройки серверов.
Я называю такую сеть для себя «одноуровневой» сетью — в ней абсолютно отсутствует явный уровень ядра сети, уровень распределения смещен на граничный маршрутизатор (с функциями firewall, VPN и возможно proxy), а коммутаторы доступа обслуживают как компьютеры сотрудников, так и сервера.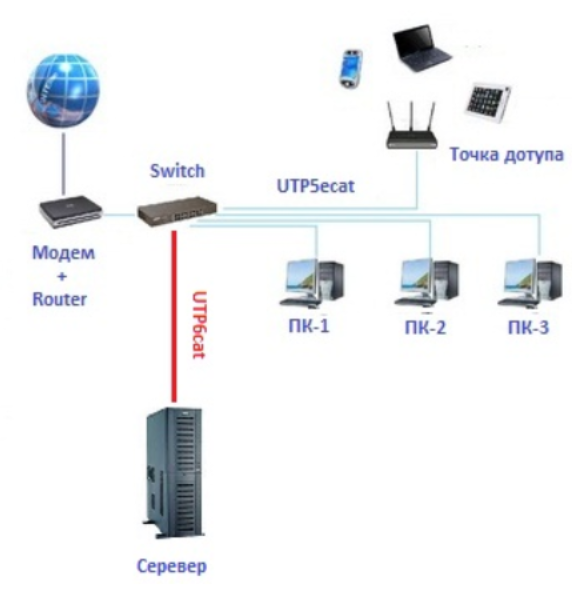
В случае роста предприятия — увеличения количества сотрудников, сервисов и серверов, зачастую приходится:
- увеличивать количество коммутаторов в сети и портов доступа
- увеличивать серверные мощности
- бороться с широковещательными доменами — внедрять сегментирование сети и маршрутизацию между сегментами
- бороться со сбоями в работе сети, из-за которых возникают простои у сотрудников, так как это влечет за собой дополнительные финансовые траты для руководства (сотрудник простаивает, зар. плата платится, а работа не делается)
- в процессе борьбы со сбоями, задумываться о резервировании критически важных узлов сети — маршрутизаторов, коммутаторов, серверов и сервисов
- ужесточать политику безопасности, так как могут возникать коммерческие риски и опять же — для более стабильной работы сети
Все это приводит к тому, что инженер (администратор сети) рано или поздно задумывается о правильном построении сети и приходит уже к 2-х уровневой модели.
Эта модель уже явно выделяет из себя 2 уровня — уровень доступа и уровень распределения, который по совместительству является и уровнем ядра (collapsed-core).
Совмещенный уровень распределения и ядра выполняет следующие функции:
- агрегирует в себе линки от коммутаторов доступа
- вводит маршрутизацию сегментов сети — пользователей и устройств становится так много, что в одну сеть /24 они не помещаются, а если помещаются, то broadcast-штормы вызывают постоянные сбои (особенно, если пользователи помогают им создавая петли)
- обеспечивает связь между соседними сегментами коммутаторов (по более скоростным линкам)
- обеспечивает связь между пользователями и их устройствами и серверной фермой, которая тоже к этому времени начинает выделяться в отдельный сегмент сети — ЦОД.
- начинает обеспечивать совместно с коммутаторами доступа, в той или иной мере, политику безопасности, которая начинает появляться у предприятия к этому времени. Компания растет, коммерческие риски также растут (здесь я подразумеваю не только положения о коммерческой тайне, разграничение политик доступа и т.д., но и об элементарных простоях сети и сотрудников).
Таким образом сеть рано или поздно вырастает до 2-х уровневой модели: 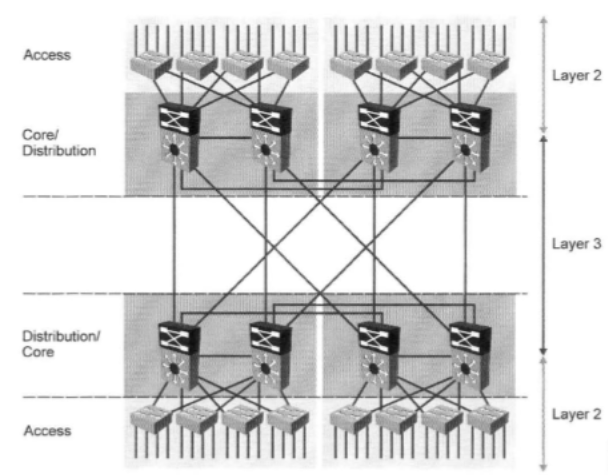
В этой модели появляются особые требования как к коммутаторам уровня доступа, которые агрегируют в себе линки от пользователей и устройств сети (принтеры, точки доступа, VoIP устройства, IP-телефонов, IP-камер и т.д.) так и к коммутаторам уровня распределения и ядра.
Коммутаторы доступа должны быть уже более интеллектуальны и функциональны, чтобы удовлетворять требованиям производительности, безопасности и гибкости сети, и должны:
- иметь различные виды портов доступа и магистральных портов — желательно с возможностью запаса по росту трафика, так и по количеству портов
- иметь достаточную коммутационную емкость и пропускную способность
- иметь необходимый функционал безопасности, который удовлетворял бы текущей политики безопасности (а в идеале и росту ее дальнейших требований)
- иметь возможность питания труднодоступных сетевых устройств с возможностью удаленной перезагрузки их по питанию (PoE, PoE+)
- иметь возможность резервировать собственное электро-питание, чтобы использовать это в тех местах, где это необходимо
- иметь (по возможности) дальнейший потенциал роста функционала — частый пример, когда коммутатор доступа со временем превращается в коммутатор распределения
К коммутаторам распределения в свою очередь тоже предъявляются соответствующие требования:
- как в части магистральных нисходящих портов в сторону коммутаторов доступа, так и в сторону peer интерфейсов соседних коммутаторов распределения (а в дальнейшем и возможных uplink интерфейсов в сторону ядра)
- в части L2 и L3 функционала
- в части функционала безопасности
- в части обеспечения отказоустойчивости (резервирование, кластеризация и резервирование эл. питания)
- в части обеспечения гибкости при балансировке трафика
- иметь (по возможности) дальнейший потенциал роста функционала (трансформация со временем устройства агрегации в ядро)
- в некоторых случаях на коммутаторах распределения может быть уместным использовать PoE, PoE+ порты.
Дальше — больше: в случае проведения руководством политики активного роста и развития предприятия, сеть в дальнейшем также продолжит развиваться — предприятие может начать арендовать соседние здания, строить свои собственные корпуса или поглощать более мелких конкурентов, увеличивая тем самым количество рабочих мест для сотрудников. Одновременно с этим также происходит рост сети, который требует:
- обеспечение сотрудников рабочими местами — необходимы новые коммутаторы доступа с портами доступа
- наличие новых коммутаторов распределения для агрегирования линков от коммутаторов доступа
- построения новых, а также модернизации существующих линий связи
Как следствие происходит рост трафика по следующим причинам:
- из-за увеличения портов доступа и соответственно пользователей сети
- из-за увеличения трафика смежных подсистем, которые выбирают для себя в качестве транспорта сеть предприятия — телефония, безопасность, инженерные системы и т.д.
- из-за внедрения дополнительных сервисов — с ростом персонала появляются новые отделы, требующие определенного ПО
- увеличиваются вычислительные мощности ЦОД, чтобы удовлетворять требованиям инфраструктуры и приложений
- растут требования безопасности к сети и информации — знаменитая триада ЦРУ (шутка), а если серьезно, то CIA — Confidentiality, Integrity and Availability:
- в связи с этим, к критичным уровням сети — распределения и ЦОД появляются дополнительные требования по отказоустойчивости и резервированию
- опять же происходит рост трафика из-за внедрения новых систем безопасности — например РКВИ и т.д.
Рано или поздно рост трафика, сервисов и количества пользователей приведет к необходимости внедрения дополнительного уровня сети — ядра, которое будет выполнять высокоскоростную коммутацию/маршрутизацию пакетов с использованием высокоскоростных линков связи.
В этот момент предприятие может перейти к 3-х уровневой модели сети: 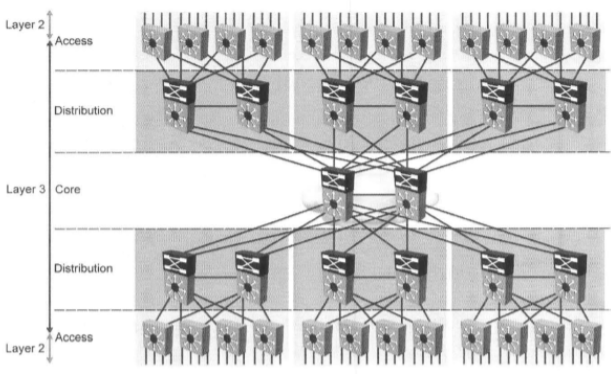
Как видно на рисунке выше — в такой сети присутствует уровень ядра, который агрегирует в себе скоростные линки от коммутаторов распределения. Таким образом к коммутаторам ядра также выдвигаются требования по:
- пропускной способности интерфейсов — 1GE, 2.5GE,10GE, 40GE, 100GE
- производительности коммутатора (switching capacity и forwarding perfomance)
- типам интерфейсов — 1000BASE-T, SFP, SFP+, QSFP, QSFP+
- количеству и набору интерфейсов
- возможностей резервирования (стэкирование, кластеризация, резервирования плат управления (актуально для модульных коммутаторов), резервирование эл. питания и т.д.)
- функционалу
На таком уровне сети определенно необходима как ее техническая модификация:
- резервирование узлов и связей ядра (очень-очень-очень желательно)
- резервирование узлов и линков связей уровня распределения (в зависимости от критичности)
- резервирование линков связи между коммутаторами доступа и уровнем распределения (по необходимости)
- ввод протоколов динамической маршрутизации
- балансировка трафика как в ядре так и на уровнях распределения и доступа (при необходимости)
- внедрение дополнительных сервисов — как транспортных, так и сервисов безопасности (при необходимости)
так и юридическая, определяющая сетевую политику безопасности предприятия, которая дополняет общую политику безопасности в части:
- требований по внедрению и настройке тех или иных функций безопасности на коммутаторах доступа и распределения
- требований доступа, мониторинга и управления оборудованием сети (протоколы удаленного доступа, разрешенные для управления сегменты сети, настройки логирования и т.д.)
- требований к резервированию
- требований к формирования минимально необходимого ЗИП-комплекта
В этом разделе я кратко описал эволюцию сети и предприятия от нескольких коммутаторов и пары десятков сотрудников до нескольких десятков (а может быть и сотен коммутаторов) и нескольких сотен (а то и тысяч) только тех сотрудников, которые непосредственно работают в сети предприятия (а ведь есть еще производственные департаменты и инженерные сети).
Понятно, что в реальности такого «чудесного» и быстрого развития предприятия не происходит.
Обычно проходят годы, чтобы предприятие и сеть выросла от своего начального 1 уровня, до 3-го, описываемого мной.
Зачем я пишу все эти прописные истины? Затем, что хочу здесь упомянуть такой термин как ROI — return-on-investment (возврат/окупаемость инвестиций) и рассмотреть ту его сторону, которая касается напрямую выбора сетевого оборудования.
При выборе оборудования, сетевые инженеры и их руководители зачастую выбирают оборудование исходя из 2-х факторов — текущей цены оборудования и минимального технического функционала, который необходим на данный момент для решения конкретной задачи, или задач (о закупке оборудования для резервирования расскажу далее).
При этом, редко рассматриваются возможности дальнейшего «роста» оборудования. При возникновении ситуации, когда оборудование себя исчерпает по функционалу или производительности, то в дальнейшем закупается более мощное и функциональное, а старое сдается на склад, либо куда-нибудь на сеть по принципу «чтобы стояло» (это кстати тоже служит причиной появления большого зоопарка оборудования и закупки кучи информационных систем, работающих с ним).
Таким образом вместо покупки части лицензий на доп. функционал и производительность, которые стоят гораздо дешевле чем новое более высокопроизводительное оборудование, приходится покупать новую железку и переплачивать по следующим причинам:
- сеть зачастую растет медленно и расширение функционала, или производительности коммутатора вашей сети может хватить еще на долгое время
- не секрет, что оборудование иностранных вендоров привязано к заграничной валюте (доллару или евро). Если быть честным — рост доллара или евро (или периодическая мини-девальвация рубля, тут как посмотреть) приводит к тому, что доллар 10 лет назад и доллар сейчас это совсем разные вещи с точки зрения рубля
Суммируя все выше сказанное, хочу заметить, что покупка сетевого оборудования с более широким функционалом сейчас, может привести к экономии в дальнейшем.
Здесь затраты на закупку оборудования я рассматриваю в контексте инвестирования в свою сеть и инфраструктуру.
Таким образом многие вендоры (не только Extreme) придерживаются принципа pay-as-you-grow, закладывая в оборудование кучу функционала и возможностей по увеличению производительности интерфейсов, которые в дальнейшем активируются покупкой отдельных лицензий. Также они предлагают модульные коммутаторы с широким набором интерфейсных и процессорных карточек, и возможностью последовательного наращивания как их количества, так и производительности.
Резервирование критичных узлов
В данной части статьи я хотел бы кратко описать основные принципы резервирования таких важных узлов сети, как коммутаторы ядра, ЦОД или распределения. И начать я хочу с рассмотрения общих видов резервирования — стэкирования и кластеризации.
У каждого из методов есть свои плюсы и минусы, о которых я и хотел бы поговорить.
Ниже представлена общая сводная таблица сравнения 2-х методов: 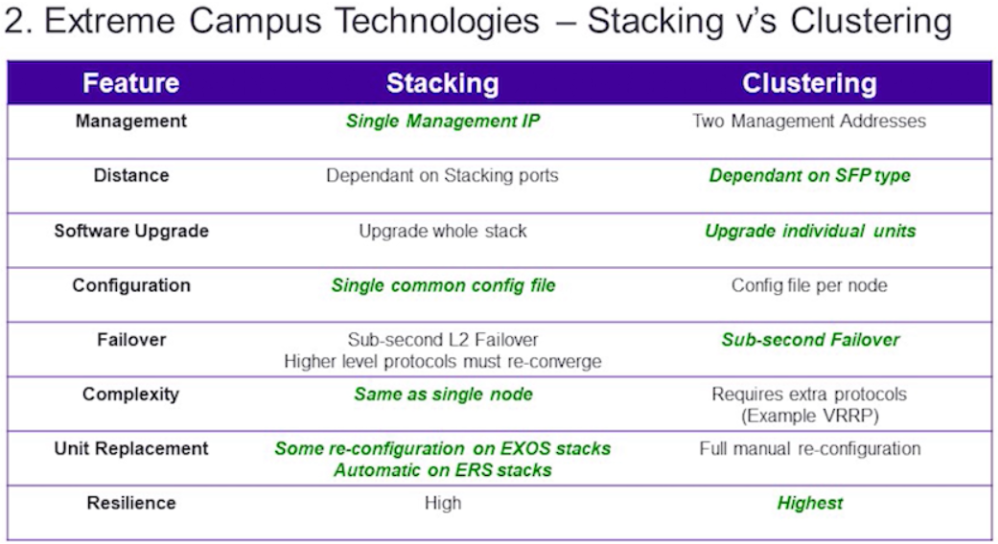
- управление — как видно из таблицы, в этом плане преимущество у стэкирования так как с точки зрения управления стэк из нескольких коммутаторов представляется одним коммутатором с большим количеством портов. Вместо управления например 8-ю различными коммутаторами при кластеризации вы можете управлять только одним при стэкировании.
- расстояние — на данный момент, строго говоря, преимущество у кластеризации не является таким уж явным, так как появились технологии стэкирования коммутаторов через порты стэкирования или порты двойного назначения (например SummitStack-V у Extreme, VSS — у Cisco и т.д.), которые также зависят от типов трансиверов. Здесь преимущество отдано кластеризации по принципу того, что при стэкировании существуют варианты, при которых приходится использовать обычные порты стэкирования, которые зачастую подключаются специальными кабелями ограниченной длины — 0.5, 1, 1.5, 3 или 5 метров.
- обновление ПО — здесь мы видим, что у кластеризации преимущество перед стэкированием и дело в следующем — при обновлении версии ПО оборудования при стэкировании вы обновляете ПО на мастер-коммутаторе, который в дальнейшем берет на себя роль размещения нового ПО на standby-member коммутаторах стэка. С одной стороны это облегчает вашу работу, но обновление ПО зачастую требует аппаратной перезагрузки оборудования, что приводит к перезагрузке всего стэка и таким образом к перерыву его работы и всех завязанных на него сервисов на время = времени перезагрузки. Обычно это очень критично для ядра и ЦОД. При кластеризации — у вас имеется 2 независящих друг от друга устройства, на которых вы можете обновлять ПО последовательно друг за другом. При этом перерывов в сервисах можно избежать.
- конфигурация настроек — здесь преимущество конечно у стэкирования, так как в случае и с управлением вам необходимо править настройки только для одного устройства и его конфигурационного файла. У кластеризации же количество файлов конфигурации будет равняться количесту узлов кластера.
- отказоустойчивость — здесь обе технологии приблизительно равны, но небольшое преимущество все-таки имеется у кластеризации. Причина здесь кроется в следующем — если рассматривать стэк с точки зрения запущенных процессов и протоколов, то мы увидим следующее:
- есть master-switch, на котором запущены все основные процессы и протоколы (например протокол динамической маршрутизации — OSPF)
- есть остальные slave-switch коммутаторы, на которых запущены основные процессы, необходимые для работы в стэке и обслуживании трафика, проходящего через них
- при выходе из строя master-switch коммутатора, следующий по приоритету slave-switch коммутатор обнаруживает отказ мастера
- он инициирует себя как мастера и запускает все процессы, которые работали на мастере (в том числе и наблюдаемый нами протокол OSPF)
- после некоторого времени старта процессов (обычно довольно маленького), начинает отрабатывать уже сам протокол OSPF
- таким образом OSPF при отказе одного из узлов при кластеризации отработает чуточку быстрее чем при стэкировании (на время, необходимое запуску и инициализации процессов и протоколов на slave коммутаторе стэка). Хотя должен заметить, что современные протоколы стэкирования и коммутаторы отрабатывают очень быстро, зачастую длительность перерыва по трафику при переключении стэка занимает менее одной секунды, но все-таки номинально кластеризация выигрывает по данному параметру.
- сложность — как видно из таблицы, в плане сложности выигрывает стэкирование. Это прямое следствие пунктов «управления» и «конфигурации настроек». Одиночный узел занимает гораздо меньше времени для настроек и управления. Также при кластеризации довольно часто приходится настраивать дополнительные протоколы маршрутизации или протоколы резервирования шлюзов — VRRP, HSRP и другие.
- замена узлов — тут однозначное преимущество у стэкирования. Очень часто для замены коммутатора в стэке необходимо провести минимально необходимые настройки оборудования, например:
- обновить ПО нового коммутатора до версии ПО стэка (а это можно делать сразу при поступлении коммутаторов в ЗИП)
- настроить несколько базовых комманд для стэкирования (а для некоторых видов коммутаторов даже это может не требоваться)
- вытащить вышедший из строя коммутатор стэка и подключить новый
- подключить электропитание и патчкорды
- упругость — я рассматриваю для себя как один из основных параметров. В целом упругость это комплексная характеристика, которая означает свойство чего-либо изменяться под действием нагрузки и возвращаться к первоначальному виду после ее исчезновения. Как не странно для кластеризации она будет выше даже с учетом счета 4:3 по характеристикам в пользу стэкирования. Все дело в человеческом факторе. Да-да, не удивляйтесь — в силе таких параметрах стэкирования, как единое управление, конфигурация настроек и облегченная сложность и кроется слабость стэкирования, когда в дело вступает человеческий фактор.
За свою работу в области IT я много раз встречал ситуации (да чего уж греха таить и сам наступал на эти же грабли, особенно в начале), когда при настройке стэка инженер ошибался в вводе той или иной команды или включением/oтключением того или иного функионала на оборудовании, что приводило к отказу всего стэка и его ручной перезагрузке. Отдельно стоит упомянуть любителей приложения Putty для Windows (ох уж это копирование правой кнопкой мыши).
На самом деле обе технологии довольно хороши (особенно по сравнению с отсутствием резервирования) и у каждой есть свои сильные и слабые стороны, но для уровня ядра и для высоконагруженного ЦОД я бы предпочел все-таки использовать кластеризацию.
Хотя это только мое мнение. Многие профессиональные инженеры, которые уже много лет на профессиональном уровне занимаются поддержкой сети, могут в равной степени пользоваться обеими технологиями — тут все зависит от опыта и квалификации.
Помимо технологий стэкирования и резервирования узлов сети, существуют также общие принципы резервирования частей самого узла сети и связей между узлами:
Под резервированием внутри узла сети я понимаю:
- резервирование блоков питания — установка 2-х блоков питания, дублирующих друг друга (да еще желательно подключенная к 1-й категории электропитания) может значительно облегчить вам жизнь.
- резервирование плат управления — в большей степени относится к модульным коммутаторам, у которых предусмотрено подключение нескольких дублирующих друг друга плат управления.
- резервирование интерфейсных карт — также относится по большей части к модульным коммутаторам.
Под резервированием связей/линков понимается в основном наличие дублирующих друг друга кабельных трасс (или радиолинков в случае открытых пространств) с:
- распределением по разным кабельным шахтам и каналам внутри здания
- географическим распределением по территории на уровне 2-х и более зданий, города, области или страны (так называемые объемные кольца)
При этом при построении резервных линков связи необходимо соблюдать ряд рекомендаций для оборудования:
- в случае дублирования интерфейсных карт модульного коммутатора, или при наличии стэка, необходимо распределять линки между юнитами — интерфейсными карточками в случае модульных коммутаторов и коммутаторами в случае стэка.
- желательно использовать протоколы агрегирования связи (LACP, MLT, PAgP и т.д.) для объединения линков в группы и балансировки нагрузки между ними.
- использовать маршрутизаторы поддерживающие протоколы ECMP (Equal-Cost-Multi-Path) — когда при доставке нескольких пакетов по одному маршруту эти пакеты идут не через один best path (и интерфейс), а распределяются по нескольким best-path (и нескольким интерфейсам), которые определяются по равенстве метрик протокола маршрутизации, который в свою очередь отвечает за наполнение итоговой таблицы маршрутизации.
А теперь, как и обещал, опишу реальный случай из моей практики и принцип экономии при резервировании критичных узлов, который произошел несколько лет назад:
- в одной компании, назову ее X, была стандартная 3-х уровневая модель сети:
- с несколькими ядрами
- несколькими десятками агрегаций
- несколькими тысячами коммутаторов доступа
- несколькими десятками тысяч пользователей
- сеть была довольно сложно построена:
- с кучей динамических протоколов маршрутизации и протоколов — OSPF, MP-BGP, MPLS, PIM, IGMP, IPv6 и т.д.
- кучей сервисов — доступ в интернет, L2 и L3 VPN, VoIP, IPTV, выделенных линий и т.д.
- но было одно узкое место в сети — граничный маршрутизатор, который сочетал в себе функции BGP-бордера и терминировал некоторые пользовательские сервисы
- да, он стоил как крыло самолета (несколько миллионов рублей)
- да, на тот момент он был одним из топовых устройств в линейки у самого именитого сетевого вендора
- да, он должен был быть очень надежным — с отличным показателем MTBF
- да, у него было 4 блока питания, собранных по схеме 2×2 и включенных с разных УЭПС и вводов.
Но все это не отменяло того факта, что он был единой точкой отказа сети.
И в один, далеко не прекрасный для меня и моих коллег день этот маршрутизатор приказал долго жить (в дальнейшем уже выяснили, что произошел какой-то сбой на линии эл. питания через УЭПС, который привел к выходу одновременно 2-х блоков питания и при этом один из блоков спалил модуль RP маршрутизатора и интерфейсную карту, которые были подключены к общей шине данных устройства).
Резервных плат — RP и интерфейсной карточки у нас не было, но был контракт на замену оборудования или его комплектующих с одним из партнеров по схеме NBD.
К сожалению у партнеров на тот момент на складе оказалась только интерфейсная карточка, но не было платы RP, она пришла только спустя несколько дней (через 3 дня).
В итоге наличие единой точки отказа в сети (даже с наличием контракта поддержки и замены оборудования) вылилось в следующие финансовые затраты:
- доля услуг компании, приходящаяся или связанная с этим бордером, составляла порядка 60–70%
- как потом было подсчитано, дневная прибыль составляла около 900 тыс. рублей (примерно) на тот момент
- таким образом за 3 дня простоя теоретически была утеряна прибыль в размере от 1 млн 620 тыс. рублей до 1 млн 890 тыс. рублей
Конечно чистые потери были меньше, так как компенсации основной части пользователей были возвращены не в виде денег, а в виде услуг, но они все равно были:
- часть компенсаций корпоративным пользователям
- повышенные расходы на сотрудников предприятия, которые работали все эти 3–4 дня в полном составе — переработки, ночные дежурства, увеличение смен и т.д.
- репутационные потери, что тоже не маловажно
- и самое важное — нервы, как руководства и сотрудников, так и клиентов
В итоге политика компании была пересмотрена:
- отказались от контракта замены по условию NBD
- оставили обычный сервисный контракт
- закупили дублирующий маршрутизатор стоимостью примерно 1 — 1.3 млн рублей для резервирования 90% функционала основного
В дальнейшем закупка дополнительного оборудования и резервирование основного позволило сбалансировать между ними нагрузку по внешним линкам, трафику и пользователям, и обеспечило в дальнейших авариях запас прочности для компании.
Пример проектирования сети Enterprise
В данной части статьи я постараюсь изложить основные моменты при расчете опорной сети предприятия. Я не буду перегружать вас всей методикой PPDIOO (Prepare-Planning-Design-Implement-Operate-Optimize), а лишь обозначу главные ее моменты:
- Prepare/Подготовка — необходимо определиться со своим руководством о целях модернизации сети, которых вы хотите добиться — повысить отказоустойчивость, внедрить новые сервисы или технологии. Определение ограничений — технических и организационных я здесь пропущу, так как предполагаю, что вы являетесь сотрудником организации и обладаете большим запасом по времени на их преодоление. К теме бюджета вернусь ниже.
- Planning/Планирование — здесь вы должны будете построить полную характеристику вашей текущей сети (если вы ее еще не знаете), т.е. описать сеть как она есть сейчас:
- количество и тип оборудования
- количество и типы портов
- существующие кабельные трассы и схемы коммутации внутри зданий и между ними
- схемы электропитания
- L2 и L3 адресации
- построить карты сетей Wi-Fi c указанием точек доступа и контроллеров
- описать свою серверную ферму
- желательно описать все свои сервисы и связи между ними
- если у вас уже внедрена в том или ином виде политика сетевой безопасности и разграничения сетевого доступа обязательно учесть ее при проектировании
- сразу замечу, что второй шаг, по сути представляет из себя полную инвентаризацию сети, начиная от кабельной инфраструктуры и схем электропитания, и заканчивая сервисами (приложениями и их портами). Этот шаг очень-очень трудоемкий и даже порой нудный. Если вы или ваш предшественник не вел документации или даже элементарной системы мониторинга, то самое время подумать об этом. Сеть имеет тенденцию меняться со временем с той или иной скоростью и только ведение актуальной документации или системы мониторинга может помочь вам уследить за ее состоянием и облегчить ее администрирование. Но это уже относится к шагу operate.
- Design/Проектирование — вооружившись полными знаниями о вашей сети, полученными на предыдущем шаге, вы наконец-то садитесь и думаете как модернизировать вашу сеть. Ниже я постараюсь продемонстрировать небольшой пример расчета сети.
Для себя я составил небольшой список с исходными данными, которым я буду руководствоваться при расчете и проектировании опорной сети.
Представим шаг Prepare в виде списка того, что у нас есть в наличии и что планируется сделать:
- есть довольно крупное предприятие с приблизительным количеством рабочих мест, порядка 700–800 шт (здесь я имею ввиду тех сотрудников, которым требуется доступ к сети предприятия)
- имеется несколько отдельно-стоящих зданий в пределах территории предприятия:
- Основные корпуса:
- количество зданий — 2 шт
- количество этажей в здании — 7 шт
- количество телекоммуникационных шкафов на этаже в одном здании — 3 (всего 21) шт
- количество сотрудников в здании =~ 250 человек
- Дополнительные корпуса:
- количество зданий — 10 шт
- количество этажей в здании/цеху — 2 шт
- количество телекоммуникационных шкафов в здании — 3 шт
- количество сотрудников в здании =~ 20 человек
- Текущий уровень ядра сети (кстати очень распространенная схема, которая встречалась мне не раз в том или ином виде и составе портов) представлен:
- 2-мя коммутаторами L2:
- 1Gb порты типа RJ-45 — 24 шт
- 1Gb SFP порты — 4 шт
- 1-м коммутатором L2:
- 1Gb SFP порты — 24 шт
- топология ядра — кольцо
- peer-to-peer линки между коммутаторами включены с использованием оптических волокон
- коммутаторы располагаются в небольших серверных комнатах со шкафами
- 2-мя коммутаторами L2:
- Текущий уровень распределения:
- совмещен с уровнем ядра сети в части агрегирования линков от коммутаторов доступа
- L3 адресация вынесена на граничный маршрутизатор и/или межсетевой экран
- Текущий уровень доступа:
- коммутаторы L2 с 16×100 Mb портами доступа RJ-45 и 2-х гигабитными аплинк combo-портами RJ-45/SFP
- коммутаторы располагаются в шкафах на этажах
- топология коммутаторов доступа:
- звезда (hub-and-spoke — ступица и спицы) с коммутатором ядра/распределения в середине
- луч/spoke представляет из себя ветку коммутаторов по этажам — 3 шт в цепочке
- имеются неуправляемые коммутаторы доступа
- коммутаторы в 9 дополнительных корпусах включены через медиаконвертора (преобразователи оптического сигнала в электрический)
- Текущая кабельная инфраструктура:
- Кабельная система между зданиями:
- имеется оптический кабель между 2-мя главными зданиями емкостью 8 волокон
- имеется по 1-му оптическому кабелю между одним из дополнительных корпусов (где установлен коммутатор ядра) и каждым из основных строений емкостью 8 волокон каждый
- имеется по 1-му оптическому кабелю между доп. корпусами и корпусами с установленными коммутаторами ядра емкостью 4 волокна (их распределение показано на картинке ниже)
- тип волокон во всех кабелях — одномодовый/SMF
- используются 2-х волоконные одномодовые SFP трансиверы
- часть кабелей терминируются на оптических кроссах (ODF) в отдельных помещениях (кросс-залы/серверные), а часть кабелей в этажных ШТО
- Кабельная система внутри зданий:
- имеется смешанная кабельная структура между серверными комнатами и первыми шкафами на этажах:
- медные кабели Cat5e — 10 шт (или 100 парные кабели)
- оптоволоконный многомодовый/MMF кабель на 4 или 8 волокон — 1 шт
- оптоволоконный многомодовый/MMF кабель на 4 волокна между этажными шкафами
- медные кабели Cat5e между этажными шкафами и розетками доступа
- текущий ЦОД:
- есть несколько серверов, например 6 штук
- включены 1Gb портами в коммутатор ядра в 1-м основном здании
- все приложения предприятия вынесены на сервера
- адресация L2, L3 и маршрутизация:
- в сети имеется несколько VLAN — 2,3 штуки на здание
- сервера выделены в отдельную /24 сеть
- для внутренних нужд используются серые сети класса B, входящие в диапазон — 172.16.0.0/16
- L3 адреса терминируются на граничном маршрутизаторе и/или на межсетевом экране
- используется статическая маршрутизация
- дополнительная информация:
- телефония:
- в зданиях и некоторых корпусах развернута традиционная телефония с использованием цифровых АТС старого образца (не IP-АТС)
- необходимо телефонизировать новые корпуса, без затрат на протяжку дорогих медных кабельных линий определенной емкости и построения дублирующей СКС для телефонии внутри зданий
- со временем планируется внедрять IP-телефонию на всей территории предприятия, совмещать ее с CRM-системами и переводить на нее всех сотрудников
- емкость портов:
- необходимо проанализировать текущую емкость магистральных портов и портов доступа, и зарезервировать не менее 25–30% под будущие нужды
- проанализировать достаточность текущей пропускной способности портов доступа и магистральных линков
- предусмотреть наличие PoE/PoE+ портов доступа для устройств из смежных систем — видеонаблюдения и телефонии
- видеонаблюдение:
- планируется использовать сеть предприятия в качестве транспорта для сети видеонаблюдения
- необходимо предусмотреть наличие PoE портов для камер видеонаблюдения
- беспроводные системы:
- в дальнейшем планируется внедрить беспроводную инфраструктуру для мобильности сотрудников
- необходимо предусмотреть наличие PoE портов для точек доступа
- бюджет, сроки и требования к оборудованию:
- использовать имеющееся оборудование по максимуму
- при проектировании сети учесть возможность расширения пропускной способности сети на N лет вперед
- при проектировании сети учесть поддержку всевозможных функций безопасности — тут перечень функционала, начиная от port-security и заканчивая аутентификацией и авторизацией пользователей по 802.1х.
- максимально возможно зарезервировать критичные узлы сети первостепенной важности — ядро и ЦОД, и предусмотреть возможность резервирования узлов второстепенной важности — узлов распределения
- бюджет проекта должен предусматривать последовательное финансирование в несколько этапов
- сумма бюджета — тут уже каждое предприятие определяет для себя, руководствуясь своими финансовыми показателями
- сроки — в самом идеальном случае т
- телефония:
- Кабельная система между зданиями:
