1.Elastic stack: анализ security логов. Введение

В связи окончанием продаж в России системы логирования и аналитики Splunk, возник вопрос, чем это решение можно заменить? Потратив время на ознакомление с разными решениями, я остановился на решении для настоящего мужика — «ELK stack». Эта система требует времени на ее настройку, но в результате можно получить очень мощную систему по анализу состояния и оперативного реагирования на инциденты информационной безопасности в организации. В этом цикле статей мы рассмотрим базовые (а может и нет) возможности стека ELK, рассмотрим каким образом можно парсить логи, как строить графики и дашбоарды, и какие интересные функции можно сделать на примере логов с межсетевого экрана Check Point или сканера безопасности OpenVas. Для начала, рассмотрим, что же это такое — стек ELK, и из каких компонентов состоит.
«ELK stack» — это сокращение от трех проектов с открытым исходным кодом: Elasticsearch, Logstash и Kibana. Разрабатывается компанией Elastic вместе со всеми связанными проектами. Elasticsearch — это ядро всей системы, которая сочетает в себе функции базы данных, поисковой и аналитической системы. Logstash — это конвейер обработки данных на стороне сервера, который получает данные из нескольких источников одновременно, парсит лог, а затем отправляет в базу данных Elasticsearch. Kibana позволяет пользователям визуализировать данные с помощью диаграмм и графиков в Elasticsearch. Также через Kibana можно администрировать базу данных. Далее более детально рассмотрим каждую систему отдельно.

Logstash
Logstash — это утилита для обработки лог событий из различных источников, с помощью которой можно выделить поля и их значения в сообщении, также можно настроить фильтрацию и редактирование данных. После всех манипуляций Logstash перенаправляет события в конечное хранилище данных. Утилита настраивается только через конфигурационные файлы.
Типичная конфигурация logstash представляет из себя файл (ы) состоящий из нескольких входящих потоков информации (input), несколько фильтров для этой информации (filter) и несколько исходящих потоков (output). Выглядит это как один или несколько конфигурационных файлов, которые в простейшем варианте (который не делает вообще ничего) выглядит вот так:
input {
}
filter {
}
output {
}
В INPUT мы настраиваем на какой порт будут приходить логи и по какому протоколу, либо из какой папки читать новые или постоянно дозаписывающиеся файлы. В FILTER мы настраиваем парсер логов: разбор полей, редактирование значений, добавление новых параметров или удаление. FILTER это поле для управления сообщением которое приходит на Logstash с массой вариантов редактирования. В output мы настраиваем куда отправляем уже разобранный лог, в случае если это elasticsearch отправляется JSON запрос, в котором отправляются поля со значениями, либо же в рамках дебага можно выводить в stdout или записывать в файл.
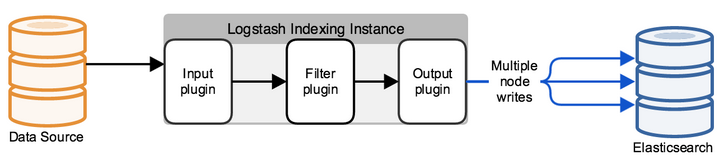
ElasticSearch
Изначально, Elasticsearch — это решение для полнотекстового поиска, но с дополнительными удобствами, типа легкого масштабирования, репликации и прочего, что сделало продукт очень удобным и хорошим решением для высоконагруженных проектов с большими объемами данных. Elasticsearch является нереляционным хранилищем (NoSQL) документов в формате JSON, и поисковой системой на базе полнотекстового поиска Lucene. Аппаратная платформа — Java Virtual Machine, поэтому системе требуется большое количество ресурсов процессора и оперативки для работы.
Каждое приходящее сообщение, как с Logstash или с помощью API запроса, индексируется как «документ» — аналог таблицы в реляционных SQL. Все документы хранятся в индексе — аналог базы данных в SQL.
Пример документа в базе:
{
"_index": "checkpoint-2019.10.10",
"_type": "_doc",
"_id": "yvNZcWwBygXz5W1aycBy",
"_version": 1,
"_score": null,
"_source": {
"layer_uuid": [
"dae7f01c-4c98-4c3a-a643-bfbb8fcf40f0",
"dbee3718-cf2f-4de0-8681-529cb75be9a6"
],
"outzone": "External",
"layer_name": [
"TSS-Standard Security",
"TSS-Standard Application"
],
"time": "1565269565",
"dst": "103.5.198.210",
"parent_rule": "0",
"host": "10.10.10.250",
"ifname": "eth6",
]
}
Вся работа с базой данных строится на JSON запросах с помощью REST API, которые либо выдают документы по индексу, либо некую статистику в формате: вопрос — ответ. Для того чтобы все ответы на запросы визуализировать была написана Kibana, которая представляет из себя веб сервис.
Kibana
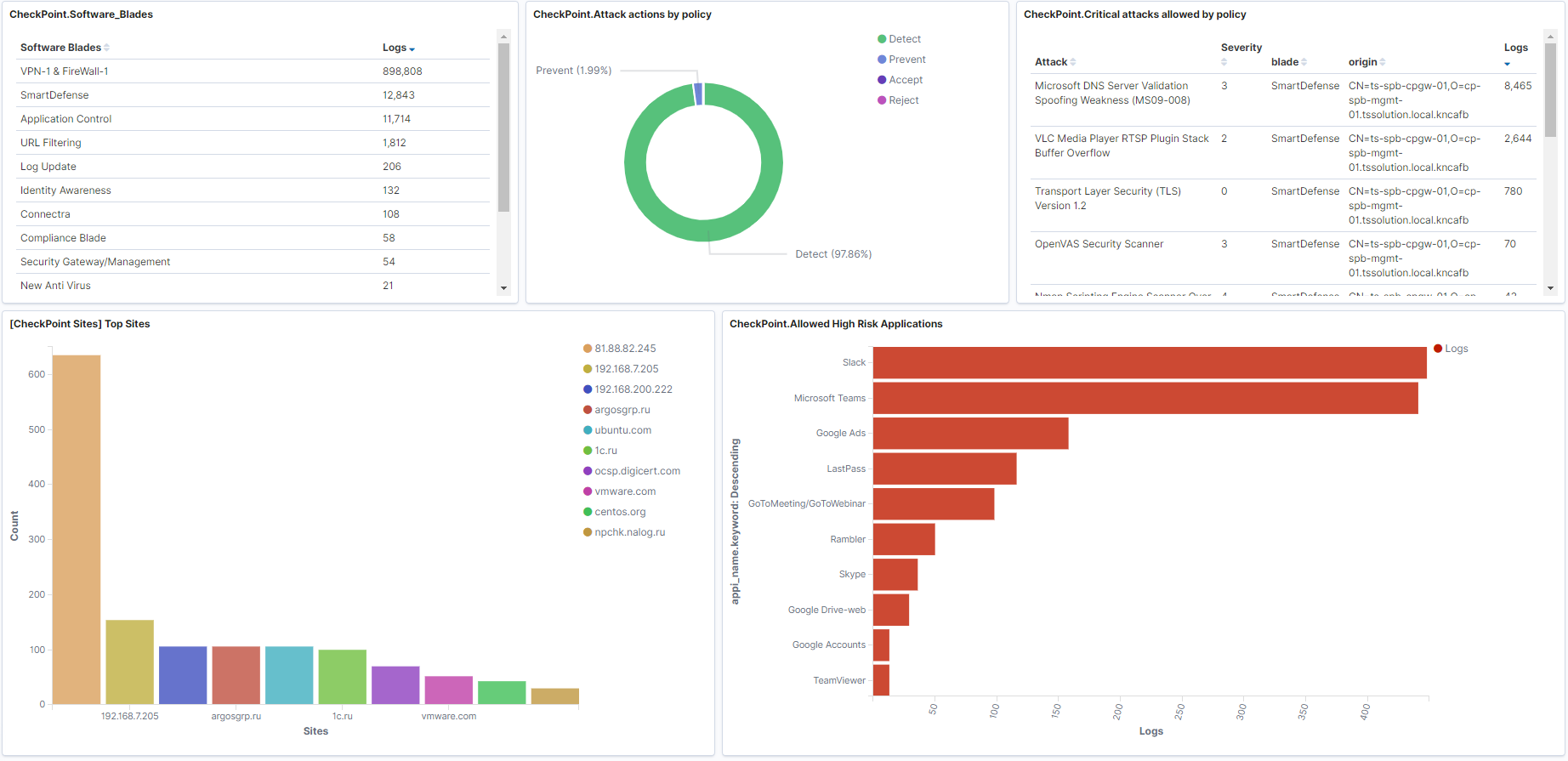
Kibana позволяет искать\брать данные и запрашивать статистику из базы данных elasticsearch, но основе ответов строятся множество красивых графиков и дашбоардов. Также система имеет функционал администрирования базы данных elasticsearch, в последующих статьях мы рассмотрим более подробно данный сервис. А сейчас покажем пример дашбоардов по межсетевому экрану Check Point и сканеру уязвимостей OpenVas, которые можно будет построить.
Пример дашбоарда для Check Point, картинка кликабельна:
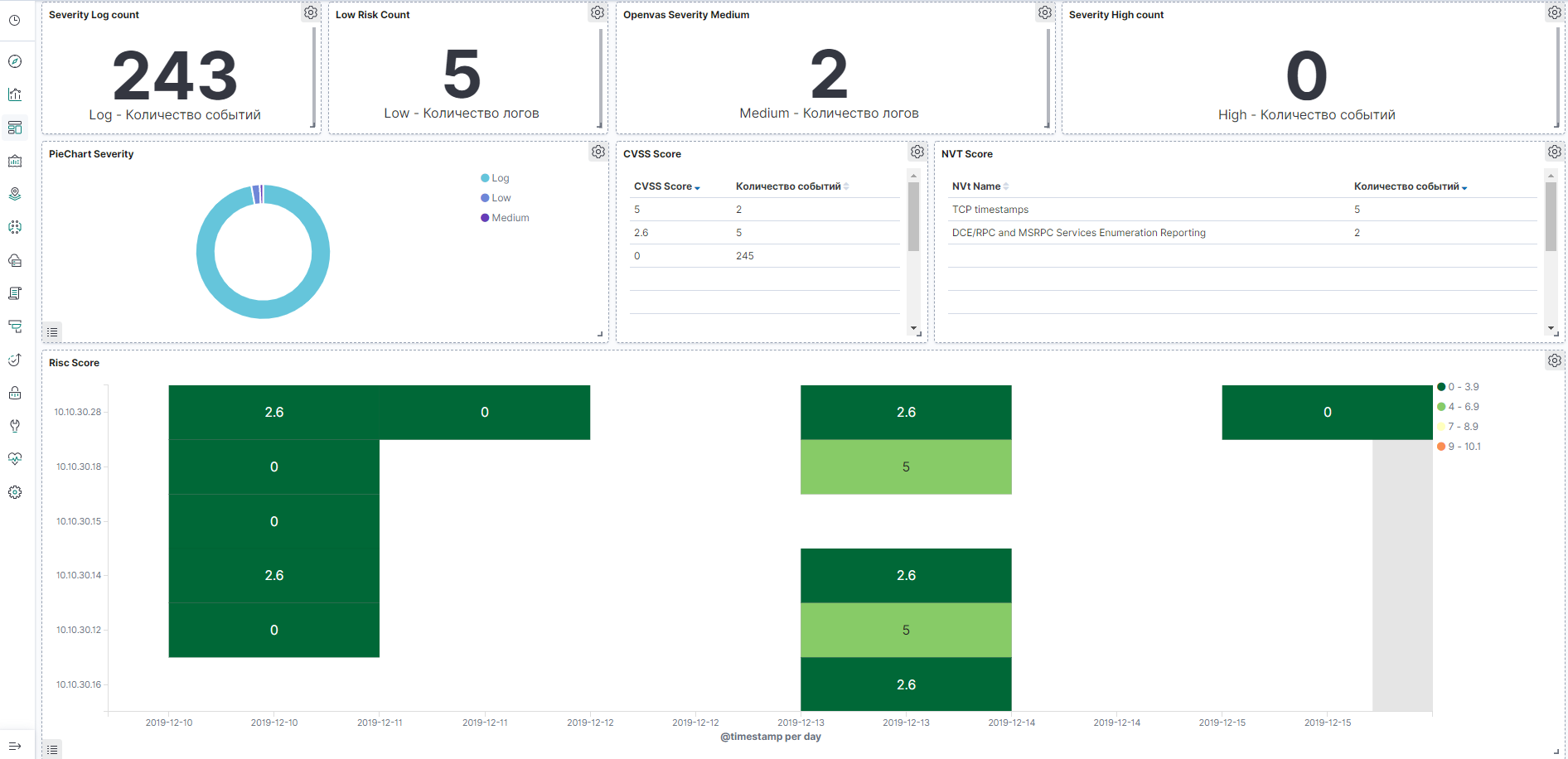
Пример дашбоарда по OpenVas, картинка кликабельна:
Заключение
Мы рассмотрели из чего состоит ELK stack, немного познакомились с основными продуктами, далее в курсе отдельно будем рассматривать написание конфигурационного файла Logstash, настройку дашбоардов на Kibana, познакомимся с API запросами, автоматизацией и много чего еще!
Так что следите за обновлениями (Telegram, Facebook, VK, TS Solution Blog), Яндекс.Дзен.
