11 друзей Sanic’а – собираем асинхронное веб-приложение на Python
В нашей компании по ряду причин перешли к асинхронным решениям, и ниже я опишу пример асинхронного веб-приложения с возможностью работы с брокером очередей RabbitMQ и запуском периодичных заданий. С кодом проекта можно ознакомиться по ссылке. Это приложение можно использовать как шаблон для новых проектов, в который достаточно будет добавить свою бизнес-логику, чтобы получилось полноценное production-решение.
Статья поможет новичкам посмотреть, как можно использовать вместе различные асинхронные библиотеки. А опытные программисты могут сравнить представленное ниже решение со своими наработками и конструктивно покритиковать.
Выбор зависимостей:
- sanic — веб-сервер. Выбран из-за простоты использования и наличия большого количества вспомогательных библиотек.
Альтернативы:
- aioHttp (но в качестве loop рекомендую использовать uvloop, либо какую-нибудь другую реализацию, написанную на C);
- FastApi
- aiopg — коннектор к базе данных. Есть более быстрые реализации, но aiopg поддерживает возможность работы с SQLAlchemy Core (подробнее в документации).
Альтернативы:
- asyncpg. Для поддержки работы с SQLAlchemy Core необходимо установить библиотеку databases либо gino.
- SQLAlchemy — библиотека для работы с базами данных. Всю её мощь в асинхронном приложении пока использовать не получится (много блокирующих операций), поэтому возьмём из неё модели и возможность написания запросов без использования raw SQL. Для асинхронного Python не имеет альтернатив.
- alembic — библиотека для миграции к базе данных. Поддерживает возможность создания автоматических миграций на основе SqlAlchemy, что полезно для новичков.
Альтернативы:
- yoyo-migrations
- migrate
- aioamqp — коннектор к RabbitMQ. Этот брокер сообщений используется в крупных приложениях для асинхронного отказоустойчивого обмена данными.
Альтернативы:
- aiorabbit
- aio-pika
- manage.py — библиотека для удобного запуска приложений с возможностью передачи дополнительных параметров из консоли.
Альтернативы:
- Marshmallow — реализует удобную валидацию входящих данных.
Альтернативы:
- schematics
- jsonschema
- sanic-openapi — в связке с marshmallow позволяет генерировать документацию к API-методам в swagger.
Альтернативы:
- envparse — утилита для парсинга конфигов приложения.
Альтернативы:
- использовать
os.environ.get()из стандартной библиотеки.
- использовать
- APScheduler — асинхронная библиотека для запуска «кронов».
Альтернативы:
- async-cron
- AioHttp — фреймворк, часть функциональности которого будет использоваться для асинхронных HTTP-запросов.
Альтернативы:
- requests-async
Перечисленные выше зависимости тянут за собой другие библиотеки, полный список зависимостей можно изучить в файле requirements.txt.
После того, как мы выбрали стек технологий, рассмотрим расположение основных модулей приложения.
Структура проекта

alembic и alembic.ini
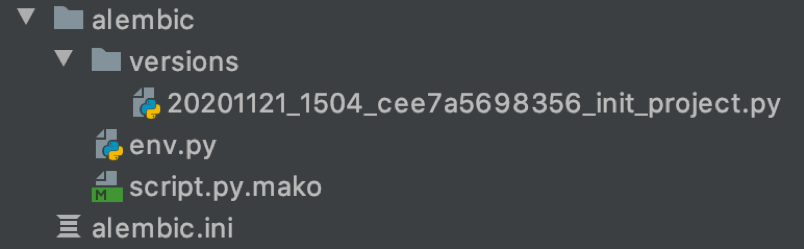
Содержат миграции приложения и конфигурацию для их запуска.
Типовая миграция:
from alembic import op
import sqlalchemy as sa
revision = 'cee7a5698356'
down_revision = None
branch_labels = None
depends_on = None
def upgrade():
op.create_table('student',
sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),
sa.Column('name', sa.String(), nullable=True),
sa.Column('active', sa.Boolean(), nullable=True),
sa.Column('created_at', sa.DateTime(), server_default=sa.text('now()'), nullable=True),
sa.Column('updated_at', sa.DateTime(), server_default=sa.text('now()'), nullable=True),
sa.PrimaryKeyConstraint('id')
)
def downgrade():
op.drop_table('student')
amqp
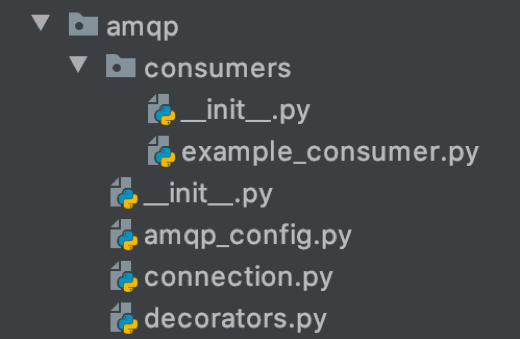
В consumers перечислены обработчики входящих сообщений. amqp_config содержит конфигурации для подключения к различным vhost. Prefix в конфигурации задаёт имя канала для дальнейшего использования в приложении. В connection перечислены базовые функции для удобного подключения к RabbitMQ с возможностью переподключения, а также биндинги exchange«ей и очередей (при старте приложения все необходимые для работы сущности должны автоматически создаваться из кода). В decorators можно найти декоратор для отказоустойчивой работы с сообщениями из очередей. При получении ошибки сообщение упадёт в альтернативную очередь, и через заданное время снова попадёт в основную. Если же за несколько попыток сообщение не удалось обработать, то оно будет переложено в третью очередь для дальнейшего «ручного» анализа программистами.
Пример самого простого обработчика сообщений:
import json
from sanic.log import logger
from models.student import Student
class ExampleConsumer:
def __init__(self, app):
self.app = app
async def handle(self, channel, body, envelope, properties):
logger.info('incoming msg {}'.format(body))
data = json.loads(body.decode())
async with self.app.db_engine.acquire() as conn:
await Student.create(conn=conn, values=data)
app

app.py содержит инициализацию Sanic-приложения с обслуживающими функциями, а в server.py находится его запуск.
Инициализировать приложение можно вот так:
def init_app(api=False, consume=False, schedule=False) -> AppSanic:
app = AppSanic(__name__, log_config=LOG_SETTINGS, strict_slashes=True)
app.exception(NotFound)(handle_404)
app.listener('before_server_start')(setup_connect)
app.listener('before_server_stop')(close_connect)
if api:
set_router(app)
if consume:
app.listener('before_server_start')(setup_amqp_connection)
app.listener('after_server_start')(start_consume_amqp)
app.listener('before_server_stop')(close_amqp_connection)
if schedule:
app.listener('before_server_start')(schedule_initializer)
app.blueprint(routes.srv)
return app
core
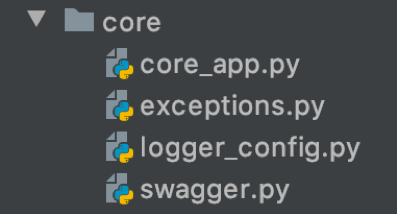
Папка core содержит вспомогательные функции для инициализации приложения.
handler
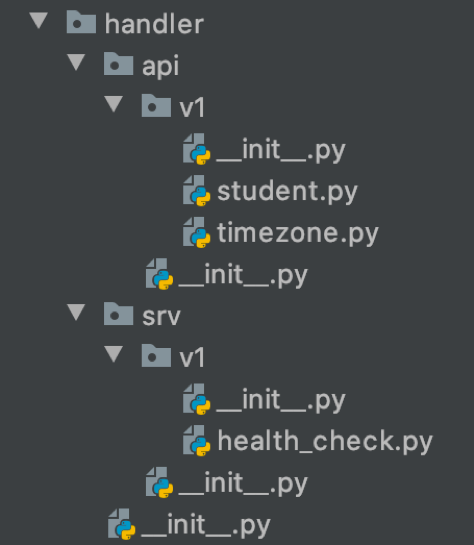
В этой папке лежат обработчики для API-методов. Маршрутизация к ним находится в файле routes.py в корне приложения.
Пример API по созданию новой записи и получения её по ID:
async def create_student(request: Request):
data = request['validated_json']
async with request.app.db_engine.acquire() as conn:
result = await Student.create(conn=conn, values=data)
return http_created(StudentResultSchema().dump(result))
async def get_student_by_id(request: Request, student_id):
async with request.app.db_engine.acquire() as conn:
result = await Student.get_by_id(conn=conn, student_id=student_id)
if not result:
return http_bad_request('student not found')
return http_ok(StudentResultSchema().dump(result))
lib

В lib представлены самописные классы и функции, используемые во всём проекте.
models
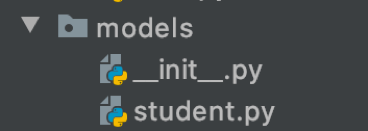
Папка models содержит модели для доступа к данным. Alembic умеет через reflection видеть изменения в этих моделях и создавать автоматические миграции через команду alembic revision --autogenerate.
Модель «Студент» с набором базовых действий с этой сущностью:
from datetime import datetime
from sqlalchemy import Column, String, Integer, Boolean, DateTime, text
from lib.db_mixin import DB
from . import Base
class Student(Base, DB):
__tablename__ = 'student'
id = Column(Integer, autoincrement=True, primary_key=True)
name = Column(String, nullable=True)
active = Column(Boolean, default=True, nullable=True)
created_at = Column(DateTime, default=datetime.utcnow, server_default=text('now()'))
updated_at = Column(DateTime, default=datetime.utcnow, server_default=text('now()'))
@classmethod
async def create(cls, conn, values):
cur = await Student.insert().values(
**values
).returning(Student.__table__).execute(conn)
result = await cur.first()
return dict(result)
@classmethod
async def update_by_id(cls, conn, student_id, values):
cur = await Student.update().values(
updated_at=datetime.utcnow(),
**values
).where(
Student.id == student_id
).returning(Student.__table__).execute(conn)
result = await cur.first()
return dict(result) if result else None
@classmethod
async def get_by_id(cls, conn, student_id):
result = await Student.select() \
.where(Student.id == student_id) \
.get(conn)
return dict(result) if result else None
@classmethod
async def get_all(cls, conn):
result = await Student.select() \
.where(Student.active.is_(True)) \
.all(conn)
return [dict(i) for i in result]
@classmethod
async def set_not_active_by_id(cls, conn, student_id):
await Student.update().values(active=False) \
.where(Student.id == student_id) \
.execute(conn)
@classmethod
async def delete_by_id(cls, conn, student_id):
await Student.delete() \
.where(Student.id == student_id) \
.execute(conn)
student_table = Student.__table__
modules
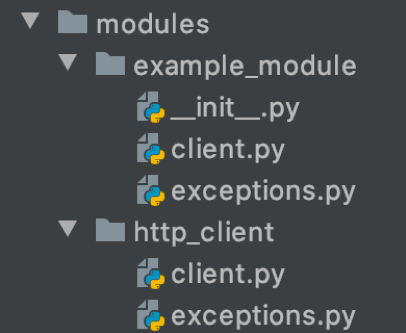
В modules представлен модуль с HTTP-клиентом для запросов к внешним сервисам, а также приведён пример клиента для получения данных с worldtimeapi.org.
from modules.http_client.client import BaseClient
import settings
class TimezoneApiClient(BaseClient):
service_url = settings.TIMEZONE_API_HOST
request_hooks = [
'auth_request',
]
current_time_url = 'timezone/{area}/{city}'
def auth_request(self, kwargs):
if 'headers' not in kwargs:
kwargs['headers'] = {}
kwargs['headers'].update({
# 'Authorization': 'settings.EXAMPLE_TOKEN',
'Accept': 'application/json'
})
async def get_time(self, area, city):
response = await self.get(self.get_full_url('current_time_url', area=area, city=city))
return response
schedule

Расписание запускаемых «кронов» находится в __init__.py, код периодических функций лежит в остальных .py-файлах папки schedule.
Самый простой «крон»:
from sanic import Sanic
from sanic.log import logger
from apscheduler.schedulers.asyncio import AsyncIOScheduler
from models.student import Student
async def example_schedule(app):
logger.info('start example_schedule')
async with app.db_engine.acquire() as conn:
all_students = await Student.get_all(conn=conn)
for s in all_students:
await Student().update_by_id(
conn=conn,
student_id=s['id'],
values={
'name': s['name'] + '_new'
}
)
logger.info('end example_schedule')
def initialize_scheduler(app: Sanic, loop):
scheduler = AsyncIOScheduler({
'event_loop': loop,
'apscheduler.timezone': 'UTC',
})
scheduler.add_job(example_schedule, 'interval', minutes=1, kwargs={'app': app})
scheduler.add_job(example_schedule, 'cron', hour="*", minute=00, kwargs={'app': app})
return scheduler
schemas
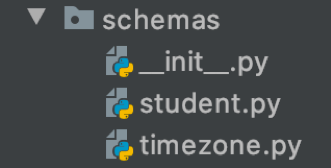
В этой папке находятся marshmallow-схемы, используемые как в handlers, так и в остальных модулях проекта.
Пример валидации входных и выходных данных сущности «Студент»:
from marshmallow import fields
from lib.schema import BaseSchema
class CreateStudentSchema(BaseSchema):
name = fields.String(required=True)
class UpdateStudentSchema(BaseSchema):
name = fields.String(required=True)
class StudentResultSchema(BaseSchema):
id = fields.Integer(required=True)
name = fields.String(required=True)
active = fields.Boolean(required=True)
created_at = fields.DateTime(format='%Y-%m-%dT%H:%M:%S+00:00', required=True)
updated_at = fields.DateTime(format='%Y-%m-%dT%H:%M:%S+00:00', required=True)
Теперь, когда мы разобрались со структурой и особенностями приложения, можно перейти к его запуску.
Запуск

Перед запуском необходимо поднять базу и RabbitMQ через команду
docker-compose upТакже прогоним миграции командой
alembic upgrade headЗапуск приложения благодаря библиотеке manage.py похож на локальный запуск Django-проектов:
- Веб-сервер —
python manage.py run - Консьюмеры —
python manage.py consume - Кроны —
python manage.py schedule
При работе в API-режиме в случае запуска приложения на многоядерном сервере можно установить количество внутренних процессов равным количеству ядер сервера с помощью переменной среды
WORKERS (либо через os.cpu_count()). При запуске в режиме консьюмера работу тестового консьюмера можно проверить через веб-панель RabbitMQ (находится по адресу http://localhost:15672/, сервер слушает очередь example.main).
Работу планировщика задач можно увидеть по сообщениям в логах либо по изменению данных в базе, — если через API добавить несколько тестовых студентов.
Документация

Самым удобным, на мой взгляд, способом отображения документации является Swagger. Чтобы описанные в нём форматы данных не расходились с реальным кодом, необходимо сделать так, чтобы они генерировались из одних и тех же схем. Для этого мы будем использовать библиотеку sanic_openapi и самописную функцию
open_api_schemas.@doc.summary('Обновление записи "Студент"')
@doc.consumes(open_api_schemas(UpdateStudentSchema()), location='body')
@doc.produces(open_api_schemas(StudentResultSchema()))
@validate_json(UpdateStudentSchema)
async def update_student_by_id(request: Request, student_id):
data = request['validated_json']
async with request.app.db_engine.acquire() as conn:
result = await Student.update_by_id(conn=conn, student_id=student_id, values=data)
if not result:
return http_bad_request('student not found')
return http_ok(StudentResultSchema().dump(result))
Документация приложения расположена по адресу
http://0.0.0.0:8090/swagger/#/. Чтобы включить её отображение, необходимо проставить переменную среды DEBUG в значение True. Сделать это можно либо bash-командой export DEBUG=True, либо создав файл .env в корне проекта и написав туда аналогичную строчку.Для тестового проекта документация будет иметь вид:

А что дальше?

Первый этап закончен, теперь приложение может принимать входящие запросы, читать сообщения из RabbitMQ и выполнять периодические задания. Но оно всё ещё не «production ready».
Чтобы это исправить, надо:
- Покрыть код приложения тестами (рекомендую pytest).
- Разработать декораторы и middleware для авторизации и контроля доступа к данным.
- Настроить сборщик логов и подключить Sentry.
- Начать собирать метрики приложения (например, с помощью Prometheus) и выставить по ним оповещения.
- Подключить системы для кеширования данных (например, Redis).
- Собрать приложения в Docker, подготовить его к работе на тестовых и боевых стендах.
- Провести нагрузочное тестирование для выявления узких мест и правильного выставления лимитов по ресурсам.
Если эти темы интересны, могу описать их в следующих статьях.
Исходный код библиотеки доступен на GitHub под MIT лицензией.
В комментариях было бы интересно узнать про конфигурации ваших асинхронных приложений, а также их достоинства и недостатки.
