[recovery mode] Лента новостей: почему мы делаем это неправильно?
Здравствуй, меня зовут Дмитрий Карловский и у меня для вас новость. Ну как новость, свежий взгляд на привычную вещь в виде очередной статьи. Скорее всего вы попадёте на неё из какой-либо ленты новостей. Или не попадёте, если новость будет опубликована не вовремя. Независимо от того, насколько данная статья была бы вам интересна.
Всё дело в том, как формируются ленты и как пользователь с ними взаимодействует. И тут, к сожалению, как обычно, самое простое решение — предельно неправильное. Давайте разберёмся почему.
Допустим пользователь запросил у нас список каких-то сущностей. То, как пользователь будет эти сущности просматривать, зависит от его целей. Способов потребления можно выделить два:
-
Активный поиск. Пользователь ищет что-то конкретное. Он применяет фильтрацию и сортировку, чтобы сузить выдачу, после чего последовательно просматривает материалы, проверяя каждый из них. Тут важно, чтобы просматриваемый список не менялся в процессе просмотра иначе легко можно проскочить то, что ищешь.
-
Пассивный поиск. Пользователь не ищет ничего конкретного. Наоборот, он хочет, чтобы сервис посмотрел что у этого сервиса есть и вывел пользователю то, что будет тому интересно. Тут как раз важно показывать пользователю наиболее релевантные материалы на данный момент для конкретного пользователя. А то, что он уже видел — вообще не показывать.
Итак, ленты новостей предназначены как раз для пассивного потребления этих самых новостей. Да, пользователь может ограничить круг интересов с помощью фильтров, но он не ищет какую-то конкретную новость, так как скорее всего про неё ещё не знает и зашёл в ленту, чтобы как раз о ней узнать. И его удовлетворённость зависит от того, насколько больше интересных (релевантных) материалов он увидит и сколько неинтересных не увидит.
На релевантность могут влиять множество факторов. Например, изменение приоритета назначенной на тебя задачи в менеджере задач — очень важная новость, которую стоит показать пользователю как можно раньше. Даже если после этого появились комментарии у десятка других задач.
Но есть и общие критерии, такие как:
- Просмотренность. Если пользователь уже видел эту новость и как-то на неё отреагировал (промотал, удалил, пометил как прочтённую, перешёл к подробностям и тп), то второй раз он её видеть уже не хочет.
- Актуальность. Некоторые новости теряют свою актуальность с появлением более свежих новостей на ту же тему. Например, из новостей об изменении статуса выполнения задачи интересна лишь самая последняя, отражающая актуальное состояние.
- Дата. Свежие новости часто более интересны. А некоторые старые новости уже настолько не интересны, что их лучше вообще не показывать (например, новость о том, что неделю назад отключали на день горячую воду).
В подавляющем большинстве случаев ленты новостей формируются путём выдачи материалов отсортированных по дате их создания, публикации или изменения. То есть остальные (более важные) критерии релевантности попросту не учитываются. В конечном счёте это приводит к неудовлетворённости пользователя. Несколько примеров для иллюстрации:
Лента ВКонтакте
Пользователь открывает новости первый раз и последовательно их просматривает — тут всё хорошо. Через некоторое время сверху появляется уведомление, что появилось несколько свежих новостей. И тут у него появляется не хитрый выбор:
- Продолжать листать ленту
- Перемотать ленту на начало, чтобы увидеть свежие новости (которые не факт, что более релевантные).
Так как лента квазибесконечная, а вкладка браузера не может жить вечно, да и любопытство никто не отменял. Так что рано или поздно пользователь вновь окажется в «начале» ленты. Ок, листаем вниз. Ничто не предвещает беды, как вдруг начинают идти новости, которые пользователь уже видел. И тут опять у пользователя не хитрый выбор:
- Быстро-быстро мотать ленту, спуская интернет трафик в трубу, в надежде домотать до новостей, которые ещё он не видел.
- Забить на ленту и заняться чем-то другим.
Получается каждый раз, когда пользователь не домотал до каких-то новостей, то он уже никогда их не видит. А ведь они могли бы оказаться ему интересны. Более того, они могли оказаться критически важными и кардинальным образом изменить его жизнь.
Эта проблема настолько типична, что ей впору дать специальное название. Пусть это будет «Синдромом Фрагментарной Осведомлённости».
Главная Хабра
СФО тут усугубляется паджинацией. При переходе между страницами пользователь видит новости с предыдущей страницы. А если он задержится на какой-то странице чуть дольше, то он запросто может получить несколько страниц «боянов» подряд. Подробнее я расписал эту проблему в заметке про паджинацию.
Ютуб
В «рекомендованных» просто выдают 18 зачастую боянистых видеороликов и всё. Чтобы увидеть в рекомендациях что-то новое, нужно вручную поудалять всё то, что не вызвало интереса. Разумеется редкий пользователь таким будет заниматься. В «подписках» — просто сортируют по дате, из-за чего старые, но возможно интересные пользователю ролики, он никогда не увидит. Разве что случайно наткнётся на них в «рекомендованном».
Когда пользователь только открыл ленту первый раз, у него есть только одна точка поступления новостей — сразу после предыдущей просмотренной. Он просматривает их вниз и вдруг появляется вторая точка поступления — где-то вверху. И сложно сказать где новости релевантней. Когда же после некоторого перевыва он возвращается, то у него сразу есть не меньше двух точек: начало ленты и то место, где он закончил смотреть новости последний раз. А так как частно пользователь не имеет возможность досмотреть новости до ранее просмотренных, то эти точки поступления новостей множатся и множатся.
Точка поступления релевантных новостей должна быть только одна. При этом в неё должны поступать наиболее релевантные новости в режиме реального времени. Среди всех новостей можно выделить следующие группы:
- Видимые. Те новости, что мы ранее ему подобрали и он видит сейчас на экране.
- Просмотренные. Новости, которые пользователь уже посмотрел и промотал. Когда новость уходит из видимой области наверх — можно смело помечать её как прочитанную.
- История. Список новостей, сформированный для конкретного пользователя. Сюда входят как те новости, что пользователь уже просмотрел, так и те на которые он смотрит прямо сейчас.
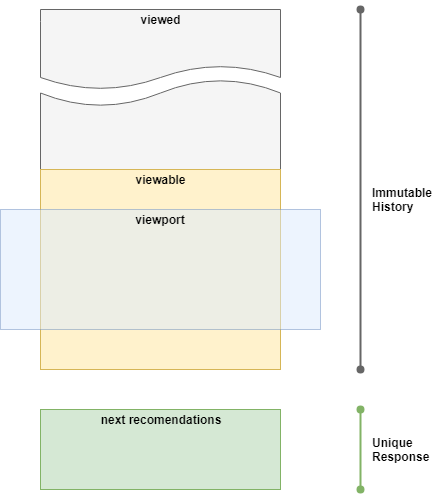
В идеале даже перезагрузка страницы не должна ничего менять в списке новостей. Когда пользователь запрашивает ещё новостей (нажатием кнопки или прокруткой вниз), мы подбираем ещё порцию самых релевантных на текущий момент новостей и подкладываем их в историю. Таким образом у пользователя есть чёткое представление о ленте, как о чём-то интересном и не меняющемся. Всё, что он когда-либо видел располагается в том порядке, в котором он это видел. А мотая вниз он постоянно получает что-то интересное, не беспокоясь, что что-то пропустит. Правда возможно мотать придётся долго, если новостей много.
Самое простое, конечно, просто считать свежие новости более релевантными. Но можно позволить пользователю помочь сервису понять что его интересует, а что нет. Сделать это можно добавив возможность удаления новостей. Если пользователь не просто промотал новость, а удалил её, чтобы та не засоряла его историю, значит такого типа новости ему не интересны и эту информацию можно использовать для последующей подборки.
Так как история у нас пополняется и просматривается с конца, то мы не можем использовать традиционную паджинацию, ведь новости тогда будут постоянно перескакивать между страницами. Кроме того, запрос какой-нибудь 100500 страницы для СУБД может оказаться слишком тяжеловесным. Поэтому для выборки данных мы будет использовать якоря. Для этого в запросе мы будем указывать следующие данные:
- Якорь. Идентификатор новости, начиная с которой нужно возвращать данные. Если якорь не указан, то в качестве якоря берётся последняя прочитанная новость.
- Смещение. Число новостей для выборки. Это число может быть положительным и тогда возвращаются новости после якорной. Либо отрицательным и тогда возвращаются новости до якорной.
Если смещение отрицательное, а нужного числа новостей до якорной нет, то просто возвращается сколько есть. По разнице числа запрощенных и числа пришедших клиент может понять, что мы упёрлись в начало истории.
Если смещение положительное, а нужного числа новостей после якорной нет, то история дополняется до нужного числа наиболее релевантными на данный момент новостями. Если же новости совсем закончились, то опять же, возвращаем сколько есть и клиент детектирует конец ленты.
Открываем ленту, никакого якоря у нас ещё нет:
GET /feed?offset=5
Делаем запрос за непрочитанными новостями:
SELECT FROM history WHERE user = 123 AND read_at NOT NULL ORDER BY id ASC limit 5
Пользователь видит подборку непрочитанных новостей, на которых остановился в прошлый раз:
[ { id : 3232 } , { id : 5343 } , { id : 34343 } , { id : 982 } , { id : 7346 } ]
Пользователь мотает вверх, чтобы увидеть новость, которую видел в прошлый раз:
GET /feed?anchor=3232&offset=-5
SELECT FROM history WHERE user = 123 AND id < 3232 ORDER BY id DESC limit 5
[ { id : 898 } , { id : 323 } , { id : 544 } , { id : 843 } , { id : 329 } ]
Пользователь мотает вниз, дабы увидеть что-то новое:
GET /feed?anchor=7346&offset=5
SELECT FROM history WHERE user = 123 AND id > 7346 ORDER BY id ASC limit 5
Если получили мало новостей — отбираем нужное число наиболее релевантных из отсутствующих в истории и добавляем их в историю, после чего возвращаем всё вместе:
[ { id : 437874 } , { id : 483974 } , { id : 48375 } , { id : 839473 } , { id : 326763 } ]
Если вы знаете какие-либо сервисы, реализующие ленты таким или похожим образом, буду рад разместить ссылки на них тут, чтобы читатели смогли сами оценить удобство такого подхода.
