[recovery mode] Кластеризация беспроводных точек доступа с использованием метода k-средних
Визуализация и анализ данных в настоящее время широко применяется в телекоммуникационной отрасли. В частности, анализ в значительной степени зависит от использования геопространственных данных. Возможно, это связано с тем, что телекоммуникационные сети сами по себе географически разбросаны. Соответственно, анализ таких дисперсий может дать огромную ценность.
Данные
Чтобы проиллюстрировать алгоритм кластеризации k-средних мы воспользуемся базой географических данных для бесплатного общественного WiFi в Нью-Йорке. Набор данных доступен в NYC Open Data. В частности, алгоритм кластеризации k-средних используется для формирования кластеров использования WiFi на основе данных широты и долготы.
Из самого набора данных данные о широте и долготе извлекаются с использованием языка программирования R:
#1. Prepare data
newyork<-read.csv("NYC_Free_Public_WiFi_03292017.csv")
attach(newyork)
newyorkdf<-data.frame(newyork$LAT,newyork$LON)
Вот фрагмент данных:
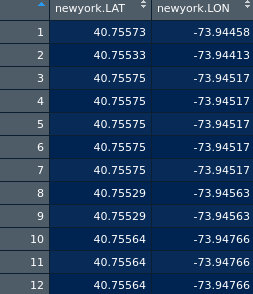
Определяем количество кластеров
Далее определяем количество кластеров с помощью ниже приложенного кода, который показывает результат в виде графика.
#2. Determine number of clusters
wss <- (nrow(newyorkdf)-1)*sum(apply(newyorkdf,2,var))
for (i in 2:20) wss[i] <- sum(kmeans(newyorkdf,
centers=i)$withinss)
plot(1:20, wss, type="b", xlab="Number of Clusters",
ylab="Within groups sum of squares")
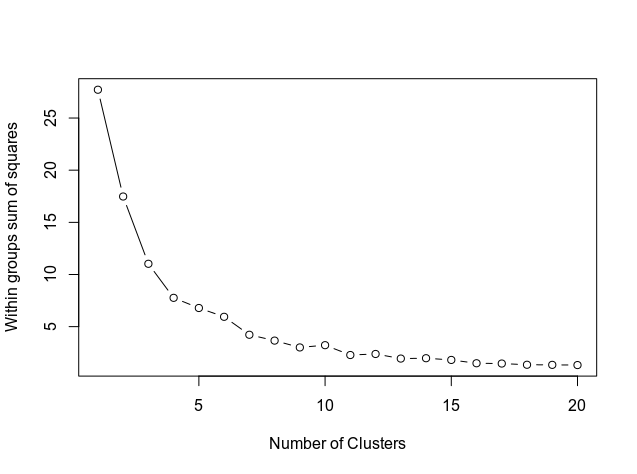
На графике видно, как кривая выравнивается примерно на отметке 11. Следовательно, это количество кластеров, которые будут использоваться в модели k-средних.
Анализ K-средних
Сам анализ K-средних проводится:
#3. K-Means Cluster Analysis
set.seed(20)
fit <- kmeans(newyorkdf, 11) # 11 cluster solution
# get cluster means
aggregate(newyorkdf,by=list(fit$cluster),FUN=mean)
# append cluster assignment
newyorkdf <- data.frame(newyorkdf, fit$cluster)
newyorkdf
newyorkdf$fit.cluster <- as.factor(newyorkdf$fit.cluster)
library(ggplot2)
ggplot(newyorkdf, aes(x=newyork.LON, y=newyork.LAT, color = newyorkdf$fit.cluster)) + geom_point()
Во наборе данных newyorkdf имеется информация о широте, долготе и метка кластера:
> newyorkdf
newyork.LAT newyork.LON fit.cluster
1 40.75573 -73.94458 1
2 40.75533 -73.94413 1
3 40.75575 -73.94517 1
4 40.75575 -73.94517 1
5 40.75575 -73.94517 1
6 40.75575 -73.94517 1
…
80 40.84832 -73.82075 11
Вот наглядная иллюстрация:
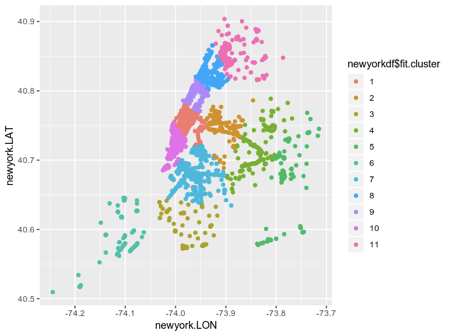
Эта иллюстрация полезна, но визуализация будет еще ценнее если наложить ее на карту самого Нью-Йорка.
# devtools::install_github("zachcp/nycmaps")
library(nycmaps)
map(database="nyc")
#this should also work with ggplot and ggalt
nyc <- map_data("nyc")
gg <- ggplot()
gg <- gg +
geom_map(
data=nyc,
map=nyc,
aes(x=long, y=lat, map_id=region))
gg +
geom_point(data = newyorkdf, aes(x = newyork.LON, y = newyork.LAT),
colour = newyorkdf$fit.cluster, alpha = .5) + ggtitle("New York Public WiFi")

Этот тип кластеризации дает отличное представление о структуре сети WiFi в городе. Это указывает на то, что географический регион, отмеченный кластером 1, показывает большой трафик WiFi. С другой стороны, меньшее количество соединений в кластере 6 может указывать на низкий трафик WiFi.
Кластеризация K-Means сама по себе не говорит нам, почему трафик для конкретного кластера высок или низок. Например, когда кластер 6 имеет высокую плотность населения, но низкая скорость интернета приводит к меньшему количеству соединений.
Однако этот алгоритм кластеризации обеспечивает отличную отправную точку для дальнейшего анализа и облегчает сбор дополнительной информации. Например, на примере данной карты можно строить гипотезы касательно отдельных географических кластеров. Оригинал статьи находится тут.
