[recovery mode] Как я делаю OCR
Привет меня зовут Игорь, в свободное от основной профессии время я интересуюсь машинным обучением и занимаюсь разработкой OCR для мобильных устройств.
Современные решения OCR насколько мне известно в большинстве случаев состоят из двух компонентов, детектирование текста и последующее распознавание.
Для обучения требуется много качественно размеченных данных, и в случае с детектированием текста это настоящая проблема, найти в открытом доступе большой качественный датасет очень сложно.
Для решения проблемы я написал собственную программу для разметки данных.
Работа в программе должна быть проста предельно проста и эффективна, увеличение и уменьшение изображения, перетаскивание, создание и удаление объектов, разметка происходит только с помощью мышки.
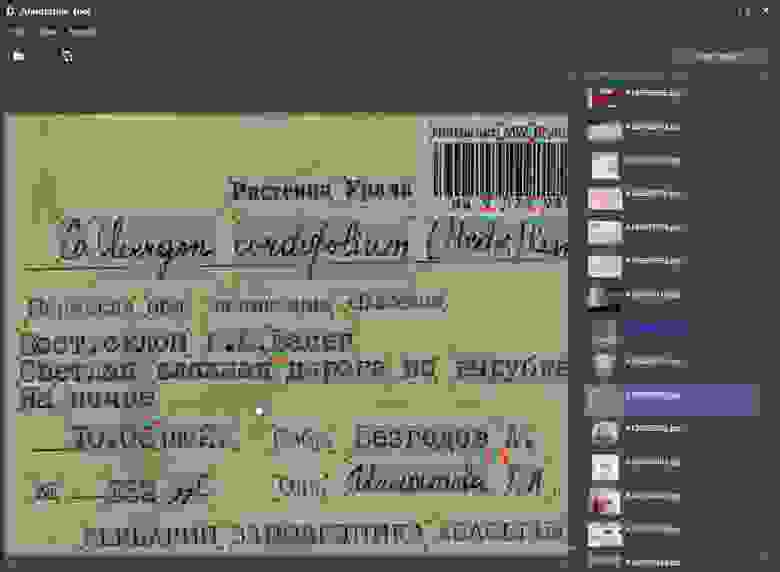
На каком то этапе разметки я натренировал в keras сетку DBNet, законвертил её в TensorFlow Lite, и дело пошло в разы быстрей, в полуавтоматическом режиме, теперь приходилось больше корректировать.
В течении нескольких месяцев в свободное время я собирал и размечал изображения.
В итоге удалось собрать и разметить 19 230 изображений содержащих преимущественно латинский и русский текст, а так же немного на китайском.

Используя данный датасет я натренировал в Keras выше указанную DBNet сеть на основе ResNet50V2, результат детектирования после месячной тренировки на одной GeForce RTX 2060 Ghost 12GB выглядит следующим образом.

Похоже пора переходить ко второму этапу, распознавание текста.
А для тех кто не хочет собирать данные, вы можете использовать мой датасет.
Успехов в машинном обучении!
