[Перевод] Знакомство с реактивными потоками – для Java-разработчиков
Привет, Хабр!
Сегодня мы вернемся к одной из тем, затрагиваемых в нашей замечательной книге «Реактивные шаблоны проектирования». Речь пойдет об Akka Streams и потоковой передаче данных в целом — в книге Роланда Куна этим вопросам посвящены главы 10 и 15–17.
Реактивные потоки — это стандартный способ асинхронной обработки данных в потоковом стиле. Они были включены в Java 9 как интерфейсы java.util.concurrent.Flow, а сейчас становятся настоящей палочкой-выручалочкой для создания потоковых компонентов в различных приложениях — и такая расстановка сохранится на протяжении ближайших лет. Следует отметить, что реактивные потоки — «просто» стандарт, а сами по себе ни на что не годятся. На практике используется та или иная конкретная реализация этого стандарта, и сегодня мы поговорим об Akka Streams — одной из ведущих реализаций реактивных потоков с момента их зарождения.
Контекст
Типичный конвейер потоковой обработки состоит из нескольких шагов, на каждом из которых информация передается на следующий шаг (то есть, по нисходящей). Итак, если взять два смежных шага и считать вышестоящий поставщиком, а следующий за ним — потребителем данных, то окажется, что поставщик может работать либо медленнее потребителя, либо быстрее его. Когда поставщик работает медленнее — все нормально, но ситуация осложняется, если потребитель не поспевает за поставщиком. В таком случае потребитель может переполниться данными, которые ему приходится (в меру сил) аккуратно обрабатывать.
Простейший способ справиться с избытком данных — взять и отбросить все, что не удается обработать. Именно так и поступают, например, при работе с сетевым оборудованием. Но что делать, если мы вообще ничего не хотим отбрасывать? Тогда нам пригодится обратное давление (backpressure)
Идея обратного давления очень важна в контексте Reactive Streams и сводится к тому, что мы ограничиваем объем данных, передаваемых между соседними звеньями конвейера, поэтому ни одно звено не переполняется. Поскольку важнейший аспект реактивного подхода — не допускать блокировок за исключением случаев, когда это совершенно необходимо, реализация обратного давления в реактивном потоке также должна быть неблокирующей.
Как это делается
Стандарт Reactive Streams определяет ряд интерфейсов, но не реализацию как таковую. Это значит, что, просто добавив зависимость к org.reactivestreams: reactive-streams, мы просто топчемся на месте — нам все равно нужна конкретная реализация. Существует множество реализаций Reactive Streams, и в этой статье мы воспользуемся Akka Streams и соответствующим DSL на основе Java. Среди других реализаций можно упомянуть RxJava 2.x или Reactor и др.
Пример использования
Допустим, у нас есть каталог, в котором мы хотим отслеживать новые CSV-файлы, затем каждый файл обрабатывать по потоковому принципу, на лету выполнять кое-какую агрегацию, а собранные таким образом результаты отправлять на веб-сокет (в реальном времени). Кроме того, мы хотим задать некий порог накопления агрегированных данных, по достижении которого будет инициироваться уведомление по электронной почте.
В нашем примере в строках CSV будут пары (id, value), причем, id будет меняться раз в две строки, например:
370582,0.17870700247256666
370582,0.5262255382633264
441876,0.30998025265909457
441876,0.3141591265785087
722246,0.7334219632071504
722246,0.5310146239777006
Мы хотим рассчитать среднее значение value для двух строк с общим id и отправлять его на веб-сокет лишь в том случае, если оно превышает 0.9. Более того, мы хотим отправлять по электронной почте уведомление после каждого пятого значения, поступающего на веб-сокет. Наконец, мы хотим считывать и отображать данные, полученные с веб-сокета, и это будет делаться через тривиальный фронтенд, написанный на JavaScript.
Архитектура
Мы собираемся использовать ряд инструментов из экосистемы Akka (см. рис. 1). Естественно, в центре всей системы будет находиться Akka Streams, которая позволяет обрабатывать данные в реальном времени по потоковому принципу. Для считывания CSV-файлов мы воспользуемся Alpakka, это набор соединителей для интеграции Akka Streams с различными технологиями, протоколами или библиотеками. Интересно, что, поскольку Akka Streams — это реактивные потоки, вся экосистема Alpakka также доступна и любой другой реализации RS — именно такой выигрыш в интероперабельности призваны достичь is RS-интерфейсы. Наконец, мы воспользуемся Akka HTTP, по которому предоставим конечную точку веб-сокета. Самое приятное в данном случае — Akka HTTP бесшовно интегрируется с Akka Streams (которую, фактически, и использует «под капотом»), поэтому предоставить поток в качестве веб-сокета не составляет труда.
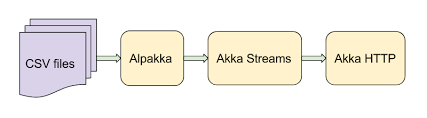
Рис. 1. Обзор архитектуры
Если сравнить эту схему с классической архитектурой Java EE, то, вероятно, заметно, что здесь все устроено гораздо проще. Никаких контейнеров и бинов, а лишь простое автономное приложение. Более того, стек Java EE вообще не поддерживает потоковый подход.
Основы Akka Streams
В Akka Streams конвейер обработки (граф) состоит из элементов трех типов Source (источник), Sink (уловитель)и Flow-ы (шаги обработки).
На базе этих компонентов определяем наш граф, который, в сущности — просто рецепт для обработки данных. Никаких вычислений там не производится. Чтобы конвейер заработал, нам нужно материализовать граф, то есть, привести его в запускаемую форму. Для этого вам понадобится так называемый материализатор, оптимизирующий определение графа и, в конечном итоге, запускающий его. Однако, встроенный ActorMaterializer фактически безальтернативен, поэтому вы вряд ли будете пользоваться какой-либо иной реализацией.
Если внимательно присмотреться к параметрам типов компонентов, то заметно, что каждый компонент (кроме соответствующих типов ввода/вывода) имеет таинственный тип Mat. Он относится к так называемому «материализованному значению» — это значение, доступное извне графа (в противоположность типам ввода/вывода, доступным только для внутренней коммуникации между шагами графа — см. рис. 2). Если вы предпочитаете игнорировать материализованное значение (а такое часто случается, если нас интересует всего лишь передача данных между шагами графа), то для обозначения такого варианта есть специальный параметр типа: NotUsed. Его можно сравнить с Void из Java, однако, семантически он чуть нагруженнее: в смысловом отношении «мы не используем этого значения» информативнее Void. Также отмечу, что в некоторых API используется схожий тип Done, сигнализирующий, что та или иная задача завершена. Пожалуй, другие библиотеки Java в обоих этих случаях использовали бы Void, но в Akka Streams все типы стараются по максимуму наполнить полезной семантикой.
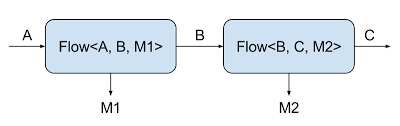
Рис. 2. Описание параметров типа Flow
Приложение
Теперь давайте перейдем к конкретной реализации обработчика CSV. Для начала определим граф Akka Streams, а потом по протоколу Akka HTTP соединим поток с веб-сокетом.
Составные элементы потокового конвейера
На входной точке нашего потокового конвейера мы хотим отслеживать, появились ли в интересующем нас каталоге новые CSV-файлы. Хотелось бы использовать для этого java.nio.file.WatchService, но, поскольку у нас потоковое приложение, нужно получить источник событий (Source) и с ним и работать, а не организовывать все через обратные вызовы. К счастью, такой Source уже доступен в Alpakka в форме одного из соединителей DirectoryChangesSource, входит в состав alpakka-file, где «под капотом» используется WatchService:
private final Source, NotUsed> newFiles =
DirectoryChangesSource.create(DATA_DIR, DATA_DIR_POLL_INTERVAL, 128);
Так получаем источник, выдающий нам элементы типа Pair. Мы собираемся отфильтровывать их так, чтобы подбирать лишь новые CSV-файлы, а затем передавать их «вниз». Для такого преобразования данных, а также для всех последующих мы будем пользоваться маленькими элементами, именуемыми Flow, из которых затем сложится полноценный конвейер обработки:
private final Flow, Path, NotUsed> csvPaths =
Flow.>create()
.filter(this::isCsvFileCreationEvent)
.map(Pair::first);
private boolean isCsvFileCreationEvent(Pair p) {
return p.first().toString().endsWith(".csv") && p.second().equals(DirectoryChange.Creation);
}
Можно создать Flow, к примеру, при помощи обобщенного метода create()— он полезен, когда сам входной тип обобщенный. Здесь результирующий поток будет порождать (в виде Path) каждый новый CSV-файл, появляющийся в DATA_DIR.
Теперь мы собираемся преобразовать Path-ы в строки, потоком выбираемые из каждого файла. Чтобы превратить источник в другой источник, можно воспользоваться одним из методов flatMap*. В обоих случаях мы создаем Source из каждого входящего элемента и каким-либо образом комбинируем несколько получившихся источников в новый, цельный, сцепляя или сливая исходные источники. В данном случае мы остановимся на flatMapConcat, поскольку хотим сохранить порядок строк, так, чтобы строки с одинаковыми id остались рядом друг с другом. Чтобы преобразовать Path в поток байт, воспользуемся встроенной утилитой FileIO:
private final Flow fileBytes =
Flow.of(Path.class).flatMapConcat(FileIO::fromPath);
На этот раз воспользуемся методом of() для создания нового потока — он удобен, когда входной тип не является обобщенным.
Показанный выше ByteString — это представление последовательности байт, принятое в Akka Streams. В данном случае мы хотим разобрать поток байт как CSV-файл — и для этого вновь воспользуемся одним из модулей Alpakka, на этот раз alpakka-csv:
private final Flow, NotUsed> csvFields =
Flow.of(ByteString.class).via(CsvParsing.lineScanner());
Обратите внимание на используемый здесь комбинатор via, позволяющий прикрепить произвольный Flow к выводу, полученному на другом шаге графа (Source или другой Flow). В результате получается поток элементов, каждый из которых соответствует полю в отдельно взятой строке CSV-файла. Затем их можно преобразовать в модель нашей предметной области:
class Reading {
private final int id;
private final double value;
private Reading(int id, double value) {
this.id = id;
this.value = value;
}
double getValue() {
return value;
}
@Override
public String toString() {
return String.format("Reading(%d, %f)", id, value);
}
static Reading create(Collection fields) {
List fieldList = fields.stream().map(ByteString::utf8String).collect(toList());
int id = Integer.parseInt(fieldList.get(0));
double value = Double.parseDouble(fieldList.get(1));
return new Reading(id, value);
}
}
Для преобразования как такового используем метод map и передаем ссылку на метод Reading.create:
private final Flow, Reading, NotUsed> readings =
Flow.>create().map(Reading::create);
На следующем этапе мы должны сложить показания в пары, вычислить для каждой группы среднее значение value и передавать информацию далее лишь при достижении определенного порога. Поскольку нам требуется, чтобы среднее вычислялось асинхронно, мы воспользуемся методом mapAsyncUnordered, выполняющим асинхронную операцию с заданным уровнем параллелизма:
private final Flow averageReadings =
Flow.of(Reading.class)
.grouped(2)
.mapAsyncUnordered(10, readings ->
CompletableFuture.supplyAsync(() ->
readings.stream()
.map(Reading::getValue)
.collect(averagingDouble(v -> v)))
)
.filter(v -> v > AVERAGE_THRESHOLD);
Определив вышеуказанные компоненты, мы готовы сложить из них цельный конвейер (при помощи уже знакомого вам комбинатора via). Это совершенно не сложно:
private final Source liveReadings =
newFiles
.via(csvPaths)
.via(fileBytes)
.via(csvFields)
.via(readings)
.via(averageReadings);
Примечание
При комбинировании компонентов так, как показано выше, компилятор предохраняет нас, не давая случайно соединить два блока, содержащие несовместимые типы данных.
Поток как веб-сокет
Теперь воспользуемся Akka HTTP для создания простого веб-сервера, который будет играть такие роли:
- Предоставлять источник показаний как веб-сокет,
- Выдавать тривиальную веб-страницу, которая подключается к веб-сокету и отображает полученные данные.
Ничего не стоит создать веб-сервер при помощи Akka HTTP: нужно просто унаследовать HttpApp и предоставить требуемые отображения по DSL маршрута:
class Server extends HttpApp {
private final Source readings;
Server(Source readings) {
this.readings = readings;
}
@Override
protected Route routes() {
return route(
path("data", () -> {
Source messages = readings.map(String::valueOf).map(TextMessage::create);
return handleWebSocketMessages(Flow.fromSinkAndSourceCoupled(Sink.ignore(), messages));
}
),
get(() ->
pathSingleSlash(() ->
getFromResource("index.html")
)
)
);
}
}
Здесь определяется два маршрута: /data, то есть, конечная точка веб-сокета, и / по которому выдается тривиальный фронтенд. Уже понятно, насколько просто предоставить Source из Akka Streams в качестве конечной точки веб-сокета: берем handleWebSocketMessages, задача которого — усовершенствовать HTTP-соединение до соединения с веб-сокетом и организовать там поток, в котором будут обрабатываться входящие и исходящие данные.
WebSocket моделируется в виде потока, то есть, на клиент посылаются исходящие и входящие сообщения. В данном случае мы хотим игнорировать входящие данные и создаем такой поток, «входящая» сторона которого заведена в Sink.ignore(). «Исходящая» сторона потока обработчика веб-сокета просто связана с нашим источником, из которого поступают средние значения. Все, что приходится сделать с числами double, в виде которых представлены средние — преобразовать каждое из них в TextMessage, это применяемая в Akka HTTP обертка для данных веб-сокета. Все элементарно делается при помощи уже знакомого нам метода map.
Чтобы запустить сервер, нужно всего лишь запустить метод startServer, указав хост-имя и порт:
Server server = new Server(csvProcessor.liveReadings);
server.startServer(config.getString("server.host"), config.getInt("server.port"));
Фронтенд
Чтобы получать данные с веб-сокета и отображать их, воспользуемся совершенно простым кодом на JavaScript, который просто прикрепляет полученные значения к textarea. В этом коде используется синтаксис ES6, который должен нормально выполняться в любом современном браузере.
let ws = new WebSocket("ws://localhost:8080/data");
ws.onopen = () => log("WS connection opened");
ws.onclose = event => log("WS connection closed with code: " + event.code);
ws.onmessage = event => log("WS received: " + event.data);
Метод log прикрепляет сообщение к textarea, а также ставит метку времени.
Запуск
Чтобы запустить и протестировать приложение, нужно:
- запустить сервер (
sbt run), - перейти в браузере на localhost:8080 (или к выбранным вами хосту/порту, если вы изменили умолчания),
- скопировать один или несколько файлов из
src/main/resources/sample-dataв каталогdataв корне проекта (если вы не менялиcsv-processor.data-dirв конфигурации), - смотреть, как данные выводятся в логах сервера и в браузере.
Добавляем почтовый триггер
Последний штрих в нашем приложении — побочный канал, в котором мы будем имитировать почтовые оповещения, отсылаемые после поступления на веб-сокет каждого пятого элемента. Он должен работать «сбоку», чтобы не нарушать передачу основных элементов.
Чтобы реализовать такое поведение, воспользуемся более продвинутой возможностью Akka Streams — языком Graph DSL — на котором напишем наш собственный шаг графа, на котором поток разветвляется на две части. Первая просто подает значения на веб-сокет, а вторая контролирует, когда истекут очередные 5 секунд, и отправляет уведомление по электронной почте — см. рис. 3.
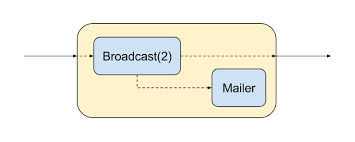
Рис. 3. Наш собственный шаг графа для отправки сообщений по электронной почте
Мы будем использовать встроенный шаг Broadcast, на котором наш ввод высылается на набор объявленных выводов. Также напишем наш собственный уловитель — Mailer:
private final Graph, NotUsed> notifier = GraphDSL.create(builder -> {
Sink mailerSink = Flow.of(Double.class)
.grouped(EMAIL_THRESHOLD)
.to(Sink.foreach(ds ->
logger.info("Sending e-mail")
));
UniformFanOutShape broadcast = builder.add(Broadcast.create(2));
SinkShape mailer = builder.add(mailerSink);
builder.from(broadcast.out(1)).toInlet(mailer.in());
return FlowShape.of(broadcast.in(), broadcast.out(0));
});
Начинаем создавать наш собственный шаг графа с метода GraphDSL.create(), где предоставляется экземпляр построителя графа, Builder — он используется для манипуляций со структурой графа.
Далее определим наш собственный уловитель, где применяется grouped для объединения входящих элементов в группы произвольного размера (по умолчанию 5), после чего эти группы отправляются вниз. Для каждой такой группы сымитируем побочный эффект: уведомление, поступающее по электронной почте.
Определив наш собственный уловитель, можем использовать экземпляр builder, чтобы добавить его к графу. Также добавляем шаг Broadcast с двумя выходами.
Далее нужно указать соединение между элементами графа — один из выходов шага Broadcast мы хотим соединить с уловителем электронной почты, а другой — сделать выходом для написанного нами шага графа. Ввод написанного нами шага будет напрямую соединен с выходом шага Broadcast.
Примечание 1
Компилятор не может определить, правильно ли соединены все части графа. Однако, этот момент проверяется материализатором во время выполнения, поэтому висящих элементов на входе или на выходе не будет.
Примечание 2
В данном случае можно заметить, что все написанные нами шаги имеют вид Graph
На последнем этапе подключаем notifier как дополнительный шаг конвейера liveReadings, который теперь приобретет следующий вид:
private final Source liveReadings =
newFiles
.via(csvPaths)
.via(fileBytes)
.via(csvFields)
.via(readings)
.via(averageReadings)
.via(notifier);
Запустив обновленный код, вы увидите, как в логе появляются записи о почтовых уведомлениях. Уведомление отправляется всякий раз, когда через веб-сокет успевает пройти еще пять значений.
Итог
В этой статье мы изучили общие концепции потоковой обработки данных, узнали, как при помощи Akka Streams построить легковесный конвейер обработки данных. Это альтернатива традиционному подходу, применяемому на Java EE.
Мы рассмотрели, как использовать некоторые шаги обработки, встроенные в Akka Streams, как написать собственный шаг на языке Graph DSL. Также было показано, как использовать Alpakka для потоковой подачи данных из файловой системы и протокол Akka HTTP, позволяющий создать простой веб-сервер с веб-сокетом на конечной точке, бесшовно интегрируемый с Akka Streams.
Полноценный рабочий пример с кодом из этой статьи находится на GitHub. В нем есть несколько дополнительных log-шагов, расставленных в разных точках. Они помогают точнее представить, что происходит внутри конвейера. В статье я специально их опустил, чтобы она получилась покороче.
