[Перевод] Знакомство с Apache Spark
Здравствуйте, уважаемые читатели!
Мы наконец-то приступаем к переводу серьезной книги о фреймворке Spark:

Сегодня мы предлагаем вашему вниманию перевод обзорной статьи о возможностях Spark, которую, полагаем, можно с полным правом назвать слегка потрясающей.
Я впервые услышал о Spark в конце 2013 года, когда заинтересовался Scala — именно на этом языке написан Spark. Несколько позже я принялся ради интереса разрабатывать проект из области Data Science, посвященный прогнозированию выживаемости пассажиров «Титаника». Оказалось, это отличный способ познакомиться с программированием на Spark и его концепциями. Настоятельно рекомендую познакомиться с ним всем начинающим Spark-разработчикам.
Сегодня Spark применяется во многих крупнейших компаниях, таких, как Amazon, eBay и Yahoo! Многие организации эксплуатируют Spark в кластерах, включающих тысячи узлов. Согласно FAQ по Spark, в крупнейшем из таких кластеров насчитывается более 8000 узлов. Действительно, Spark — такая технология, которую стоит взять на заметку и изучить.

В этой статье предлагается знакомство со Spark, приводятся примеры использования и образцы кода.
Что такое Apache Spark? Введение
Spark — это проект Apache, который позиционируется как инструмент для «молниеносных кластерных вычислений». Проект разрабатывается процветающим свободным сообществом, в настоящий момент является наиболее активным из проектов Apache.
Spark предоставляет быструю и универсальную платформу для обработки данных. По сравнению с Hadoop Spark ускоряет работу программ в памяти более чем в 100 раз, а на диске — более чем в 10 раз.
Кроме того, код на Spark пишется быстрее, поскольку здесь в вашем распоряжении будет более 80 высокоуровневых операторов. Чтобы оценить это, давайте рассмотрим аналог «Hello World!» из мира BigData: пример с подсчетом слов (Word Count). Программа, написанная на Java для MapReduce, содержала бы около 50 строк кода, а на Spark (Scala) нам потребуется всего лишь:
sparkContext.textFile("hdfs://...")
.flatMap(line => line.split(" "))
.map(word => (word, 1)).reduceByKey(_ + _)
.saveAsTextFile("hdfs://...")
При изучении Apache Spark стоит отметить еще один немаловажный аспект: здесь предоставляется готовая интерактивная оболочка (REPL). При помощи REPL можно протестировать результат выполнения каждой строки кода без необходимости сначала программировать и выполнять все задание целиком. Поэтому написать готовый код удается гораздо быстрее, кроме того, обеспечивается ситуативный анализ данных.
Кроме того, Spark имеет следующие ключевые черты:
- В настоящее время предоставляет API для Scala, Java и Python, также готовится поддержка других языков (например, R)
- Хорошо интегрируется с экосистемой Hadoop и источниками данных (HDFS, Amazon S3, Hive, HBase, Cassandra, etc.)
- Может работать на кластерах под управлением Hadoop YARN или Apache Mesos, а также работать в автономном режиме
Ядро Spark дополняется набором мощных высокоуровневых библиотек, которые бесшовно стыкуются с ним в рамках того же приложения. В настоящее время к таким библиотекам относятся SparkSQL, Spark Streaming, MLlib (для машинного обучения) и GraphX — все они будут подробно рассмотрены в этой статье. Сейчас также разрабатываются другие библиотеки и расширения Spark.
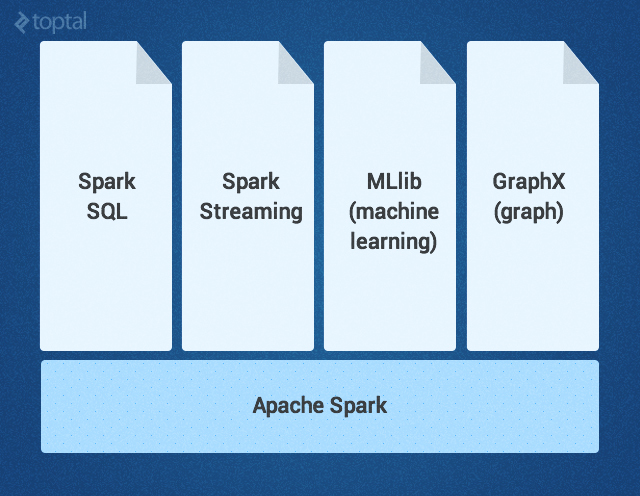
Ядро Spark
Ядро Spark — это базовый движок для крупномасштабной параллельной и распределенной обработки данных. Ядро отвечает за:
- управление памятью и восстановление после отказов
- планирование, распределение и отслеживание заданий кластере
- взаимодействие с системами хранения данных
В Spark вводится концепция RDD (устойчивый распределенный набор данных) — неизменяемая отказоустойчивая распределенная коллекция объектов, которые можно обрабатывать параллельно. В RDD могут содержаться объекты любых типов; RDD создается путем загрузки внешнего набора данных или распределения коллекции из основной программы (driver program). В RDD поддерживаются операции двух типов:
- Трансформации — это операции (например, отображение, фильтрация, объединение и т.д.), совершаемые над RDD; результатом трансформации становится новый RDD, содержащий ее результат.
- Действия — это операции (например, редукция, подсчет и т.д.), возвращающие значение, получаемое в результате некоторых вычислений в RDD.
Трансформации в Spark осуществляются в «ленивом» режиме — то есть, результат не вычисляется сразу после трансформации. Вместо этого они просто «запоминают» операцию, которую следует произвести, и набор данных (напр., файл), над которым нужно совершить операцию. Вычисление трансформаций происходит только тогда, когда вызывается действие, и его результат возвращается основной программе. Благодаря такому дизайну повышается эффективность Spark. Например, если большой файл был преобразован различными способами и передан первому действию, то Spark обработает и вернет результат лишь для первой строки, а не станет прорабатывать таким образом весь файл.
По умолчанию каждый трансформированный RDD может перевычисляться всякий раз, когда вы выполняете над ним новое действие. Однако RDD также можно долговременно хранить в памяти, используя для этого метод хранения или кэширования; в таком случае Spark будет держать нужные элементы на кластере, и вы сможете запрашивать их гораздо быстрее.
SparkSQL
SparkSQL — это компонент Spark, поддерживающий запрашивание данных либо при помощи SQL, либо посредством Hive Query Language. Библиотека возникла как порт Apache Hive для работы поверх Spark (вместо MapReduce), а сейчас уже интегрирована со стеком Spark. Она не только обеспечивает поддержку различных источников данных, но и позволяет переплетать SQL-запросы с трансформациями кода; получается очень мощный инструмент. Ниже приведен пример Hive-совместимого запроса:
// sc – это существующий SparkContext.
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
sqlContext.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")
// Запросы формулируются на HiveQL
sqlContext.sql("FROM src SELECT key, value").collect().foreach(println)
Spark Streaming
Spark Streaming поддерживает обработку потоковых данных в реальном времени; такими данными могут быть файлы логов рабочего веб-сервера (напр. Apache Flume и HDFS/S3), информация из соцсетей, например, Twitter, а также различные очереди сообщений вроде Kafka. «Под капотом» Spark Streaming получает входные потоки данных и разбивает данные на пакеты. Далее они обрабатываются движком Spark, после чего генерируется конечный поток данных (также в пакетной форме) как показано ниже.

API Spark Streaming точно соответствует API Spark Core, поэтому программисты без труда могут одновременно работать и с пакетными, и с потоковыми данными.
MLlib
MLlib — это библиотека для машинного обучения, предоставляющая различные алгоритмы, разработанные для горизонтального масштабирования на кластере в целях классификации, регрессии, кластеризации, совместной фильтрации и т.д. Некоторые из этих алгоритмов работают и с потоковыми данными — например, линейная регрессия с использованием обычного метода наименьших квадратов или кластеризация по методу k-средних (список вскоре расширится). Apache Mahout (библиотека машинного обучения для Hadoop) уже ушла от MapReduce, теперь ее разработка ведется совместно с Spark MLlib.
GraphX
GraphX — это библиотека для манипуляций над графами и выполнения с ними параллельных операций. Библиотека предоставляет универсальный инструмент для ETL, исследовательского анализа и итерационных вычислений на основе графов. Кроме встроенных операций для манипуляций над графами здесь также предоставляется библиотека обычных алгоритмов для работы с графами, например, PageRank.
Как использовать Apache Spark: пример с обнаружением событий
Теперь, когда мы разобрались, что такое Apache Spark, давайте подумаем, какие задачи и проблемы будут решаться с его помощью наиболее эффективно.
Недавно мне попалась статья об эксперименте по регистрации землетрясений путем анализа потока Twitter. Кстати, в статье было продемонстрировано, что этот метод позволяет узнать о землетрясении более оперативно, чем по сводкам Японского Метеорологического Агентства. Хотя технология, описанная в статье, и не похожа на Spark, этот пример кажется мне интересным именно в контексте Spark: он показывает, как можно работать с упрощенными фрагментами кода и без кода-клея.
Во-первых, потребуется отфильтровать те твиты, которые кажутся нам релевантными — например, с упоминанием «землетрясения» или «толчков». Это можно легко сделать при помощи Spark Streaming, вот так:
TwitterUtils.createStream(...)
.filter(_.getText.contains("earthquake") || _.getText.contains("shaking"))
Затем нам потребуется произвести определенный семантический анализ твитов, чтобы определить, актуальны ли те толчки, о которых в них говорится. Вероятно, такие твиты, как «Землетрясение!» или «Сейчас трясет» будут считаться положительными результатами, а «Я на сейсмологической конференции» или «Вчера ужасно трясло» — отрицательными. Авторы статьи использовали для этой цели метод опорных векторов (SVM). Мы поступим также, только реализуем еще и потоковую версию. Полученный в результате образец кода из MLlib выглядел бы примерно так:
// Готовим данные о твитах, касающихся землетрясения, и загружаем их в формате LIBSVM
val data = MLUtils.loadLibSVMFile(sc, "sample_earthquate_tweets.txt")
// Разбиваем данные на тренировочные (60%) и тестовые (40%).
val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L)
val training = splits(0).cache()
val test = splits(1)
// Запускаем тренировочный алгоритм, чтобы построить модель
val numIterations = 100
val model = SVMWithSGD.train(training, numIterations)
// Очищаем пороговое значение, заданное по умолчанию
model.clearThreshold()
// Вычисляем приблизительные показатели по тестовому множеству
val scoreAndLabels = test.map { point =>
val score = model.predict(point.features)
(score, point.label)
}
// Получаем параметры вычислений
val metrics = new BinaryClassificationMetrics(scoreAndLabels)
val auROC = metrics.areaUnderROC()
println("Area under ROC = " + auROC)
Если процент верных прогнозов в данной модели нас устраивает, мы можем переходить к следующему этапу: реагировать на обнаруженное землетрясение. Для этого нам потребуется определенное число (плотность) положительных твитов, полученных в определенный промежуток времени (как показано в статье). Обратите внимание: если твиты сопровождаются геолокационной информацией, то мы сможем определить и координаты землетрясения. Вооружившись этими знаниями, мы можем воспользоваться SparkSQL и запросить имеющуюся таблицу Hive (где хранятся данные о пользователях, желающих получать уведомления о землетрясениях), извлечь их электронные адреса и разослать им персонализированные предупреждения, вот так:
// sc – это имеющийся SparkContext.
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
// sendEmail – это пользовательскаяфункция
sqlContext.sql("FROM earthquake_warning_users SELECT firstName, lastName, city, email")
.collect().foreach(sendEmail)
Другие варианты использования Apache Spark
Потенциально сфера применения Spark, разумеется, далеко не ограничивается сейсмологией.
Вот ориентировочная (то есть, ни в коем случае не исчерпывающая) подборка других практических ситуаций, где требуется скоростная, разноплановая и объемная обработка больших данных, для которой столь хорошо подходит Spark:
В игровой индустрии: обработка и обнаружение закономерностей, описывающих игровые события, поступающие сплошным потоком в реальном времени; в результате мы можем немедленно на них реагировать и делать на этом хорошие деньги, применяя удержание игроков, целевую рекламу, автокоррекцию уровня сложности и т.д.
В электронной коммерции информация о транзакциях, поступающая в реальном времени, может передаваться в потоковый алгоритм кластеризации, например, по k-средним или подвергаться совместной фильтрации, как в случае ALS. Затем результаты даже можно комбинировать с информацией из других неструктутрированных источников данных — например, с отзывами покупателей или рецензиями. Постепенно эту информацию можно применять для совершенствования рекомендаций с учетом новых тенденций.
В финансовой сфере или при обеспечении безопасности стек Spark может применяться для обнаружения мошенничества или вторжений, либо для аутентификации с учетом анализа рисков. Таким образом можно получать первоклассные результаты, собирая огромные объемы архивированных логов, комбинируя их с внешними источниками данных, например, с информацией об утечках данных или о взломанных аккаунтах (см., например, https://haveibeenpwned.com/), а также использовать информацию о соединениях/запросах, ориентируясь, например, на геолокацию по IP или на данные о времени
Заключение
Итак, Spark помогает упростить нетривиальные задачи, связанные с большой вычислительной нагрузкой, обработкой больших объемов данных (как в реальном времени, так и архивированных), как структурированных, так и неструктурированных. Spark обеспечивает бесшовную интеграцию сложных возможностей — например, машинного обучения и алгоритмов для работы с графами. Spark несет обработку Big Data в массы. Попробуйте — не пожалеете!
