[Перевод] Заметки о жизненном цикле ПО
В последнее время я внимательно наблюдал, как нашей команде удаётся совершенствовать надёжность продукта и оперативность реагирования на инциденты. Это заставило меня задуматься, каков жизненный цикл современного софтверного проекта. При этом я воспользовался следующей моделью.
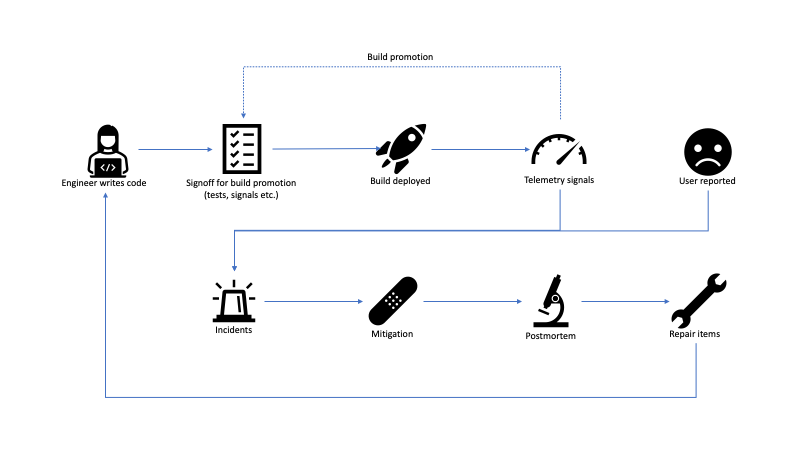
В самом общем виде цикл начинается с a программистов, которые пишут код. Код постепенно мерджится, после чего проходит некоторая каденция, и новая сборка подготавливается к релизу. Как правило, при этом нужно в совокупности рассмотреть данные тестирования и сигналы телеметрии, чтобы инженеры могли завершить цикл, развернув результат сборки. В случае провала тестов или выявления тех или иных аномалий в данных телеметрии сборка бракуется. Если всё выглядит нормально, то сборка развёртывается. После предоставления сборки в широкое пользование поступают новые сигналы телеметрии.
Сегодня в большинстве софтверных проектов в той или иной форме применяется управляемое раскрытие (controlled exposure). Например, сервисы могут развёртываться сначала в окружении для разработки, затем в окружении для препродакшена, после этого перейти в продакшен в одном регионе и, наконец, во всех регионах. Аналогично, клиентский софт развёртывается на разных уровнях. Например, новые сборки Office сначала развёртываются в отделе, разрабатывающем Office, затем во всей компании Microsoft, потом у клиентов, решивших поучаствовать в программе Insider и, наконец во всём мире (здесь я чрезмерно всё упрощаю, поскольку управление релизами Office устроено гораздо сложнее, но впечатление вы составили). Сигналы телеметрии от некоторого уровня подаются обратно в процесс продвижения сборки. Так удаётся с уверенностью рассчитывать, что на следующем уровне сборка может быть представлена более широкой аудитории.
Конечно же, иногда что-то идёт не по плану. В продукте выявляются проблемы, о которых узнают либо по сигналам телеметрии, либо, что хуже, из пользовательских жалоб. Такие случаи переходят в категорию live-инцидентов. Дежурные инженеры реагируют на них и стараются сгладить в кратчайшие сроки. Когда пожар потушен, принято проводить постмортем, чтобы понять, как возникла проблема, и как предотвратить аналогичную проблему в будущем. Информация, добытая в ходе постмортема, обычно перетекает в категорию »требует ремонта», которая пополняет инженерный бэклог.
Этот жизненный цикл можно разделить на две части: проактивную и реактивную, которые примерно соответствуют верхней и нижней половине вышеприведённой схемы.
Проактивный подход
К проактивной части относятся те действия, которые позволяют не пропустить существующие проблемы в продакшен.

Есть несколько уровней, на которых проблема может просочиться через какую-нибудь лазейку.
Код
На этапе написания кода некоторая фича может быть недотестирована, и поэтому какие-то отклонения окажутся не выявлены. Код может быть недостаточно качественно инструментирован, что не позволит получить хороший сигнал, либо может не преодолеть этап включения возможности (feature gate), Речь идёт о флагах, контролируемых службами, и эти флаги можно ставить и снимать, чтобы включать или отключать фичу. Такая функция исключительно ценна для быстрого устранения проблем в продакшене.
Все вышеперечисленные вещи решаются путём обучения и прививания инженерной культуры. Джуниоры, работающие в команде, могут даже не представлять себе всех требований, которые должна удовлетворять фича, до тех пор, пока она не будет готова.
В данном случае рекомендуется вести чеклист фич — список тех вещей, которые инженер должен учесть до того, как отправлять пул-реквест. В частности, такие вещи, как покрытие тестами, телеметрия, включение возможностей, производительность, доступность (пользовательского интерфейса) и т.д.
Каждый, кто пишет код, должен знать, где лежит этот чеклист, а те, кто занимается ревью кода, должны держать в уме этот список при оценке изменений.
Отмашка на продвижение сборки
Есть две основные проблемы, по которым регрессия кода может проскользнуть через процесс валидации сборки: либо есть пробел в процессе валидации, либо не хватает каких-то сигналов. Естественно, при этом предполагается, что код был снабжён тестами и должным образом инструментирован на этапе написания кода. Проблема возникает, если те, кто валидировал сборку, не провели каких-то валидационных тестов (ручных или автоматических), либо не заметили сигнала телеметрии, который мог бы подсказать, что что-то пошло не так.
Обе эти проблемы решаемы при помощи автоматизации.
Нужно иметь дашборд пойдёт/не пойдёт, в котором агрегируются все релевантные сигналы (в частности, результаты прогонов тестов и метрики телеметрии).
Разумеется, не так просто составить такой дашборд и гарантировать, что весь код будет правильно инструментирован и снабжён нужными тестами.
Сигналы телеметрии
В телеметрии могут быть пробелы: проблема проявляется, а сигнала об этом мы не получаем. Если такое происходит, то на подобных инцидентах нужно учиться, понимать, где возникают пробелы, а затем устранять эти пробелы. Подробнее об этом — в разделе о реактивном подходе.
Реактивный подход
В этой части рассказано, как максимально быстро сглаживать проблемы, если они, всё-таки, проскользнули в продакшен.
Инциденты
Входной точкой реактивного цикла является инцидент. Инцидент — это сообщение для дежурного инженера, по такому сообщению запускается цикл исправления проблемы. Чем быстрее создан инцидент, тем скорее можно приступить к его исправлению.
В данном случае о проблемах идут оповещения. Система оповещений прогоняет автоматизированные запросы по входящим сигналам телеметрии и анализирует аномалии или пороговые сообщения. Здесь многое может пойти не так:
- Можно собрать много телеметрии, но не сформулировать правильных запросов, которые позволили бы заметить внезапные всплески или спады, либо другие аномалии в потоке телеметрии.
- Можно постоянно перестраховываться и генерировать слишком много предупреждений. Большинство таких предупреждений окажутся ложноположительными, и поэтому дежурному инженеру сложно будет определить, когда угроза реальная.
- Предупреждения могут быть сформулированы очень общо, в них может не хватать информации, опираясь на которую дежурный мог бы легко устранить проблему.
Нужно постоянно заниматься тонкой настройкой оповещений, чтобы они были точными, и по ним сразу было понятно, что делать, а ложноположительных результатов было как можно меньше.
Даже при условии, что сигналы телеметрии корректны, на них может влиять множество факторов, которых мы не контролируем. Например, в выходные или праздники пользовательская активность может резко возрастать или падать (в зависимости от того, говорим ли мы об игровом приложении или о рабочем инструменте). Поэтому разрабатывать точные оповещения становится ещё сложнее.
Хуже всего, когда о проблемах мы узнаем от пользователей, не получив никаких оповещений. Это свидетельствует о крупном пробеле, и последующий постмортем должен показать, что делать дальше (см. ниже раздел о постмортемах).
Устранение проблем
При устранении проблем есть несколько осложняющих факторов. Дежурный инженер может не уметь справляться с теми или иными типами инцидентов.
Хорошая идея — предусмотреть гайд по устранению неисправностей (TSG) на оповещение каждого типа. Такой гайд пишет эксперт-предметник, подробно объясняющий, как устранять данную проблему.
Часто бывает и так, что лёгкого способа устранить проблему просто нет. Тогда приходится возвращаться на этап работы с кодом: весь код должен быть работоспособен до перехода к реализации конкретных возможностей, и тогда устранение неполадок должно сводиться к простому переключению веток.
Ещё одна распространённая проблема, которую мы затронули в предыдущем разделе об оповещениях: бывает, что для быстрой идентификации сути проблемы не хватает информации. Дежурный инженер видит инциденты, понимает, что что-то не так, но не обладает достаточной информации для быстрого устранения проблемы. В оповещениях должно содержаться такое количество информации, которое позволит извлекать из них пользу.
Постмортемы
Постмортемы бесценны как инструмент, позволяющий учиться на инцидентах. В ходе постмортема устранённый инцидент анализируется, выявляется и осмысливается его коренная причина, команда собирается и совместно обсуждает произошедшее, а также принимает меры для предотвращения таких же инцидентов в будущем. Постмортем — это не порицание, а попытка ответить на следующий вопрос:
Что можно сделать, чтобы в будущем ничего подобного не происходило?
Если постмортем не даёт ответа на этот вопрос, то в нём не так много пользы. Хороший постмортем позволяет выявить одну или несколько областей задач, которые могут быть переданы инженерам для реализации дополнительных «буйков», чтобы гарантировать, что аналогичные проблемы не повторятся.
Требует ремонта
Наконец, мало идентифицировать дефектные элементы, требующие ремонта. Если накопится длинный бэклог таких элементов, внедрением которых никто не занимается, то ситуацию этот список нисколько не упростит.
Инженеры должны задавать приоритет для обработки каждого из этих элементов.
Элементы, требующие ремонта — один из самых критичных участков работы: мы видели инциденты в продакшене, мы знаем радиус поражения от этих инцидентов и знаем, какую работу нужно провести, чтобы предотвратить такие инциденты в будущем.
Заключение
В этой статье была рассмотрена модель жизненного цикла ПО. Первая часть этой модели — проактивная: инженеры пишут код, далее делается отмашка на сборку, а после этого постепенно увеличивается пользовательская аудитория продукта. Вторая часть — реактивная: инцидент устраняется там, где произошёл, решением этой проблемы занимается дежурный инженер, далее команда проводит постмортем и составляет список элементов, которые следует отремонтировать.
Также были рассмотрены некоторые распространённые проблемы, возникающие на разных этапах жизненного цикла и рекомендуется, как лучше всего с ними справляться.
Этот обзор сделан в самом общем виде. Каждый пункт можно рассмотреть гораздо глубже: от написания безопасного кода до управления релизами, изучения моделей телеметрии, обеспечения эксплуатационной надёжности (SRE) и т.д. Всё это очень важно для производства качественного ПО.
