[Перевод] Введение в обучение с подкреплением
Всем привет!
Мы открыли новый поток на курс «Machine learning», так что ждите в ближайшее время статей связанных с данной, так сказать, дисциплиной. Ну и разумеется открытых семинаров. А сейчас давайте рассмотрим, что такое обучение с подкреплением.
Обучение с подкреплением является важным видом машинного обучения, где агент учится вести себя в окружающей среде, выполняя действия и видя результаты.
В последние годы мы наблюдаем много успехов в этой увлекательной области исследований. Например, DeepMind и Deep Q Learning Architecture в 2014 году, победа над чемпионом по игре в го с AlphaGo в 2016, OpenAI и PPO в 2017 году, среди прочих.

DeepMind DQN
В этой серии статей мы сосредоточимся на изучении различных архитектур, используемых сегодня для решения задачи обучения с подкреплением. К ним относятся Q-learning, Deep Q-learning, Policy Gradients, Actor Critic и PPO.
В этой статье вы узнаете:
- Что такое обучение с подкреплением, и почему вознаграждения являются центральной идеей
- Три подхода к обучению с подкреплением
- Что означает «глубокое» в глубоком обучении с подкреплением
Очень важно овладеть этими аспектами, прежде чем погрузиться в реализацию агентов обучения с подкреплением.
Идея обучения с подкреплением заключается в том, что агент будет учиться у окружающей среды, взаимодействуя с ней и получая вознаграждения за выполнение действий.

Обучение через взаимодействие с окружающей средой происходит из нашего естественного опыта. Представьте, что вы ребенок в гостиной. Вы видите камин и подходите к нему.
Рядом тепло, вы чувствуете себя хорошо (положительное вознаграждение +1). Вы понимаете, что огонь — это положительная вещь.
Но потом вы пытаетесь дотронуться до огня. Ой! Он обжог руку (отрицательное вознаграждение -1). Вы только что поняли, что огонь положителен, когда вы на достаточном расстоянии, потому что он производит тепло. Но если приблизитесь к нему — обожжетесь.
Именно так люди учатся через взаимодействие. Обучение с подкреплением — это просто вычислительный подход к обучению через действия.
Процесс обучения с подкреплением
В качестве примера представим, что агент учится играть в Super Mario Bros. Процесс обучения с подкреплением (Reinforcement Learning — RL) можно смоделировать как цикл, который работает следующим образом:
- Агент получает состояние S0 от окружающей среды (в нашем случае мы получаем первый кадр игры (состояние) от Super Mario Bros (окружающая среда))
- Исходя из этого состояния S0, агент предпринимает действие A0 (агент будет двигаться вправо)
- Окружающая среда перемещается в новое состояние S1 (новый кадр)
- Окружающая среда дает некоторое вознаграждение R1 агенту (не мертв: +1)
Этот RL-цикл выдаёт последовательность состояний, действий и вознаграждений.
Цель агента — максимизировать ожидаемое накопленное вознаграждение.
Центральная идея Гипотезы вознаграждения
Почему цель агента заключается в максимизации ожидаемого накопленного вознаграждения? Ну, обучение с подкреплением основано на идее гипотезы вознаграждения. Все цели можно описать максимизацией ожидаемого накопленного вознаграждения.
Поэтому в обучении с подкреплением, чтобы добиться наилучшего поведения, нам нужно максимизировать ожидаемое накопленное вознаграждение.
Накопленное вознаграждение на каждом временном шаге t может быть записано как:

Это эквивалентно:
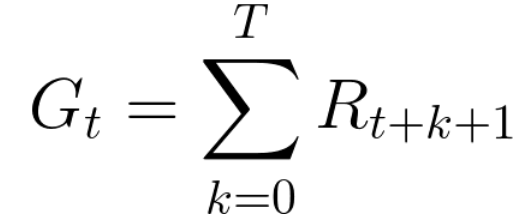
Однако на самом деле мы не можем просто прибавлять такие вознаграждения. Вознаграждения, которые поступают раньше (в начале игры), более вероятны, поскольку они более предсказуемы, чем вознаграждения в дальнейшей перспективе.

Допустим, что ваш агент — это маленькая мышь, а оппонент — кошка. Ваша цель — съесть максимальное количество сыра, прежде чем кошка вас съест. Как мы видим на диаграмме, мышь вероятнее съест сыр рядом с собой, чем сыр около кошки (чем ближе мы находимся к ней, тем это опаснее).
Как следствие, вознаграждение у кошки, даже если оно больше (больше сыра), будет снижено. Мы не уверены, что сможем его съесть. Чтобы снизить вознаграждение, мы делаем следующее:
- Определяем дисконтную ставку, называемую гамма. Она должна быть между 0 и 1.
- Чем больше гамма, тем меньше скидка. Это означает, что обучающегося агента больше заботят долгосрочные вознаграждения.
- С другой стороны, чем меньше гамма, тем больше скидка. Это означает, что в приоритете краткосрочные вознаграждения (ближайший сыр).
Накопленное ожидаемое вознаграждение с учетом дисконтирования выглядит следующим образом:
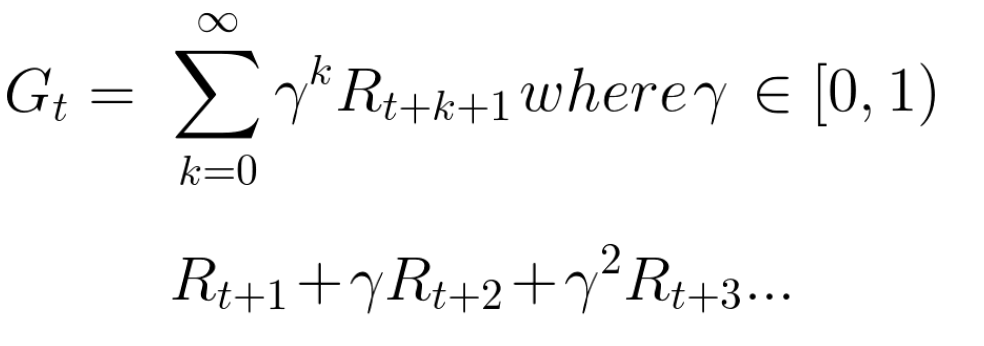
Грубо говоря, каждое вознаграждение будет снижено с помощью гаммы к показателю времени. По мере увеличения временного шага кошка становится ближе к нам, поэтому будущая награда становится все менее вероятной.
Эпизодические или непрерывные задачи
Задача — это экземпляр проблемы обучения с подкреплением. У нас могут быть два типа задач: эпизодическая и непрерывная.
Эпизодическая задача
В этом случае мы имеем начальную точку и конечную точку (терминальное состояние). Это создает эпизод: список состояний, действий, вознаграждений и новых состояний.
Возьмем к примеру Super Mario Bros: эпизод начинается с запуска нового Марио и заканчивается, когда вы убиты или достигнете конца уровня.

Начало нового эпизода
Непрерывные задачи
Это задачи, которые продолжаются вечно (без терминального состояния). В этом случае агент должен научиться выбирать лучшие действия и одновременно взаимодействовать с окружающей средой.
Например, агент, который выполняет автоматическую торговлю акциями. Для этой задачи нет начальной точки и терминального состояния. Агент продолжает работать, пока мы не решим его остановить.

Метод Монте-Карло против метода временных различий
Есть два способа обучения:
- Сбор вознаграждений в конце эпизода, а затем расчет максимального ожидаемого будущего вознаграждения — подход Монте-Карло
- Оценка вознаграждения на каждом шагу — временное различие
Монте-Карло
Когда эпизод заканчивается (агент достигает «терминального состояния»), агент просматривает общее накопленное вознаграждение, чтобы увидеть, насколько хорошо он справился. В подходе Монте-Карло вознаграждение получается только в конце игры.
Затем мы начинаем новую игру с дополненными знаниями. Агент принимает лучшие решения с каждой итерацией.
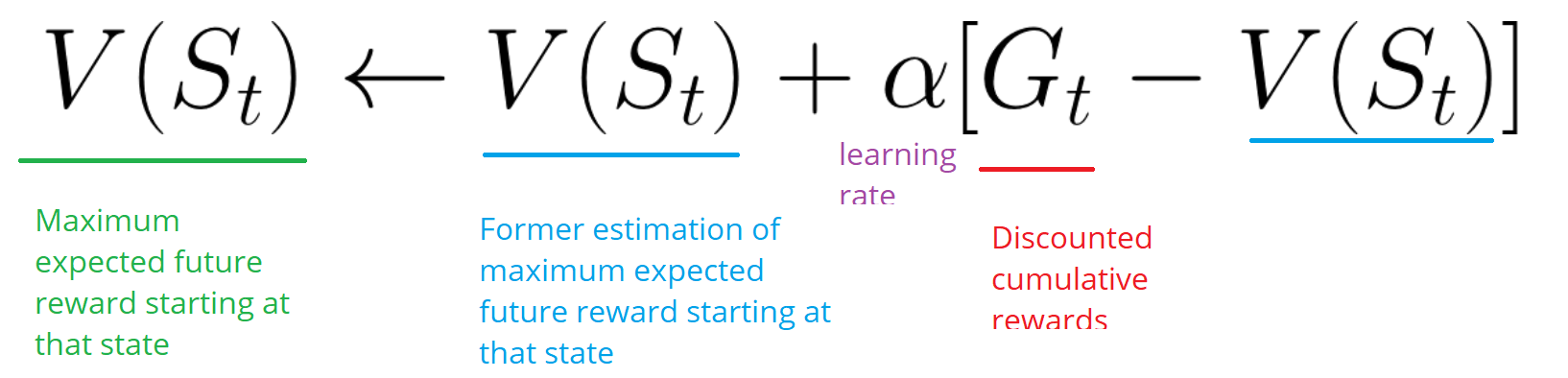
Приведем пример:
Если мы возьмем лабиринт в качестве окружающей среды:
- Мы всегда начинаем с одной и той же начальной точки.
- Мы прекращаем эпизод, если кошка ест нас или мы двигаемся > 20 шагов.
- В конце эпизода у нас есть список состояний, действий, вознаграждений и новых состояний.
- Агент суммирует общее вознаграждение Gt (чтобы увидеть, насколько хорошо он справлялся).
- Затем он обновляет V (st) в соответствии с приведенной выше формулой.
- Затем запускается новая игра уже с новыми знаниями.
Запуская все большее количества эпизодов, агент будет учиться играть все лучше и лучше.
Временные различия: обучение на каждом временном шаге
Метод временных различий (TD — Temporal Difference Learning) не будет ждать конца эпизода, чтобы обновить максимально возможное вознаграждение. Он будет обновлять V в зависимости от полученного опыта.
Этот метод называется TD (0) или пошаговый TD (обновляет функцию полезности после любого отдельного шага).

TD-методы ожидают только следующего временного шага для обновления значений. В момент времени t + 1 формируется TD цель с использованием вознаграждения Rt+1 и текущей оценки V (St+1).
TD цель — это оценка ожидаемого: фактически вы обновляете предыдущую оценку V (St) к цели в пределах одного шага.
Компромисс Разведка/Эксплуатация
Прежде чем рассматривать различные стратегии решения задач обучения с подкреплением, мы должны рассмотреть еще одну очень важную тему: компромисс между разведкой и эксплуатацией.
- Разведка находит больше информации об окружающей среде.
- Эксплуатация использует известную информацию для максимизации вознаграждения.
Помните, что цель нашего RL-агента — максимизировать ожидаемое накопленное вознаграждение. Однако мы можем попасть в распространенную ловушку.
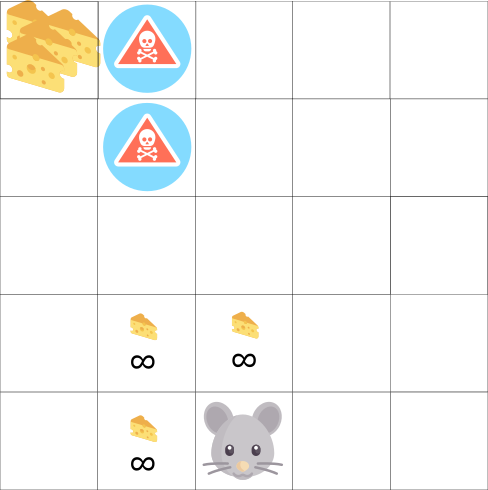
В этой игре у нашей мыши может быть бесконечное количество маленьких кусочков сыра (+1 каждый). Но на вершине лабиринта есть гигантский кусок сыра (+1000). Однако, если мы сосредоточимся только на вознаграждении, наш агент никогда не достигнет гигантского куска. Вместо этого он будет использовать только ближайший источник вознаграждений, даже если этот источник небольшой (эксплуатация). Но если наш агент немного разведает обстановку, он сможет найти большое вознаграждение.
Это то, что мы называем компромиссом между разведкой и эксплуатацией. Мы должны определить правило, которое поможет справиться с этим компромиссом. В будущих статьях вы узнаете разные способы это сделать.
Три подхода к обучению с подкреплением
Теперь, когда мы определили основные элементы обучения с подкреплением, давайте перейдем к трем подходам решения задач обучения с подкреплением: на основе стоимости, на основе политике и на основе модели.
На основе стоимости
В RL на основе стоимости, целью является оптимизация функции полезности V (s).
Функция полезности — это функция, которая сообщает нам о максимальном ожидаемом вознаграждении, которое агент получит в каждом состоянии.
Значение каждого состояния — это общая сумма вознаграждения, которое агент может рассчитывать накопить в будущем, начиная с этого состояния.
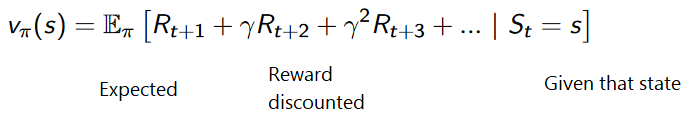
Агент будет использовать эту функцию полезности, чтобы решить, какое состояние выбрать на каждом шаге. Агент выбирает состояние с наибольшим значением.
В примере лабиринта на каждом шаге мы возьмем наибольшее значение: -7, затем -6, затем -5 (и т. д.), чтобы достичь цели.
На основе политики
В RL на основе политики мы хотим напрямую оптимизировать функцию политики π (s) без использования функции полезности. Политикой является то, что определяет поведение агента в данный момент времени.
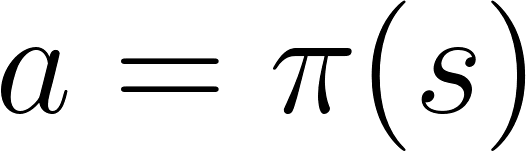
действие = политика (состояние)
Мы изучаем функцию политики. Это позволяет нам сопоставить каждое состояние с наилучшим соответствующим действием.
Есть два типа политики:
- Детерминистская: политика в заданном состоянии всегда будет возвращать одно и то же действие.
- Стохастическая: выводит вероятность распределения по действиям.

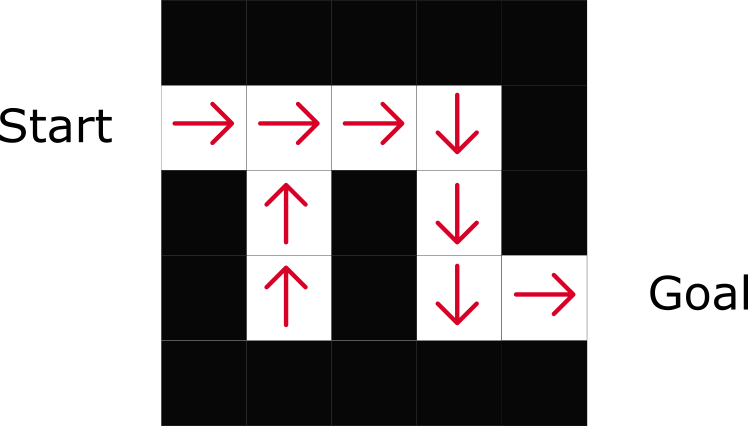
Как можно заметить, политика прямо указывает на лучшее действие для каждого шага.
На основе модели
В RL на основе модели мы моделируем среду. Это означает, что мы создаем модель поведения окружающей среды. Проблема заключается в том, что каждой среде потребуется другое представление модели. Вот почему мы не будем сильно заострять внимание на этом типе обучения в следующих статьях.
Знакомство с глубоким обучением с подкреплением
Глубокое обучение с подкреплением (Deep Reinforcement Learning) вводит глубокие нейронные сети для решения задач обучения с подкреплением — отсюда и название «глубокое».
Например, в следующей статье мы будем работать над Q-Learning (классическое обучение с подкреплением) и Deep Q-Learning.
Вы увидите разницу в том, что в первом подходе мы используем традиционный алгоритм для создания таблицы Q, которая помогает нам найти, какое действие нужно предпринять для каждого состояния.
Во втором подходе мы будем использовать нейронную сеть (для аппроксимации вознаграждения на основе состояния: значение q).
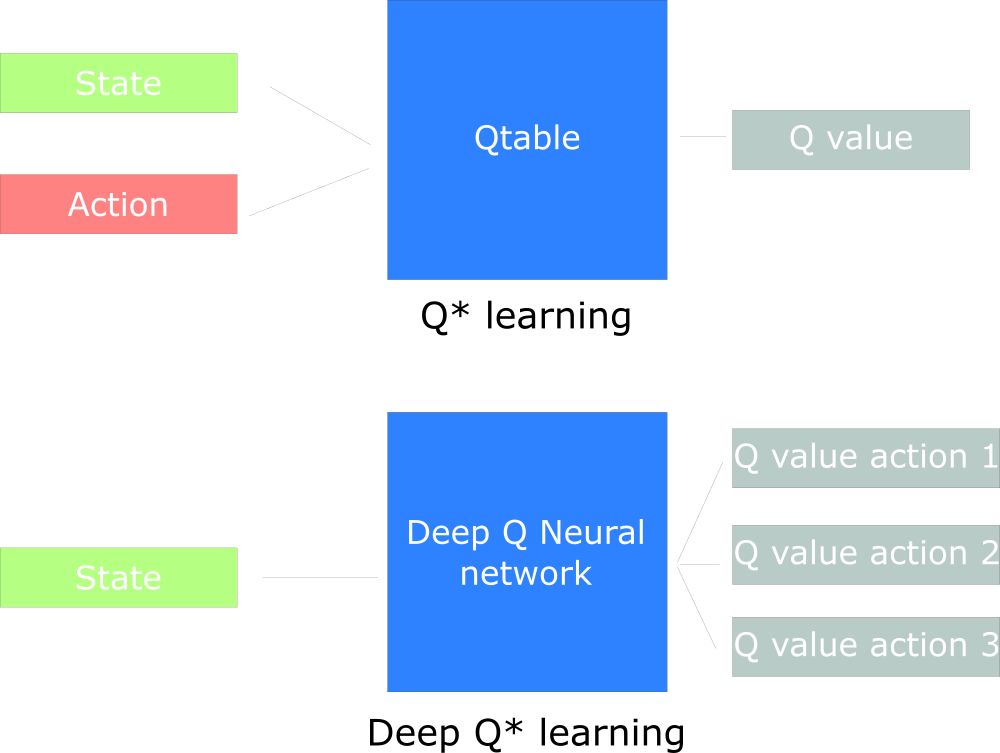
Схема, вдохновленная учебным пособием Q от Udacity
Вот и всё. Как всегда мы ждём ваши комментарии или вопросы тут или их можно задать преподавателю курса Артуру Кадурину на его открытом уроке, посвящённому обучению сетей.
