[Перевод] Введение в lock-free программирование

В этом посте мы хотели бы еще раз поднять тему программирования без блокировок, сперва дав ему определение, а затем выделить из всего многообразия информации несколько ключевых положений. Мы покажем, как эти положения соотносятся между собой, с помощью блок-схем, а потом мы немного коснемся деталей. Минимальное требование к разработчику, постигающему lock-free, — умение писать правильный многопоточный код, используя мьютексы или другие высокоуровневые объекты синхронизации, например, семафоры или события.
Программирование без блокировок (Lock-free) — это своего рода испытание, причем не столько из-за сложности самой задачи, сколько из-за трудности постижения сути предмета.
Мне повезло получить первое представление о lock-free из превосходной подробной статьи Брюса Доусона «Lockless Programming Considerations». И как многим другим, мне довелось применить советы Брюса на практике, занимаясь разработкой и отладкой безблокировочного кода на таких платформах как Xbox 360.
С тех пор в свет вышло множество хороших работ, начиная с абстрактной теории и доказательств корректности и заканчивая практическими примерами и подробностями аппаратного уровня. Я приведу список ссылок в примечаниях. Порой информация в одном источнике противоречит другим, например, некоторые работы предполагают последовательную консистентность (sequential consistency), что позволяет обойти проблемы упорядочения памяти (memory ordering) — настоящее бедствие для C/C++ кода. В то же время новая библиотека атомарных операций стандарта C++11 заставляет взглянуть на проблему в новом свете и отказаться от привычного многим способа представления lock-free алгоритмов.
Что это?
Обычно безблокировочное программирование описывают как программирование без мьютексов, которые также называют блокировками (locks). Это верно, но это лишь часть общей картины. Общепринятое определение, основанное на академической литературе, немного шире. «Без блокировок» — это в сущности некое свойство, которое позволяет описать код, не вдаваясь в подробности о том, как он написан.
Как правило, если какая-то часть вашей программы удовлетворяет нижеперечисленым условиям, то эта часть может полноправно считаться lock-free. И наоборот, если данная часть этим условиям не удовлетворяет, lock-free она не будет.
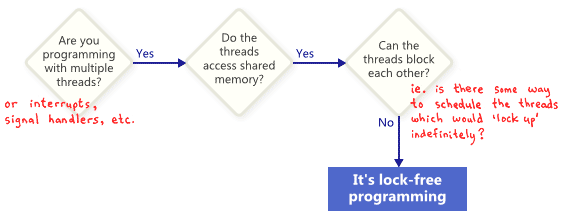
Перевод: Вы работаете с несколькими потоками (прерываниями, обработчиками сигналов и т.д.)? — Да. — Потоки имеют доступ к разделяемой памяти? — Да. — Могут ли потоки блокировать друг друга (другими словами, можно ли выполнить планирование потоков так, чтобы они заблокировались на неопределенное время)? — Нет. — Это программирование без блокировок.
В этом смысле, термин lock (блокировка) в lock-free относится не непосредственно к мьютексам, с скорее к возможности того, что само приложение каким-то образом окажется заблокированным, будь то взаимоблокировка (deadlock), динамическая взаимоблокировка (livelock) или гипотетического планирования потоков, выполненного вашим злейшим врагом. Последний пункт может показаться забавным, но он-то и является ключевым. Разделяемые мьютексы легко вывести из строя: как только один поток получает мьютекс, ваш недоброжелатель может просто больше никогда не выполнять планирование этого потока. Конечно, реальные операционные системы таким образом не работают, пока мы просто определяем термины.
Вот простой пример операции, которая не содержит мьютексов, но все равно не является lock-free. Вначале X = 0. В качестве упражнения подумайте, как выполнить планирование двух потоков таким образом, чтобы ни один не смог выйти из цикла.
while (X == 0)
{
X = 1 - X;
}Никто не ожидает, что большое приложение будет полностью lock-free. Обычно из всего кода мы выделяем подмножество lock-free операций. Например, в безблокировочной очереди может быть некоторое количество безблокровочных операций:
push, pop, возможно, isEmpty и т.д. Херлихи и Шавит, авторы книги The Art of Multiprocessor Programming, склонятся к тому, чтобы представлять такие операции в виде методов класса, и предлагают следующее краткое определение lock-free: «при бесконечном выполнении бесконечно часто вызываемый метод всегда завершается». Иными словами, пока программа может вызывать такие lock-free операции, количество завершенных вызовов будет увеличиваться. Во время таких операций блокировка системы алгоритмически невозможна.
Херлихи и Шавит, авторы книги The Art of Multiprocessor Programming, склонятся к тому, чтобы представлять такие операции в виде методов класса, и предлагают следующее краткое определение lock-free: «при бесконечном выполнении бесконечно часто вызываемый метод всегда завершается». Иными словами, пока программа может вызывать такие lock-free операции, количество завершенных вызовов будет увеличиваться. Во время таких операций блокировка системы алгоритмически невозможна.
Одно из важных последствий программирования без блокировок: даже если один поток будет находиться в состоянии ожидания, он не помешает прогрессу остальных потоков в их собственных lock-free операциях. Это определяет ценность программирования без блокировок при написании обработчиков прерываний и систем реального времени, когда определенная задача должна быть завершена за ограниченный отрезок времени, независимо от состояния остальной программы.
Последнее уточнение: операции, специально предназначенные для блокировки, не лишают алгоритм статуса lock-free. Например, операция pop очереди может блокироваться намеренно, если очередь пуста. Остальные пути все равно будут считаться безблокировочными.
Механизмы программирования без блокировок
Оказывается, для того, чтобы удовлетворить условию отсутствия блокировок, существует целое семейство механизмов: атомарные операции (atomic operations), барьеры памяти (memory barriers), избегание проблем ABA — лишь некоторые из них. И в этот момент все становится адски сложно.
Как же соотносятся все эти механизмы? Для иллюстрации я нарисовал следующую блок-схему. Расшифрую каждый блок ниже.
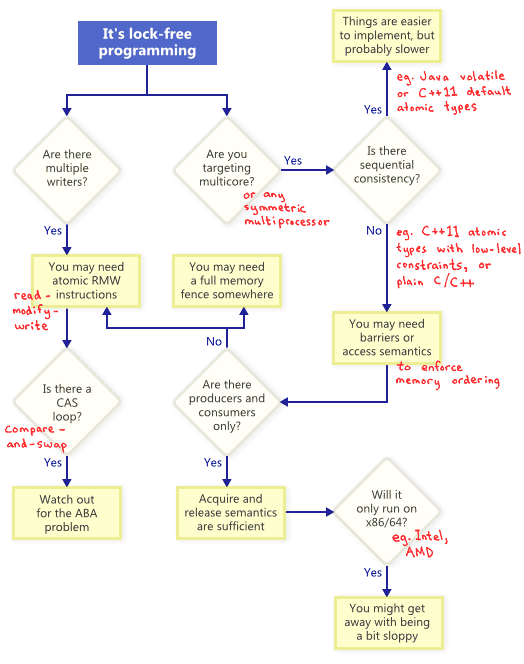
Операции атомарного изменения (RMW, read-modify-write)
Атомарные операции — это такие операции, которые производят неделимые манипуляции памятью: ни один поток не может наблюдать такую операцию на промежуточной стадии выполнения. В современных процессорах многие операции уже атомарны. Например, обычно являются атомарными выровненные операции чтения/записи простых типов.
 RMW-операции идут еще дальше, позволяя атомарно выполнять более сложные транзакции. Они особенно полезны, когда алгоритм без блокировок должен поддерживать несколько потоков на запись, потому что при попытке нескольких потоков выполнить RMW на один адрес, они оперативно выстроятся в ряд и выполнят эти операции по одному. Я уже касался RMW в этом блоге, когда рассказывал о реализации легковесного мьютекса, рекурсивного мьютекса и легковесной системы логирования.
RMW-операции идут еще дальше, позволяя атомарно выполнять более сложные транзакции. Они особенно полезны, когда алгоритм без блокировок должен поддерживать несколько потоков на запись, потому что при попытке нескольких потоков выполнить RMW на один адрес, они оперативно выстроятся в ряд и выполнят эти операции по одному. Я уже касался RMW в этом блоге, когда рассказывал о реализации легковесного мьютекса, рекурсивного мьютекса и легковесной системы логирования.
Примеры RMW-операций: _InterlockedIncrement в Win32, OSAtomicAdd32 в iOS и std::atomic в C++11. Примите к сведению, что стандарт атомарных операций C++11 не гарантирует, что реализация будет lock-free на любой платформе, поэтому лучше всего изучить возможности вашей платформы и инструментария. Для уверенности можно вызвать std::atomic<>::is_lock_free.
Различные семейства процессоров поддерживают RMW по-разному. Такие процессоры, как PowerPC и ARM, предоставляют LL/SC-инструкции (load-link/store-conditional, загрузка с пометкой/попытка записи), что позволяет реализовать вашу собственную RMW-транзакцию на низком уровне, хотя так делают нечасто. Обыкновенных RMW обычно бывает достаточно.
Как показано на блок-схеме, атомарные RMW — необходимая часть программирования без блокировок даже на однопроцессорных системах. Без атомарности поток может быть прерван на середине транзакции, что может привести к рассогласованному состоянию (inconsistent state).
Циклы Compare-And-Swap
Возможно, наиболее обсуждаемая RMW-операция — compare-and-swap (CAS). В Win32 CAS доступна с помощью семейства встроенных функций, таких как
_InterlockedCompareExchange. Разработчики часто выполняют compare-and-swap в цикле, чтобы повторять попытки выполнить странцанцию. Этот сценарий обычно включает в себя копирование разделяемой переменной в локальную, совершение над ней какой-то работы и попытку опубликовать изменения, используя CAS.void LockFreeQueue::push(Node* newHead)
{
for (;;)
{
// Copy a shared variable (m_Head) to a local.
Node* oldHead = m_Head;
// Do some speculative work, not yet visible to other threads.
newHead->next = oldHead;
// Next, attempt to publish our changes to the shared variable.
// If the shared variable hasn't changed, the CAS succeeds and we return.
// Otherwise, repeat.
if (_InterlockedCompareExchange(&m_Head, newHead, oldHead) == oldHead)
return;
}
}Такие циклы тоже считают lock-free, так как если тест не прошел в одном потоке, значит, он должен был пройти в другом, хотя некоторые архитектуры предлагают более слабый вариант CAS, где это не всегда так. Во время реализации CAS-цикла необходимо стараться избегать ABA проблемы.
Последовательная согласованность (sequential consistency)
Последовательная согласованность означает, что все потоки согласны с порядком, в котором выполнялись операции с памятью, и что этот порядок соответствует порядку операций в исходном коде программы. При последовательной согласованности мы не пострадаем от проделок переупорядочивания памяти, подобных той, что я описал в предыдущем посте.
Простой (но очевидно непрактичный) способ достичь последовательной согласованности — выключить оптимизации компилятора и запускать все потоки на одном процессоре. Память одного процессора никогда не окажется в беспорядке, даже если потоки запланированы на случайное время.
Некоторые языки программирования предоставляют последовательную согласованность даже для оптимизированного кода, выполняемого на нескольких процессорах. В C++11 можно объявить разделяемые переменные как атомарные (atomic) типы C++11, обеспечивающие упорядочение. В Java можно пометить все разделяемые переменные как volatile. Вот пример из моего предыдущего поста, переписанный в стиле C++11:
std::atomic X(0), Y(0);
int r1, r2;
void thread1()
{
X.store(1);
r1 = Y.load();
}
void thread2()
{
Y.store(1);
r2 = X.load();
} Так как атомарные типы C++11 гарантируют последовательную согласованность, получить на выходе r1 = r2 = 0 невозможно. Чтобы получить желаемый результат, компилятор добавляет дополнительные инструкции — обычно это барьеры памяти или RMW-операции. Из-за этих дополнительных инструкций реализация может оказаться менее эффективной, чем та, где разработчик работает с упорядочением памяти напрямую.
Упорядочение памяти (memory reordering)
Как предлагается в блок-схеме, каждый раз при lock-free разработке под мультиядерную (или любую другую SMP-) систему, когда ваше окружение не гарантирует последовательной согласованности, нужно подумать, как бороться с проблемой переупорядочения памяти.
В современных архитектурах существует три группы инструментов, обеспечивающих корректное упорядочение памяти как на уровне компилятора, так и на уровне процессора:
- Легковесные инструкции синхронизации и барьеров памяти, о которых я расскажу в будущих постах;
- Полные инструкции барьеров памяти, которые я демонстрировал раньше;
- Операции с памятью, основанные на acquire/release семантике (семантике захвата/освобождения ресурсов).
Acquire-семантика обеспечивает упорядочение памяти для последующих операций, release-семантика — для предыдущих. Эти семантики частично подходят для случая отношений производителя/потребителя, когда один поток публикует информацию, а другой ее читает. Обсудим это более подробно в будущем посте.
У разных процессоров разные модели памяти
Когда дело касается переупорядочения памяти, у всех семейств CPU свои привычки. Правила зафиксированы в документации каждого производителя и строго соблюдаются при производстве железа. Например, процессоры PowerPC или ARM могут сами менять порядок инструкций, а семейство x86/64 от Intel и AMD обычно этого не делают. Говорят, что первые имеют более слабую модель памяти.
Есть большой соблазн абстрагироваться от этих низкоуровневых деталей, особенно когда C++11 предоставляет нам стандартный способ писать портируемый код без блокировок. Но думаю, в настоящее время большинство lock-free разработчиков имеют хоть какое-то представление о различии аппаратных платформ. Ключевое отличие, которое точно стоит запомнить, — это то, что на уровне инструкций в x86/64 каждая загрузка из памяти происходит с acquire-семантикой, а каждая запись в память — c release-семантикой — по крайней мере для не-SSE инструкций и не для памяти с комбинируемой записью (write-combining memory). В результате, раньше довольно часто писали lock-free код, который работал на x86/64, но падал на других процессорах.
Если вам интересны технические подробности того, как и почему процессоры переупорядочивают память, рекомендую прочесть Appendix C в Is Parallel Programming Hard. В любом случае, не забывайте, что переупорядочение памяти может также произойти из-за того, что компилятор переупорядочил инструкции.
В этом посте я почти не затронул практическую сторону программирования без блокировок, например, когда стоит им заниматься? Настолько ли сильно оно нам нужно? Я также не упомянул важность проверки ваших lock-free алгоритмов. Тем не менее, надеюсь, что это введение позволило некоторым читателям познакомится с основными принципами lock-free, так что они смогут дальше углубляться в тему, не чувствуя себя в полной растерянности.
Дополнительные ссылки

- Блог Anthony Williams и его книга C++ Concurrency in Action
- Сайт Dmitriy V«jukov и различные обсуждения на форуме
- Блог Bartosz Milewski
- Low-Level Threading series в блоге Charles Bloom
- Doug Lea, JSR-133 Cookbook
- Howells and McKenney, документ memory-barriers.txt
- Hans Boehm, коллекция ссылок о модели памяти C++11
- Herb Sutter, серия статей Effective Concurrency
Комментарии (5)
20 февраля 2017 в 19:18
+2↑
↓
«В этом посте я почти не затронул практическую сторону программирования без блокировок, например, когда стоит им заниматься? Настолько ли сильно оно нам нужно?»
Вот действительно, напишите хоть в комментарии, зачем и когда оно нужно. Понятно, что вроде бы для оптимизации быстродействия, но на сколько и по сравнению с чем? marshinov
marshinov
20 февраля 2017 в 19:22
0↑
↓
Задач, требующих прям lock-free вроде-бы нет, но для себя интересно. Буду рад, если продолжите писать.20 февраля 2017 в 19:57
0↑
↓
Предположу, что lock-free даёт выигрыш при параллельном программировании с сильной гранулярностью задач, когда расходы на традиционную синхронизацию велики.
Впрочем, я на практике с таким не встречался — обычно удавалось снизить гранулярность, либо подобный код вообще преобразовывался в асинхронный.
Также стоит отметить, что одновременный доступ к атомарному значению существенно снижает производительность. Может так оказаться, что однопоточная реализация алгоритма окажется быстрее многопоточного из-за отсутствия накладных расходов. Поэтому таких ситуаций лучше избегать совсем.
20 февраля 2017 в 22:39
+1↑
↓
Насколько я знаю, есть две основные ситуации, где это нужно:
- Нужно гарантировать минимальную задержку выполнения для худшего случая. Пусть даже ценой ухудшения среднего быстродействия.
- Высокая загрузка системы (ну, просто при высокой загрузке мы стабильно попадаем в тот самый «худший случай»).
20 февраля 2017 в 22:46
0↑
↓
Есть ли какие-то цифры и факты на эту тему?
Просто гуглеж на тему «lock free vs mutex» выдает какие-то пространные рассуждения на тему быстродействия, аналогично без конкретных замеров…
