[Перевод] Введение в графовые нейросети с механизмом самовнимания на примере PyTorch Geometric

К старту флагманского курса по Data Science реализуем и сравним свёрточную сеть и сеть с механизмом самовнимания. С помощью t-SNE покажем, что и каким образом изучается в графовой сети с механизмом самовнимания. За подробностями приглашаем под кат.
Графовые сети внимания по вполне понятным причинам — один из самых популярных типов графовых нейросетей. В графовых свёрточных сетях у всех соседних узлов важность одинаковая. Очевидно, что так быть не должно.
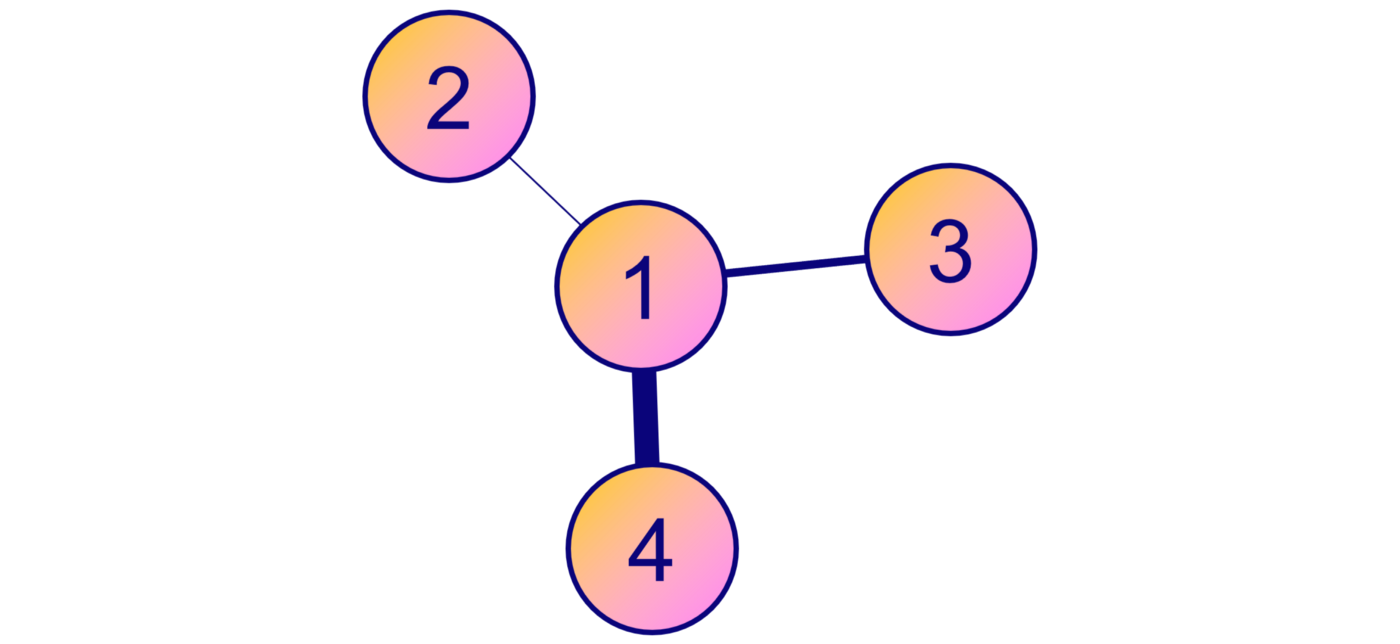 Узел 4 важнее узла 3, который важнее узла 2
Узел 4 важнее узла 3, который важнее узла 2
Эта проблема решается в графовых сетях с механизмом внимания. Чтобы учесть важность каждого соседнего узла, механизмом внимания каждому соединению присваивается весовой коэффициент.
Рассчитаем весовые коэффициенты и реализуем в PyTorch Geometric эффективную графовую сеть с механизмом внимания. Запустить код этого руководства можно в блокноте Google Colab.
Графовые данные
 Набор данных CiteSeer, созданный на yEd Live
Набор данных CiteSeer, созданный на yEd Live
Для наших целей есть три классических набора графовых данных. Это сети научных работ, где каждое соединение узлов — цитата из научной работы.
Cora. Состоит из 2708 работ по машинному обучению в одной из семи категорий. Признаки узла — наличие (1) или отсутствие (0) в работе 1433 элементов набора слов. Иными словами, речь идёт о бинарном «мешке слов».
CiteSeer. Аналогичный набор данных из 3312 научных работ для классификации в одну из шести категорий. Признаки узла — наличие (1) или отсутствие (0) в работе элементов набора из 3703 слов.
PubMed. Это набор данных из 19 717 научных публикаций о диабете из базы данных PubMed из трёх категорий. Признаки узла — взвешенные по TF-IDF векторы слов из словаря на 500 уникальных слов.
Эти наборы данных широко применялись в научном сообществе. Используя многослойные персептроны (MLP), графовые свёрточные сети (GCN) и графовые сети с механизмом внимания (GAT), сравним наши показатели точности с указанными в литературе:

Набор данных PubMed довольно большой, его обработка и обучение на нём графовой нейросети продлятся дольше. Cora — самый изученный в литературе. Поэтому возьмём CiteSeer как усреднённый вариант.
С помощью класса Planetoid в PyTorch Geometric можно напрямую импортировать любой из этих наборов данных:
from torch_geometric.datasets import Planetoid
# Import dataset from PyTorch Geometric
dataset = Planetoid(root=".", name="CiteSeer")
# Print information about the dataset
print(f'Number of graphs: {len(dataset)}')
print(f'Number of nodes: {dataset[0].x.shape[0]}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')
print(f'Has isolated nodes: {dataset[0].has_isolated_nodes()}')Number of graphs: 1
Number of nodes: 3327
Number of features: 3703
Number of classes: 6
Has isolated nodes: TrueУ нас 3327 узлов вместо 3312. На самом деле в PyTorch Geometric используется реализация CiteSeer из этой работы, где тоже показаны 3327 узлов. Но часть узлов, а именно 48, изолирована! Корректно классифицировать их без агрегирования нелегко. Построим график числа соединений каждого узла с помощью degree:
from torch_geometric.utils import degree
from collections import Counter
# Get list of degrees for each node
degrees = degree(data.edge_index[0]).numpy()
# Count the number of nodes for each degree
numbers = Counter(degrees)
# Bar plot
fig, ax = plt.subplots(figsize=(18, 7))
ax.set_xlabel('Node degree')
ax.set_ylabel('Number of nodes')
plt.bar(numbers.keys(),
numbers.values(),
color='#0A047A')
У большинства узлов есть только 1 или 2 соседних. Этим можно объяснить меньшие показатели точности CiteSeer, чем у двух других наборов данных.
2. Самовнимание
Термин «самовнимание» в графовых нейросетях впервые появился в 2017 году в работе Veličković et al., когда за основу взяли простую идею: не у всех узлов должна быть одинаковая важность. И это не просто внимание, а самовнимание — здесь входные данные сравниваются друг с другом:

Этим механизмом каждому соединению присваивается весовой коэффициент (показатель внимания). Пусть αᵢⱼ — это показатель внимания между узлами i и j. Вот как вычисляется встраивание узла 1, где
