[Перевод] Введение в автономную навигацию для дополненной реальности

Компьютерные системы с управлением без помощи контроллеров — новый этап во взаимодействии человека и компьютера. К этой области относятся технологии, воспринимающие физическую среду, включая распознавание жестов, распознавание голоса, распознавание лица, отслеживание движения, реконструкцию среды. Камеры Intel RealSense F200 и R200 реализуют ряд возможностей из этой области. Благодаря возможности съемки с определением глубины камеры F200 и R200 позволяют выстраивать трехмерную среду и отслеживать движение устройства по отношению к среде. Реконструкция среды вместе с отслеживанием движения позволяет реализовать возможности виртуальной реальности, в которой виртуальные предметы вписываются в реальный мир.
Цель этой статьи — ознакомление с автономной навигацией и описание ее применения в приложениях дополненной реальности. Разработанный пример использует камеру Intel RealSense R200 и игровой движок Unity 3D. Рекомендуется заранее ознакомиться с возможностями Intel RealSense SDK и Unity. Сведения об интеграции Intel RealSense SDK с Unity см. в статьях Разработка игр с Unity и камерой Intel RealSense 3D и Первый взгляд: дополненная реальность в Unity с Intel RealSense R200.
Камеры Intel RealSense могут предоставлять данные в приложения дополненной реальности, но создание действительно интересного виртуального мира — дело разработчиков. Один из способов создания живой среды состоит в использовании автономных агентов. Автономные агенты — это объекты, действующие независимо, используя искусственный интеллект. Искусственный интеллект определяет операционные параметры и правила, которым должен подчиняться агент. Агент динамически реагирует на условия среды, в которой он находится, в реальном времени, поэтому даже при простоте принципов действия может обладать сложной моделью поведения.
Автономные агенты могут существовать во множестве видов, однако в этом обсуждении мы остановимся на агентах, способных передвигаться и ориентироваться. К таким агентам относятся игровые персонажи, не управляемые игроком (NPC), и птицы, собирающиеся в стаи в учебных анимационных программах. Цели агентов будут различаться в зависимости от приложения, но принципы передвижения и навигации одинаковы во всех случаях.
Автономная навигация
Навигацию агентов можно осуществить разными способами: как простыми, так и сложными, как с точки зрения реализации, так и с точки зрения ресурсоемкости. Самый простой подход — определить путь, по которому будет двигаться агент. Выбрана путевая точка, затем агент движется к ней по прямой линии. Такой подход несложен в реализации, но его применение сопряжено с несколькими проблемами. Наиболее очевидная из них: что произойдет, если между агентом и путевой точкой нет прямого пути (рис. 1)?

Рисунок 1. Агент движется к цели по прямому пути, но путь прегражден препятствием. Примечание. Описываемые вопросы применимы к навигации и в двухмерном, и в трехмерном пространстве. Здесь для иллюстрации используется двухмерное пространство
Чтобы проложить маршрут в обход препятствий, требуется добавить дополнительные путевые точки (рис. 2).

Рисунок 2. Добавляются дополнительные путевые точки, чтобы агент мог обходить препятствия
На крупных картах с большим числом препятствий будет гораздо больше путевых точек и маршрутов. Кроме того, повышение плотности путевых точек (рис. 3) поможет прокладывать более эффективные маршруты (длина пути агента до точки назначения будет меньше).
Рисунок 3. По мере увеличения размеров карт увеличивается количество путевых точек и возможных маршрутов
При большом количестве путевых точек требуется способ построения маршрута между двумя путевыми точками, расположенными не по соседству одна с другой. Эта проблема называется «поиском пути». Поиск пути тесно связан с теорией графов и применяется во множестве областей, не только в навигации. Естественно, в этой области ведется немало исследований, для решения различных проблем поиска пути создано множество алгоритмов. Одним из наиболее известных алгоритмов поиска пути является A*. Этот алгоритм предусматривает движение между соседними путевыми точками в сторону места назначения и построение карты всех посещенных путевых точек и всех путевых точек, соединенных с ними. После достижения места назначения алгоритм вычисляет путь, используя созданную карту. После этого агент может двигаться по этому пути. Алгоритм А* не предусматривает поиск по всему доступному пространству, поэтому построенный путь далеко не всегда является оптимальным. Эффективность такого алгоритма с точки зрения нагрузки на вычислительные ресурсы достаточно высока.

Рисунок 4. Алгоритм A* осуществляет обход карты, пытаясь отыскать маршрут к цели Анимация: Subh83/CC BY 3.0
Алгоритм А* по своей природе не может адаптироваться к изменениям среды, таким как добавление или удаление препятствий, движение границ. Среда дополненной реальности по своей сути является динамической, поскольку такая среда создается и изменяется в соответствии с движением пользователя и физического пространства.
В динамической среде желательно, чтобы агенты принимали решение в реальном времени; такое решение должно приниматься на основе всего объема текущих знаний агента о среде. Таким образом, необходимо определить структуру, чтобы агент мог принимать решения и действовать в реальном времени. В отношении навигации удобным и распространенным является подход, при котором структура поведения разделяется на три уровня.
- Выбор действия состоит из постановки целей и определения способов достижения этих целей. Например, кролик будет перемещаться по полю в поисках еды, но при появлении рядом хищника кролик будет спасаться бегством. Конечные автоматы (машины конечных состояний) удобно использовать для реализации такого поведения, поскольку они определяют состояния агента и условия, при которых состояния изменяются.
- Наведение — это расчет движения на основе текущего состояния агента. Например, если за кроликом гонится хищник, кролик должен убегать от хищника. Наведение вычисляет как величину, так и направление движения.
- Передвижение — это механика, посредством которой перемещается агент. Кролик, человек, автомобиль и космический корабль перемещаются разными способами. Передвижение определяет и способ движения (например, с помощью ног, колес, ракетных двигателей), и параметры этого движения (например, массу, максимальную скорость, максимальную силу и т. д.).
Вместе эти уровни образуют искусственный интеллект агента. В следующем разделе мы покажем пример приложения Unity, демонстрирующий реализацию этих трех уровней. Далее мы встраиваем автономную навигацию в приложение дополненной реальности с помощью камеры R200.
Реализация автономной навигации
В этом разделе описывается платформа поведения в сцене Unity для автономной навигации, начиная с движения.
▍Передвижение
Передвижение агента основывается на законах динамики Ньютона: при применении силы к массе возникает ускорение. Мы используем упрощенную модель с равномерно распределенной массой тела, к которому может быть применена сила с любого направления. Для ограничения движения задается максимальная сила и максимальная скорость (фрагмент кода 1).
public float mass = 1f; // Mass (kg)
public float maxSpeed = 0.5f; // Maximum speed (m/s)
public float maxForce = 1f; // "Maximum force (N)
Фрагмент кода 1. Модель передвижения агента
Агент должен обладать компонентами rigidbody и collider, которые инициализируются при запуске (см. фрагмент кода 2). Для простоты модели гравитация исключена, но ее можно включить.
private void Start () {
// Initialize the rigidbody
this.rb = GetComponent ();
this.rb.mass = this.mass;
this.rb.useGravity = false;
// Initialize the collider
this.col = GetComponent ();
}
Фрагмент кода 2. Компоненты rigidbody и collider инициализируются при Start ()
Агент перемещается путем применения силы к rigidbody на шаге FixedUpdate () (см. фрагмент кода 3). FixedUpdate () работает аналогично Update (), но гарантированно выполняется с одинаковым интервалом в отличие от Update (). Движок Unity проводит расчет физики (операции с твердыми телами) после завершения шага FixedUpdate ().
private void FixedUpdate () {
Vector3 force = Vector3.forward;
// Upper bound on force
if (force.magnitude > this.maxForce) {
force = force.normalized * this.maxForce;
}
// Apply the force
rb.AddForce (force, ForceMode.Force);
// Upper bound on speed
if (rb.velocity.magnitude > this.maxSpeed) {
rb.velocity = rb.velocity.normalized * this.maxSpeed;
}
}
Фрагмент кода 3. Сила применяется к rigidbody на шаге FixedUpdate (). В этом примере агент перемещается вдоль оси Z
Если величина силы превышает максимальную силу агента, она корректируется таким образом, чтобы сила величины была равна максимальной силе (направление сохраняется). Функция AddForce () применяет силу путем численного интегрирования.
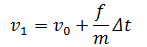
Уравнение 1. Численное интегрирование скорости. Функция AddForce () осуществляет это вычисление
Где ν1 — новая скорость, ν0 — прежняя скорость, f — сила, m — масса, а Δt— интервал времени между обновлениями (по умолчанию фиксированный шаг времени в Unity равен 0,02 с). Если величина скорости превышает максимальную скорость агента, она корректируется таким образом, чтобы совпадать с максимальной скоростью.
▍Наведение
Наведение вычисляет силу, которая будет придана модели передвижения. Будет применено три алгоритма поведения при наведении: поиск, прибытие и уклонение от препятствий.
Поиск
Поведение «Поиск» пытается как можно быстрее двигать объект к цели. Желаемая скорость этого поведения — движение напрямую к цели с максимальной скоростью. Сила наведения вычисляется как разница между желаемой и текущей скоростями агента (рис. 5).

Рисунок 5. Поведение «Поиск» применяет силу наведения, чтобы изменить текущую скорость до желаемой
Реализация (фрагмент кода 4) сначала вычисляет желаемый вектор путем нормализации смещения между агентом и целью и умножения его на максимальную скорость. Возвращаемая сила наведения — это желаемая скорость минус текущая скорость rigidbody.
private Vector3 Seek () {
Vector3 desiredVelocity = (this.seekTarget.position - this.transform.position).normalized * this.maxSpeed;
return desiredVelocity - this.rb.velocity;
}
Фрагмент кода 4. Поведение «Поиск»
Агент использует алгоритм «Поиск», вызывая Seek () при вычислении силы в FixedUpdate () (фрагмент кода 5).
private void FixedUpdate () {
Vector3 force = Seek ();
...
Фрагмент кода 5. Вызов Seek () в FixedUpdate ()
Пример алгоритма «Поиск» в действии показан на видео 1. Агент снабжен синей стрелкой, указывающей текущую скорость rigidbody, и красной стрелкой, указывающей, что на данном временном интервале применяется наведение.
Видео 1. Изначально скорость агента направлена перпендикулярно направлению на цель, поэтому агент движется по кривой
Прибытие
При алгоритме «Поиск» агент промахивается мимо цели и движется вокруг нее, поскольку он двигался с наибольшей возможной скоростью. Алгоритм «Прибытие» схож с алгоритмом «Поиск», а отличие состоит в том, что он пытается полностью остановиться у цели. Параметр «Радиус замедления» определяет расстояние до цели, по достижении которого агент начнет замедлять движение. Когда агент окажется внутри радиуса замедления, величина желаемой скорости будет обратно пропорциональна расстоянию между агентом и целью. В зависимости от значений максимальной силы, максимальной скорости и радиуса замедления такое поведение может не привести к полной остановке.
Поведение «Прибытие» (фрагмент кода 6) сначала вычисляет расстояние между агентом и целью. Приведенная скорость вычисляется как максимальная скорость, приведенная к расстоянию, разделенному на радиус замедления. Желаемая скорость является наименьшей между приведенной скоростью и максимальной скоростью. Таким образом, если расстояние до цели меньше радиуса замедления, то желаемая скорость является приведенной скоростью. В противном случае желаемая скорость является максимальной скоростью. Оставшаяся часть этой функции работает в точности как «Поиск» с желаемой скоростью.
// Arrive deceleration radius (m)
public float decelerationRadius = 1f;
private Vector3 Arrive () {
// Calculate the desired speed
Vector3 targetOffset = this.seekTarget.position - this.transform.position;
float distance = targetOffset.magnitude;
float scaledSpeed = (distance / this.decelerationRadius) * this.maxSpeed;
float desiredSpeed = Mathf.Min (scaledSpeed, this.maxSpeed);
// Compute the steering force
Vector3 desiredVelocity = targetOffset.normalized * desiredSpeed;
return desiredVelocity - this.rb.velocity;
}
Фрагмент кода 6. Поведение «Прибытие»
Видео 2. Алгоритм «Прибытие» снижает скорость при достижении цели
Уклонение от препятствий
Алгоритмы «Прибытие» и «Поиск» отлично подходят для прибытия к месту назначения, но не справляются с препятствиями. В динамичной среде агент должен иметь возможность уклоняться от новых появляющихся препятствий. Алгоритм «Уклонение от препятствий» анализирует путь перед агентом по предполагаемому маршруту и определяет, есть ли на этом пути какие-либо препятствия, которых следует избегать. Если препятствия обнаружены, то алгоритм вычисляет силу, изменяющую путь движения агента таким образом, что агент не сталкивается с препятствием (рис. 6).
Рисунок 6. Если на текущей траектории обнаруживается препятствие, возвращается сила, предотвращающая столкновение
Реализация алгоритма «Уклонение от препятствий» (фрагмент кода 7) использует spherecast для обнаружения столкновений. При этом вдоль текущего вектора скорости rigidbody выпускается сфера, а для каждого столкновения возвращается RaycastHit. Сфера движется из центра агента, ее радиус равен сумме радиуса столкновения объекта со значением параметра «Радиус уклонения». С помощью радиуса уклонения пользователь может определить пустое пространство вокруг агента. Дальность движения сферы ограничивается параметром «Переднее обнаружение».
// Avoidance radius (m). The desired amount of space between the agent and obstacles.
public float avoidanceRadius = 0.03f;
// Forward detection radius (m). The distance in front of the agent that is checked for obstacles.
public float forwardDetection = 0.5f;
private Vector3 ObstacleAvoidance () {
Vector3 steeringForce = Vector3.zero;
// Cast a sphere, that bounds the avoidance zone of the agent, to detect obstacles
RaycastHit[] hits = Physics.SphereCastAll(this.transform.position, this.col.bounds.extents.x + this.avoidanceRadius, this.rb.velocity, this.forwardDetection);
// Compute and sum the forces across all hits
for(int i = 0; i < hits.Length; i++) {
// Ensure that the collidier is on a different object
if (hits[i].collider.gameObject.GetInstanceID () != this.gameObject.GetInstanceID ()) {
if (hits[i].distance > 0) {
// Scale the force inversely proportional to the distance to the target
float scaledForce = ((this.forwardDetection - hits[i].distance) / this.forwardDetection) * this.maxForce;
float desiredForce = Mathf.Min (scaledForce, this.maxForce);
// Compute the steering force
steeringForce += hits[i].normal * desiredForce;
}
}
}
return steeringForce;
}
Фрагмент кода 7. Поведение «Уклонение от препятствий»
При использовании spherecast возвращается массив объектов RaycastHit. Объект RaycastHit содержит информацию о столкновении, в том числе расстояние до столкновения и нормаль к плоскости поверхности, с которой произошло столкновение. Нормаль — это вектор, перпендикулярный плоскости. Его можно использовать, чтобы направить агент в сторону от точки столкновения. Величина силы определяется путем приведения максимальной силы обратно пропорционально расстоянию до столкновения. Силы каждого столкновения складываются, а результат является суммарной силой уклонения в один временной интервал.
Для получения более сложного поведения можно использовать сразу несколько алгоритмов одновременно (фрагмент кода 8). Алгоритм «Уклонение от препятствий» полезен только при использовании вместе с другими алгоритмами. В этом примере (видео 3) «Уклонение от препятствий» используется вместе с алгоритмом «Прибытие». Алгоритмы поведения объединяются просто путем сложения их сил. Возможны и более сложные схемы, где для определения весовых коэффициентов приоритета сил используются эвристические механизмы.
private void FixedUpdate () {
// Calculate the total steering force by summing the active steering behaviors
Vector3 force = Arrive () + ObstacleAvoidance();
...
Фрагмент кода 8. Алгоритмы «Прибытие» и «Уклонение от препятствий» используются одновременно путем сложения их сил
Видео 3. Агент использует сразу два типа поведения: «Прибытие» и «Уклонение от препятствий»
▍Выбор действия
Выбор действия — это постановка общих целей и принятие решений агентом. Наша реализация агента уже включает простую модель выбора действий в виде объединения алгоритмов «Прибытие» и «Уклонение от препятствий». Агент пытается прибыть к цели, но при обнаружении препятствий его траектория будет изменена. Параметры «Радиус уклонения» и «Обнаружение впереди» алгоритма «Уклонение от препятствий» определяют действие, которое будет выполнено.
Интеграция камеры R200
Теперь агент способен самостоятельно передвигаться, его можно включать в приложение дополненной реальности.
Следующий пример создан на основе примера Scene Perception, входящего в состав Intel RealSense SDK. Это приложение создает трехмерную модель с помощью Scene Perception, а пользователь сможет задать и перемещать цель в трехмерном пространстве. После этого агент сможет перемещаться по созданной трехмерной модели для достижения цели.
▍Scene Manager
Сценарий Scene Manager инициализирует сцену и обрабатывает пользовательское управление. Единственным видом управления является касание (или щелчок мыши, если устройство не поддерживает касания). Трассировка луча из точки касания определяет, происходит ли касание созданной трехмерной модели. Первое касание создает цель на трехмерной модели, второе — создает агента, а каждое последующее касание перемещает положение цели. Логику управления обрабатывает конечный автомат (фрагмент кода 9).
// State machine that controls the scene:
// Start => SceneInitialized -> TargetInitialized -> AgentInitialized
private enum SceneState {SceneInitialized, TargetInitialized, AgentInitialized};
private SceneState state = SceneState.SceneInitialized; // Initial scene state.
private void Update () {
// Trigger when the user "clicks" with either the mouse or a touch up gesture.
if(Input.GetMouseButtonUp (0)) {
TouchHandler ();
}
}
private void TouchHandler () {
RaycastHit hit;
// Raycast from the point touched on the screen
if (Physics.Raycast (Camera.main.ScreenPointToRay (Input.mousePosition), out hit)) {
// Only register if the touch was on the generated mesh
if (hit.collider.gameObject.name == "meshPrefab(Clone)") {
switch (this.state) {
case SceneState.SceneInitialized:
SpawnTarget (hit);
this.state = SceneState.TargetInitialized;
break;
case SceneState.TargetInitialized:
SpawnAgent (hit);
this.state = SceneState.AgentInitialized;
break;
case SceneState.AgentInitialized:
MoveTarget (hit);
break;
default:
Debug.LogError("Invalid scene state.");
break;
}
}
}
}
Фрагмент кода 9. Обработчик касаний и конечный автомат для примера приложения
Компонент Scene Perception формирует множество небольших трехмерных моделей. Такие модели обычно имеют не более 30 вершин. Расположение вершин может изменяться, в результате чего некоторые модели несколько наклонены по отношению к поверхности, на которой они находятся. Если объект находится поверх модели (например, цели или объекта), то объект будет неправильно ориентирован. Чтобы обойти эту проблему, используется средняя нормаль трехмерной модели (фрагмент кода 10).
private Vector3 AverageMeshNormal(Mesh mesh) {
Vector3 sum = Vector3.zero;
// Sum all the normals in the mesh
for (int i = 0; i < mesh.normals.Length; i++){
sum += mesh.normals[i];
}
// Return the average
return sum / mesh.normals.Length;
}
Фрагмент кода 10. Вычисление средней нормали трехмерной модели
▍Сборка приложения
Весь код, разработанный для этого примера, доступен на сайте Github.
Следующие инструкции встраивают Scene Manager и реализацию агента в приложение Intel RealSense.
- Откройте пример RF_ScenePerception в папке Intel RealSense SDK RSSDK\framework\Unity.
- Загрузите и импортируйте пакет AutoNavAR Unity.
- Откройте RealSenseExampleScene в папке Assets/AutoNavAR/Scenes/.
- Соберите и запустите приложение на любом совместимом устройстве с камерой Intel RealSense R200.
Видео 4. Выполненная интеграция с камерой Intel RealSense R200
Дальнейшее развитие автономной навигации
Мы разработали пример, демонстрирующий автономный агент в приложении дополненной реальности с камерой R200. Существует несколько способов развить эту работу, повысить «разумность» и реалистичность агента.
В качестве агента использовалась упрощенная механическая модель с равномерным распределением массы и без ограничений движений по направлениям. Можно разработать более совершенную модель, в которой масса будет распределена неравномерно, а силы, применяемые к телу, будут ограничиваться (например, автомобиль с разными силами разгона и торможения, космический корабль с основным двигателем и боковыми маневровыми двигателями). Чем точнее выполнены механические модели, тем более реалистичным будет движение.
Крейг Рейнольдс (Craig Reynolds) первым подробно описал поведенческие алгоритмы наведения в контексте анимации и игр. Алгоритмы «Поиск», «Прибытие» и «Уклонение от препятствий», продемонстрированные в нашем примере, созданы на основе его работы. Рейнольдс описал и другие алгоритмы поведения, в том числе «Бегство», «Преследование», «Странствие», «Исследование», «Уклонение от препятствий» и «Следование по маршруту». Рассматриваемые групповые алгоритмы поведения включают «Разделение», «Слияние» и «Построение». Еще один полезный ресурс — «Программирование искусственного интеллекта игр на примерах» Мэта Бэкленда (Mat Buckland). Здесь описывается реализация поведенческих алгоритмов и ряд других вопросов, в том числе конечные автоматы и поиск путей.
В этом примере к агенту одновременно применяются алгоритмы наведения «Прибытие» и «Уклонение от препятствий». Так можно сочетать любое количество алгоритмов поведения для получения более сложных моделей. Например, поведенческий алгоритм «Объединение в стаю» создан на основе разделения, слияния и построения. Сочетание различных поведенческих алгоритмов может иногда дать неестественный результат. Рекомендуется поэкспериментировать с разными типами таких алгоритмов для выявления новых возможностей.
Кроме того, некоторые методики поиска путей предназначены для использования в динамических средах. Алгоритм D* близок к A*, но может обновлять путь на основе новых наблюдений (т. е. добавленных и удаленных препятствий). Алгоритм D* Lite работает так же, как D*, и проще в реализации. Поиск путей можно использовать вместе с наведением: можно задать путевые точки, а затем использовать наведение для их обхода.
Выбор действий не обсуждается в этой статье, но широко изучается в теории игр. В теории игр исследуется математическая основа стратегии и принятия решений. Теория игр применяется во множестве областей, включая экономику, политические науки и психологию. В отношении автономных агентов теория игр может управлять тем, как и когда принимаются решения. «Теория игр 101: полный справочник» Уильяма Спаниэля (William Spaniel) — отличный начальный ресурс, снабженный серией видеоматериалов в YouTube.
Заключение
Существует целый арсенал инструментов для настройки движения, поведения и действий агентов. Автономная навигация наиболее подходит для динамических сред, подобных создаваемым камерой Intel RealSense в приложениях дополненной реальности. Даже простые модели движения и наведения могут образовывать сложное поведение без предварительного знания среды. Изобилие доступных моделей и алгоритмов обеспечивает гибкость реализации автономных решений для любых приложений.
