[Перевод] Вред маленьких функций

Перевод статьи Синди Шридхаран.
В этой статье автор собирается:
- Пролить свет на некоторые предполагаемые преимущества маленьких функций.
- Объяснить, почему некоторые из преимуществ вовсе не такие радужные, как рекламируется.
- Объяснить, почему маленькие функции иногда контрпродуктивны.
- Объяснить, в каких случаях маленькие функции действительно полезны.
Среди общих советов по программированию неизменно превозносятся элегантность и эффективность маленьких функций. В книге «Чистый код» — многими воспринимаемой в качестве библии программистов — есть глава, посвящённая одним лишь функциям, и она начинается с примера поистине ужасной, и к тому же длинной функции. И дальше в книге длина функции клеймится как самый страшный грех:
Функция не только длинная, она содержит дублирующий код, кучу непонятных строковых значений и много странных и неочевидных типов данных и API. Вы разобрались в ней после трёх минут изучения? Вероятно, нет. В ней происходит слишком многое и на слишком многих уровнях абстракции. Здесь непонятные строковые значения и странные вызовы функций перемешаны с выражениями if двойной вложенности, управляемыми флагами.
В той же главе кратко обсуждается, какие качества должны сделать код «простым в чтении и понимании» и «позволить случайному читателю интуитивно понять, какого рода программе они принадлежат», а потом заявляется, что для этого необходимо делать функции меньше.
Первое правило функций гласит, что они должны быть маленькими. Второе правило гласит, что функции должны быть ещё меньше.
Идея, что функции должны быть маленькими, считается практически священной и не подлежащей пересмотру. Она часто всплывает в ходе ревизий кода, в дискуссиях в Twitter, на конференциях, в книгах и подкастах, статьях про лучшие методики рефакторинга и так далее. И недавно эта идея выскочила в ленте в виде такого твита:
В моём Ruby-коде половина методов длиной всего в одну-две строки. 93% короче 10. https://t.co/Qs8BoapjoP https://t.co/ymNj7al57j
— @martinfowler
Автор приводит ссылку на свою статью о длине функций, в которой пишет:
Если при взгляде на фрагмент кода вы приложили усилия чтобы понять, что тут делается, значит вам нужно извлечь это в функцию и дать ей имя в честь этого «что».Приняв для себя этот принцип, я выработал привычку писать очень маленькие функции — обычно длиной всего несколько строк [2]. Меня настораживает любая функция длиной больше пяти строк, и я нередко пишу функции длиной в одну строку [3].
Достоинства маленьких функций пропагандируются столь часто, что всего через несколько дней эта тема всплыла в виде такого твита:
Мне нравится часть совета @dc0d_
— @davecheney
Некоторые так озабочены маленькими функциями, что страстно отстаивают идею абстрагирования любой и каждой части номинально сложной логики в отдельную функцию.
Нам приходилось работать с кодовыми базами, написанными людьми, впитавшими эту идею до такой нечестивой степени, что конечный результат получился адским и полностью противоречащим всем добрым намерениям, которыми был вымощен путь. В этой статье мы хотим объяснить, почему некоторые из широко разрекламированных преимуществ маленьких функций не всегда соответствуют нашим надеждам, а иногда и вовсе контрпродуктивны.
Предполагаемые преимущества маленьких функций
В подтверждение достоинств маленьких функций обычно выкатывается ряд утверждений.
Делают что-то одно
Небольшая функция имеет больше шансов делать что-то одно. Примечание: Маленькая != Одна строка.
—@davecheney
Идея проста: функция должна делать только что-то одно, и делать её хорошо. На первый взгляд звучит очень здраво, даже в некой гармонии с философией Unix.
Неясность возникает тогда, когда нужно определить «что-то одно». Это может быть что угодно, от простого выражения возвращения до условного выражения, части математического вычисления или сетевого вызова. Как это часто бывает, «что-то одно» означает один уровень абстракции какой-то логики (обычно бизнес-логики).
Например, в веб-приложении «чем-то одним» может быть CRUD-операция вроде «создания пользователя». При создании пользователя как минимум необходимо сделать запись в базе данных (и обработать все сопутствующие ошибки). Возможно, также придётся отправить человеку приветственное письмо. Более того, кто-то ещё захочет инициировать специальное сообщение в брокере сообщений вроде Kafka, чтобы скормить событие другим системам.
Получается, что «один уровень абстракции» вовсе не один. Некоторые программисты, безоговорочно принявшие идею, что функция должна делать «что-то одно», с трудом сопротивляются стремлению рекурсивно применять этот принцип к каждой своей функции или методу.
Так что многие из них не могут остановиться, пока не сделают функцию полностью DRY и модульной —, а это никогда не получается идеально
— @copyconstruct
То есть вместо разумной и непоколебимой абстракции, которую можно понять (и протестировать) как один элемент, мы создаём ещё более мелкие элементы, из которых формируются все компоненты «чего-то одного», пока это одно не станет полностью модульным и полностью DRY.
Ошибочность DRY
DRY is one of the most dangerous design principlα (34) floatiα (25) aα (28)und α (29)t α (13)α (27)e toα (22)y
— @xaprb
DRY не обязательно синоним пристрастия делать функции как можно меньше. Но я много раз наблюдал, как второе приводит к первому. Я считаю, что DRY хороший ориентир, но очень часто прагматизм и разум кладутся на алтарь догматического следования этому принципу, в особенности программистами с Rails-убеждениями.
У Реймонда Хеттингера, одного из основных разработчиков Python, есть фантастическое выступление Beyond PEP8: Best practices for beautiful, intelligible code. Его нужно посмотреть не только Python-программистам, а вообще всем, кто интересуется программированием или зарабатывает им на жизнь. В нём очень проницательно разоблачены недостатки догматического следования PEP8 — руководству по стилю в Python, реализованному во многих линтерах. И ценность выступления не в том, что оно посвящено PEP8, а в ценных выводах, которые можно сделать, многие из которых не зависят от конкретного языка.
Посмотрите хотя бы одну минуту из выступления, во время которой рисуется пугающе точная аналогия с коварным зовом DRY. Программисты, настаивающие на широчайшем применении DRY, рискуют за деревьями не увидеть леса.
Главный недостаток в DRY — это принуждение к абстракциям, вложенным и преждевременным. Поскольку невозможно абстрагироваться идеально, нам приходится делать это неплохо, в меру своих сил. При этом нельзя дать точное определение, насколько должно быть «неплохо», это зависит от многих факторов.
На этом графике термин «абстракция» можно заменить на «функцию». Например, прикидывая, как лучше всего спроектировать уровень абстракции А, можно продумать:
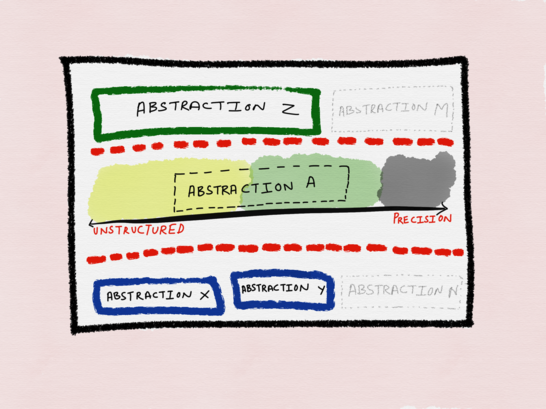
- Характер предположений, лежащих в основе абстракции А, какова вероятность (и длительность) того, что они будут логичными.
- Склонность уровней абстракций, лежащих в основе абстракции А (X и Y), а также базирующихся на ней (Z), оставаться согласованными, гибкими и корректными в реализации и проектировании.
- Каковы требования и ожидания в отношении любых будущих абстракций выше (М), или ниже абстракции А (N).
Разрабатываемая нами абстракция А неизбежно будет постоянно пересматриваться, вплоть до частичного или полного отказа. Поэтому основополагающим свойством нашей абстракции, которая неизбежно будет модифицироваться, должна быть гибкость.
И если мы прямо сейчас начнём при любой возможности использовать принцип DRY, то лишим себя в будущем этой гибкости, способности адаптироваться к любым возможным изменениям. Что нам действительно нужно сделать, так это дать себе немного свободы вносить неизбежные изменения, которые потребуются рано или поздно, а не начинать сразу же строить идеальное решение.
Лучшая абстракция — та, что оптимизируется достаточно, а не идеально. Это фича, а не баг. Необходимо понять эту важнейшую особенность абстракций, чтобы успешно их проектировать.
У Алекса Мартелли, придумавшего фразу «утиная типизация» (duck-typing) и знаменитую Pythonista, есть выступление под названием The Tower Of Abstraction; почитайте эти слайды из презентации:


У известной рубистки Сэнди Метц есть выступление All The Little Things, в котором она постулировала, что «дублирование гораздо дешевле неправильной абстракции», а значит нужно «предпочесть дублирование неправильной абстракции».
Я считаю, что абстракции вообще не могут быть «правильными» или «неправильными», потому граница между этими понятиями нечеткая и вечно меняется. Нашу тщательно выпестованную «идеальную» абстракцию от статуса «неправильной» отделяет лишь одно бизнес-требование или отчёт об ошибке.
Мне кажется, абстракцию нужно воспринимать как некий диапазон, как на графике выше. Один край диапазона — это оптимизация с точки зрения точности, в то время как абсолютно все аспекты нашего кода нужно оптимизировать до состояния абсолютной точности. Но лучшее — враг хорошего: стремление к идеалу не поможет спроектировать хорошие абстракции, поскольку требует идеального соответствия. Другая часть нашего спектра — это оптимизация с точки зрения неточности и отсутствия границ. И несмотря на максимальную гибкость, у этого подхода есть свои недостатки.
Иногда для конкретного контекста есть лишь ОДНО идеальное решение. Но контекст может в любое время измениться, как и идеальное решение https://t.co/ML7paTXtdu
— @copyconstruct
Как и в большинстве случаев, «идеал» находится где-то посередине. Не существует универсального идеального решения. «Идеальность» зависит от множества факторов — программистских и межличностных, — и хороший разработчик должен уметь распознать, где находится «идеальная» точка спектра для каждого контекста, и постоянно переоценивать этот идеал.
Имена
После решения, что и как мы абстрагируем, важно дать абстракции имя.
А именовать трудно.
В программировании считается прописной истиной, что давать длинные, описательные имена — это хорошо, причём некоторые выступают за замену комментариев в коде на функции, имена которых представляют собой комментарии. Смысл в том, что чем более описательное имя, тем лучше инкапсуляция.
и наконец именование. Фоулер с друзьями выступают за описательные имена,
такЧтоМыСделалиИменаКакЭтоКоторыеОченьТрудноЧитать
— @copyconstruct
Возможно, это прокатывает в мире Java, где многословие в порядке вещей. Но код с такими именами трудно читать. При чтении кода такие слепки из кучи слов вводят меня в лёгкий ступор, пока я пытаюсь выделить все эти слоги в имени функции, встроить её в мысленную модель, которая к тому моменту сформировалась у меня в голове, а затем решить, стоит ли перейти к определению функции и изучить её реализацию.
Но с «маленькими функциями» другая проблема: погоня за ними приводит к тому, что маленьких функций становится ещё больше, и у всех многословные имена ради отказа от комментариев и самодокументированности кода.
И меня сильно утомляет осмысление многословных имён функций (и переменных), встраивание их в мысленную модель, решение, какие изучить подробнее, а какие пропустить, и наконец сложение всех кусочков мозаики в единую картину.
Чем меньше функции, тем больше их и их имён. Лучше я буду читать код, а не имена функций.
— @copyconstruct
Я считаю, что ключевые слова, конструкты и идиомы, предлагаемые языком программирования, визуально воспринимаются гораздо легче, чем придуманные имена переменных и функций. Например, когда я читаю блок if-else, то редко вдумываюсь в if или elseif, тратя больше времени на осмысление логики работы программы.
И мне неприятно, когда ход моих мыслей нарушается чем-то вроде aVeryVeryLongFuncNameAndArgList. Особенно если вызываемая функция состоит из одной строки и легко могла быть инлайнена. Контекстные переключения не дёшевы, неважно, процессорные это переключения, или программисту приходится мысленно переключаться, читая код.
Ещё одно следствие избытка маленьких функций, особенно с очень описательными и неинтуитивными именами — труднее искать по кодовой базе. Функцию createUser грепать просто, а функцию renderPageWithSetupsAndTeardowns (это имя взято в качестве яркого примера из книги Clean Code), напротив, не так просто запомнить или найти. Многие редакторы поддерживают нечёткий поиск по кодовой базе, поэтому избыток функций с похожими префиксами наверняка приведёт к очень большому количеству результатов в выдаче, что трудно назвать идеалом.
Потеря локальности
Лучше всего маленькие функции работают тогда, когда для поиска определения функции нам не нужно покидать пределы файла или границы пакета. С этой целью в книге Clean Code предлагается так называемое Правило понижения (The Stepdown Rule).
Нам нужно, чтобы код читался как связное повествование. Нам нужно, чтобы за каждой функцией следовали другие функции на следующем уровне абстракции, чтобы по мере чтения списка функций мы последовательно опускались по уровням абстракции. Я называю это Правилом понижения.
В теории звучит прекрасно, но я редко видел, чтобы это работало на практике. Напротив, когда в код добавляется много функций, почти неизменно теряется локальность.
Предположим, что мы начали с трёх функций А, В и С, которые вызываются (и читаются) друг за другом. Изначально наши абстракции подкреплялись определёнными предположениями, требованиями и оговорками, которые мы усердно исследовали и аргументировали в начале проектирования.

Довольно скоро у нас появилось непредвиденное новое требование, пограничный случай или ограничение. Нужно модифицировать функцию А, поскольку инкапсулированное в ней «что-то одно» больше не подходит (или изначально не подходило и теперь требует исправления). В соответствии с советами из Clean Code мы решили, что лучше всего создать новые функции, в которые спрячем новые требования.
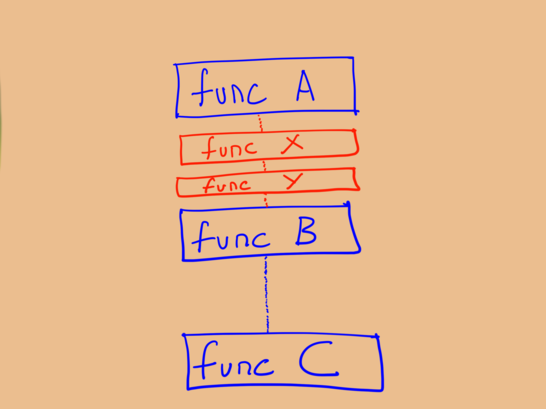
Пару недель спустя концепция снова поменялась и нам приходится создавать дополнительные функции для инкапсулирования дополнительных требований.
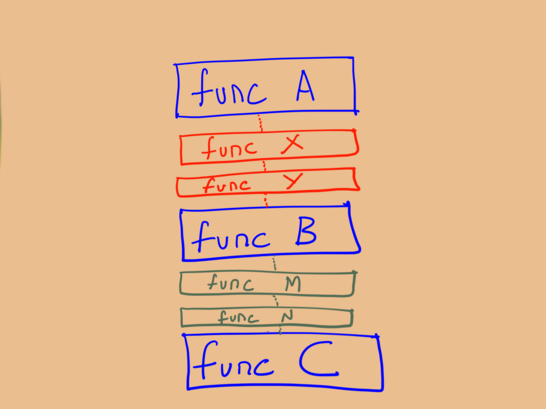
Вот мы и пришли к той самой проблеме, описанной Сэнди Метц в её статье The Wrong Abstraction. Там говорится:
Существующий код оказывает мощное воздействие. Самим своим существованием он утверждает свою корректность и необходимость. Мы знаем, что код отражает вложенные в него усилия, и мы очень не хотим их обесценить. Но, к сожалению, истина такова, что чем сложнее и непредсказуемее код, то есть чем больше мы в него вкладываем, тем больше ощущаем необходимость сохранить его («ошибка невозвратных затрат»).
Возможно, это верно для команды, изначально работавшей над кодовой базой и продолжающей её поддерживать, но встречались противоположные ситуации, когда базой начинают владеть новые программисты (или руководители). То, что начиналось с благих намерений, превращается в спагетти-код, который уж точно невозможно назвать чистым и который всё сильнее хочется реорганизовать или переписать целиком.
Кто-то скажет, что это в определённой степени неизбежно. И будет прав. Мы редко говорим о том, как важно писать код, который будет умирать постепенно (graceful death). Раньше я уже писал о том, как важно, чтобы код можно было легко вывести из эксплуатации, а для самой кодовой базы это ещё важнее.
+1. Нужно оптимизировать код, чтобы он умирал постепенно. В этом должен был помочь принцип открытости/закрытости, но не получилось
— @copyconstruct
Программисты слишком часто считают код «мёртвым» только в том случае, если он удалён, больше не используется или сам сервис выключен. Если же код, который мы пишем, будем считать умирающим при каждом добавлении нового Git-коммита, то это может побудить нас писать код, удобный для модифицирования. Если думать о том, как лучше абстрагировать, то это сильно помогает осознать тот факт, что создаваемый нами код может умереть (быть изменённым) уже через несколько часов. Так что куда полезнее делать код удобным для модифицирования, чем пытаться выстроить повествование, как это советуется в Clean Code.
Загрязнение классами
В языке, поддерживающем ООП, с уменьшением функций увеличивается размер или количество классов. Мы видели, как в случае с Go это приводило к разрастанию интерфейсов (в сочетании с интерфейсным загрязнением) или большому количеству мелких пакетов.
Это усугубляет когнитивные нагрузки при сопоставлении бизнес-логики с нашими абстракциями. Чем больше классов/интерфейсов/пакетов, тем труднее разобраться со всем этим одним махом, и ничто не оправдывает затраты на поддержание всех этих построенных нами классов/интерфейсов/пакетов.
Меньше аргументов
Приверженцы маленьких функций почти неизменно стремятся передавать им меньше аргументов.
Проблема в том, что из-за этого возрастает риск сделать зависимости неявными.
Кроме того, при использовании в языках с наследованием, вроде Ruby, это приводит к сильной зависимости функций от глобального состояния и синглтонов
— @copyconstruct
Мне встречались в Ruby классы с 5–10 маленькими методами, каждый из которых делал что-то очень простое и брал в качестве аргументов один-два параметра. Многие из этих методов изменяют общее глобальное состояние или зависят от неявно передаваемых им синглтонов, что можно расценить как антипаттерн.
Кроме того, при неявности зависимостей сильно усложняется тестирование, в придачу к трудностям настройки и сброса состояния перед каждым тестом наших крошечных функций.
Трудно читать
Я уже говорил об этом выше, но стоит напомнить: многочисленные маленькие функции, особенно длиной в одну строку, чрезмерно затрудняют чтение кодовой базы. Особенно это вредит новичкам, для которых код и должен быть оптимизирован в первую очередь.
Черты «новичка в кодовой базе»: 1. и правда новичок 2. ветеран другой подсистемы 3. исходный автор
— @sdboyerпрочие факторы, которые надо учесть — 1) новичок в языке программирования 2) новичок во фреймворке (rails, django и так далее) 3) новичок в организационном стиле
— @copyconstruct
Есть несколько видов новичков в кодовой базе. Лучше всего иметь в команде кого-то, способного проверить ряд категорий этих «новичков». Это помогает мне пересмотреть свои предположения и непреднамеренно навязанные мной какому-то новичку трудности при первом прочтении кода. Я понял, что этот подход действительно помогает сделать код лучше и проще, чем при противоположном подходе.
Простой код необязательно легче в написании, и в нём вряд ли будет применён принцип DRY. Нужно потратить кучу времени на обдумывание, уделить внимание подробностям и постараться прийти к самому простому решению, одновременно верному и лёгкому в обсуждении. Самое поразительное в этой труднодостижимой простоте, что такой код одинаково легко понимают и старые, и новые программисты, что бы ни подразумевалось под «старыми» и «новыми».
«Новичку» в кодовой базе, если ему повезло и он уже знает используемый язык и/или фреймворк, то самое трудное для него — понять бизнес-логику или подробности реализации. А если не повезло и приходится прокладывать путь сквозь кодовую базу на незнакомом языке, то главной проблемой будет пройти по канату между достаточным пониманием языка/фреймворка, чтобы можно было без затруднений понять, что делает код, и способностью выделить «что-то одно» и понять, как проработать это настолько, чтобы проект перешёл на следующую стадию.
И вряд ли в подобных ситуациях часто бывало так, что вы смотрите на незнакомую кодовую базу и думаете:
О, посмотрите на эти функции. Такие маленькие. Такие DRY. Такие прекраааааааасные.
Когда рискуешь заходить на неизведанные территории, то надеешься лишь, что придётся сделать как можно меньше мысленных скачков и переключений контекста, пытаясь найти ответ на вопрос.
Если об абстракции трудно рассуждать (или приходится ломать голову там, где в этом нет нужды), то оно того не стоит.
— @copyconstruct
Трата времени и сил на упрощение кода ради тех, кто будет в будущем его сопровождать или использовать, будет иметь огромную отдачу, особенно для open source-проектов.
Когда маленькие функции действительно полезны
Несмотря на всё сказанное, маленькие функции могут быть полезны, особенно при тестировании.
Сетевой ввод-вывод
Ага, расскажи мне, как всё хорошо работает, когда ты запускаешь пару десятков сервисов с разными dbs и зависимостями на своём macbook.
— @tyler_treatКроме того, большие интеграционные тесты, охватывающие многие сервисы, являются антипаттерном, но убеждать в этом людей до сих пор бесполезно.
— @tyler_treat
Не будем рассказывать, как лучше всего писать функциональные, интеграционные и модульные тесты для множества сервисов. Но когда речь заходит о модульных тестах сетевого ввода-вывода, то на самом деле ничего не тестируется.
Разгон и обрушение базы данных/очереди ради модульного тестирования может быть плохой идеей, но излишне усложнённые заглушки/фальшивки гораздо хуже.
— @copyconstruct
Не стоит быть фанатом заглушек. У них несколько недостатков. Начнём с того, что заглушки — искусственная симуляция какого-то результата. Они хороши не больше, чем позволяет наше воображение и возможность предсказать разные виды сбоев, с которыми может столкнуться приложение. Скорее всего, работа заглушек не совпадает с реальным сервисом, который они замещают, если только вы тщательно не протестируете каждую из них на соответствие. К тому же заглушки работают лучше всего, когда каждая из них в единственном экземпляре и каждый тест использует одну и ту же заглушку.
Тем не менее, заглушки всё ещё практически единственный способ модульного тестирования сетевого ввода-вывода. Мы живём в эру микросервисов и аутсорсинга вендору большинства (если не всех) проблем, не относящихся к ядру нашего основного продукта. Многие функции ядра приложения используют от одного до пяти сетевых вызовов, и при модульном тестировании лучше всего вместо этих вызовов использовать заглушки.
В целом, заглушки нужно применять только в минимальном количестве кода. Когда API вызывает почтовый сервис, чтобы отправить нашему свежесозданному пользователю приветственное письмо, нужно установить HTTP-соединение. Изолирование этого запроса в наименьшей возможной функции позволит в тестах имитировать заглушкой наименьший кусок кода. Обычно это должна быть функция не длиннее 1–2 строк, которая устанавливает HTTP-соединение и возвращает с ответом любую ошибку. То же самое относится к публикации события в Kafka или к созданию нового пользователя в БД.
Тестирование на основе свойств
Учитывая, что тестирование на основе свойств (property based testing) приносит невероятную выгоду с помощью такого небольшого кода, оно используется преступно мало. Впервые такой вид тестирования появился в Haskell-библиотеке QuickCheck, а потом был внедрён другие языки, например в Scala (ScalaCheck) и Python (Hypothesis). Тестирование на основе свойств позволяет в соответствии с определёнными условиями генерировать большое количество входных данных для какого-то теста и гарантировать его прохождение во всех этих случаях.
Многие тестовые фреймворки заточены под тестирование функций, и потому имеет смысл изолировать до одной функции всё, что может быть подвергнуто тестированию на основе свойств. Это особенно пригодится при тестировании кодирования или декодирования данных, либо для тестирования парсинга JSON/msgpack, и тому подобного.
Заключение
DRY и маленькие функции — это не обязательно плохо (даже если это следует из лукавого заголовка). Но они вовсе не обязательно хороши.
Количество маленьких функций в кодовой базе, или средняя длина функций — не повод для хвастовства. На конференции 2016 Pycon было выступление под названием onelineizer, посвящённое одноимённой программе, способной конвертировать любую программу на Python (включая саму себя) в одну строку кода. Об этом забавно рассказать перед слушателями на конференции, но глупо писать production-код в той же манере.
По словам одного из лучших программистов современности:
профессиональный совет в Go: не следуйте слепо догматическому совету, всегда руководствуйтесь своим мнением.
— @rakyll
Это универсальный совет, не только для Go. Сложность программ, которые мы создаём, значительно возросла, а ограничения, с которыми мы сталкиваемся, стали более разнообразными, поэтому программисты должны соответствующим образом адаптировать свое мышление.
К сожалению, ортодоксальное программирование всё ещё сильно влияет на умы с помощью книг, написанных во времена царствования ООП и «шаблонов проектирования». Многие из пропагандируемых идей и практик не подвергались сомнению в течение десятилетий и срочно требуют пересмотра. Особенно потому, что в последние годы ландшафт и парадигмы программирования сильно эволюционировали. Ходя старыми тропами, программисты становятся ленивее и погружаются в ощущение самоуверенности, которое они вряд ли могут себе позволить.
