[Перевод] Внедряем устойчивый SRE-подход в компании

Сложно управлять микросервисами, не придерживаясь принципов SRE (site reliability engineering — обеспечение надёжности информационных систем). В этой статье мы расскажем, как наладили процесс SRE в компании Reputation.
В 2020 году у компании Reputation было больше 150 микросервисов, которые собирали и обрабатывали миллионы отзывов из интернета, извлекая из них полезную информацию для наших клиентов. Правда, данных и сервисов у нас было столько, что нам с трудом удавалось мониторить систему вручную и оценивать её надёжность.
Мы получали жалобы, например: «Вы не собрали отзывы об этом заведении в TripAdvisor за последние три месяца», «Вы опаздываете с ответами на отзывы по этому отделению» или «У меня в Google меньше отзывов, куда делись запросы на отзывы».
Мы собирали миллионы отзывов и отправляли миллионы запросов на отзывы с нашей платформы, так что нам нужна была надёжная система для мониторинга на уровне отдельных клиентов или даже филиалов клиента (под филиалом мы подразумеваем, например, магазин в Сан-Франциско), чтобы можно было вовремя замечать, когда что-то идёт не так. Что ещё важнее, на основе этих данных мы могли бы инвестировать в улучшение надёжности наших сервисов или добавление новых функций.
Определяем проблему
Прежде чем мы в Reputation приступили к полноценному внедрению принципов SRE, у нас было две команды: команда инженеров, которая занималась возможностями продуктов, их обслуживанием и исправлением багов, и команда эксплуатации, которая отвечала за порядок в продакшене. Она следила за работоспособностью инфраструктуры, сервисов, баз данных и так далее. Так что аптайм у сервисов был очень хороший (обычно 99,99%). Поэтому мы очень удивлялись, когда клиенты жаловались на нарушение SLA для одного из их филиалов.
Например, запланированное для клиента задание начиналось на 15 минут позже или выполнялось слишком долго. Отзывы собирались в разных объёмах и не полностью. Уведомления по электронной почте приходили не вовремя и т. д. Всё это указывало, скорее, на проблемы с приложением и бизнес-логикой, а не с инфраструктурой.
Мы решили реализовать устойчивый процесс SRE, чтобы достичь следующих целей:
Определить SLO (service level objective, целевые уровни обслуживания) и SLI (service level indicator, индикаторы уровня обслуживания).
Автоматизировать отслеживание SLI.
Создать дашборды для SLO.
Повысить надёжность сервисов на основе показателей SLO.
Подготовка команды и процесса
Для начала мы собрали независимую команду из пяти SRE-инженеров. Они должны были вместе с владельцем каждого сервиса определить SLO, SLI и требования к мониторингу этого сервиса. Работая с командами сервисов, SRE-инженеры изучили функционал каждого продукта, чтобы помочь владельцам сервисов и продуктов обозначить SLO.
SLO указывает целевой уровень надёжности сервиса.
Последнее слово при определении SLO оставалось за владельцем сервиса. Определив SLO, SRE-инженеры и владельцы сервисов приступили к SLI.
SLI — это индикатор уровня предоставляемого обслуживания.
SLO — это целевое значение или диапазон значений для уровня обслуживания, который измеряется с помощью SLI. Мы соблюдаем SLO, если:
SLI <= target
or
lower bound <= target <= upper boundНапример, мы измеряем надёжность сервиса по времени выполнения заданий и хотим, чтобы все задания выполнялись от 15 до 30 минут.
Определив SLO и SLI, мы должны задать целевое значение надёжности для SLO. Мы хотим, чтобы 100% заданий выполнялись за 15–30 минут? Поначалу достигнуть 100% SLO будет сложно, потому что у команды нет достаточно данных. К тому же завышенные ожидания приведут к лишнему стрессу для сотрудников, если желаемых показателей не удастся достичь. В идеале следует задать не слишком высокое значение и периодически корректировать его.
Например, в нашем примере можно было бы задать для SLO следующие целевые значения:
95% of jobs should complete within 30 minutes
Job Latency <= 30 minutes
90% of jobs should be complete between 15 to 30 minutes
15 minutes <= Job Latency <= 30 minutesОпределив SLO, SLI и целевые значения, мы должны решить, как часто будем измерять их. Например, SLO можно измерять ежемесячно или за скользящий период (например, за последние 28 дней). Впоследствии мы будем сравнивать SLO за эти периоды. Мы, например, рассчитываем SLO за фиксированный месяц, чтобы затем отслеживать тренды из месяца в месяц.
Реализация
Определив SLO, SLI, целевые значения надёжности и период измерения, мы должны найти способы измерять SLI. После сбора SLI из них можно рассчитать SLO. Затем SLO нужно объединить за указанный период (например, месяц).
Давайте посмотрим на примере, как SRE-инженеры помогли владельцу сервиса определить SLO.
RepConnect — это сервис, который управляет заданиями. Клиенты планируют задания в RepConnect в указанное время дня и ожидают, что RepConnect будет запускать эти задания и выполнять их в заданные сроки. SRE-инженеры вместе с владельцем RepConnect определили SLO и SLI.
SLO: время выполнения задания
90% заданий должны выполняться за 15 минут
95% заданий должны выполняться за 30 минут
SLO: задержка задания
90% заданий должны начинаться в пределах 15 минут от запланированного времени
95% заданий должны начинаться в пределах 30 минут от запланированного времени
Период времени: один месяц
Как измерять
Мы в Reputation реплицируем данные рантайма из MongoDB в BigQuery каждые 15 минут (как описано здесь). Команда SRE решила использовать BigQuery, чтобы отслеживать SLI и рассчитывать SLO. Они написали хранимую процедуру в BigQuery и запланировали её выполнение раз в день. Мы собирались рассчитывать SLO за месяц, поэтому считали показатели не в реальном времени, а раз в день. Хранимая процедура должна была обрабатывать все записи о заданиях и вычислять время, затраченное на их выполнение. Это значение сравнивалось с диапазонами SLO, а результаты сохранялись в новую таблицу. Точно так же рассчитывалась разница между запланированным и фактическим временем начала задания, чтобы вычислить задержку. Задержки затем делились на два диапазона, как описано выше.
Итак, каждый день мы измеряли SLI и вычисляли SLO по диапазонам.
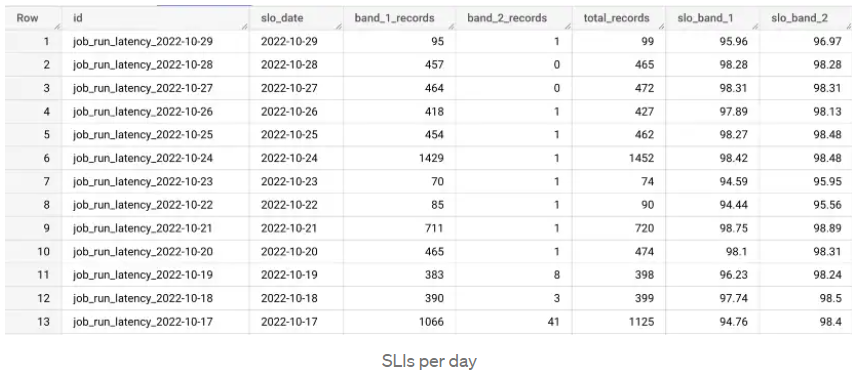
В таблице приводится пример расчёта времени выполнения заданий по дням. В столбце total_records приводится общее число заданий в день, в band_1_records — задания, выполненные не более чем за 15 минут, а в band_2_records — задания, которые заняли от 15 до 30 минут. В столбце slo_band_1 мы видим процент достижения целевого значения для первого SLI, а в slo_band_2 — для второго.
Мы собираем данные за отдельные дни и рассчитываем SLO за месяц.

Это сводная таблица, где в столбцах указаны месяцы, а в строках — SLO. Красная ячейка показывает, что SLO был нарушен для этого диапазона в этом месяце. Глядя на этот дашборд с SLO, мы можем сформулировать Error budget (бюджеты на ошибки).
Error budget — это культура при которой команда перестает выпускать новые функции (кроме тех, которые направлены на повышение надёжности), пока сервис не соответствует SLO).
Когда на дашборде SLO постоянно появляются красные значения, значит что-то идёт не так, и команде инженеров нужно поработать над качеством и надёжностью продукта.

Старт практического курса SRE: data-driven подход к управлению надёжностью систем 28 февраля.
