[Перевод] Визуализация кодовой эволюции

От переводчика:
На этого интересного автора, Адама Торнхила, я набрел при поиске видео с конференции GOTO. Кому данная статья покажется интересной, советую посмотреть его выступление. Я немного заморочился с переводом (благодарен Тане за помощь!), потому что тематика показалась очень своеобразной, не встречал ранее аналогичные работы (буду рад ссылкам в комментариях!). Статья свежая, августа 2016, в оригинале называется Software ®Evolution — Part 1. В тексте идет повествования от первого лица, но имеется в виду автор оригинальной статьи.
Как эволюция кода позволяет понимать большие кодовые базы
Обычно плохой код — это надолго. Он не просто остаётся в конкретном файле, но ещё остаётся там на года, переживая своих создателей (внутри организации) и вызывая недовольство следующего поколения программистов, ответственных за поддержку. Изменения в таком коде являются рискованной деятельностью. Учитывая масштаб нынешних кодовых баз, мы нуждаемся в более эффективных инструментах для выявления подобных частей системы, так чтобы мы могли сделать коррекцию, приложить дополнительные усилия в тестировании или выполнить ревью кода. В этой статье мы используем данные по предыдущему поведению в сфере разработки для того, чтобы получить руководство к указанным решениям.
Вызовы масштаба
Нынешние системы ПО состоят из сотен тысяч или даже миллионов строк кода. Масштаб таких систем делает их почти невозможными для осмысления. В мире существует немного людей, способных держать в голове миллионы строк кода.
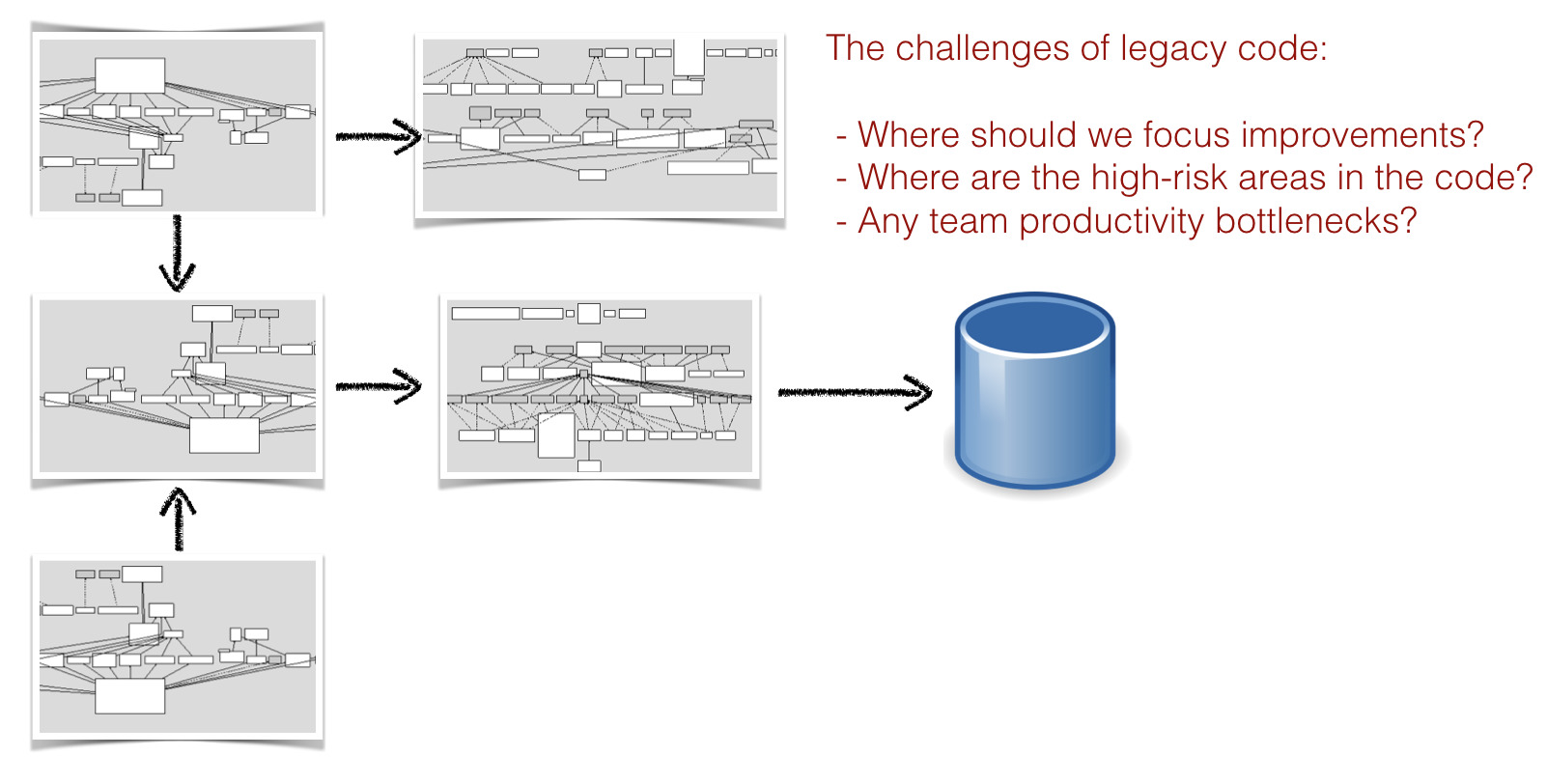
Типичная система состоит из нескольких технологических стеков и сложных подсистем
Также, сегодняшние системы построены на нескольких разных технологиях. Как пример, рассмотрим классическую трёхслойную архитектуру, в которой используется JS на фронтенде, сервисы на Java или Net, а язык запросов SQL для доступа к БД. Если даже это техническое разнообразие само по себе недостаточно сложно, то надо помнить, что большие системы реализуются разработчиками из разных команд. Каждый программист по отдельности видит маленький кусочек кодовой базы. Это значит, что каждый программист по-своему представляет систему, и ни у кого нет в голове целостной картины.
Если мы хотим понять и улучшить большую кодовую базу, наша основная задача — решить эти технические и организационные вызовы. В итоге решение должно удовлетворять требованиям:
- Содержать коллективное знание обо всех участвующих программистах для инвентаризации всех частей кодовой базы, чтобы обратиться к ним позже.
- Представлять независимый от языка подход для оперирования полиглотными кодовыми базами.
- Приоритизировать среди миллионов строк кода те части кода, которые особо важны в смысле продуктивности и рисков.
К сожалению, отчеты типа тех, что выдает CHAOS, делают очевидным то, что большинство проектов не справляются поставленными сроками или бюджетом, и это слабое место организаций. Я думаю, есть простое объяснение для непрерывных провалов в нашей индустрии. Настолько сложно приоритизировать улучшения, потому что большинство времени мы опираемся в наших решениях на оценку системы в ее актуальном состоянии, т.е. на её код. Однако, я считаю, что это неполная информация. А именно, есть два ключевых аспекта, которые мы упускаем:
- Время. Исходя только из самого кода, мы не можем увидеть, как система развивается, и не можем предсказать долгосрочные тренды. В рамках разработки нет способа отделить стабильный код от кода, который мы должны продолжать изменять. Как мы увидим, временное измерение является ключевым для нашей способности приоритизировать улучшения в коде.
- Социальные сведения. Один лишь код сам по себе не может указать, является ли конкретный модуль узким местом в производительности, нуждающимся в скоординированных усилиях нескольких программистов. Т.к. коммуникация и необходимость координации есть движущие силы в затратах индустрии ПО, нам нужна социальная составляющая, чтобы принимать взвешенные решения относительно системы. И возможно, будет удивительным, но эта социальная составляющая находится за пределами менеджмента и при этом так же важна для нашей способности принимать толковые технические решения
Посмотрим, как можно использовать эволюцию ПО себе в помощь.
Используйте системы контроля версий в качестве данных по поведению
Анализ данных популярен, и вездесущее машинное обучение научило нас, как искать паттерны в сложных феноменах. Мне кажется чрезвычайно захватывающим то, что мы лишь недавно стали применять эти техники к себе. Нужно закрыть эту брешь, так что этому будет посвящена вся серия статей. Давайте раскроем, что происходит, когда мы начинаем изучать паттерны нашего собственного поведения (т.е. программистов), для того чтобы лучше понять, как растут наши системы.
Самое лучшее в этом подходе то, что практически все софтверные организации уже имеют все данные в своих системах контроля версий. Мы просто не привыкли мыслить о них в этом ключе. Системы контроля версий являются попросту логом поведения, описывающим то, как разработчик взаимодействует с кодом. Данные контроля версий не только содержат информацию о том, когда и где были внесены правки, но также содержат социальные сведения в виде записи об авторе правок. Давайте обратимся к данным из контроля версий.

На пути к эволюционному представлению о ПО
В качестве ежедневной работы в Empear, я проанализировал сотни различных кодовых баз. Есть некоторые паттерны, которые я встречаю снова и снова, независимо от языка программирования и технологии. Раскрытие этих паттернов поможет нам понять большие кодовые базы.
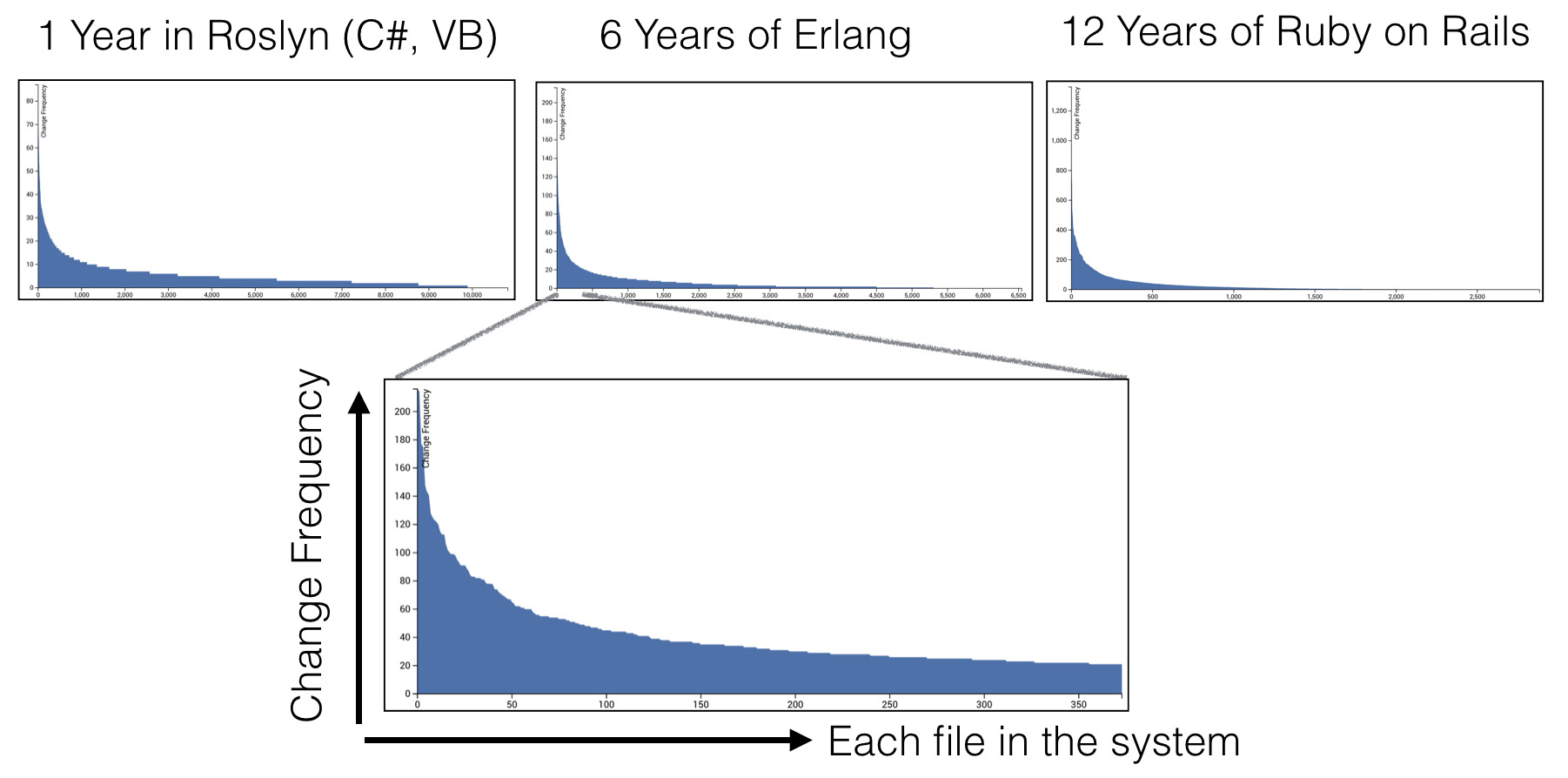
Взгляните на три графика: все они показывают одно и то же. По оси X указаны файлы в системе с сортировкой по частоте изменений (число коммитов, взятое из данные контроля версий). Ось Y показывает число коммитов для каждого файла.
На графиках — данные из трех совершенно разных систем с разными предметными областями, сами кодовые базы различных размеров, разработанные в разных компаниях и с разным сроком жизни. Но все графики показывают одинаковое геометрическое распределение.
Распределения эти говорят, что большинство наших активностей по разработке сосредоточены в относительно маленьких частях общей кодовой базы. Подавляющее большинство всех файлов остаются в «хвосте» распределения, что означает, что они составляют код, который редко или никогда не изменяется.
Наличие такого распределения изменений кода имеет несколько интересных следствий. Прежде всего, дает нам инструмент приоритизировать улучшения и рефакторинг. Рефакторинг сложного кода и высоко рискованный, и дорогой. С помощью нашего понимания как код развивается, мы можем сфокусироваться на тех частях, которые скорее всего окупят наши трудозатраты. Это те части, где мы тратим большинство наших усилий по разработке, как проиллюстрировано ниже.
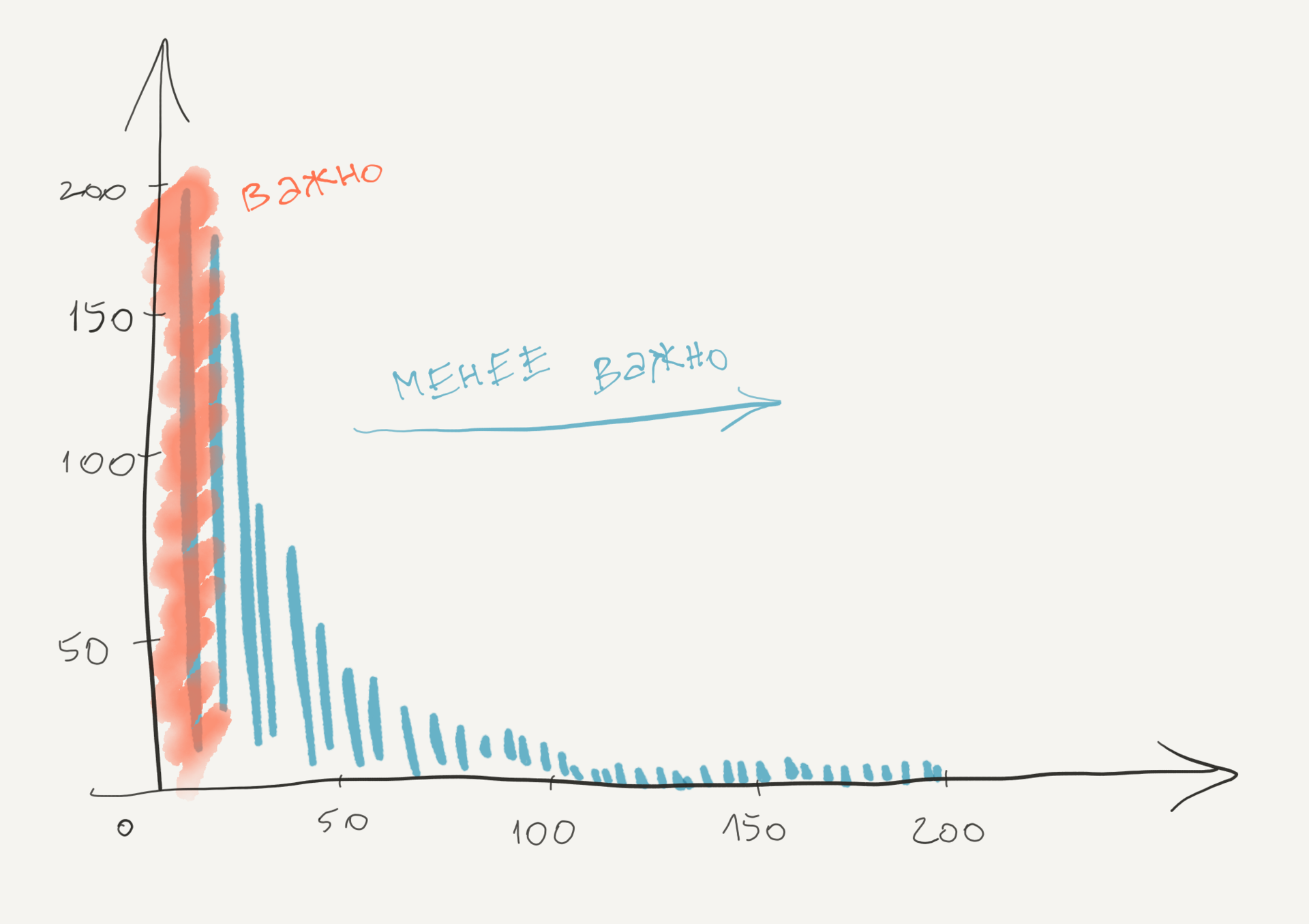
Любые улучшения, которые мы внесем в файлы в красной зоне, с большой вероятностью ведут к выигрышу производительности, т.к. это те самые файлы, с которыми мы работает все время. Также важно находить файлы с высокой частотой изменения с точки зрения качества. Дело в том, что высокая частота изменений коррелирует с повторяющимися проблемами поддержки. На деле, важность метрики изменений в модуль столь высока, что в ситуации предсказании ошибки более продуманные метрики редко предоставляют более высокую ценность.
Однако, несмотря на эти открытия, у нашей модели все еще есть слабое место. Суть в том, что код не одинаков. Например, есть большая разница между тем, чтобы увеличить номер версии в однострочном файле и исправить баг в файле с 5000 строк на C++ с хитрой вложенной логикой условий. Первое из изменений малорискованное и по практическим соображениям может быть проигнорировано, в то время как второй тип изменения нуждается в особом внимании в рамках тестирования и проверки кода. Таким образом, нам надо добавить второе измерение в нашу модель — измерение сложности, чтобы улучшить ее предсказательную силу. Давайте посмотрим, как это сделано.
Независимые от языка метрики для сложности
Было несколько попыток измерить сложность ПО. Наиболее известные подходы: McCabe cyclomatic complexity и Halstead complexity. Основной недостаток этих метрик в том, что они привязаны к языку. Т.е. нам нужно по одной метрике на каждый язык программирования, используемый в системе. Это противоречит нашей цели предоставления независимой от языка метрики для получения целостного видения современных полиглотных кодовых баз.
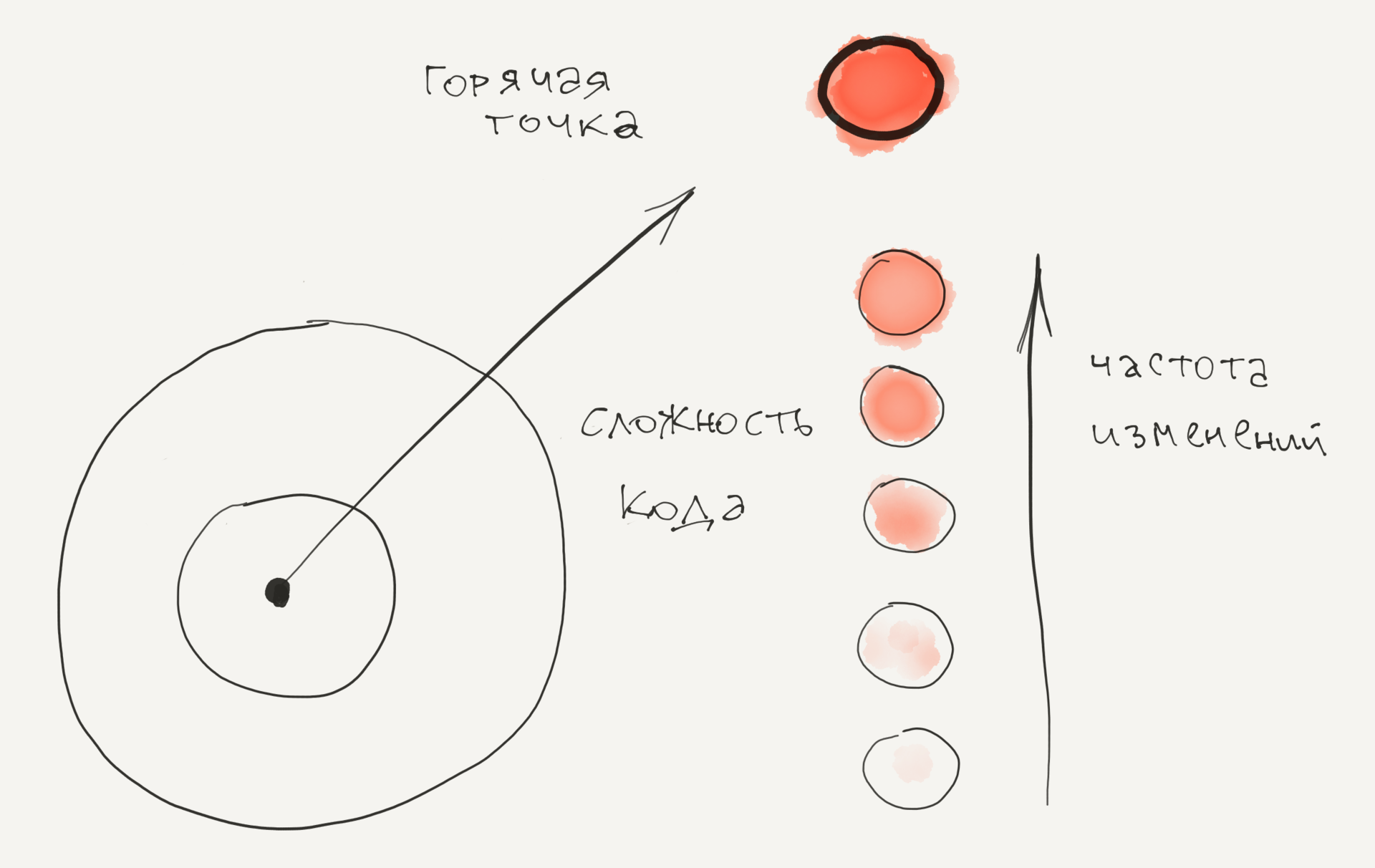
К счастью, есть более простая метрика, которая вполне сгодится: число строк кода. И да, конечно, количество строк кода весьма грубая метрика, но тем не менее имеет хорошую предсказательную силу, наравне с продуманными метрика типа цикломатической сложности. Преимущество использования строк кода состоит в простоте метрики: оно не зависит от языка и вдобавок интуитивно понятно. Будем использовать число строк как замещение для метрики сложности и совместим ее с измерением частоты изменений для указания Горячих Точек в нашей кодовой базе.
Определение высоких рисков модификаций с помощью горячих точек
Горячая точка (Hotspot) — это запутанный код, с которым приходится часто работать. ГТ высчитываются по двум разным источникам: 1) число строк кода как упрощенная метрика для сложности 2) частота изменений для каждого файла, получаемая из истории контроля версий.
Инструмент от компании Empear, Empear tool suite, для анализа ПО выдает анализ ГТ как интерактивную карту, которая позволяет вам обследовать всю кодовую базу. В визуализации ниже каждый файл представлен в виде круга.
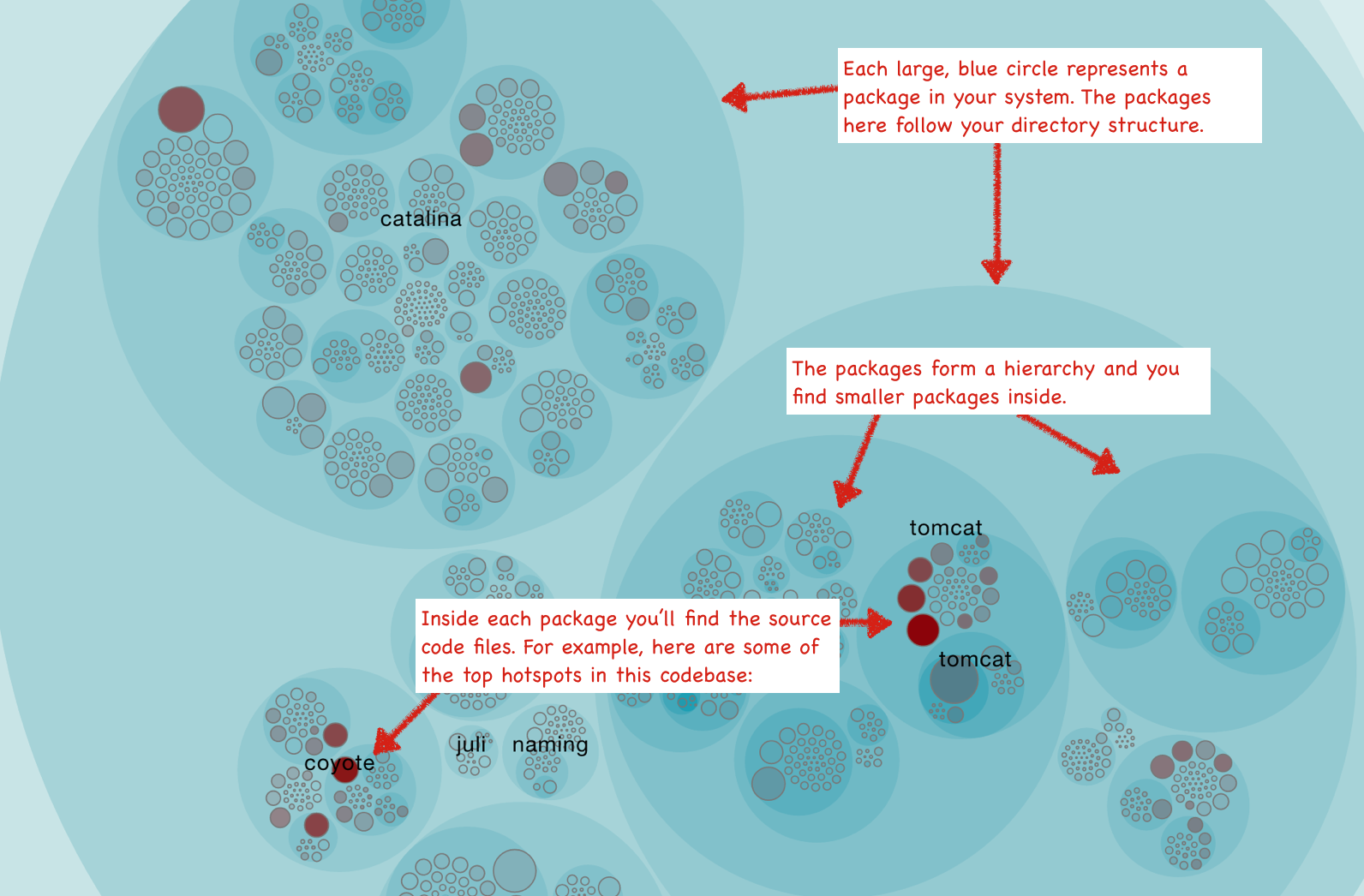
Карта ГТ дает вам возможность просмотреть каждую ГТ в контексте системы. Визуализация также позволяет определить кластеры ГТ, которые указывают на проблемные подсистемы. Конечно, высокой частотой изменений настоящая ГТ не исчерпывается. Мы исследуем эти аспекты позже, сперва пройдемся по некоторым вариантам использования.
Как использовать горячие точки
Анализ ГТ имеет несколько вариантов использования и служит многим специалистам
- Разработчики используют их для определения проблем поддержки. Сложный код, с которым надо часто работать, не приносит счастья. ГТ предоставляют информацию о том, где расположены эти куски. Используйте эту информацию для приоритизации переделок.
- Тех лиды используют ГТ для управления рисками. Изменения в ГТ или расширение ее функциональности новыми фичами несет высокий риск. Анализ ГТ позволяет определить эти места заблаговременно, так что вы можете планировать дополнительное время или выделять дополнительные ресурсы на тестирование.
- ГТ указывают места в коде в качестве кандидатов на ревью. Ревью кода отлично подходит для избавления от дефектов, но одновременно представляет собой дорогой и ручной труд, так что нам бы хотелось быть уверенными, что вложенные усилия хорошо инвестированы (апатия после код ревью — это реальная вещь). В этом случае используйте карту ГТ для определения кандидатов на ревью.
- ГТ входная точка для исследовательских тестов. Карта — прекрасный способ для опытного тестера, чтобы определить части кодовой базы, которые кажутся нестабильными при многочисленной активности разработчиков. Используйте эту информацию чтобы выбрать входную точку и сфокусирвоать области для исследовательских тестов.
Погружение глубже в тренды сложности и машинное обучение
Как только мы определили наши приоритетные ГТ, нам нужно понять, как они развиваются. Знаем ли мы уже достаточно о ГТ в том смысле, чтобы начать улучшать код и уменьшить будущие риски? Являются ли они горячими потому, что становятся со временем все более запутанными участками, или это больше ситуация микро-изменений в стабильном коде?
Чтобы ответить на эти вопросы, нам нужно взглянуть на тренд по времени, см. ниже
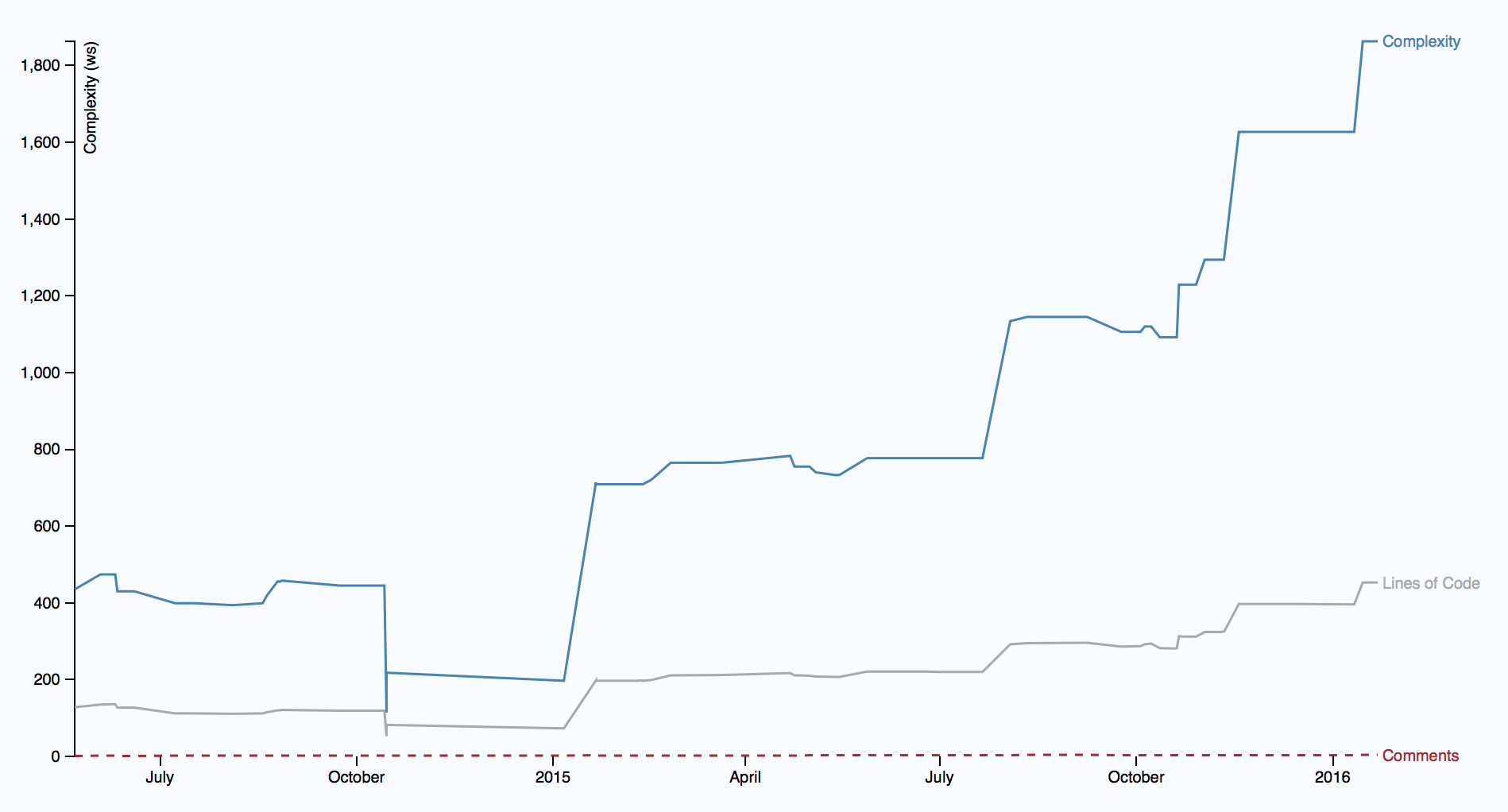
Иллюстрация показывает тренд сложности одной ГТ, начиная с середины 2014, и видно ее развитие за последние полтора года. Получается тревожная картина, т.к. сложность начала быстро расти. Что хуже, сложность растет нелинейно по отношению к количеству нового кода, что говорит о том, что код в ГТ становится сложнее для понимания. Как бонус, вы видите также, что увеличение сложности не сопровождается ростом описания в комментариях. Это выглядит все более как реальная проблема поддержки.
Если вы уделите пристальное внимание, то возможно заметите: метрика тренда сложности отличается от строк кода и сложности. В то время как строки кода служат как эвристика в карте ГТ, метрика становится слишком грубой, когда мы оцениваем конкретный длительный тренд. Например, мы хотим отличать файл, который просто вырос в чистом размере, от случая, когда каждая строка кода становится тяжелее для понимания (зачастую из-за чрезмерного использования логических условий). Оба случая имеют свои собственные проблемы, но второй случай содержит в себе риск повыше. Это значит, нам нужно быть более сосредоточенными на языке при расчете тренда.
Многомерные горячие точки
Итак, я ранее отметил, что настоящие ГТ больше, чем просто высокая степень изменений. Например, мы бы хотели рассмотреть тренд сложности как часть критериев ГТ. Инструмент от компании Empear это делает. Дополнительно в компании применяется алгоритм машинного обучения, обнаруживающий при анализе данных более глубокие паттерны изменений, такие как фрагментация разработки; она выявляет проблемы координации на уровне организации и внутренние связи. Итого, запутанный код, который часто изменяется, является проблемой (реальной ГТ), если:
- ГТ должна быть изменена одновременно с несколькими другими модулями.
- ГТ затрагивает разных разработчиков из разных команд.
Так как Empeat собирает сведения о компании, в т.ч. структуры команды, мы в состоянии обнаружить код, который действительно дорог в поддержке. Каждый раз, когда паттерн изменения в кодовой базе пересекается с организационными ограничениями, вы платите по счетам в виде расходов на координацию и коммуникацию.
Следующая иллюстрация показывает, как этот алгоритм, после запуска на большом числе проектов с открытым кодом, сокращает количество ГТ до небольшого числа от общего размера кода

Как видите из графиков, выделенные ГТ составляют лишь 2–3 процента от общего объема кода. И в то же время, непропорционально большой объем коммитов (11–16% от общего числа), сосредоточен в этих ГТ. Это значит, что любые улучшения кода в приоритетных ГТ являются хорошо потраченным временем.
Горячие точки указывают на участки с высокой плотностью дефектов
С тех пор как мы основали компанию, мы проводим большое количество времени, проверяя и тестируя анализы реальных кодовых баз. Одна из вещей, которые я сделал, было исследование, насколько хорошо обозначенные ГТ предсказывают дефекты. Это было сделано через определение мест, где в коде были совершены корректирующие действия. Затем мы отмотали назад историю контроля версий, измерили ГТ и попробовали найти корреляцию.
Наши результаты показывают сильную корреляцию между приоритетными ГТ и большинством дефектных частей в коде. В целом, приоритетные ГТ составляют лишь малую часть кода, но именно в них находится 25–70 процентов всех выявленных и разрешенных дефектов.
Моя книга Your Code as a Crime Scene глубже рассматривает некоторые исследовательские открытия, которые мы использовали как входную точку при развитии инструмента Empear, а также то, почему и как ГТ работают. Однако, позвольте сформулировать заключение одной строкой.
Существует сильная корреляция между горячими точками, стоимостью поддержки и дефектами ПО. Горячие точки являются отличной входной точкой, если вы хотите найти узкие места производительности в коде, и с Empear tool suite это знание доступно, как никогда раньше!
