[Перевод] Вам нужен чистый код? Используйте правило шести
Все хотят писать чистый код. Этому посвящены целые книги.
Но вам не нужно читать книги, чтобы начать писать более чистый код прямо сейчас. Есть одна «хитрость», которой может научиться любой кодер, она делает код гораздо менее запутанным.
Решение таково:
Каждая строка делает только одно действие
Одна строка, одна задача.
Но не стоит слишком перебарщивать.

«Катя, я вижу строку, которая выполняет два действия. Два действия, Катя!» Не становитесь таким.
Вот в чём заключается основной смысл: для понимания коротких строк кода требуется меньше мыслительных усилий, чем для понимания длинных. Над кодом, который легко читать, легче думать. Программы с короткими строками, в теории, проще поддерживать.
Однако компактный код может быть непонятным. (Слыхали об APL?) И возможность разбиения строки не означает, что это нужно делать обязательно.
В некоторых языках можно присвоить два значения двум переменным в одной строке:
x, y = 2, 7
Можно поместить каждое из присвоений в отдельную строку:
x = 2
y = 7
Но действительно ли это необходимо? Как решить, нужно ли разбивать строку?
Дело не только в длине строки
В начале своей книги The Programmer’s Brain Фелиен Херманс сообщает бесспорный факт: «Неразбериха — это часть программирования».

«А-а-а, что это вообще означает?» Возможно, это означает, что пора сделать перерыв.
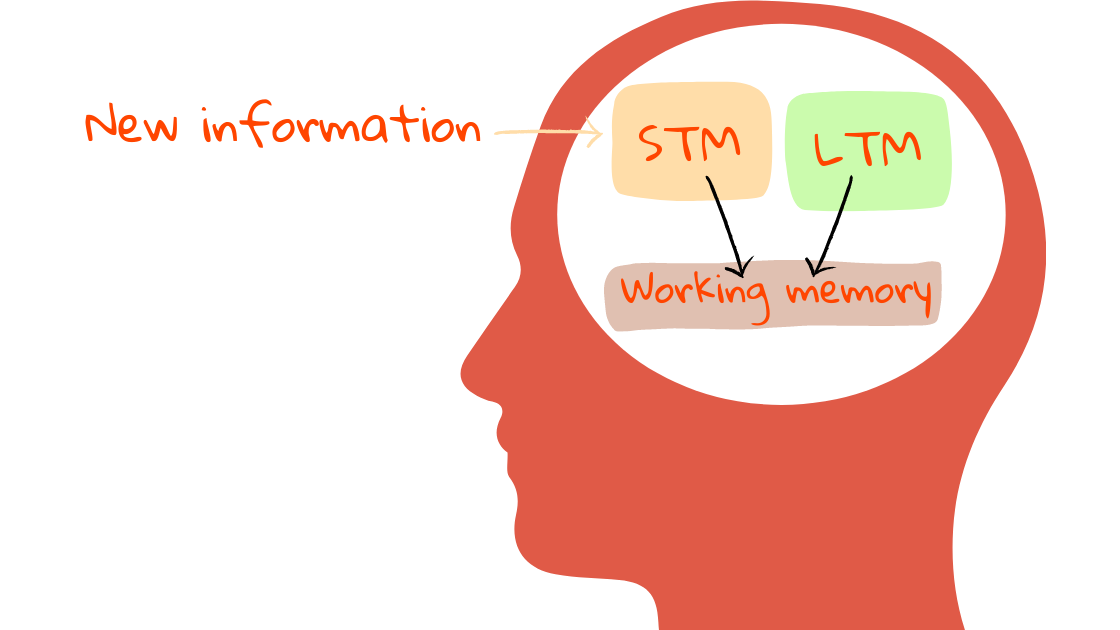
В книге Херманс (которую я крайне вам рекомендую) объясняется, как три функции памяти работают при понимании кода:
- Долговременная память (LTM): хранит информацию для долговременного поиска, например, ключевые слова, синтаксис, часто используемые идиомы и паттерны.
- Кратковременная память (STM): хранит новую информацию для кратковременного поиска (менее 30 секунд!), например, имена переменных и специальные значения.
- Рабочая память (WM): обрабатывает информацию из долговременной и кратковременной памяти, чтобы делать выводы и извлекать новое знание.
Кратковременная и рабочая память малы. И та, и другая могут хранить одновременно примерно 4–6 элементов! Если перегрузить их, то вы сразу же запутаетесь.
Как мозг обрабатывает информацию.
Это даёт нам правило определения того, не является ли строка кода слишком сложной:
Правило шести: строку кода, содержащую больше шести элементов информации, следует упростить.
Вот пример на Python:
map(lambda x: x.split('=')[1], s.split('?')[1].split('&')[-3:])
Вам сложно прочитать эту строку? Мне тоже. И на то есть причина.
Вам нужно знать, что такое map, lambda и .split(). Переменные x и s, строки '=', '?' и '&', индекс [1], и слайс [-3:] занимают место в кратковременной и рабочей памяти. Суммарно это десять элементов! Мозг этого не выдерживает.
Хотя, возможно ваш может.
Если это так, то вы, должно быть, обладаете хорошим опытом.
Ваш мозг разбивает синтаксис вида s.split('?')[1] на «часть строки справа от вопросительного знака». И вы можете воссоздать код на основе информации, хранящейся в долговременной памяти. Но вы всё равно обрабатываете за раз только небольшое количество фрагментов.
Итак, мы можем определить, когда строка кода слишком сложна. Но что дальше?
Если код запутывает, разбивайте его на части
Разбейте его на меньшие части, вот и всё.
Для разбиения кода я использую две стратегии. Я назвал их SIMPLE и MORF.
Стратегия SIMPLE добавляет строки кода для снижения когнитивной нагрузки.

Разбить на несколько строк
Давайте применим SIMPLE к той строке, которую рассматривали выше. Уберём второй аргумент из map() и вставим его в отдельную строку:
query_params = s.split('?')[1].split('&')[-3:]
map(lambda x: x.split('=')[1], query_params)
Возможно, код по-прежнему сложно читать. В первой строке нужно отслеживать семь элементов:
query_paramss.split()'?'[1]'&'[-3:]
Но в каждой строке теперь нужно отслеживать меньше элементов, чем раньше. Вашему мозгу будет проще их обрабатывать.
Применим SIMPLE ещё раз и переместим s.split('?')[1] в новую строку:
url_query_string = s.split('?')[1]
query_params = url_query_string.split('&')[-3:]
map(lambda x: x.split('=')[1], query_params)
Сравните это с исходным однострочным кодом. Какой из них проще обработать?
В стратегии MORF используется другой подход: код группируется в функции.

Вынести и переписать в виде функции.
Вот как выглядит использование MORF для нашей строки:
def query_params(url):
return url.split('?')[1].split('&')[-3:]
map(lambda x: x.split('=')[1], query_params(s))
Также можно сочетать MORF и SIMPLE:
def query_params(url):
query_string = url.split('?')[1]
return query_string.split('&')[-3:]
map(lambda x: x.split('=')[1], query_params(s))
Чтобы почувствовать смысл, вам необязательно понимать код. Мозгу проще обрабатывать каждую строку.
Но есть и бонус!
Если вы знаете, что рабочая и кратковременная память не перегружены, то будете знать, что любое непонимание возникает вследствие отсутствия информации в долговременной памяти.
Иными словами, SIMPLE и MORF не просто помогают писать более чистый код, но и позволяют выявлять пробелы в знаниях, которые можно закрыть при помощи практики.
