[Перевод] Удаление фона с помощью глубокого обучения

Перевод Background removal with deep learning.
На протяжении последних нескольких лет работы в сфере машинного обучения нам хотелось создавать настоящие продукты, основанные на машинном обучении.
Несколько месяцев назад, после прохождения отличного курса Fast.AI, звезды совпали, и у нас появилась такая возможность. Современные достижения в технологиях глубокого обучения позволили осуществить многое из того, что раньше казалось невозможным, появились новые инструменты, которые сделали процесс внедрения более доступным, чем когда-либо.
Мы поставили перед собой следующие цели:
- Улучшить наши навыки работы с глубоким обучением.
- Совершенствовать наши навыки внедрения продуктов, основанных на ИИ.
- Создать полезный продукт с перспективами на рынке.
- Весело провести время (и помочь весело провести время нашим пользователям).
- Обменяться опытом.
Учитывая вышеизложенное, мы изучали идеи, которые:
- Еще никто не смог реализовать (или реализовать должным образом).
- Не будут слишком сложными в планировании и реализации — мы отводили на проект 2–3 месяца работы с нагрузкой в 1 рабочий день в неделю.
- Будут иметь простой и привлекательный пользовательский интерфейс — мы хотели сделать продукт, которым люди будут пользоваться, а не только для демонстрационных целей.
- Будут иметь доступные данные для обучения — как знает любой специалист по машинному обучению, иногда данные дороже алгоритма.
- Будут использовать передовые методы глубокого обучения (которые еще не были выведены на рынок силами Google, Amazon или их друзьями на облачных платформах), но не слишком передовые (чтобы мы могли найти несколько примеров в интернете).
- Будут иметь потенциал для достижения результата, достаточного для вывода продукта на рынок.
Наши ранние предположения заключались в том, чтобы взять на себя какой-то медицинский проект, так как эта сфера нам очень близка, и мы чувствовали (и до сих пор чувствуем), что существует огромное количество тем, подходящих для глубокого обучения. Однако мы поняли, что столкнёмся с проблемами при сборе данных и, возможно, с законностью и регулированием, что противоречило нашему желанию не усложнять задачу самим себе. Поэтому решили придерживаться плана Б — сделать продукт для удаления фона в изображениях.
Удаление фона — задача, которую легко выполнить вручную, или почти вручную (Photoshop, и даже Power Point имеют такие инструменты), если вы используете какой-то «маркер» и технологию обнаружения границ, см. пример. Однако полностью автоматизированное удаление фона — довольно сложная задача, и, насколько нам известно, до сих пор нет продукта, который достиг приемлемых результатов (хотя есть те, кто пытается).
Какой фон мы будем удалять? Этот вопрос оказался важным, поскольку чем более конкретна модель с точки зрения объектов, углов и прочего, тем выше будет качество разделения фона и переднего плана. Когда мы начинали нашу работу, мы мыслили широко: комплексный инструмент для удаления фона, который автоматически идентифицирует передний и задний план в каждом типе изображения. Но после обучения нашей первой модели мы поняли, что лучше сосредоточить наши усилия на определенном наборе изображений. Поэтому мы решили сосредоточиться на селфи и портретах людей.

Удаление фона на фотографии (почти) человека.
Селфи — это изображение:
- с характерным и ориентированным передним планом (один или несколько «человек»), которое гарантирует нам хорошее разделение между объектом (лицо + верхняя часть тела) и фоном,
- а также с постоянным углом и всегда одним и тем же объектом (человеком).
Учитывая эти утверждения, мы занялись исследованиями и внедрением, потратив много часов на обучение, чтобы создать удобный в использовании сервис удаления фона одним кликом.
Основная часть нашей работы заключалась в обучении модели, но мы не могли позволить себе недооценить важность правильного внедрения. Хорошие модели сегментации по-прежнему не столь компактны, как модели классификации изображений (например, SqueezeNet), и мы активно изучали варианты внедрения как на стороне сервера, так и на стороне браузера.
Если вы хотите прочитать подробнее о процессе внедрения нашего продукта, можете ознакомиться с нашими постами о внедрении на стороне сервера и на стороне клиента.
Если вы хотите узнать о модели и процессе её обучения, продолжайте читать здесь.
Семантическая сегментация
При изучении задач глубокого обучения и компьютерного зрения, напоминающих стоявшие перед нами задачи, легко понять, что лучший вариант для нас — это задача семантической сегментации.
Есть и другие стратегии, такие как разделение по глубине, но они показались нам недостаточно зрелыми для наших целей.
Семантическая сегментация — хорошо известная задача компьютерного зрения, одна из трех важнейших, наряду с классификацией и обнаружением объектов. Сегментация, на самом деле, является задачей классификации, в смысле распределения каждого пикселя по классам. В отличие от моделей классификации или обнаружения изображений, модель сегментации действительно демонстрирует некоторое «понимание» изображений, то есть не только говорит, что «на этом изображении есть кошка», но и на уровне пикселей указывает, где эта кошка.
Итак, как работает сегментация? Чтобы лучше разобраться, нам нужно будет изучить некоторые из ранних работ в этой области.
Самая первая идея состояла в том, чтобы адаптировать некоторые из ранних классификационных сетей, таких как VGG и Alexnet. VGG (Visual Geometry Group) была в 2014 году передовой моделью для классификации изображений, и даже сегодня она очень полезна благодаря простой и ясной архитектуре. При изучении ранних слоев VGG можно заметить, что для категоризации присуща высокая активация. Более глубокие слои имеют еще более сильную активацию, тем не менее они ужасны по своей природе из-за повторяющегося пулинга (pooling action). С учетом всего этого было выдвинуто предположение, что для поиска/сегментации объекта может также использоваться обучение методом классификации, с некоторыми изменениями.
Ранние результаты семантической сегментации появились наряду с классификационными алгоритмами. В этом посте вы можете увидеть некоторые грубые результаты сегментации, полученные при использовании VGG:

Результаты более глубоких слоёв:
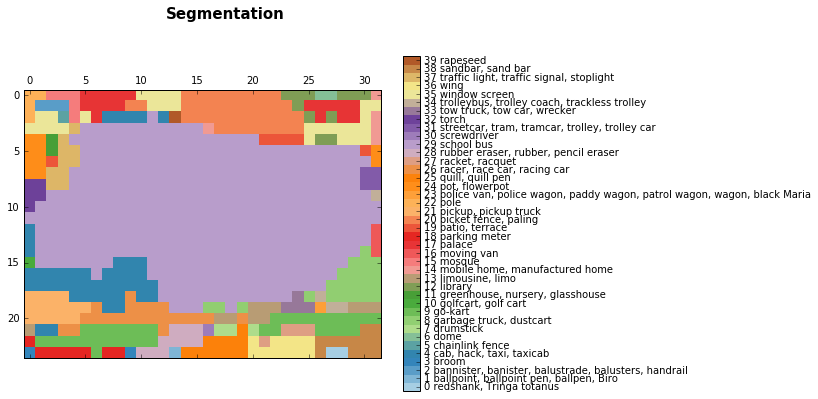
Сегментация изображения автобуса, светло-фиолетовый (29) — это класс школьного автобуса.
После билинейной передискретизации:
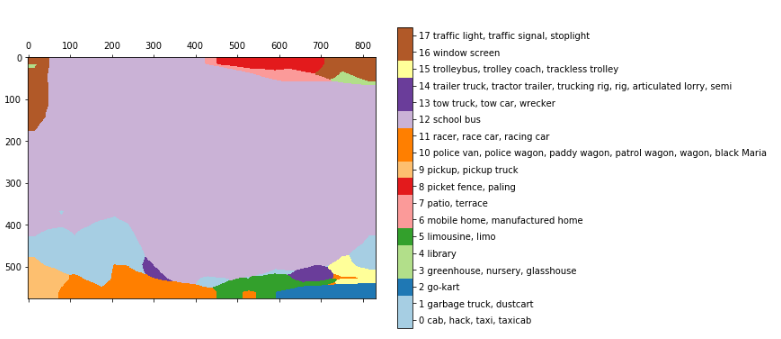
Эти результаты получаются из простого преобразования (или поддержания) полностью связанного слоя в его первоначальную форму, сохраняя его пространственные характеристики и получая полную сверточную нейронную сеть. В приведенном выше примере мы загружаем изображение 768×1024 в VGG и получаем слой 24×32 * 1000. 24×32 — это изображение после пулинга (по 32), а 1000 — это количество image-net классов, из которых мы можем получить вышеприведённое сегментирование.
Чтобы улучшить прогнозирование, исследователи просто использовали билинейный слой с передискретизацией.
В работе FCN авторы улучшили вышеприведённую идею. Они соединяли несколько слоев, чтобы получались более насыщенные интерпретации, которые назвали FCN-32, FCN-16 и FCN-8, в соответствии с частотой передискретизации:
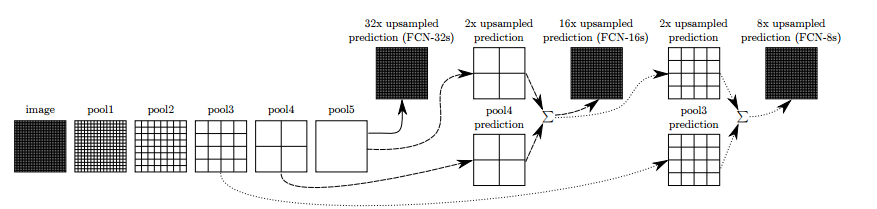
Добавление некоторых пропускных соединений (skip connections) между слоями позволило прогнозировать с кодированием более мелких деталей исходного изображения. Дальнейшее обучение еще больше улучшило результаты.
Этот метод показал себя не так плохо, как можно было подумать, и доказал, что у семантической сегментации с глубоким обучением действительно есть потенциал.

Результаты FCN.
FCN раскрыла концепцию сегментации, и исследователи смогли опробовать для этой задачи разные архитектуры. Основная идея осталась неизменной: использование известных архитектур, передискретизация и пропускные соединения по-прежнему присутствуют в более свежих моделях.
Вы можете прочитать о достижениях в этой области в нескольких хороших постах: здесь, здесь и здесь. Вы также можете заметить, что большинство архитектур имеют схему «кодировщик-декодер».
Возвращаясь к нашему проекту
Проведя некоторые исследования, мы остановились на трех доступных нам моделях: FCN, Unet и Tiramisu — это очень глубокие архитектуры типа «кодировщик-декодер». У нас также были некоторые соображения о методе mask-RCNN, но его реализация оказалась вне сферы нашего проекта.
FCN не казалась актуальной, так как её результаты были не столь хороши, как нам хотелось (даже в качестве отправной точки), но две другие модели показали неплохие результаты: основными достоинствами Unet и Tiramisu с датасетом CamVid были их компактность и скорость. Unet было довольно просто реализовать (мы использовали keras), но и Tiramisu была также вполне реализуема. Чтобы с чего-то начать, мы использовали хорошую реализацию Tiramisu, описанную на последнем уроке курса глубокого обучения Джереми Говарда.
Мы начали обучать эти две модели на некоторых датасетах. Нужно сказать, что после того, как мы впервые попробовали Tiramisu, её результаты имели гораздо больший потенциал для нас, поскольку модель могла захватывать резкие края изображения. Unet же, в свою очередь, оказалась недостаточно хороша, и результаты выглядели немного размытыми.

Размытость результатов работы Unet.
Данные
Определившись с моделью, мы начали искать подходящие датасеты. Данные для сегментации не так распространены, как данные для классификации, или даже для обнаружения. Кроме того, индексировать изображения вручную не представлялось нам возможным. Наиболее популярным датасетом для сегментации были: COCO, включающий в себя около 80 тыс. изображений в 90 категориях, VOC pascal с 11 тыс. изображениями в 20 классах, и более свежий ADE20K.
Мы решили работать с COCO, поскольку он включает в себя гораздо больше изображений класса «человек», который нас интересовал.
Учитывая нашу задачу, мы задумались над тем, будем ли использовать только актуальные для нас изображения или более «общий» датасет. С одной стороны, использование более общего датасета с большим количеством изображений и классов позволит модели справляться с бо̒льшим количеством сценариев и задач. С другой стороны, обучение в течение одной ночи позволяла нам обрабатывать ~ 150 тыс. изображений. Если мы предоставим модели весь датасет COCO, то она увидит каждое изображение дважды (в среднем), так что лучше датасет немного обрезать. Кроме того, наша модель будет лучше заточена под нашу задачу.
Еще один момент, о которой стоит упомянуть: модель Tiramisu была первоначально обучена на датасете CamVid, у которого есть некоторые недостатки, главный из которых — сильное однообразие изображений: фотографии дорог, сделанные из автомобилей. Как вы можете понять, обучение на таком датасете (даже если он содержит людей) не принесло нам пользы, поэтому после недолгих испытаний мы двинулись дальше.

Изображения из датасета CamVid.
Датасет COCO поставляется с довольно простым API, который позволяет нам точно знать, какие объекты находятся на каком изображении (согласно 90 предопределенным классам).
После некоторых экспериментов мы решили разбавить датасет: сначала отфильтровали только изображения с человеком, оставив 40 тысяч картинок. Затем отбросили все изображения с несколькими людьми, оставив только фотографии с 1–2 людьми, поскольку именно для таких ситуаций предназначен наш продукт. Наконец, мы оставили только изображения, на которых человек занимает 20% — 70% площади, удаляя картинки со слишком маленьким человеком или с какими-то непонятными монструозностями (к сожалению, мы смогли удалить не все из них). Наш окончательный датасет состоял из 11 тысяч изображений, которых, как мы чувствовали, было достаточно на этом этапе.

Слева: подходящее изображение. По центру: слишком много участников. Справа: Объект слишком маленький.
Модель Tiramisu
Хотя полное название модели Tiramisu (»100 слоев Тирамису») подразумевает гигантскую модель, на самом деле она довольно экономична и использует всего 9 миллионов параметров. Для сравнения, VGG16 использует более 130 миллионов параметров.
Модель Tiramisu основана на DenseNet, свежей модели классификации изображений, в которой все слои взаимосвязаны. Кроме того, в Tiramisu к слоям передискретизации добавлены пропускные соединения, как в Unet.
Если вы помните, эта архитектура согласуется с идеей, представленной в FCN: использование архитектуры классификации, передискретизации и добавление пропускных соединений для оптимизации.
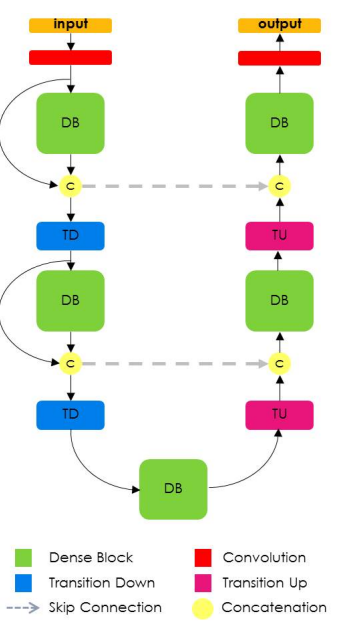
Так выглядит архитектура Tiramisu.
Модель DenseNet можно рассматривать как естественную эволюцию модели Resnet, но вместо того, чтобы «запоминать» каждый слой только до следующего слоя, Densenet запоминает все слои во всей модели. Такие соединения называются highway-соединениями. Это приводит к увеличению количества фильтров, называемому «темпом роста» (growth rate). Tiramisu имеет темп роста 16, то есть с каждым слоем мы добавляем 16 новых фильтров, пока не достигнем слоев из 1072 фильтров. Вы могли ожидать 1600 слоев, потому что это 100-слойная модель Tiramisu, однако слои с передискретизацией отбрасывают некоторые фильтры.
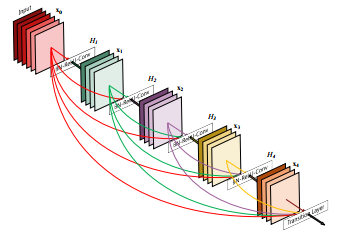
Схема модели Densenet — ранние фильтры собираются в стек на протяжении всей модели.
Обучение
Мы обучали нашу модель в соответствии с графиком, описанным в исходном документе: стандартная потеря кросс-энтропии, оптимизатор RMSProp с коэффициентом обучения 1е-3 и небольшим ослаблением. Мы разделили наши 11 тыс. изображений на три части: 70% для обучения, 20% для проверки и 10% для тестирования. Все изображения, приведенные ниже, взяты из нашего тестового датасета.
Чтобы наш график обучения совпал с приведённым в исходном документе, мы установили период дискретизации на уровне в 500 изображений. Это также позволило нам с каждым улучшением результатов периодически сохранять модель, поскольку мы обучали ее на гораздо большем количестве данных, чем в документе (датасет CamVid, который использовался в этой статье, содержал менее 1 тыс. изображений).
Кроме того, мы обучали нашу модель с использованием только двух классов: фон и человек, а в исходном документе было 12 классов. Сначала мы попытались обучать на некоторых классах датасета COCO, однако заметили, что это не приводит к улучшению результатов.
Проблемы с данными
Некоторые недостатки датасета снизили нашу оценку:
- Животные. Наша модель иногда сегментировала животных. Это, конечно, приводит к низкому IoU (intersection over union, отношение пересечения к объединению). Добавление животных в основной класс или в отдельный, вероятно, повлияло бы на наши результаты.
- Части тела. Поскольку мы программно отфильтровали наш датасет, нам не удалось определить, действительно ли класс человека — это человек, а не часть тела, например, рука или нога. Эти изображения не представляли интереса для нас, но все же возникали здесь и там.

Животное, часть тела, переносной объект. - Переносные объекты. Многие изображения в датасете связаны со спортом. Бейсбольные биты, теннисные ракетки и сноуборды были повсюду. Наша модель была как-то «смущена», не понимая, как это сегментировать. Как и в случае с животными, на наш взгляд, добавление их как часть основного класса (или как отдельный класс) помогло бы улучшить работу модели.

Спортивное изображение с объектом. - Грубые контрольные данные (ground truth). Датасет COCO был аннотирован не попиксельно, а с помощью полигонов. Иногда этого достаточно, но в каких-то случаях контрольные данные слишком «грубые», что, возможно, мешает модели учиться тонкостям.

Само изображение и (очень) грубые контрольные данные.
Результаты
Наши результаты были удовлетворительными, хотя и не идеальными: мы достигли IoU в 84,6 на нашем тестовом датасете, в то время, как современным достижением является величина в 85 IoU. Однако конкретное значение варьируется в зависимости от датасета и класса. Существуют классы, которые по своей природе легче сегментировать, например, дома или дороги, где большинство моделей легко достигают результата в 90 IoU. Более трудными классами являются деревья и люди, на которых большинство моделей достигают результатов около 60 IoU. Поэтому мы помогли нашей сети сосредоточиться на одном классе и ограниченных типах фотографий.
Мы всё еще не чувствуем, что наша работа «готова к выпуску», как хотелось бы, но считаем, что самое время остановиться и обсудить наши достижения, поскольку около 50% фотографий дадут хорошие результаты.
Вот несколько хороших примеров, которые помогут вам почувствовать возможности приложения:

Изображение — контрольные данные — наши результаты (из нашего тестового датасета).
Отладка и журналирование
Отладка является очень важной частью обучения нейронных сетей. В начале нашей работы было очень заманчиво приступить сразу к делу — взять данные и сеть, начать обучение и посмотреть, что получится. Тем не менее, мы выяснили, что чрезвычайно важно отслеживать каждый шаг, исследуя результаты на каждом этапе.
Вот часто встречающиеся сложности и наши способы решения:
- Ранние проблемы. Модель не может начать обучаться. Это может быть связано с какой-то внутренней проблемой или ошибкой предварительной обработки, например, если забыть нормализовать некоторые фрагменты данных. Во всяком случае, простая визуализация результатов может быть очень полезной. Вот хороший пост на эту тему.
- Отладка самой сети. При отсутствии серьёзных проблем начинается обучение с предопределенными потерями и метриками. В сегментировании основным критерием является IoU — отношение пересечения к объединению. Нам потребовалось несколько сессий, чтобы начать использовать для наших моделей IoU в качестве основного критерия (а не потери кросс-энтропии). Другой полезной практикой оказалось отображение прогнозирования нашей модели в каждый период дискретизации. Вот хорошая статья об отладке моделей машинного обучения. Обратите внимание, что IoU не является стандартной метрикой / потерей в keras, но вы можете легко найти ее в интернете, например, здесь. Мы также использовали этот gist для составления графика потерь и некоторого прогнозирования в каждый период дискретизации.
- Контроль версий машинного обучения. При обучении модели есть много параметров, и некоторые из них весьма сложны. Нужно сказать, что мы до сих пор не нашли идеального метода, за исключением того, что воодушевленно фиксировали все наши конфигурации (и автоматически сохраняли лучшие модели с обратным вызовом keras, см. ниже).
- Инструмент отладки. После выполнения всего вышеперечисленного мы смогли анализировать нашу работу на каждом шагу, но не без затруднений. Поэтому наиболее важным шагом было объединение вышеперечисленных шагов и и загрузка данных в Jupyter Notebook (инструмент для создания аналитических отчетов), который позволил нам легко загрузить каждую модель и каждое изображение, а затем быстро изучить результаты. Таким образом, мы смогли видеть различия между моделями и обнаруживать подводные камни и прочие проблемы.
Вот примеры улучшения нашей модели, достигнутые с помощью настройки параметров и дополнительного обучения:

Для сохранения модели с наилучшим результатом IoU (для упрощения работы Keras позволяет делать очень хорошие обратные вызовы):
callbacks = [keras.callbacks.ModelCheckpoint(hist_model, verbose=1,save_best_only =True, monitor= ’val_IOU_calc_loss’), plot_losses]
В дополнение к обычной отладке ошибок кода мы заметили, что ошибки модели «предсказуемы». Например, «отрезание» частей тела, которые не засчитываются как тело, «зазоры» на больших сегментах, излишние продолжения частей тела, плохое освещение, низкое качество и множество деталей. Некоторые из этих ошибок обходились путем добавления специфических изображений из разных датасетов, а для некоторых решения пока найти не удалось. Чтобы улучшить результаты в следующей версии модели, мы будем использовать аугментацию для «сложных» для нашей модели изображений.
Выше мы уже упоминали об этом (в разделе о проблемах датасета), но теперь рассмотрим некоторые из трудностей подробнее:
- Одежда. Очень темная или очень светлая одежда иногда интерпретируется как фон.
- «Зазоры». Результаты, хорошие во всём остальном, иногда имели в себе зазоры.

Одежда и зазоры. - Освещение. В изображениях часто встречаются плохое освещение и темнота, однако не в датасете COCO. Моделям вообще трудно работать с такими картинками, и наша модель никак не была подготовлена к таким сложным для обработки изображениям. Можно попробовать решить это с помощью добавления большего количества данных, а также с помощью аугментации данных. А пока что лучше не испытывать наше приложение ночью :)

Пример плохого освещения.
Варианты дальнейшего улучшения
Продолжение обучения
Наши результаты были получены после примерно 300 циклов дискретизации над нашими тестовыми данными. После этого началось переобучение (over-fitting). Мы достигли таких результатов очень близко к релизу, поэтому у нас не было возможности применить стандартную практику аугментации данных.
Мы обучали модель после того, как изменили размеры изображений на 224×224. Также должно улучшить результаты дальнейшее обучение с большим количеством данных и более крупными изображениями (исходный размер изображений COCO составляет около 600×1000).
CRF и другие улучшения
На некоторых этапах мы заметили, что наши результаты немного «шумны» по краям. Модель, которая может справиться с этим, — это CRF (Conditional random fields). В этом посте автор приводит упрощённый пример использования CRF.
Однако нам от неё было мало толка, возможно, потому что эта модель обычно полезна, когда результаты более грубые.
Матирование
Даже с нашими текущими результатами сегментация не идеальна. Волосы, тонкая одежда, ветви деревьев и другие мелкие предметы никогда не будут сегментированы идеально, хотя бы потому, что сегментация контрольных данных не содержит этих нюансов. Задача разделения такой деликатной сегментации называется матированием, и она также выявляет другие сложности. Вот пример современного матирования, опубликованного в начале этого года на конференции NVIDIA.
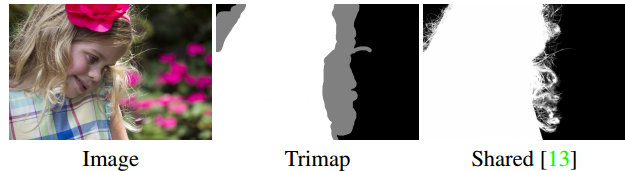
Пример матирования — входные данные включают в себя trimap.
Задача матирования отличается от других задач, связанных с обработкой изображений, поскольку входные данные включают в себя не только изображение, но и trimap — контур краев изображений, что делает матирование проблемой «полуконтролируемого» обучения.
Мы немного экспериментировали с матированием, используя нашу сегментацию в качестве trimap, однако не достигли значительных результатов.
Еще одной проблемой было отсутствие подходящего для обучения датасета.
Итоги
Как было сказано в начале, наша цель состояла в том, чтобы создать с помощью глубокого обучения значимый продукт. Как вы можете видеть в постах Алона, внедрение становится всё проще и быстрее. С другой стороны, с обучением модели дела обстоят хуже — обучение, особенно когда оно проводится за одну ночь, требует тщательного планирования, отладки и записи результатов.
Непросто балансировать между исследованиями и попытками сделать что-то новое, а также рутинным обучением и совершенствованием. Поскольку мы используем глубокое обучение, у нас всегда есть ощущение, что уже не за горами более совершенная модель, или именно такая модель, какая нам нужна, и еще один поиск в Google, или еще одна прочитанная статья приведут нас к желаемому. Но на практике наши фактические улучшения стали следствием того, что мы «выжимали» всё больше и больше из нашей исходной модели. И мы всё еще чувствуем, что можем выжать гораздо больше.
Нам было очень весело заниматься этой работой, которая несколько месяцев назад казалась научной фантастикой.
greenScreen.AI
