[Перевод] Transformer в картинках
В прошлой статье мы рассматривали механизм внимания (attention) — чрезвычайно распространенный метод в современных моделях глубокого обучения, позволяющий улучшить показатели эффективности приложений нейронного машинного перевода. В данной статье мы рассмотрим Трансформер (Transformer) — модель, которая использует механизм внимания для повышения скорости обучения. Более того, для ряда задач Трансформеры превосходят модель нейронного машинного перевода от Google. Однако самое большое преимущество Трансформеров заключается в их высокой эффективности в условиях параллелизации (parallelization). Даже Google Cloud рекомендует использовать Трансформер в качестве модели при работе на Cloud TPU. Попробуем разобраться, из чего состоит модель и какие функции выполняет.
Впервые модель Трансформера была предложена в статье Attention is All You Need. Реализация на TensorFlow доступна как часть пакета Tensor2Tensor, кроме того, группа NLP-исследователей из Гарварда создали гид-аннотацию статьи с реализацией на PyTorch. В данном же руководстве мы попробуем максимально просто и последовательно изложить основные идеи и понятия, что, надеемся, поможет людям, не обладающим глубоким знанием предметной области, понять данную модель.
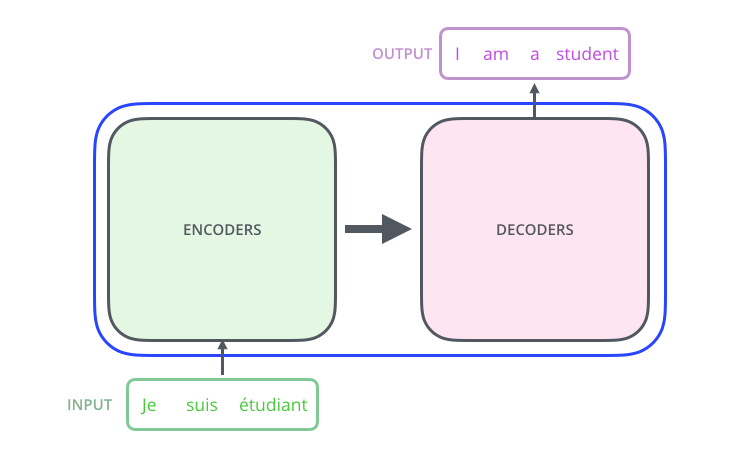
Посмотрим на модель как на некий черный ящик. В приложениях машинного перевода он принимает на вход предложение на одном языке и выводит предложение на другом.

Рассмотрев этого Оптимуса Прайма чуть ближе, мы увидим, что внутри он состоит из кодирующего компонента, декодирующего компонента и связи между ними.
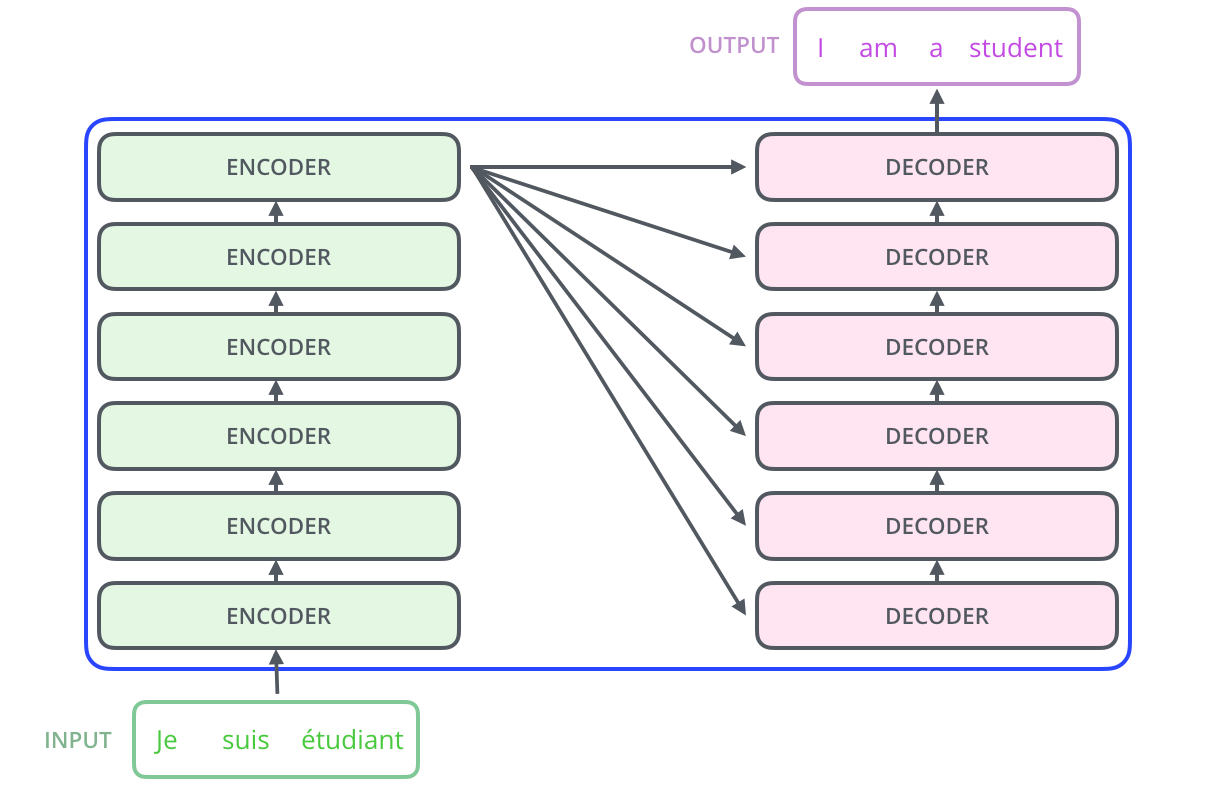
Кодирующий компонент — это стек энкодеров; в иллюстрации ниже мы изобразили 6 энкодеров, расположенных друг над другом (в числе 6 нет ничего магического, можно экспериментировать и с любым другим числом). Декодирующий компонент — это стек декодеров, представленных в том же количестве.
Все энкодеры идентичны по структуре, хотя и имеют разные веса. Каждый можно разделить на два подслоя:
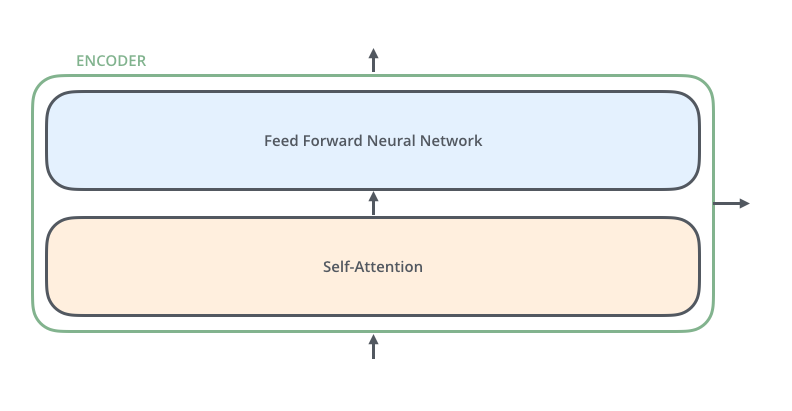
Входная последовательность, поступающая в энкодер, сначала проходит через слой внутреннего внимания (self-attention), помогающий энкодеру посмотреть на другие слова во входящем предложении во время кодирования конкретного слова. Мы рассмотрим этот механизм далее в статье.
Выход слоя внутреннего внимания отправляется в нейронную сеть прямого распространения (feed-forward neural network). Точно такая же сеть независимо применяется для каждого слова в предложении.
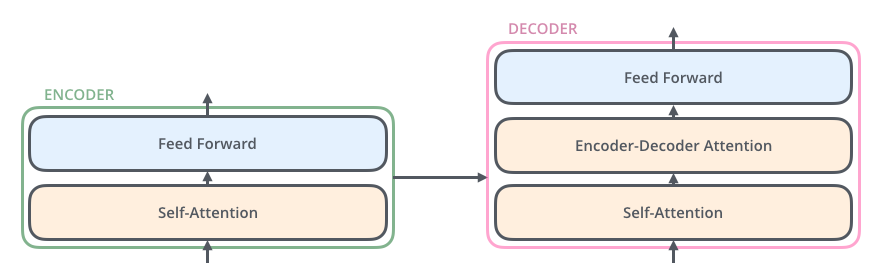
Декодер также содержит два этих слоя, но между ними есть слой внимания, который помогает декодеру фокусироваться на релевантных частях входящего предложения (это схоже с тем, как механизм внимания организован в моделях seq2seq).
Теперь, когда мы увидели основные компоненты модели, посмотрим на различные векторы/тензоры, и как они передаются от компонента к компоненту, преобразуя входную последовательность обученной модели в выходную.
Как и в случае любого NLP-приложения, мы начинаем с того, что преобразуем слово в вектор, используя алгоритм эмбеддингов слов (word embeddings).

Каждое слово преобразовывается в вектор размерностью 512. Мы будем изображать эти векторы с помощью простых квадратиков.
Эмбеддинги применяются только в самом нижнем энкодере. На уровне абстракции, общей для всех энкодеров, происходит следующее: энкодеры получают набор векторов размерностью 512 (для самого нижнего энкодера это будут эмбеддинги слов, для других — выходные вектора нижестоящих энкодеров). Размер этого набора векторов является гиперпараметром, который мы можем устанавливать, и, по сути, равен длине самого длинного предложения в обучающем корпусе.
После того как слова входящего предложения преобразовались в эмбеддинги, каждый из них в отдельности проходит через два слоя энкодера.
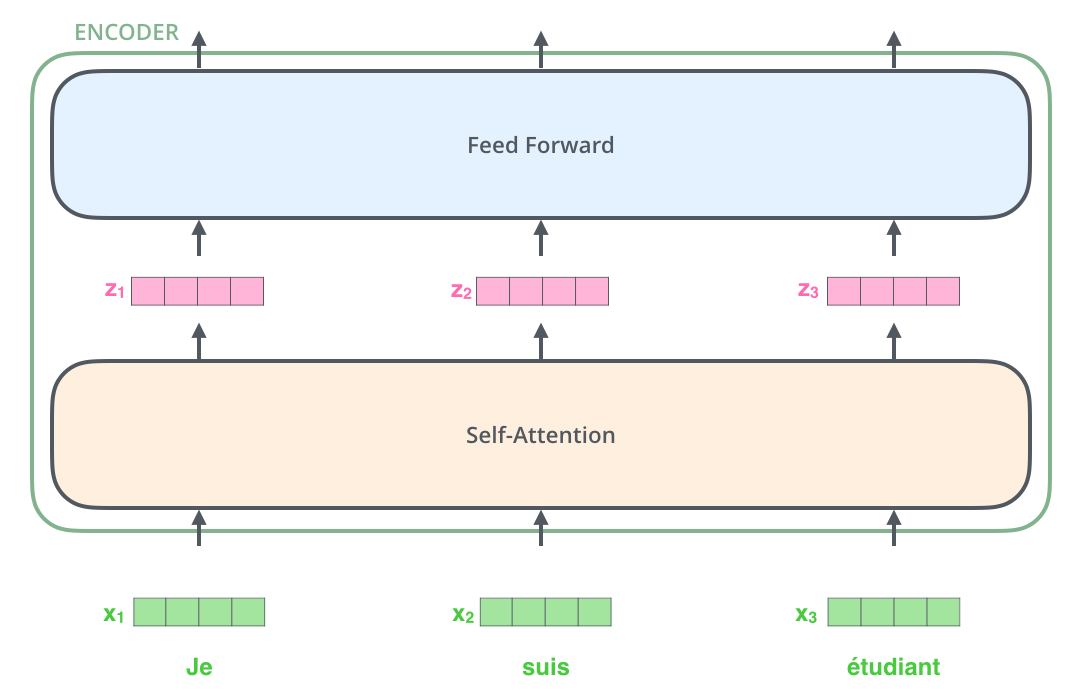
Здесь изображена одна из основных особенностей Трансформера: каждое слово идет по своей собственной траектории в энкодере. И, хотя существуют зависимости между этими траекториями в слое внутреннего внимания, в слое сети прямого распространения таких зависимостей нет, что позволяет различным траекториям выполняться параллельно во время прохождения через этот слой.
Далее мы рассмотрим, что происходит в каждом подслое энкодера на примере более короткого предложения.
Как мы уже упоминали, энкодер получает на вход и обрабатывает набор векторов, проводя их через слой внутреннего внимания и далее — через нейронную сеть прямого распространения, пока, наконец, не передает свой выход следующему энкодеру.
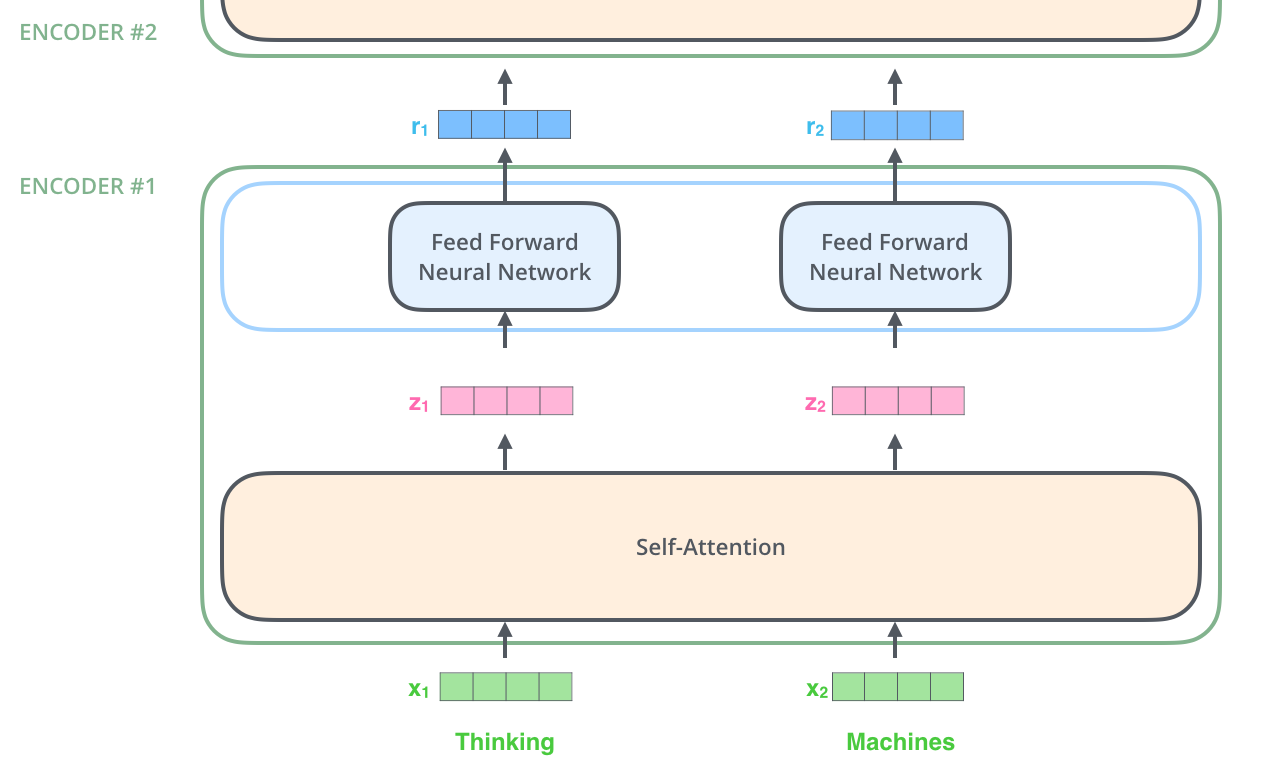
Слова в каждой из позиций проходят через слой внутреннего внимания. Далее каждое из них переходит в отдельную, но абсолютно идентичную нейронную сеть прямого распространения.
Не подумайте, что понятие «внутреннее внимание» употребляется здесь как что-то, что все обязательно должны знать. Сам автор статьи не был знаком с этим термином вплоть до того, как прочитал «Attention is All You Need». Давайте поясним, как это работает.
Пусть следующее предложение — это входящее предложение, которое мы хотим перевести:
«The animal didn’t cross the street because it was too tired»
К чему относится «it» в этом предложении? К улице (street) или к животному (animal)? Простой вопрос для человека становится целой проблемой для алгоритма.
Когда модель обрабатывает слово «it», слой внутреннего внимания помогает понять, что «it» относится к «animal».
По мере того как модель обрабатывает каждое слово (каждую позицию во входной последовательности), внутреннее внимание позволяет модели взглянуть на другие позиции входной последовательности и найти подсказку, помогающую лучше закодировать данное слово.
Если вы знакомы с рекуррентными нейронными сетями (RNN), вспомните, как сохранение скрытого состояния в RNN позволяет включать представление предыдущих слов/векторов, которые уже были обработаны, в текущее обрабатываемое слово. Механизм внутреннего внимания — это метод, который Трансформер использует для того, чтобы смоделировать «понимание» других релевантных слов при обработке конкретного слова.

Во время кодирования «it» в энкодере #5 (верхний энкодер в стеке), часть механизма внимания фокусируется на «The animal» и использует фрагмент его представления для кодирования «it».
Обязательно посмотрите ноутбук по Tensor2Tensor, в котором можно скачать модель Трансформера и изучить ее, используя данную интерактивную визуализацию.
Для начала посмотрим, как вычисляется внутреннее внимание на примере векторов, а далее перейдем к матрицам, с использованием которых данный механизм на самом деле реализован.
Первый этап в вычислении внутреннего внимания — это создать три вектора из каждого входящего вектора (в нашем случае — эмбеддинга каждого слова): вектор запроса (Query vector), вектор ключа (Key vector) и вектор значения (Value vector). Эти векторы создаются с помощью перемножения эмбеддинга на три матрицы, которые мы обучили во время процесса обучения.
Заметим, что эти новые векторы меньше в размере, чем векторы эмбеддингов. Их размерность составляет 64, в то время как эмбеддинги и входящие/выходные векторы энкодера имеют размерность 512. Они не обязаны быть меньше, но в нашем случае выбор данной архитектуры модели обусловлен желанием сделать вычисления в слое множественного внимания (multi-head attention) более стабильными.
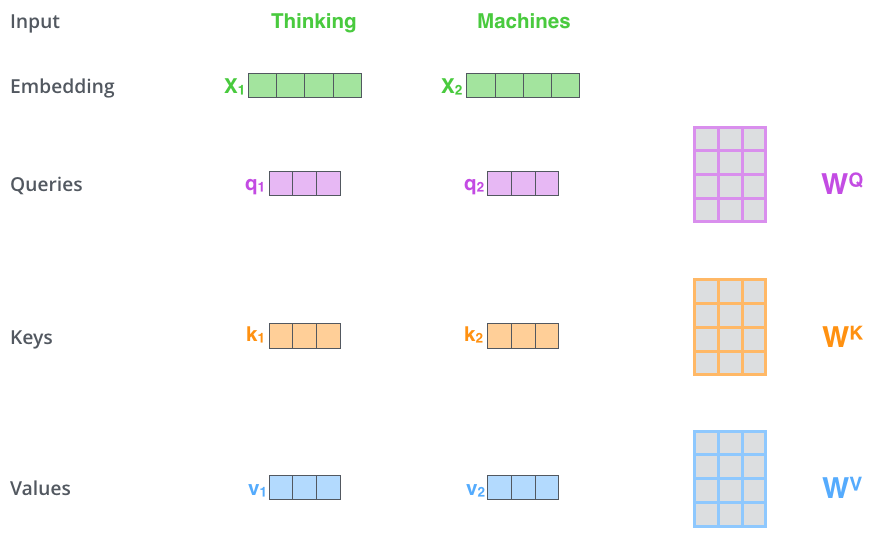
Умножение x1 на матрицу весов WQ производит q1, вектор «запроса», относящийся к этому слову. В итоге мы создаем проекции «запроса», «ключа» и «значения» для каждого слова во входящем предложении.
Что представляют собой векторы «запроса», «ключа» и «значения»?
Это абстракции, которые оказываются весьма полезны для понимания и вычисления внимания. Прочитав ниже, как вычисляется внимание, вы будете знать практически все, что вам нужно о роли этих векторов в рассматриваемой нами модели.
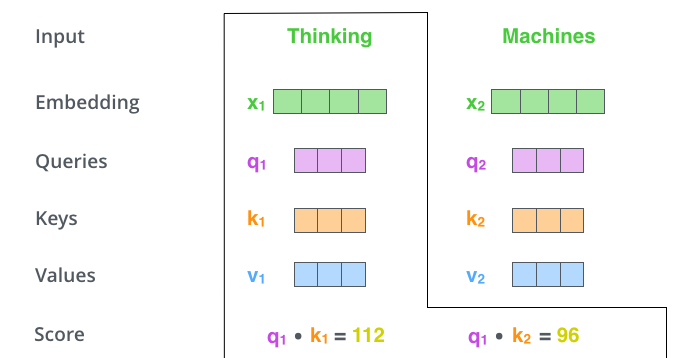
Второй этап вычисления внутреннего внимания — получение коэффициента (score). Допустим, мы подсчитываем внутреннее внимание для первого слова в нашем примере — «Thinking». Нам нужно оценить каждое слово во входящем предложении по отношению к данному слову. Коэффициент определяет, насколько нужно сфокусироваться на других частях входящего предложения во время кодирования слова в конкретной позиции.
Коэффициент подсчитывается с помощью скалярного произведения вектора запроса и вектора ключа соответствующего слова. Таким образом, если мы вычисляем внутреннее внимание для слова в позиции #1, первый коэффициент будет скалярным произведением q1 и k1, второй — скалярным произведением q1 и k2.
Третий и четвертый этапы — разделить эти коэффициенты на 8 (квадратный корень размерности векторов ключа, используемой в статье — 64; данное значение обеспечивает более стабильные градиенты и используется по умолчанию, но возможны также и другие значения), а затем пропустить результат через функцию софтмакс (softmax). Данная функция нормализует коэффициенты так, чтобы они были положительными и в сумме давали 1.
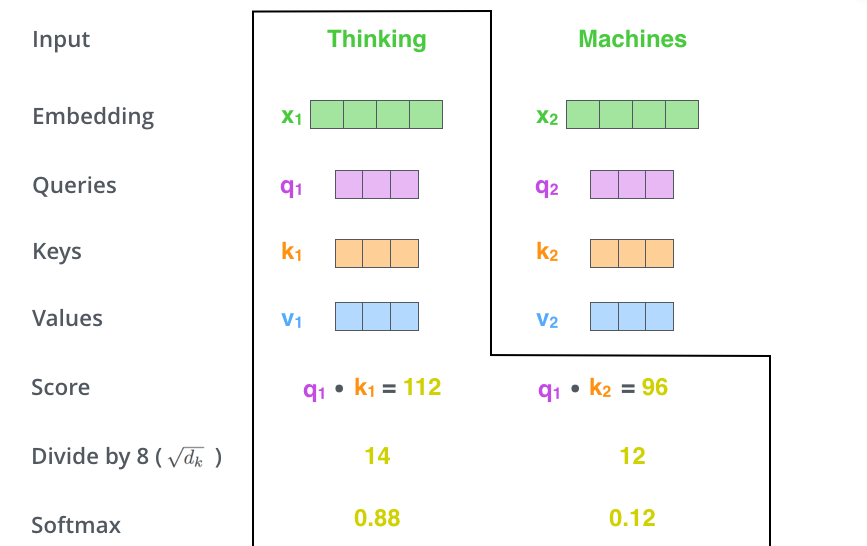
Полученный софтмакс-коэффициент (softmax score) определяет, в какой мере каждое из слов предложения будет выражено в определенной позиции. Очевидно, что слово в своей позиции получит наибольший софтмакс-коэффициент, но иногда полезно учитывать и другое слово, релевантное к рассматриваемому.
Пятый этап — умножить каждый вектор значения на софтмакс-коэффициент (перед их сложением). Интуиция здесь следующая: нужно держать без изменений значения слов, на которых мы фокусируемся, и отвести на второй план нерелевантные слова (умножив их на небольшие значения, например, 0.001).
Шестой этап — сложить взвешенные векторы значения. Это и будет представлять собой выход слоя внутреннего внимания в данной позиции (для первого слова).
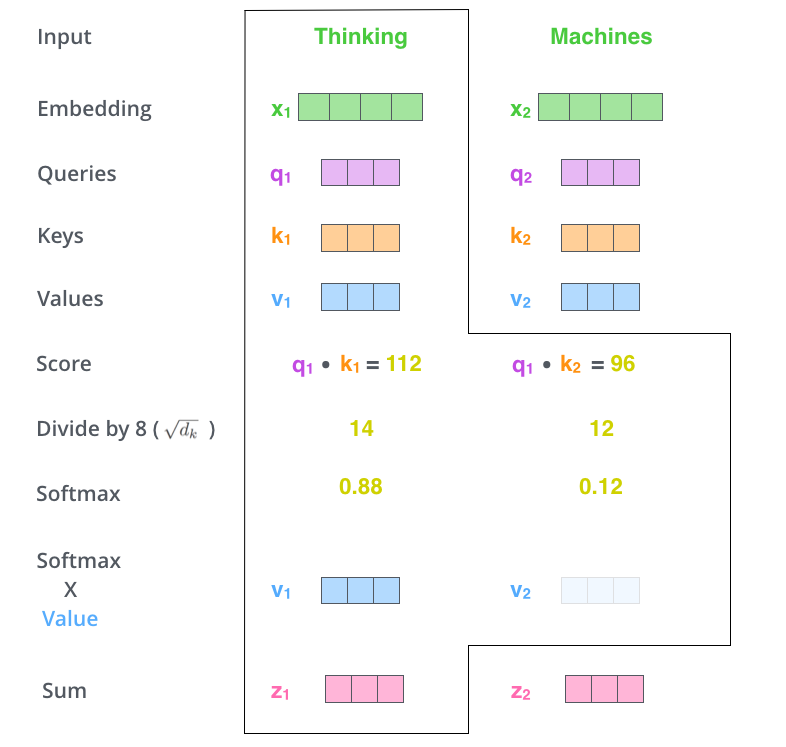
На этом завершается вычисление внутреннего внимания. В результате мы получаем вектор, который можем передавать дальше в нейронную сеть прямого распространения. В настоящих реализациях, однако, эти вычисления делаются в матричной форме для более быстрой обработки. Поэтому, посмотрев на алгоритм вычислений на уровне слов, перейдем к матричным вычислениям.
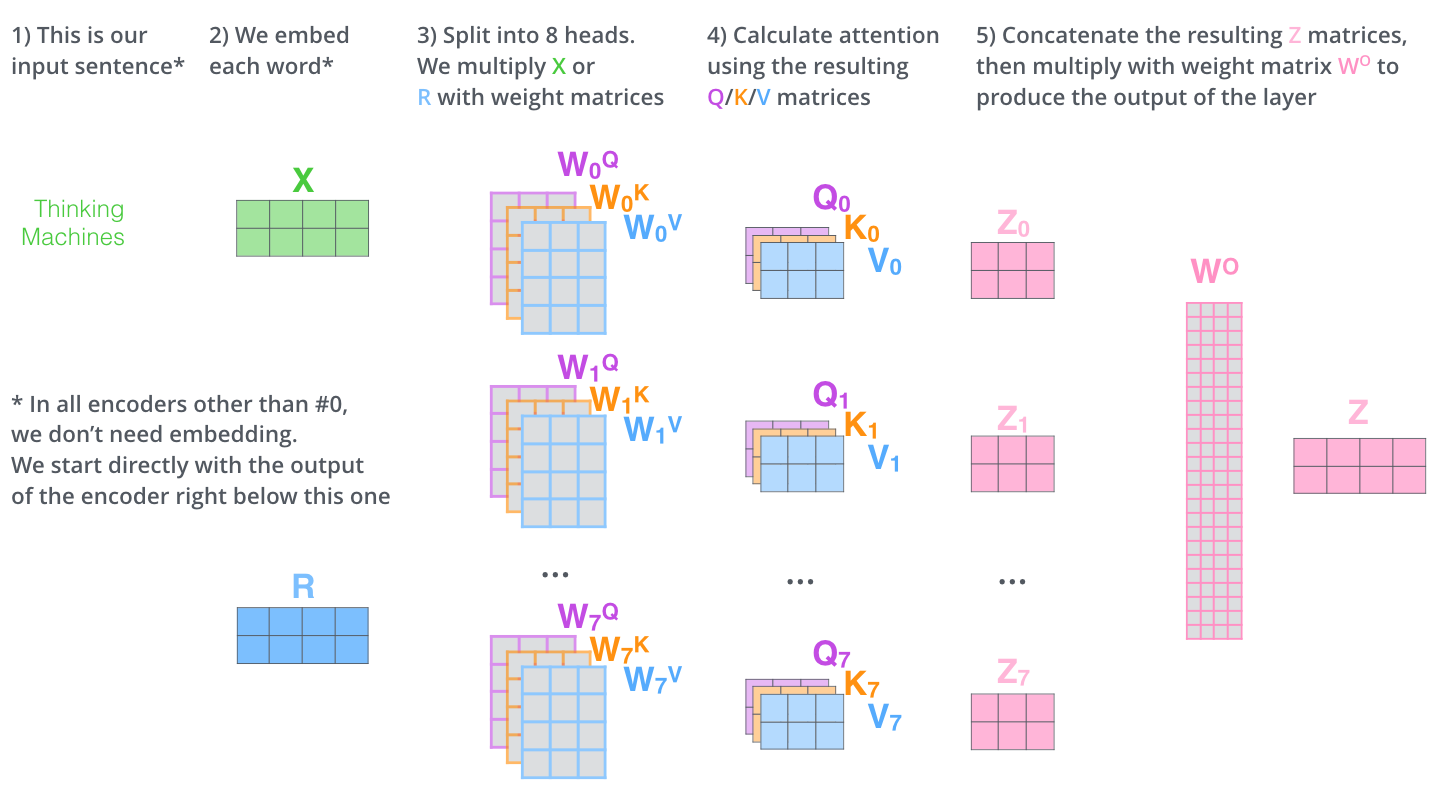
Первый этап — вычислить матрицы запроса, ключа и значения. Это делается с помощью формирования из эмбеддингов матрицы X и ее умножения на матрицы весов, которые мы обучили (WQ, WK, WV).

Каждая строка в матрице Х соответствует слову во входящем предложении. Мы снова видим разницу в размерах векторов эмбеддингов (512, или 4 квадратика на рисунке) и векторов q/k/v (64, или 3 квадратика).
Наконец, поскольку мы имеем дело с матрицами, мы можем сжать этапы 2–6 в одну формулу для вычисления выхода слоя внутреннего внимания.
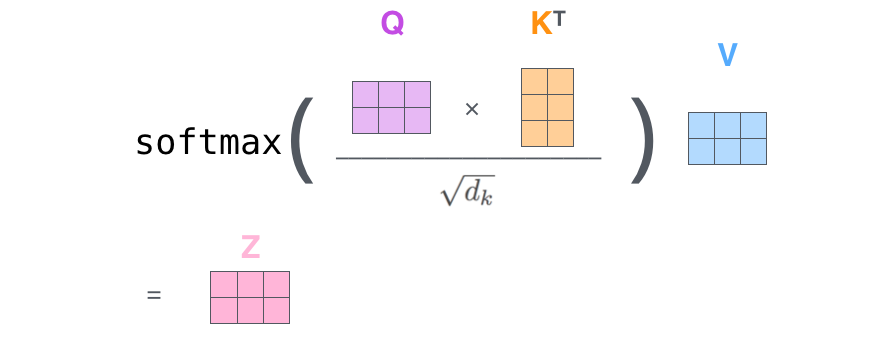
Вычисление внутреннего внимания в матричной форме.
Далее в статье внутреннее внимание совершенствуется с помощью добавления механизма, называющегося множественным вниманием (multi-head attention). Данная техника улучшает производительность слоя внутреннего внимания за счет следующих аспектов:
- Повышается способность модели фокусироваться на разных позициях. Да, в примере выше, z1 содержит немного от всех других кодировок, но он не может доминировать над самим словом. В случае с переводом предложения вроде «The animal didn«t cross the street because it was too tired», мы хотим знать, к какому слову относится «it».
- Слой внимания снабжается множеством «подпространств представлений» (representation subspaces). Как мы увидим далее, с помощью множественного внимания у нас есть не один, а множество наборов матриц запроса/ключа/значения (Трансформер использует 8 «голов» внимания, так что в итоге у нас получается 8 наборов для каждого энкодера/декодера). Каждый из этих наборов создается случайным образом. Далее после обучения каждый набор используется для отображения входящих эмбеддингов (или векторов с нижестоящих энкодеров/декодеров) в разных подпространствах представлений.
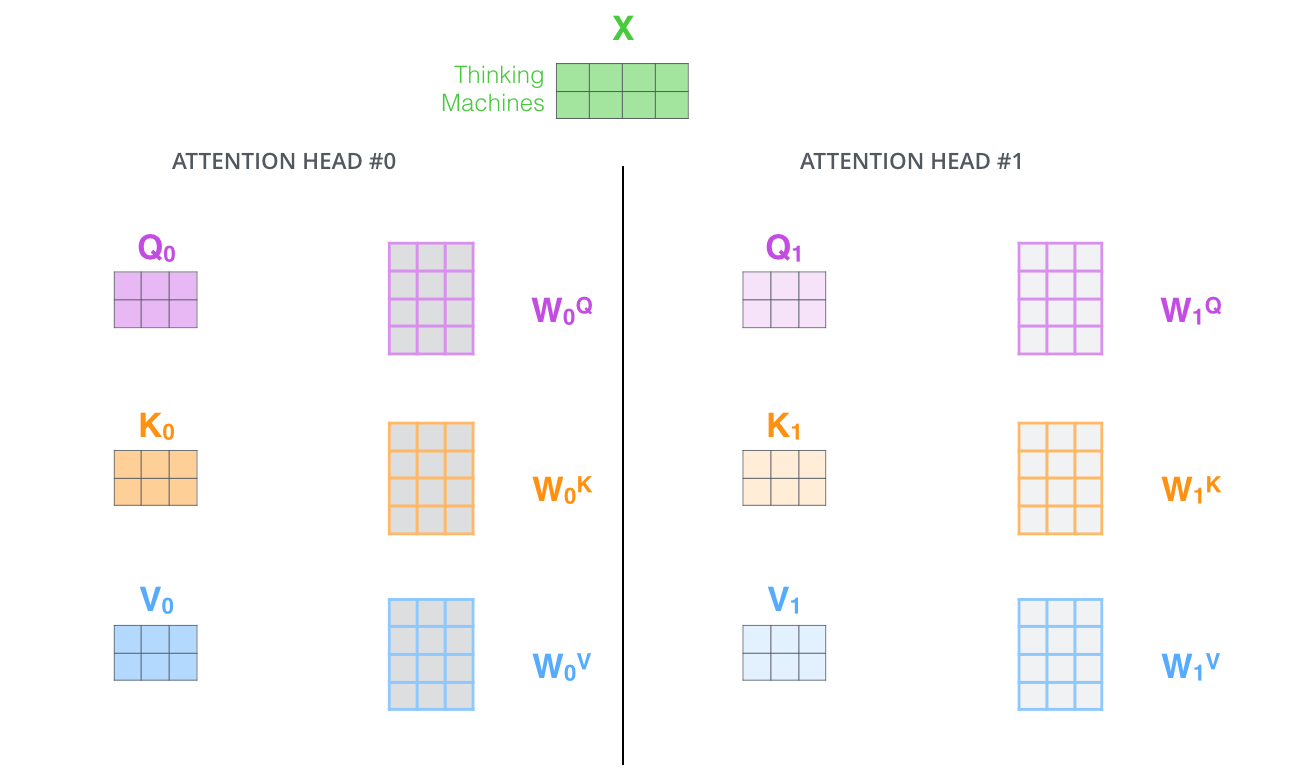
В случае множественного внимания, мы располагаем отдельными WQ/WK/WV матрицами весов для каждой «головы», что в результате дает разные Q/K/V матрицы. Как мы делали ранее, умножаем Х на WQ/WK/WV матрицы для получения Q/K/V матриц.
Сделав те же вычисления внутреннего внимания, что мы описали выше, 8 раз с разными матрицами весов, в результате получим 8 разных Z матриц.
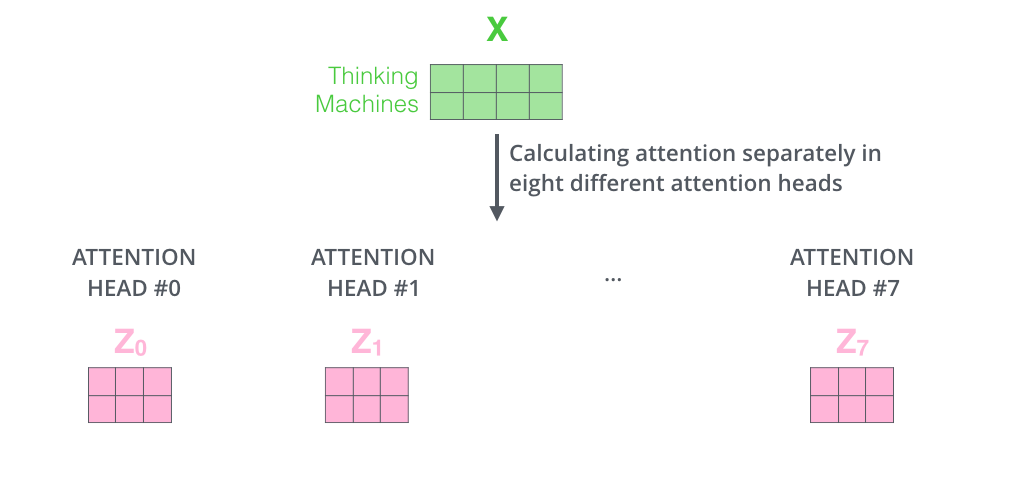
Это бросает нам определенный вызов. Слой сети прямого распространения не ожидает, что к нему поступит 8 матриц — он ждет всего одну (вектор для каждого слова), в которую нам и необходимо сжать полученные Z матрицы.
Как это сделать? Конкатенировать и затем умножить их на дополнительные веса матрицы WO.
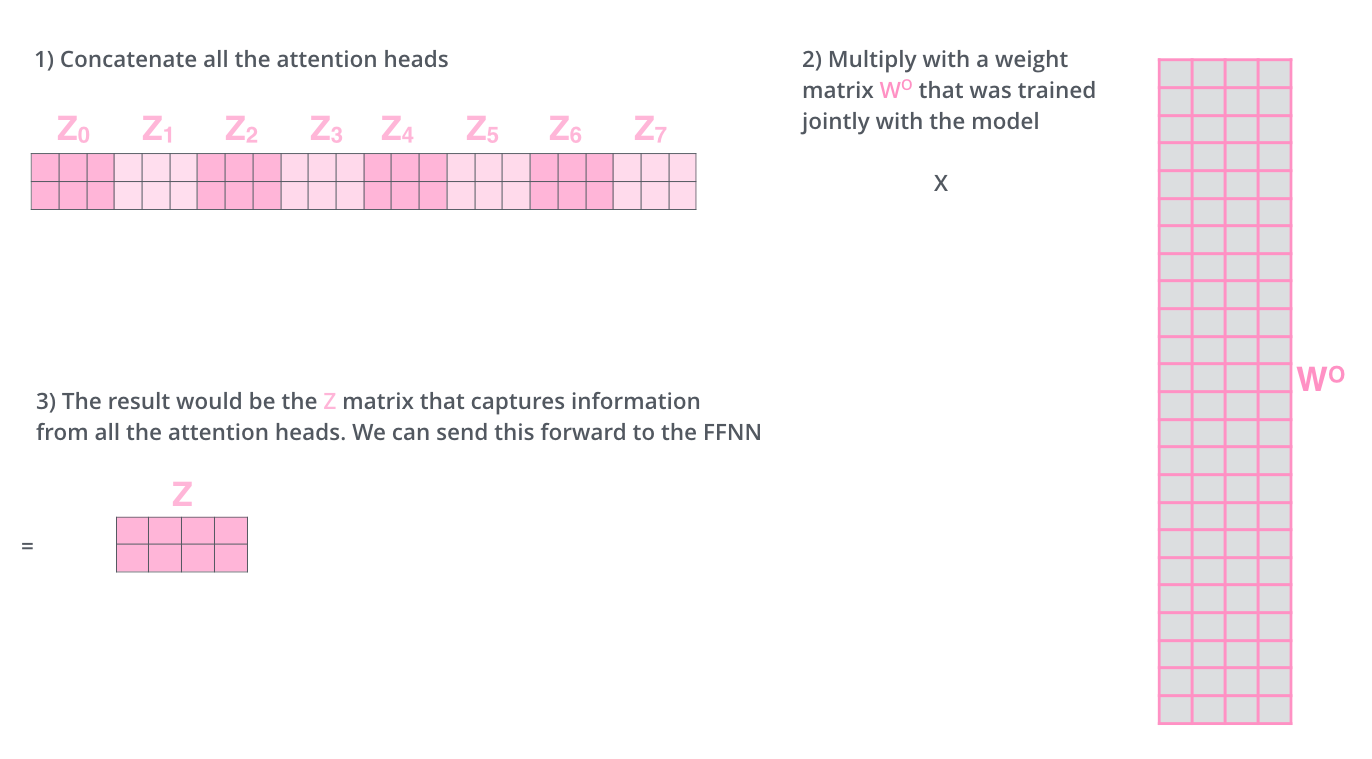
По большей части, это все, что нужно знать о множественном внутреннем внимании. Да, получилось довольно много матриц. Позвольте попробовать изобразить их на одной картинке так, чтобы мы увидели все в одном месте.
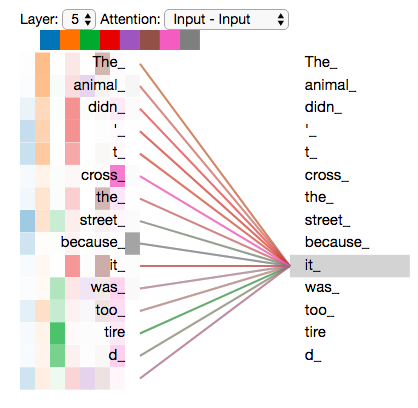
Теперь, когда мы коснулись «голов» внимания, давайте вспомним наш пример для того, чтобы посмотреть, на чем фокусируются различные «головы» во время кодирования «it» в нашем предложении:

По мере того как мы кодируем «it», одна «голова» фокусируется в большей степени на «the animal», в то время как другая — на «tired». Можно сказать, что представление моделью слова «it» строится на некотором представлении слов «animal» и «tired».
Мы можем отобразить все «головы» внимания на одной картинке, однако, ее будет сложнее интерпретировать.
Мы пропустили одну важную вещь в нашей модели — способ учитывать порядок слов во входящем предложении.
Для решения этой проблемы в Трансформеры добавляют вектор в каждый входящий эмбеддинг. Эти векторы имеют определенный шаблон, который модель запоминает и который помогает определить позицию каждого слова или расстояние между разными словами в предложении. Интуиция здесь состоит в том, что добавление этих значений к эмбеддингам создает осмысленные расстояния между векторами эмбеддингов в процессе их проецирования в Q/K/V векторы и скалярного произведения при вычислении внимания.
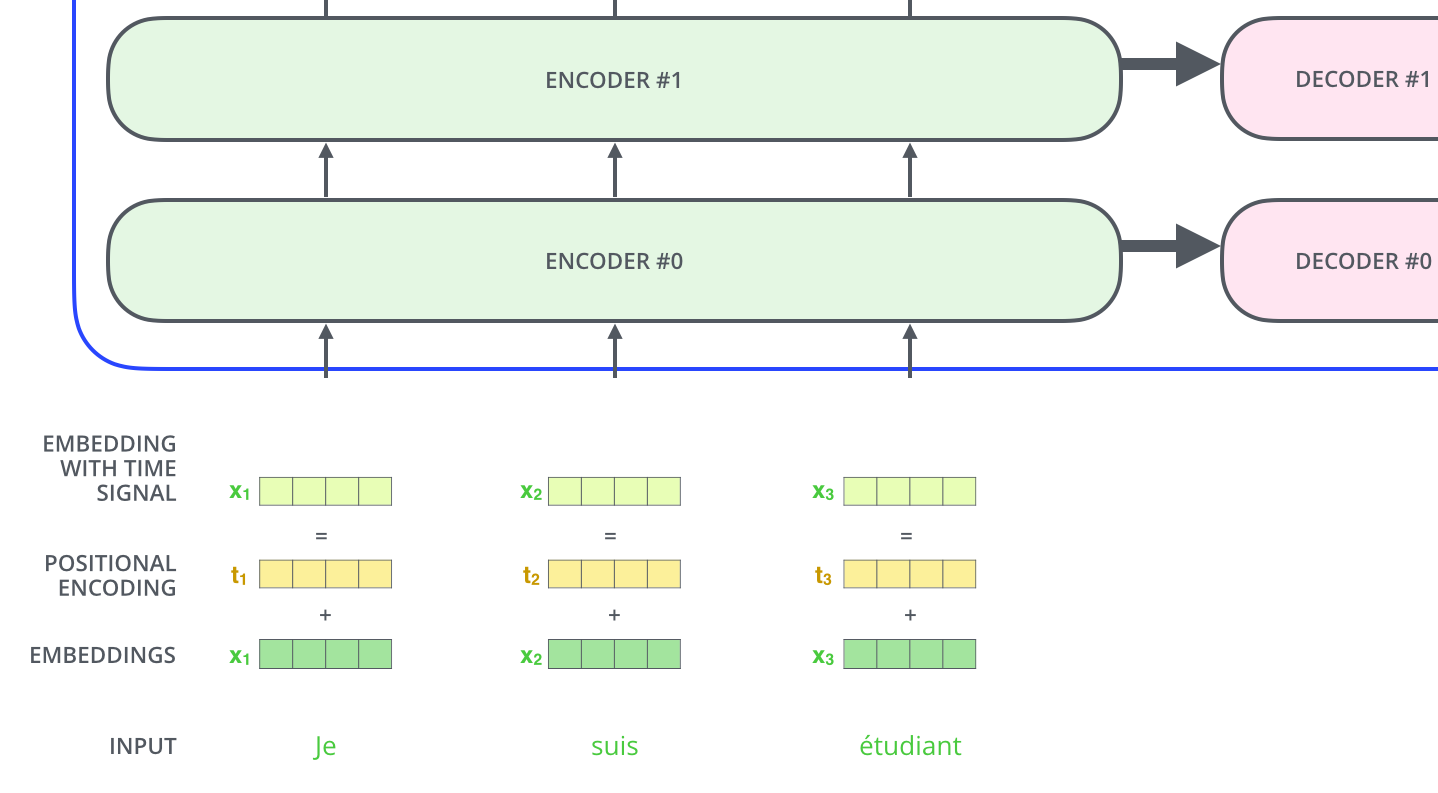
Для того, чтобы модель понимала порядок слов, мы добавляем векторы позиционного кодирования, значения которых следуют определенному шаблону.
Если мы считаем, что эмбеддинг имеет размерность 4, то реальные позиционные кодировки будут выглядеть так:
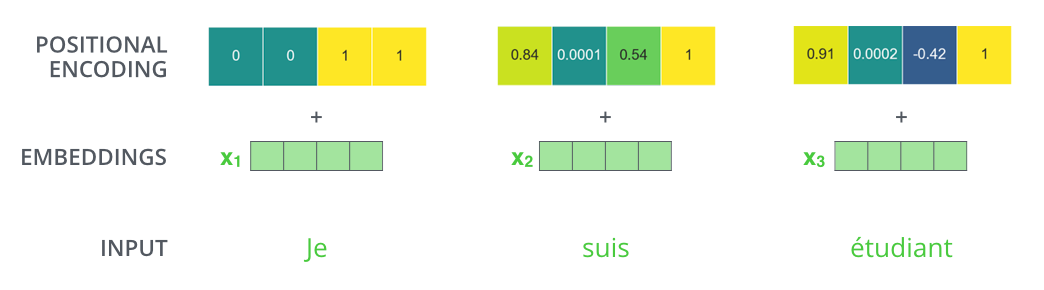
Как может выглядеть этот шаблон?
На следующем изображении каждая строка соответствует вектору позиционного кодирования: так, первая строка будет вектором, который мы добавляем к эмбеддингу первого слова во входной последовательности, вторая строка — к эмбеддингу второго слова и т.д. Каждая строка содержит 512 значений от -1 до 1. Мы перенесли эти значения в цвета, чтобы шаблон был более нагляден.
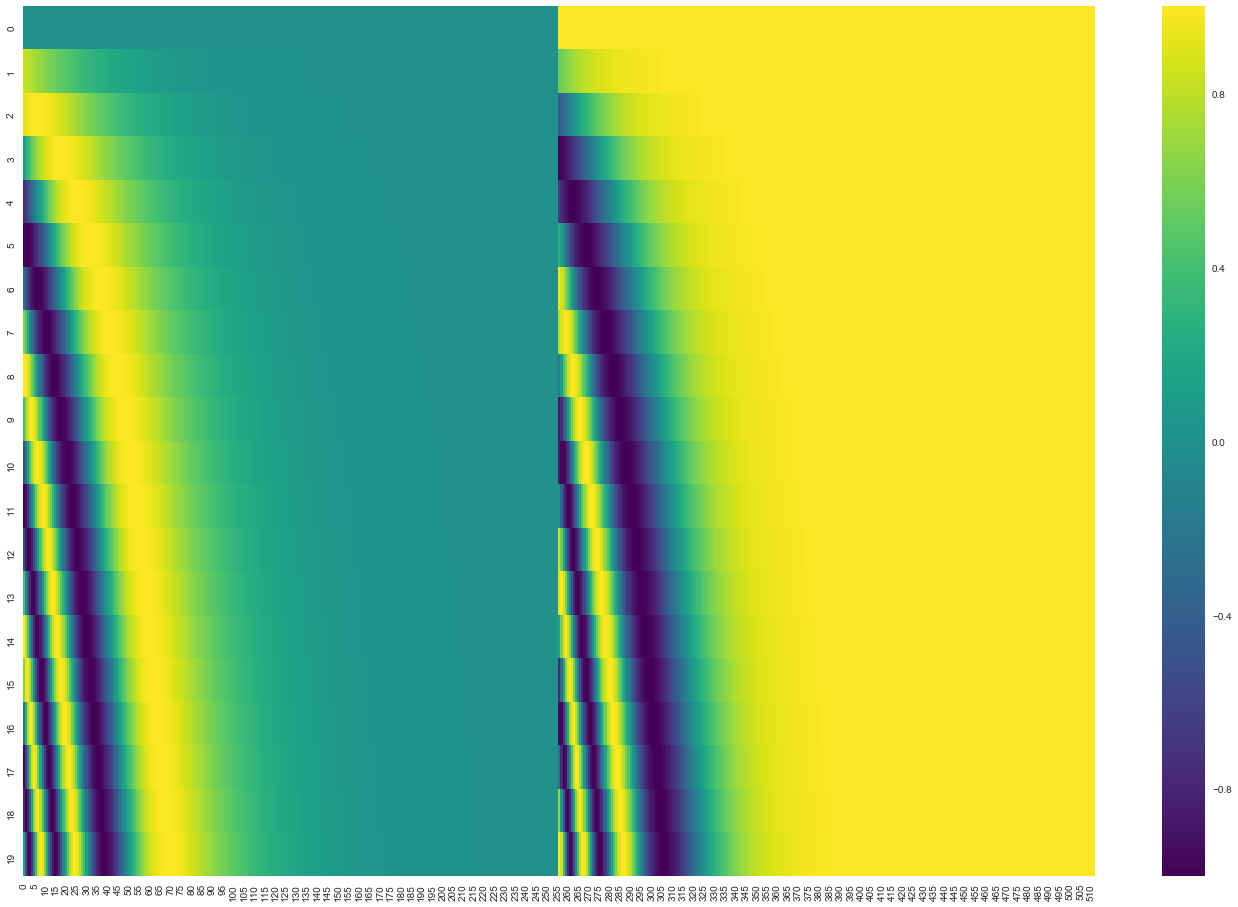
Реальный пример позиционного кодирования для 20 слов (строки) с эмбеддингами размером 512 (столбцы). Видно, что посередине есть разрыв: значения слева сгенерированы одной функцией (использующей синус), а справа — другой (использующей косинус). Они были конкатенированы для формирования каждого из векторов позиционного кодирования.
Формула для позиционного кодирования описана в статье (раздел 3.5). Вы можете посмотреть код для генерации позиционных кодировок в get_timing_signal_1d (). Это не единственный возможный метод для позиционного кодирования, однако, он позволяет масштабироваться на последовательности неопределенной длины (например, если наша обученная модель должна перевести предложение, которое длиннее всех, встречавшихся в обучающей выборке).
Последняя деталь в архитектуре энкодера, которую нам необходимо упомянуть, прежде чем двигаться дальше, заключается в том, что каждый подслой (внутреннее внимание, полносвязный) в каждом энкодере имеет остаточную связь вокруг себя, за которой следует этап нормализации слоя (layer-normalization step).
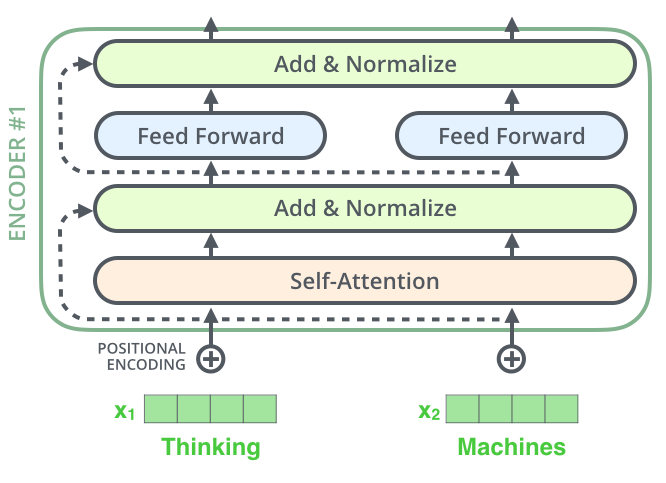
Визуализация векторов и операции нормализации слоя, относящейся к внутреннему вниманию, выглядит следующим образом:
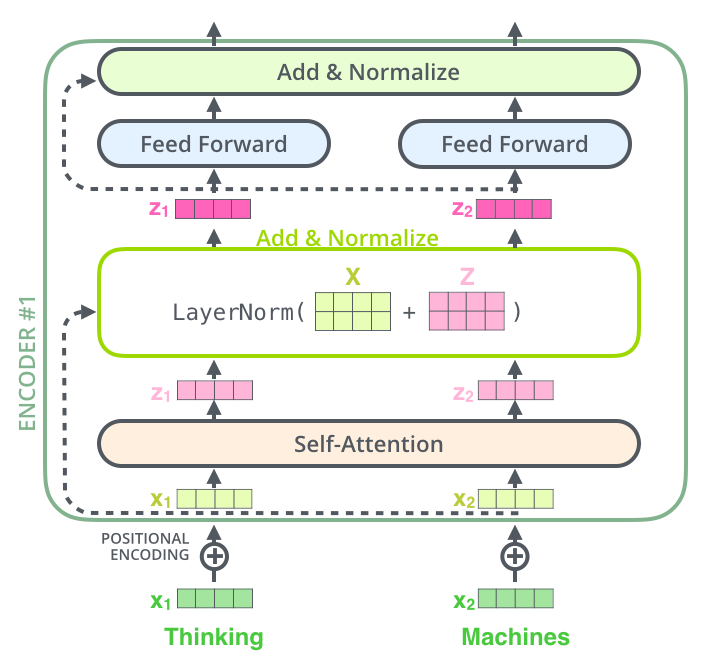
Так же выглядит ситуация и для подслоев декодера. Рассматривая Трансформер как два стека энкодеров и декодеров, представим его в виде следующей схемы:
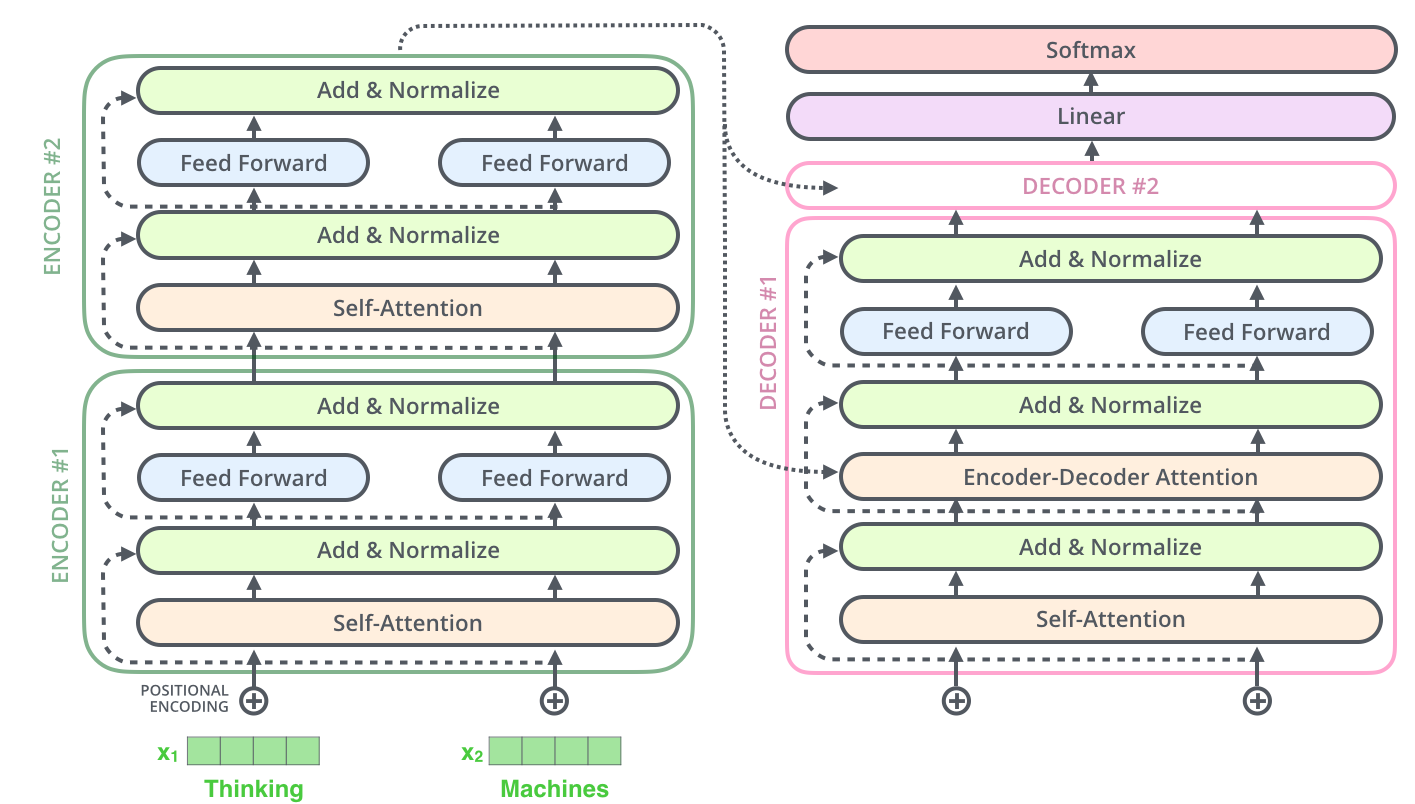
Теперь, когда мы осветили большинство понятий по части энкодера, мы фактически уже знаем, как работают компоненты декодера. Но давайте посмотрим, как компоненты энкодера и декодера работают вместе.
Энкодер начинает обрабатывать входящее предложение. Выход верхнего энкодера затем преобразуется в набор векторов внимания K и V. Они используются всеми декодерами в их «энкодер-декодер» слое внимания, что помогает им фокусироваться на подходящих местах во входящем предложении:
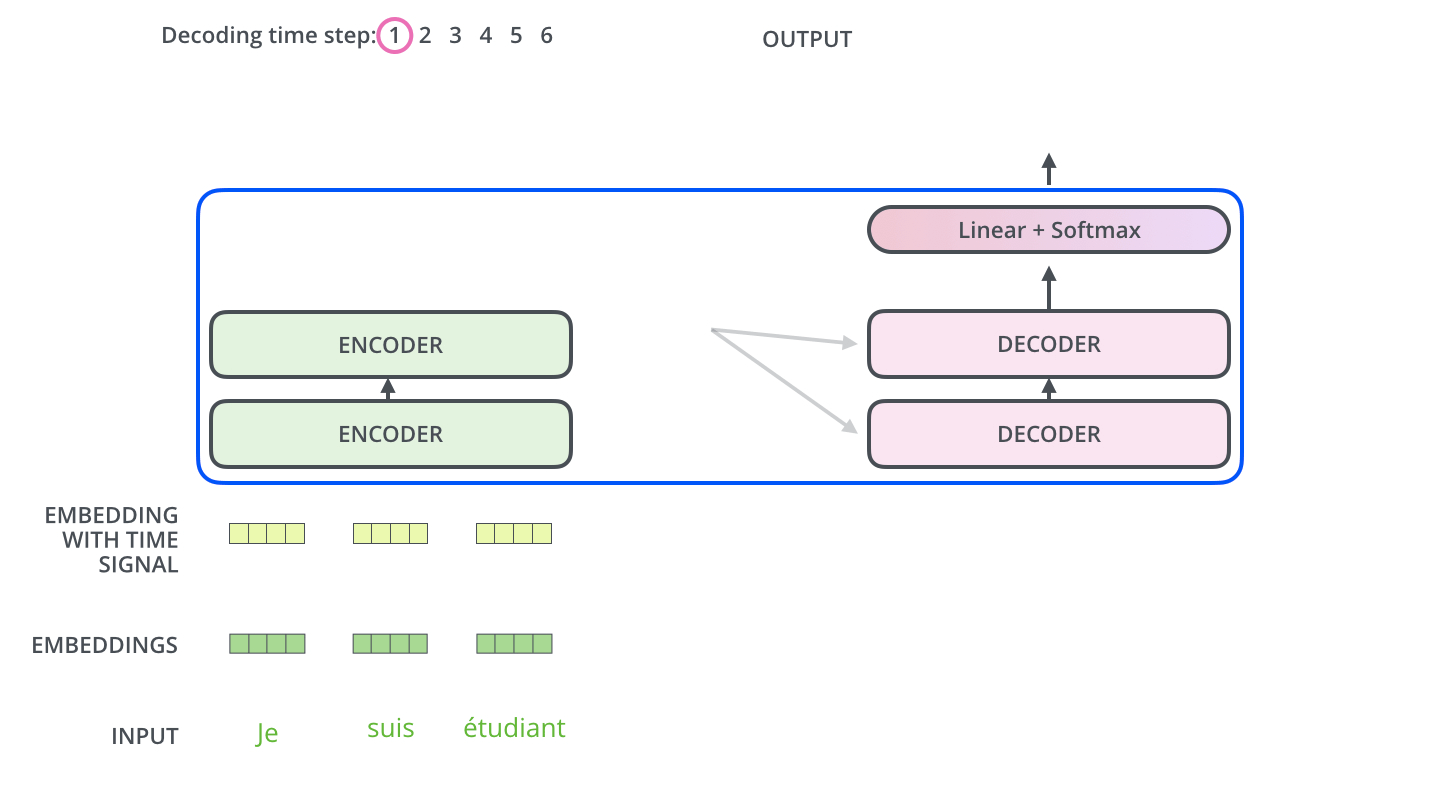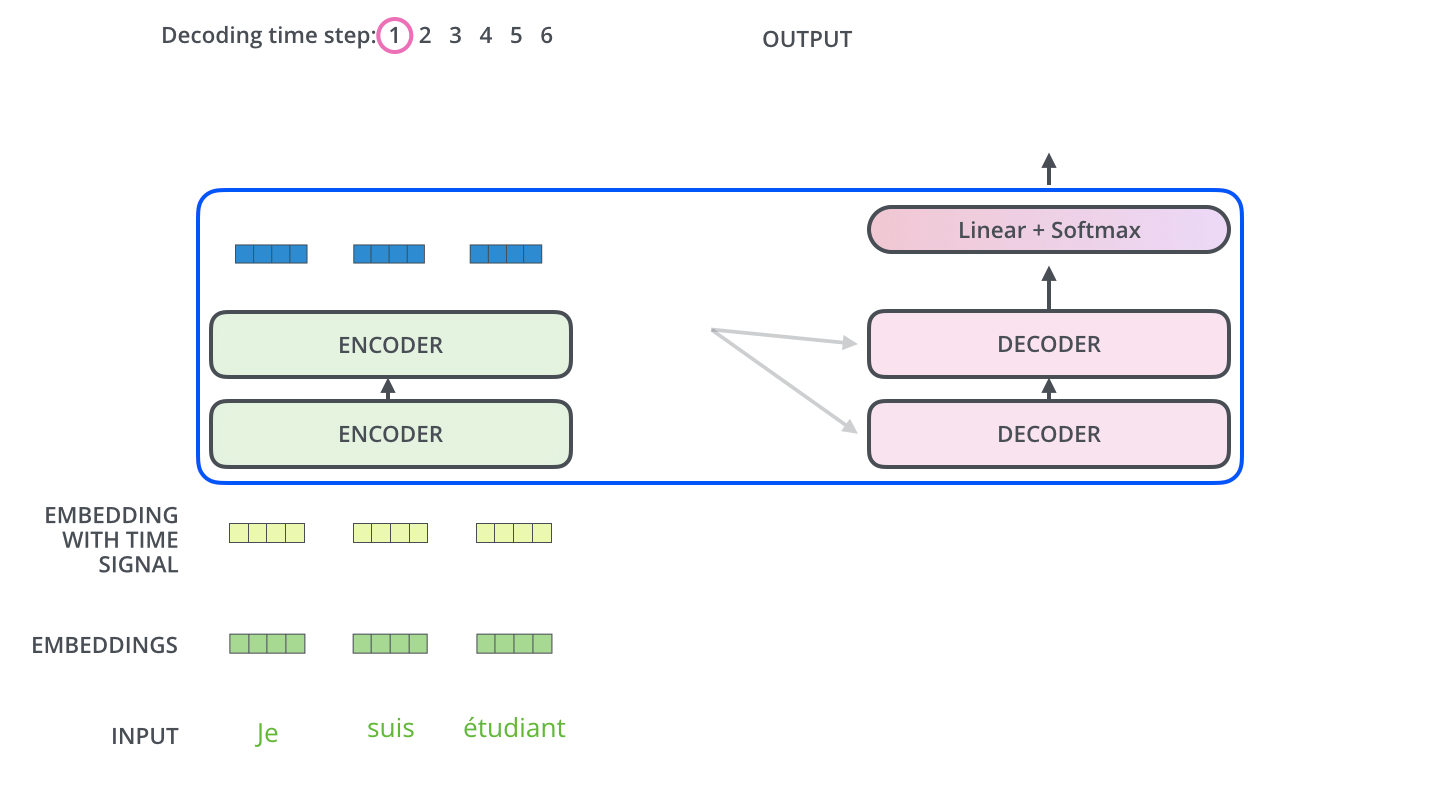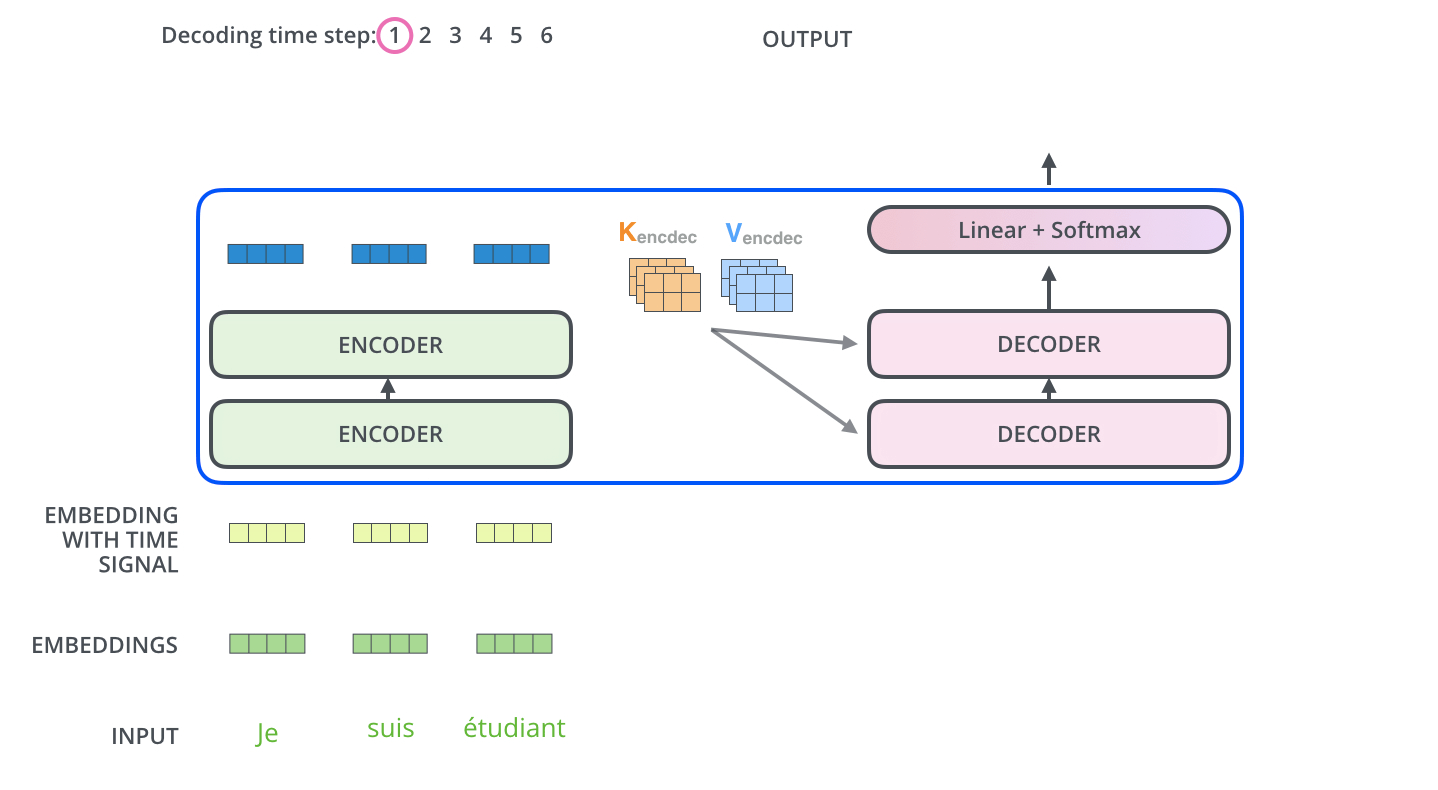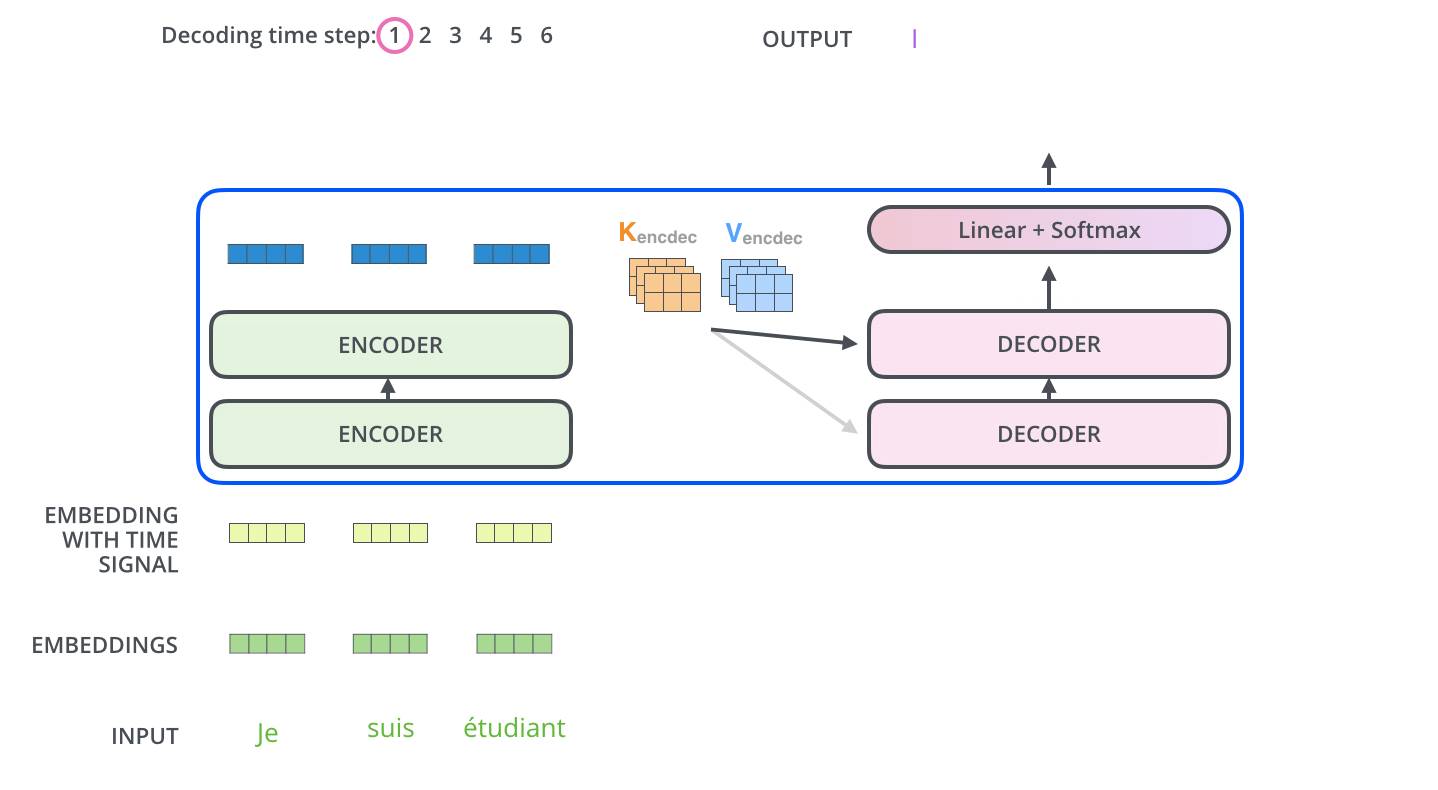
После завершения фазы кодирования начинается фаза декодирования. Каждый этап фазы декодирования возвращает элемент выходной последовательности (в данном случае — переводное предложение на английском).
Следующие шаги повторяются до появления специального символа, сообщающего, что декодер Трансформера завершил генерацию выходной последовательности. Выход каждого этапа отправляется на нижний декодер в следующем временном промежутке, и декодеры генерируют свой результат так же, как это делают энкодеры. И точно так же, как мы делали с входами энкодеров, мы добавляем позиционное кодирование на те входы декодеров, которые указывают на позицию каждого слова.
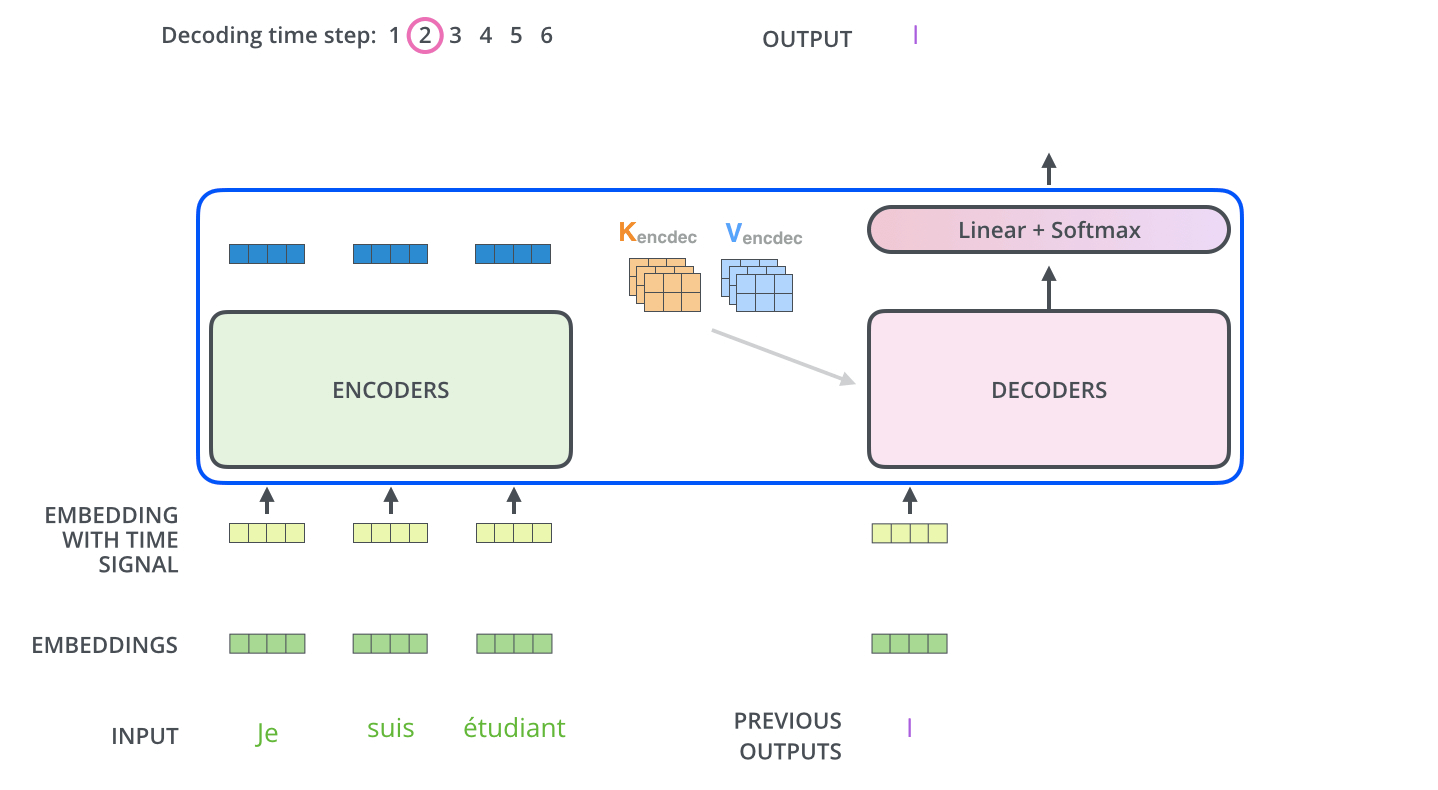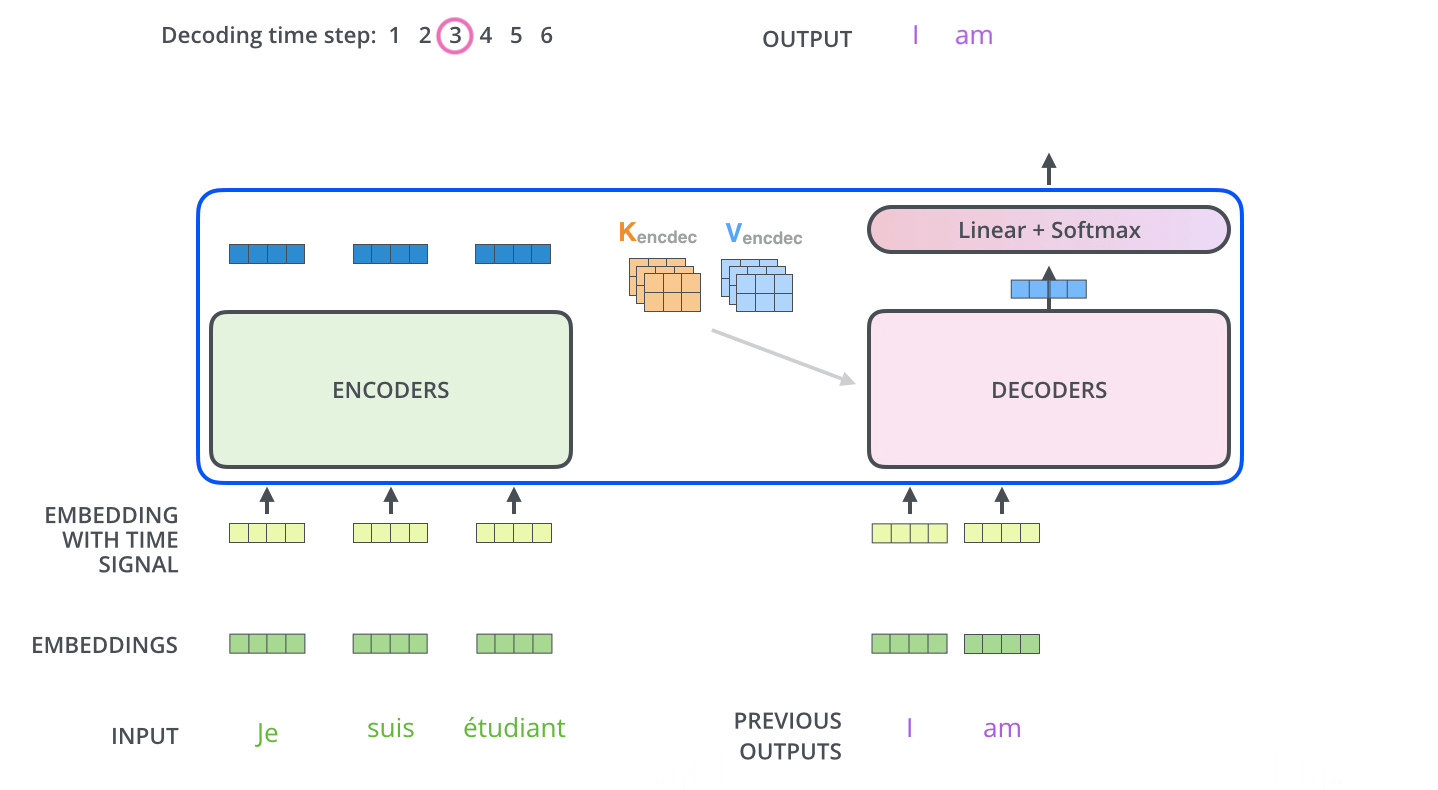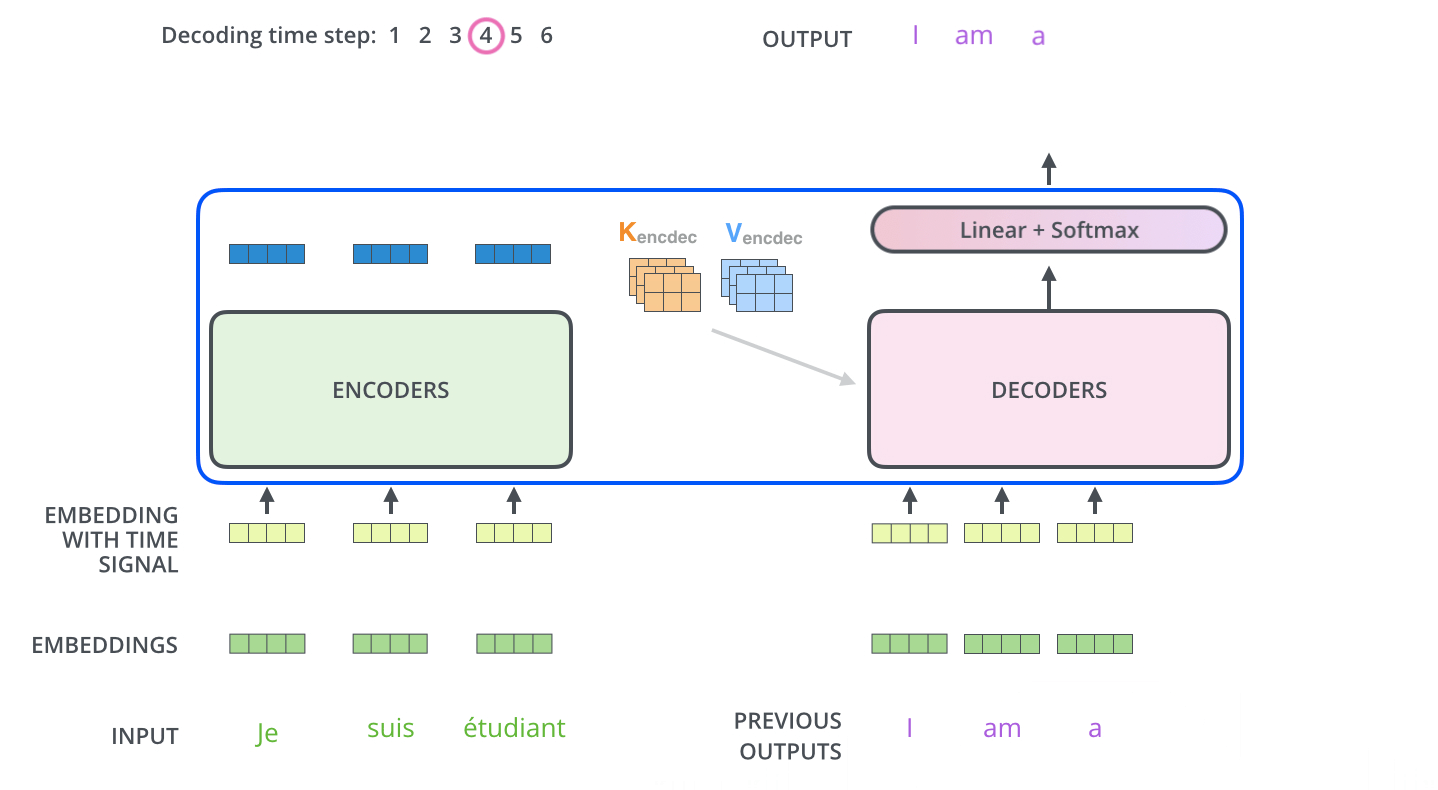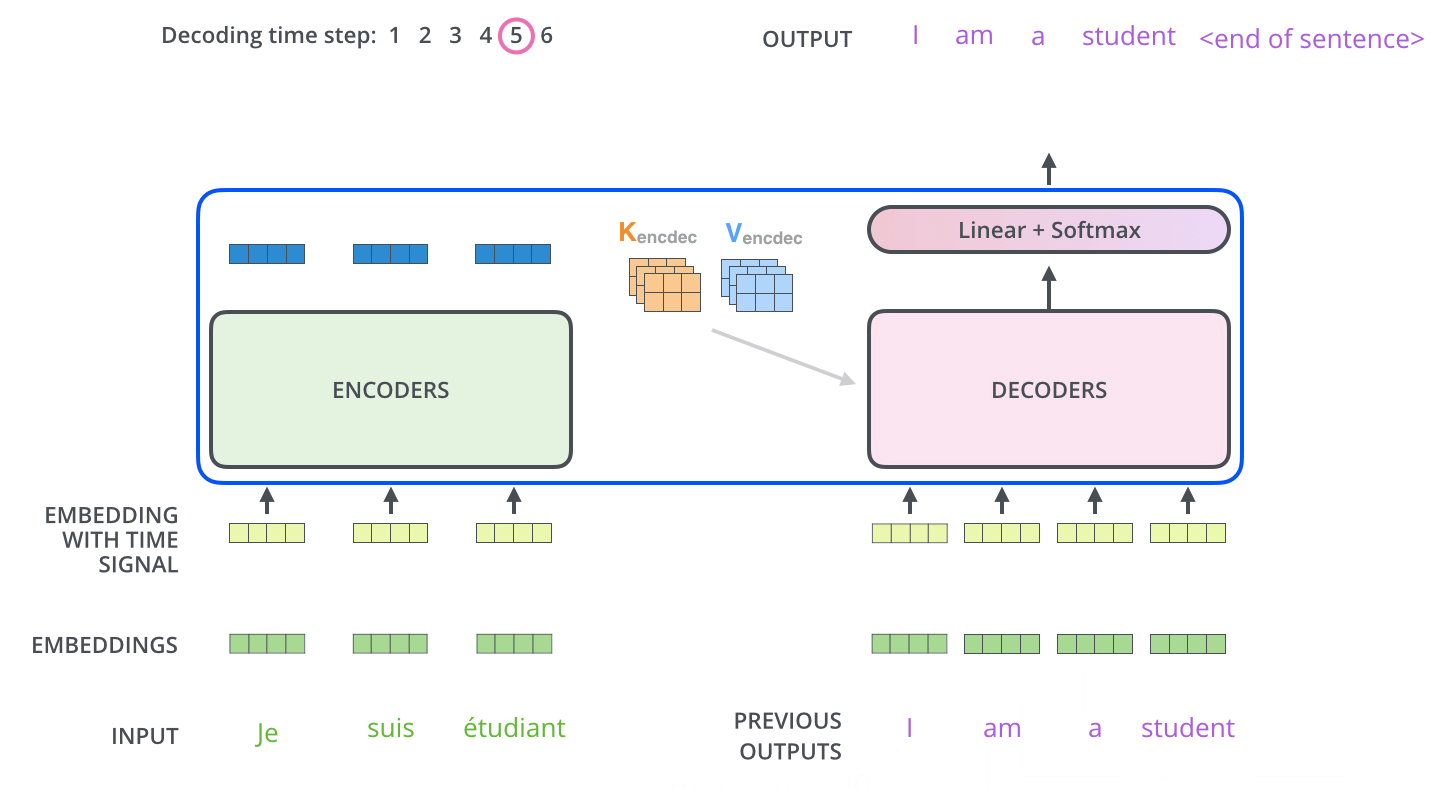
Слои внутреннего внимания в декодере работают немного отлично от слоев в энкодере.
В декодере слой внутреннего внимания может фокусироваться только на предыдущих позициях в выходном предложении. Это делается с помощью маскировки всех позиций после текущей (устанавливая их в –inf) перед этапом софтмакс в вычислении внутреннего внимания.
«Энкодер-декодер» слой внимания работает как множественное внимание, кроме того, что он создает матрицу запроса из слоя, который находится ниже, и берет матрицы ключей и значений из выхода стека энкодеров.
Стек декодеров на выходе возвращает вектор чисел с плавающей точкой. Как можно получить из этого вектора слово? За это отвечает линейный слой и следующий за ним слой софтмакс.
Линейный слой — это простая полносвязная нейронная сеть, которая переводит вектор, созданный стеком декодеров, в значительно больший вектор, называемый логит вектором (logits vector).
Пусть наша модель знает 10 тысяч уникальных английский слов («выходной словарь» нашей модели), которые она узнала из обучающего корпуса. Это означает, что наш логит вектор будет иметь 10 000 ячеек в ширину — каждая ячейка соответствует коэффициенту одного уникального слова. Таким образом мы интерпретируем выход нашей модели с помощью линейного слоя.
Слой софтмакс переводит этот показатель в вероятности (положительные числа, сумма которых равна 1). Выбирается ячейка с наиболее высокой вероятностью и на выход данного временного отрезка подается соответствующее слово.
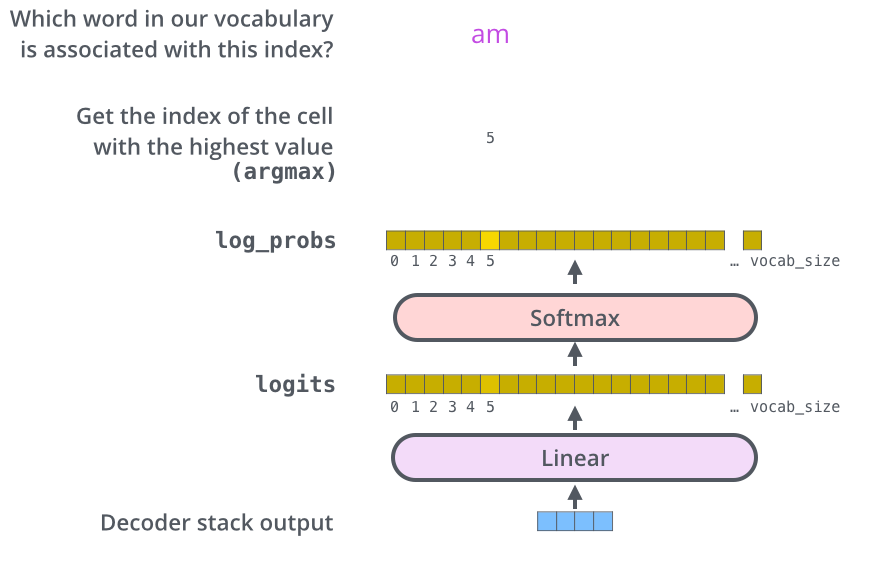
Эта картинка начинается снизу, где стек декодеров генерирует в качестве выхода вектор, который затем преобразуется в выходное слово.
Теперь, когда мы осветили весь процесс, проходящий в Трансформере, будет полезно взглянуть на основные моменты, происходящие во время обучения модели.
Во время обучения еще необученная модель пройдет через точно такой же алгоритм, описанный нами ранее. Но т.к. мы тренируем ее на размеченном обучающем корпусе, мы можем сравнить получившийся выход с имеющимся эталонным.
Для визуализации допустим, что наш словарь состоит только из 6 слов («a», «am», «i», «thanks», «student» и »
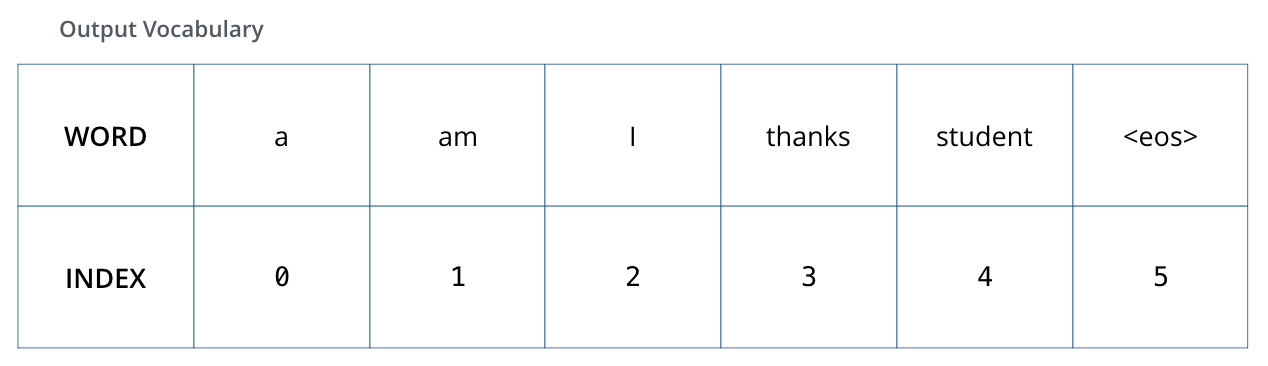
Выходной словарь нашей модели создается на этапе предобработки еще до начала обучения.
Как только мы определили наш словарь, мы можем использовать вектор такого же размера для представления каждого слова в словаре (метод, известный как one-hot-кодирование). Например, мы можем представить слово «am», используя следующий вектор:
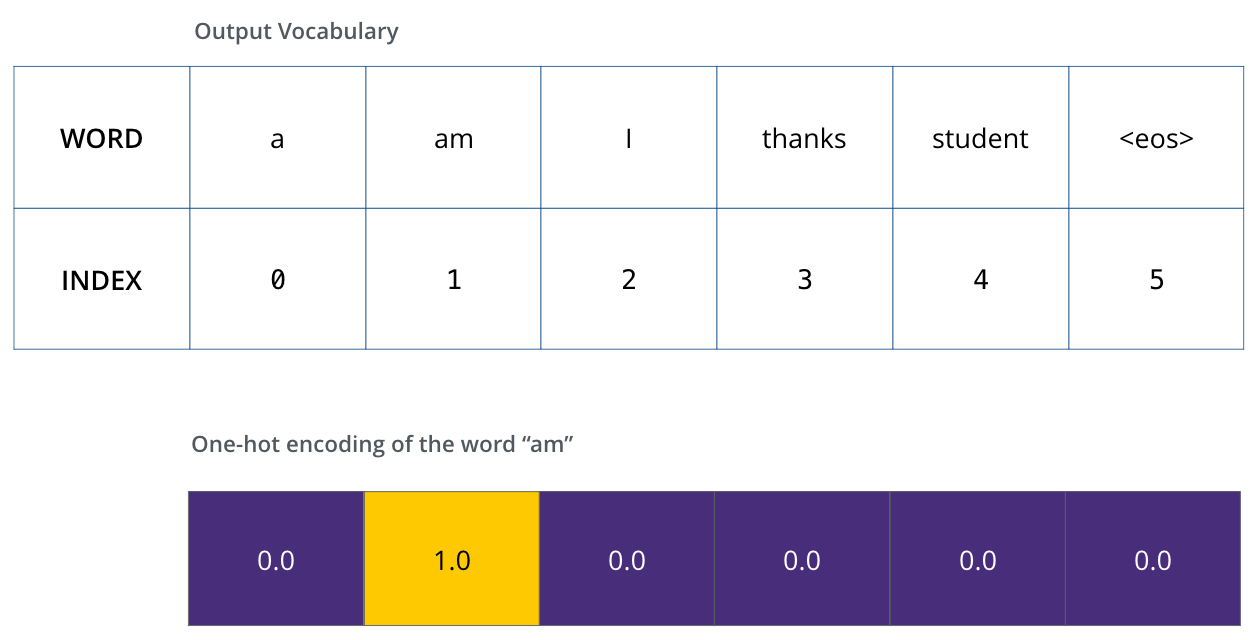
Пример: one-hot-кодирование нашего выходного словаря.
Далее давайте обсудим функцию потерь (loss function) этой модели — метрику, которую мы оптимизируем во время фазы обучения для создания обученной и, хотелось бы надеяться, точной модели.
Предположим, что мы тренируем нашу модель и это наш первый этап в обучающей фазе. Обучение проводим на простом примере — перевод «merci» в «thanks».
На деле это означает, что мы хотим получить выход, представляющий собой распределение вероятностей, указывающее на слово «thanks». Но т.к. модель еще не обучена, вряд ли у нее это получится.
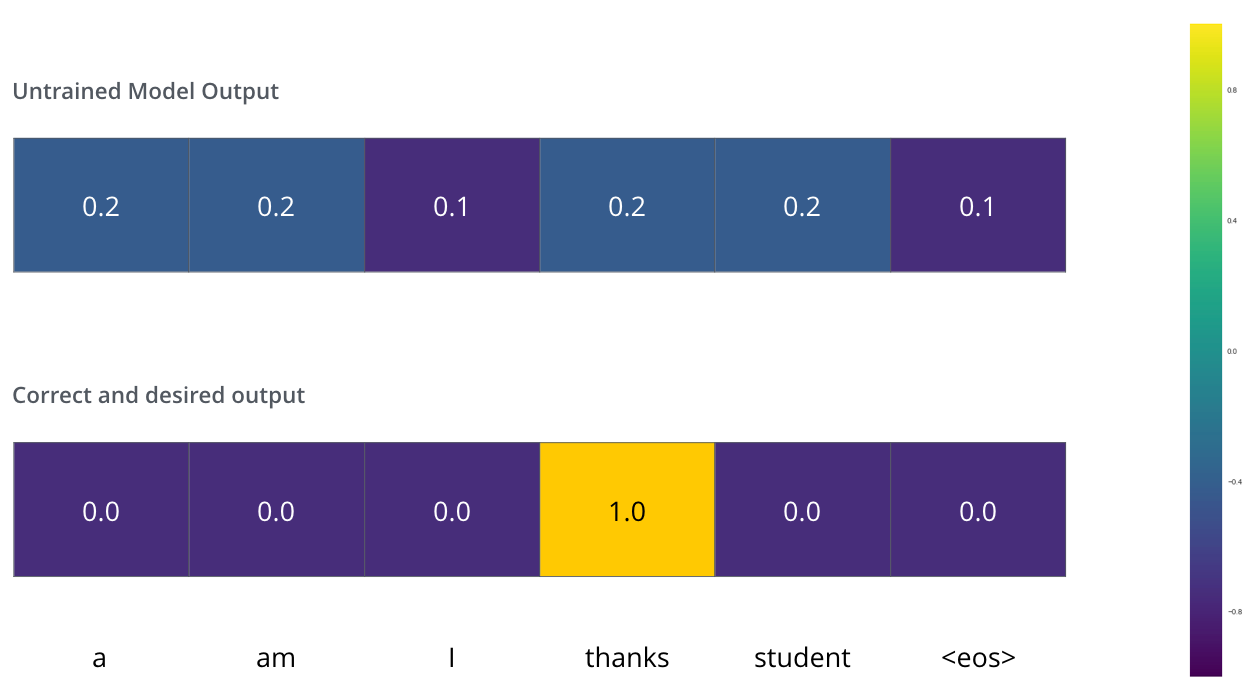
Поскольку параметры модели (веса) инициализированы случайным образом, необученная модель генерирует распределение вероятностей с произвольными значениями для каждой ячейки/слова. Мы можем сравнить его с реальным выходом, затем изменить все веса, используя метод обратного распространения ошибки для того, чтобы приблизить выход к желаемому.
Как можно сравнить два распределения вероятностей? Мы просто вычитаем одно из другого. Для более детального знакомства, см. перекрестную энтропию и расстояние Кульбака-Лейблера.
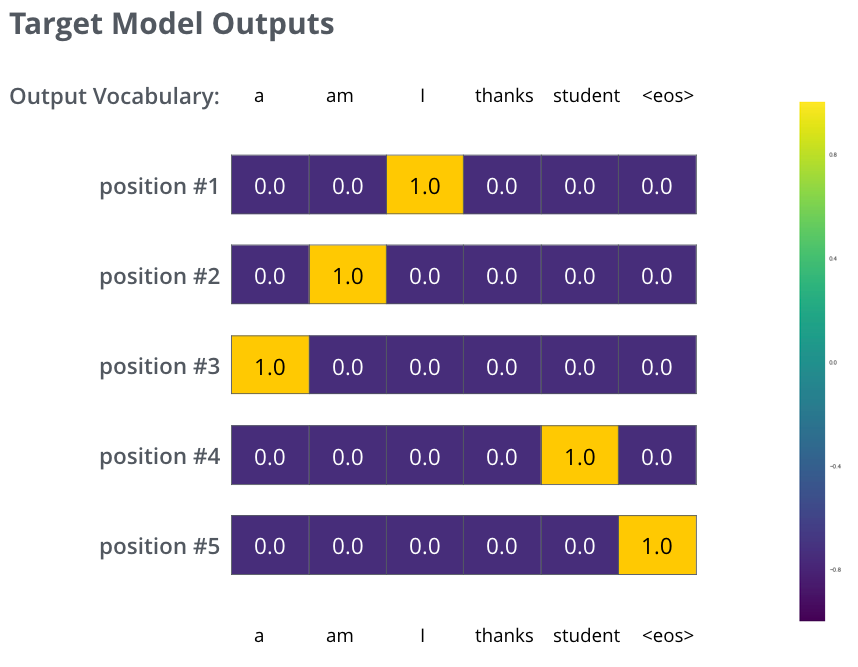
Но помните, что это сильно упрощенный пример. В реальных задачах в большинстве случаев мы будем использовать предложения длиннее одного слова. Например, подавать на вход «je suis étudiant» — и ожидать выход «I am a student». Это означает, что мы хотим, чтобы наша модель более успешно генерировала вероятностное распределение, при том что:
- каждое вероятностное распределение представляет собой вектор с размерностью равной размеру выходного словаря (6 в нашем игрушечном примере, на деле — порядка 3000 или 10000);
- первое вероятностное распределение имеет наибольшую вероятность в ячейке, соответствующей слову «i»;
- второе вероятностное распределение имеет наибольшую вероятность в ячейке, соответствующей слову «am»;
- и т.д. пока пятое вероятностное распределение не покажет символ конца предложения, который также имеет свою ячейку выходном словаре.
После обучения модели в течение достаточного времени и на достаточно большом корпусе, мы можем надеяться на получение таких вероятностных распределений:
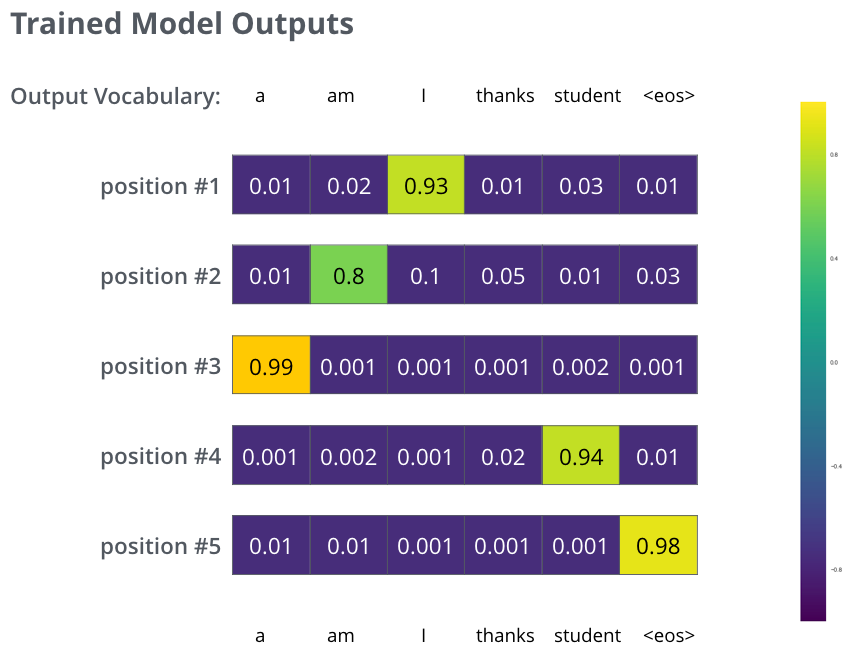
Надеемся, что после обучения модель выдаст ожидаемый нами правильный перевод. Конечно, это не является реальным индикатором в случае, если данная фраза была частью обучающей выборки (см.: перекрестная проверка). Обратите внимание, что у каждой позиции есть некая небольшая вероятность, вне зависимости от того, будет ли она выходом этого временного шага или нет — это очень полезное свойство функции софтмакс, которое помогает процессу обучения.
Теперь, исходя из того, что модель генерирует один выходной элемент за раз, мы можем полагать, что модель выбирает слово с наибольшей вероятностью из вероятностного распределения и откидывает все остальные. Это один из способов, называемый жадным декодированием (greedy decoding). Другой способ — получить, например, первые 2 сгенерированных слова (в нашем случае, «I» и «a») и дальше, на следующем шаге, дважды запустить модель: в первый раз полагая, что на первой позиции в выходе стояло «I», и второй раз, полагая, что первым словом было «a». Та гипотеза, которая произвела меньше ошибки с учетом двух позиций, в итоге и принимается. Мы повторяем это для позиций #2 и #3 и т.д. Такой метод называется «лучевым поиском» (beam search). В нашем примере размер луча (beam_size) был равен двум (т.к. мы сравнивали результаты после вычисления лучей на позициях #1 и #2), и топ-лучей (top_beams) было также два (поскольку мы оставляли два слова). С этими двумя гиперпараметрами можно экспериментировать при обучении модели.
Надеюсь, статья была полезной и станет отправной точкой в изучении Трансформера. Если вы хотите более глубоко изучить тему, предлагаю следующие шаги:
Материалы для дальнейшего изучения:
