[Перевод] Тестирование микросервисов: разумный подход
Движущая сила микросервисов
Возможность разрабатывать, развертывать и масштабировать различные бизнес-функции независимо друг от друга — это одно из самых разрекламированных преимуществ перехода на микросервисную архитектуру.
Пока властители дум всё ещё не могут определиться, справедливо ли это утверждение или нет, микросервисы уже успели войти в моду — причем до такой степени, что для большинства стартапов они де-факто стали архитектурой, выбираемой по умолчанию.
Однако, когда дело доходит до тестирования (или, чего похуже, разработки) микросервисов, выясняется, что большинство компаний по-прежнему испытывает привязанность к допотопному способу тестирования всех компонентов вместе. Создание сложной инфраструктуры считается обязательным условием для проведения сквозного (end-to-end) тестирования, при котором набор тестов для каждого сервиса обязательно должен быть выполнен — делается это для того, чтобы убедиться, что в сервисах не появилось регрессий или несовместимых изменений.
От переводчиков. В оригинальной статье Синди Шридхаран используется большое количество терминологии, для которой нет устоявшихся русских аналогов. В некоторых случаях используются употребляемые англицизмы, их нам кажется разумным писать по-русски, а в спорных случаях, во избежание неверной интерпретации, мы будем писать и исходный термин.
Сегодня мир не испытывает недостатка в книгах и статьях, посвященных лучшим практикам тестирования программного обеспечения. Однако в нашей сегодняшней статье мы сосредоточимся исключительно на теме тестирования бэкенд-сервисов и не станем затрагивать тестирование десктоп-приложений, систем с особыми требованиями по технической безопасности, инструментов с графическим интерфейсом и остальных видов ПО.
Стоит заметить, что в понятие «распределенной системы» различные специалисты вкладывают разный смысл.
В рамках нашей сегодняшней статьи, под «распределенной системой» имеется в виду система, состоящая из многочисленных движущихся частей, каждая из которых обладает различными гарантиями и видами отказов, эти части работают вместе в унисон для того, чтобы реализовывать определенную бизнес-функцию. Пусть моё описание и весьма отдаленно похоже на классическое определение распределенных систем, но оно применимо к тем системам, с которыми мне регулярно приходится сталкиваться — и я готова поспорить, что как раз такие системы подавляющее большинство из нас разрабатывает и поддерживает. Далее в статье речь идёт про распределенные системы, которые сегодня принято называть «микросервисной архитектурой».
«Полный стек в коробке»: история-предостережение
Мне часто приходится сталкиваться с компаниями, которые пытаются целиком воспроизвести топологию сервисов локально на ноутбуках разработчиков. С этим заблуждением мне пришлось столкнуться лично на прошлом месте работы, где мы пытались развернуть весь наш стек в Vagrant-боксе. Репозиторий Vagrant называли «полным стеком в коробке»; как вы уже могли догадаться, идея состояла в том, чтобы одна простая команда vagrant up должна была позволить любому инженеру в нашей компании (даже фронтенд и мобильным разработчикам), развернуть абсолютно весь стек на их рабочих ноутбуках.
Собственно говоря, это не была полноценная микросервисная архитектура масштабов Amazon, содержащая тысячи сервисов. У нас было два сервиса на бекэнде: API-сервер, основанный на gevent, и работающие в фоновом режиме асинхронные воркеры на Python, у которых был целый клубок из нативных зависимостей, включавших boost на C++ — причем, если мне не изменяет память, он компилировался с нуля каждый раз, когда запускался новый бокс на Vagrant.
Моя первая рабочая неделя в этой компании целиком ушла лишь на то, чтобы локально поднять виртуальную машину и победить великое множество ошибок. Наконец, к вечеру пятницы мне удалось заставить Vagrant работать, и все тесты успешно отработали на моём ПК. Напоследок я решила задокументировать все проблемы, с которыми мне пришлось столкнуться, чтобы у других разработчиков было меньше подобных проблем.
И что же вы думаете, когда новоприбывший разработчик начал настраивать Vagrant, то он столкнулся с совсем другими ошибками — причём у меня даже не получилось воспроизвести их на моей машине. По правде говоря, вся эта хрупкая конструкция и на моем ноутбуке дышала на ладан — я боялась даже обновить библиотеку для Python, поскольку выполненный однажды pip install ухитрился поломать настройки Vagrant, и при локальном запуске перестали проходить тесты.
В процессе разбора полетов выяснилось, что аналогичным образом дела с Vagrant обстояли и у программистов из команд мобильной и веб-разработки; устранение проблем с Vagrant стало частым источником запросов, поступающих в команду саппорта, где я тогда работала. Конечно, кто-то может заявить, что мы просто должны были потратить больше времени на то, чтобы раз и навсегда «пофиксить» настройки Vagrant, чтобы всё «просто работало», в свою защиту скажу, что описанная история происходила в стартапе, где времени и инженерных циклов вечно ни на что не хватает.
Фрэд Эбер написал замечательную рецензию на данную статью, и сделал замечание, которое в точности описывает мои ощущения:
… просьба запустить облако на машине разработчика эквивалентна необходимости поддержки нового облачного провайдера, причем худшего из всех возможных, с каким вам только доводилось сталкиваться.
Даже при том условии, что вы будете следовать самым современным методикам эксплуатации — «инфраструктура как код», неизменямая инфраструктура — попытка развернуть облачное окружение локально не принесёт вам пользы, соизмеримой с усилиями, которые уйдут у вас на его поднятие и долгосрочную поддержку.
Поговорив со своими друзьями, я выяснила, что описанная проблема отравляет жизнь не только тем, кто работает в стартапах, но и тем, кто трудится в больших организациях. За последние несколько лет мне довелось услышать немало анекдотов о том, с какой легкостью разваливается подобная конструкция и как дорого обходится эксплуатации ее поддержка. Теперь я твердо уверена в том, что идея развертывания всего стека на ноутбуках разработчиков порочна вне зависимости от того, какой размер имеет ваша компания.
Фактически, подобный подход к микросервисам равносилен созданию распределенного монолита.
2020 prediction: Monolithic applications will be back in style after people discover the drawbacks of distributed monolithic applications.
— Kelsey Hightower (@kelseyhightower) December 11, 2017
Предсказание на 2020 год: монолитные приложения снова в моде, после того, как люди ознакомились с недостатками распределенных монолитов.
Как замечает блогер Тайлер Трит:
От души посмеялся над обсуждением микросервисов на Hacker News. «Разработчики должны иметь возможность развернуть окружение локально, всё остальное — это признаки плохих инструментов». Ну да, конечно, умник, попробуй запусти штук 20 микросервисов с разными БД и зависимостями на своем Макбуке. Ах да, я же забыл, что docker compose решит все твои проблемы.Везде одно и то же. Люди начинают создавать микросервисы, при этом не меняя своего «монолитного» склада ума, и это всегда заканчивается настоящим театром абсурда. «Мне нужно запустить все это на своей машине с выбранной конфигурацией сервисов для того, чтобы протестировать одно единственное изменение». Что же с нами стало…
Если кто-нибудь, не дай бог, случайно чихнет, то мой код сразу станет не поддающимся тестированию. Что ж, удачи вам с подобным подходом. Даже невзирая на то, что масштабные интеграционные тесты, затрагивающие значительное число сервисов, являются анти-паттерном, в этом по-прежнему тяжело убедить остальных. Переход к микросервисам означает использование правильных инструментов и методов. Перестаньте использовать старые подходы в новом контексте.
В масштабах всей индустрии, мы по-прежнему привязаны к методологиям тестирования, изобретенным в далекую от нас эпоху, которая разительно отличалась от той реальности, в которой мы находимся сегодня. Люди по-прежнему увлечены идеями вроде полного покрытия тестами (настолько сильно, что в некоторых компаниях merge будет заблокирован, если патч или бранч с новой фичей приводит к понижению степени покрытия кодовой базы тестами более, чем на определенную долю процента), разработкой через тестирование и полным end-to-end тестированием на системном уровне.
В свою очередь, такие убеждения приводят к тому, что большие инженерные ресурсы вкладываются в построение сложных CI пайплайнов и замысловатых локальных окружений разработки. Достаточно быстро поддержка подобной расширенной системы оборачивается необходимостью содержать команду, которая будет создавать, поддерживать, устранять неполадки и развивать инфраструктуру. И если большие компании могут себе позволить настолько глубокий уровень изощрённости, то всем остальным лучше просто воспринимать тестирование как оно есть: это наилучшая возможная верификация системы. Если мы будем с умом подходить к оценке стоимости нашего выбора и и идти на компромиссы, то это и будет наилучшим вариантом.
Спектр тестирования
Традиционно принято считать, что тестирование производится перед релизом. В некоторых компаниях были — и существуют поныне — отдельные команды тестировщиков (QA), главной обязанностью которых является выполнение ручных или автоматизированных тестов для ПО, созданного командами разработки. Как только компонент ПО проходит QA, его передают команде эксплуатации для запуска (в случае сервисов), или же релизят в виде продукта (в случае десктоп-приложений и игр).
Эта модель медленно, но верно уходит в прошлое — по крайней мере, в отношении сервисов; на сколько я могу судить по стартапам в Сан-Франциско. Теперь команды разработчиков отвечают и за тестирование, и за эксплуатацию сервисов, которые они создают. Этот новый подход к созданию сервисов я нахожу невероятно мощным — он по-настоящему позволяет командам разработчиков думать о масштабе, целях, компромиссах и компенсациях на всем спектре методов тестирования — причем в реалистической манере. Для того, чтобы всецело разобраться, как функционируют наши сервисы, и удостовериться в корректности их работы, нам очевидно требуется возможность выбора правильного подмножества методов тестирования и инструментов с учетом требуемых параметров доступности, надежности и корректности работы сервиса.
So many amens. Testing pre-deploy is partially prep for testing in production. To paraphrase some of what you said: pre-deploy testing may teach, rehearse & reinforce biased mental models of the system, and actually work against you in prod by blinding you to reality.
— Baron Schwartz (@xaprb) December 17, 2017
Прямо как с языка сняли. Тестирование перед деплоем — это частичная подготовка к тестированию в продакшне. Перефразировав ваше утверждение: тестирование перед деплоем может научить, помочь прорепетировать и усилить необъективные ментальные модели системы, и на самом деле работает против вас в проде, делая вас невосприимчивым к реальности.
По большому счету, понятие «тестирование» может охватывать несколько видов деятельности, которые традиционно относят к сферам «релиз-инжиниринга», эксплуатации или QA. Некоторые из методов, перечисленных в таблице ниже, строго говоря не считаются формами тестирования — например, в официальном определении chaos engineering классифицируется как форма эксперимента; кроме того, приведенный список отнюдь не является исчерпывающим — в нем отсутствуют сканирование уязвимостей (vulnerability testing), тестирование на проникновение (penetration testing), моделирование угроз (threat modeling) и прочие методы тестирования. Однако, в таблицу включены все самые популярные способы тестирования, с которыми мы сталкиваемся ежедневно.

Разумеется, таксономия методов тестирования в приведенной таблице не совсем отражает реальность: как показывает практика, некоторые методы тестирования могут относиться сразу к обеим категориям. Так, к примеру, «профилирование» в ней отнесено к тестированию в продакшне — однако, к нему часто прибегают и во время разработки, поэтому его можно отнести и к тестированию в пре-продакшне. Аналогичным образом, shadowing — метод, при котором небольшое количество трафика с продакшна прогоняется по небольшому количеству тестовых инстансов — может считаться и тестированием в продакшне (ведь мы используем реальный трафик), и тестированием в пре-продакшне (ведь реальных пользователей оно не затрагивает).
Различные языки программирования обладают различной степенью поддержки тестирования приложений в продакшне. Если вы пишите на Erlang, то вполне возможно вы знакомы с руководством Фреда Эбера по использованию примитивов виртуальной машины для отладки систем в продакшне пока они продолжают работать. Языки вроде Go поставляются вместе со встроенной поддержкой профилирования кучи, блокировок, CPU и горутин для любого из запущенных процессов (тестирование в продакшне) или при запуске юнит-тестов (это можно квалифицировать как тестирование в пре-продакшне).
Тестирование в продакшне — замена тестирования в пре-продакшне?
В своей прошлой статье я уделила много внимания тестированию в «пост-продакшне», в основном с точки зрения наблюдаемости. К таким формам тестирования относятся мониторинг, оповещения, исследование и динамическая инструментация (вставка анализирующих процедур в исполняющийся код). Возможно, к тестированию в продакшне можно отнести и такие техники, как gating и использование флагов функций (feature flags, при помощи которых можно включать/отключать функциональность в коде с помощью конфигурации). Взаимодействие с пользователем и оценка пользовательского опыта — например, A/B тестирование и мониторинг реального пользователя также относятся к тестированию в продакшне.
В узких кругах идет обсуждение того, что такие методы тестирования могут прийти на смену традиционному тестированию в пре-продакшне. Недавно подобную провокационную дискуссию развернула в Twitter Сара Мей. Конечно, она в ней сразу поднимает несколько трудных тем, и я не во всем с ней согласна, но многие из ее замечаний в точности соответствуют моим ощущениям. Сара заявляет следующее:
Народная мудрость утверждает следующее: прежде, чем зарелизить код, полный набор регрессионных тестов должен стать «зеленым». Необходимо быть уверенным в том, что изменения не поломают чего-нибудь где-то еще в приложении. Но есть способы убедиться в этом, не прибегая к набору регрессионных тестов. Особенно сейчас, с расцветом сложных систем мониторинга и понимани я частоты ошибок на стороне эксплуатации.С достаточно продвинутым мониторингом и большим масштабом реалистичной стратегией становится написание кода, его «пуш» в прод и наблюдение за количеством ошибок. Если в результате что-то в другой части приложения сломается, это станет очень быстро понятно по возросшему количеству ошибок. Вы можете пофиксить проблему или сделать откат. Проще говоря, вы позволяете своей системе мониторинга выполнять ту же роль, что регрессионные тесты и continuous integration в других командах.
Многие люди восприняли это так, будто стоит убрать тестирование перед продакшном вовсе как невостребованное, но я думаю, что идея была не в этом. За этими словами скрывается факт, с которым многие разработчики ПО и профессиональные тестировщики никак не могут смириться — одно только ручное или автоматизированное тестирование зачастую могут быть недостаточными мерами — вплоть до того, что порой они совсем нам не помогают.
В книге «Lessons Learned in Software Testing » (официального перевода на русский язык нет, но есть любительский) есть глава под названием »Автоматизированное тестирование», в которой авторы утверждают, что автоматические регрессионные тесты находят лишь меньшинство багов.
Согласно результатам неофициальных опросов, процент багов, которые обнаруживаются при помощи автоматизированных тестов, на удивление низок. Проекты со значительным количеством удачно спроектированных автоматизированных тестов сообщают, что регрессионные тесты способны обнаруживать 15 процентов от общего количества багов.Автоматизированные регрессионные тесты обычно помогают обнаружить больше багов во время разработки самих тестов, чем при выполнении тестов на последующих этапах. Однако, если вы возьмете ваши регрессионные тесты и найдете способ переиспользовать их в различных окружениях (например, на другой платформе или с другими драйверами), то ваши тесты с большой вероятностью смогут обнаружить проблемы. По факту, в таком случае они уже не являются регрессионными тестами, поскольку они используются для тестирования конфигураций, которые прежде не тестировались. Тестировщики сообщают, что подобная разновидность автоматизированных тестов способна находить от 30 до 80 процентов ошибок.
Книга, безусловно, успела немного устареть, и мне не удалось найти ни одного недавнего исследования насчет эффективности регрессионных тестов, но здесь важен сам факт того, что мы настолько привыкли к тому, что лучшие практики тестирования и дисциплины основаны на безусловном превосходстве автоматизированного тестирования, и любая попытка усомниться приводит к тому, что вас считают еретиком. Если я что-то и уяснила для себя из нескольких лет наблюдений за тем, как отказывают сервисы, то это вот что: тестирование перед продакшном — это наилучшая возможная верификация некоторого небольшого набора гарантий системы, но при этом, его одного будет явно недостаточно, для проверки систем, которые будут работать длительное время и с часто меняющейся нагрузкой.
Возвращаясь к тому, о чем писала Сара:
Эта стратегия строится на многочисленных предположениях; в ее основе лежит то, что в наличии у команды есть сложная система эксплуатации, которой нет у большинства команд разработчиков. И это не все. Предполагается, что мы можем сегментировать пользователей, отображать изменения-в-процессе каждого разработчика на различном сегменте, и также определять частоту ошибок для каждого сегмента. Помимо этого, подобная стратегия предполагает такую продуктовую организацию, которая комфортно чувствует себя при экспериментах с «живым» трафиком.Опять же, если команда уже производит A/B тестирование для изменений в продукте на «живом» трафике, то это просто расширяет саму идею до изменений, сделанных разработчиками. Если у вас получится все это осуществить и получать фидбек на изменения в реальном времени — будет просто замечательно.
Выделение — мое, это, как мне кажется, самый большой блок на пути обретения большей уверенности создаваемых системах. По большей части, самым большим препятствием для перехода к более комплексному подходу в тестировании является необходимый сдвиг в мышлении. Идея привычного тестирования в пре-продакшне прививается программистам с самого начала их карьеры, в то время как идея экспериментирования с «живым» трафиком видится им либо прерогативой инженеров эксплуатации, либо встречей с чем-то страшным вроде аварийной сигнализации.
Все мы с детства приучены к неприкосновенной святости продакшна, с которым нам не положено играться, даже если это лишает нас возможности проверки наших сервисов, и все, что остается на нашу долю — это другие окружения, которые суть есть лишь бледные тени продакшна. Проверка сервисов в средах, «максимально похожих» на продакшн, сродни генеральной репетиции — вроде бы от этого и есть некоторый прок, однако между выступлением в полном зале и пустой комнате есть огромная разница.
Неудивительно, что подобное мнение разделили многие собеседники Сары. Ее ответ им был следующим:
Мне тут пишут: «но ваши пользователи увидят больше ошибок!» Это утверждение прямо-таки состоит из неочевидных заблуждений — я даже не знаю, с чего мне начать…Перенос ответственности за поиск регрессий с тестов на мониторинг в продакшне выльется в то, что пользователи скорее всего будут генерировать больше ошибок в вашей системе. Это означает, что вы не сможете позволить себе применить подобный подход без соответствующего изменения вашей кодовой базы — все должно работать таким образом, чтобы ошибки были меньше заметны (и производили меньший эффект) на ваших пользователей. На самом деле, это такое полезное давление, которое может помочь сделать опыт ваших пользователей значительно лучше. Некоторые пишут мне, что «пользователи сгенерируют больше ошибок» → «пользователи увидят больше ошибок» → «вам плевать на ваших пользователей!» Нет, это абсолютно не так, просто вы думаете неправильно.
Вот это бьет в самую точку. Если мы переносим регрессионное тестирование в мониторинг после продакшна, то такое изменение потребует не просто смены образа мышления, но и готовности принимать риски. Гораздо важнее то, что потребуется полный пересмотр дизайна системы, а также серьезные вложения в продвинутые практики релиз-инжиниринга и инструменты. Другими словами, здесь речь идет уже не просто про архитектуру с учетом сбоев — по сути, здесь идет программирование с учетом сбоев. В то время как золотым стандартом всегда было программирование ПО, которое работает без сбоев. И вот здесь подавляющее большинство разработчиков точно почувствуют себя некомфортно.
Что тестировать в продакшне, а что — в пре-продакшне?
Поскольку тестирование сервисов представлено целым спектром, обе формы тестирования должны быть учтены во время проектирования системы (причем здесь подразумеваются как архитектура, так и код). Это позволит понять, какую функциональность системы обязательно нужно будет протестировать до продакшна, а какие ее характеристики, больше напоминающие длинный хвост из особенностей, лучше исследовать уже в продакшне с применением соответствующих средств и инструментов.
Как определить, где лежат эти границы, и какой метод тестирования подойдет для той или иной функциональности системы? Это должны решать вместе разработка и эксплуатация, и, повторюсь, это должно быть сделано на этапе проектирования системы. Подход «сверху-вниз» в применении к тестированию и мониторингу после этого этапа успел доказать свою несостоятельность.
Hiring an «SRE team» won’t sprinkle some reliability on your services
The top-down approach to reliability and stability hasn’t worked so far.
A bottom-up approach is what’s needed. To achieve that, start preaching to the SWEs instead of playing to the Ops gallery.
— Cindy Sridharan (@copyconstruct) December 12, 2017
Найм «команды SRE» не даст дополнительной надежности вашим сервисам. Подход «сверху-вниз» к надежности и стабильности не работает — здесь нужен подход снизу вверх. Для достижения этих целей вы должны уверовать в SWE вместо того, чтобы продолжать заигрывать с эксплуатацией.
Чарити Мэйджорс выступила в прошлом году с докладом на Strangeloop, где она рассказала о том, что различие между наблюдаемостью и мониторингом сводится к «известным неизвестным» и «неизвестным неизвестным».
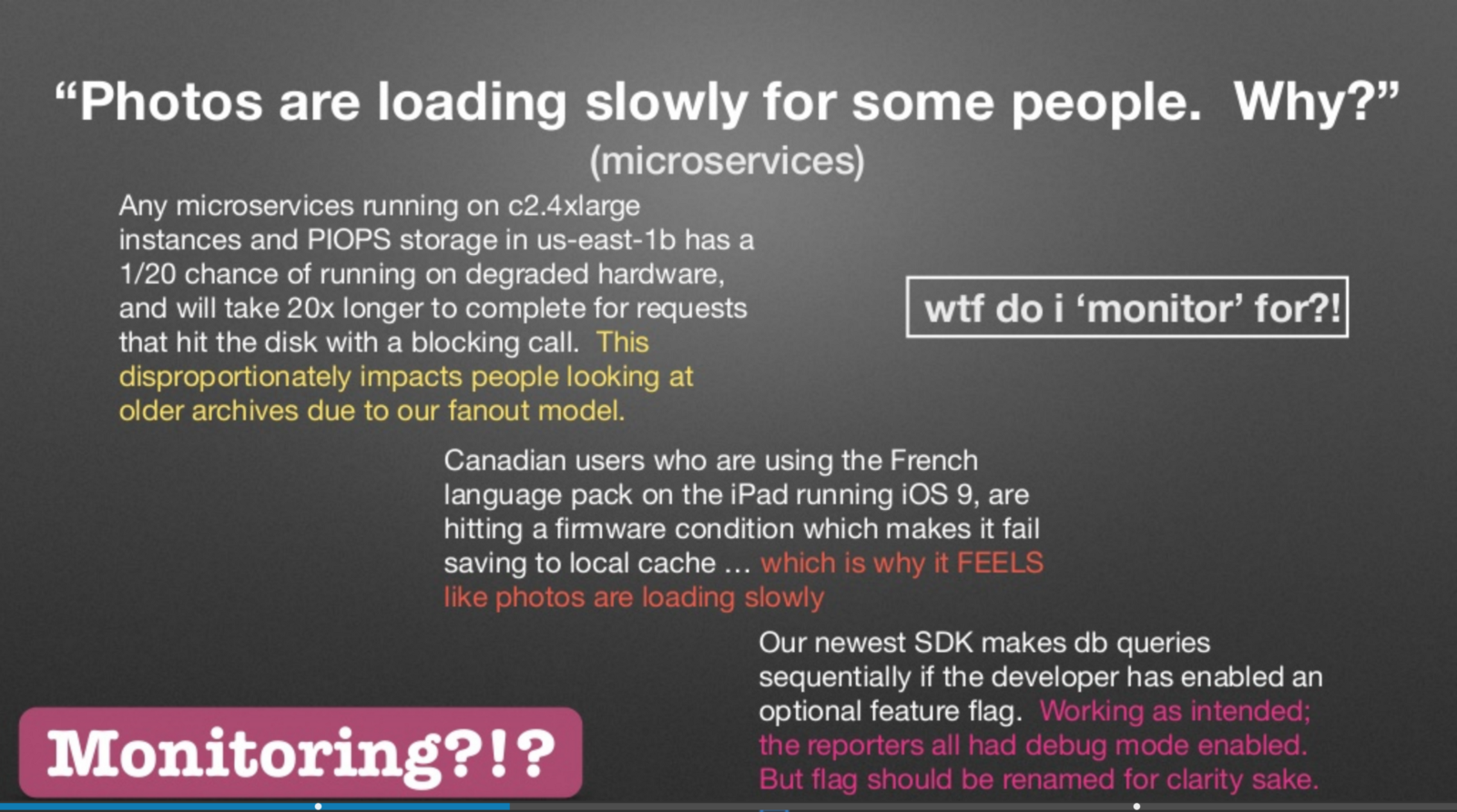
Слайд из доклада Чарити Мэйджорс на Strangeloop в 2017 году
Чарити права — перечисленные на слайде проблемы — это не то, что в идеале вам хотелось бы мониторить. Аналогично, это не те проблемы, которые вам хотелось бы тестировать в пре-продакшне. Распределенные системы патологически непредсказуемы, и невозможно предусмотреть все возможные трясины того болота, в котором могут оказаться различные сервисы и подсистемы. Чем скорее мы смиримся с тем фактом, что сама попытка заранее предугадать каждый способ, которым может быть выполнен сервис, с последующим написанием регрессионного тестового кейса является дурацкой затеей, тем быстрее мы начнем заниматься менее дисфункциональным тестированием.
Как заметил Фред Эбер в своей рецензии на эту статью:
… по мере того, как большой сервис, использующий много машин, растет, увеличиваются и шансы того, что система никогда не будет работоспособной на все 100%. В ней всегда где-то будет происходить частичный сбой. Если тесты требуют 100% работоспособности, то учтите — у вас назревает проблема.
В прошлом, я утверждала, что «мониторинг всего» — это анти-паттерн. Теперь мне кажется, что аналогичное утверждение касается и тестирования. Вы не можете, и поэтому не должны пытаться, протестировать абсолютно все. Книга про SRE утверждает, что:
Оказывается, что после определенной точки, увеличение надежности отрицательно сказывается на сервисе (и его пользователях), вместо того, чтобы делать жизнь лучше! Экстремальная надежность имеет свою цену: максимизация стабильности ограничивает скорость разработки новых функций и скорость предоставления их пользователям, и значительно увеличивает их стоимость, что в свою очередь уменьшает количество функций, которая команда сможет реализовать и предложить пользователям.Наша цель — нащупать явные границы между риском, который возьмет на себя сервис, и риском, который готов нести бизнес. Мы стремимся сделать сервис достаточно надежным, но не более того, чем от нас требуется.
Если вы в цитате выше замените «надежность» на «тестирование», совет от этого не перестанет быть менее полезным.
Однако, настало время задаться следующим вопросом: что лучше подходит для тестирования до продакшна, а что — после?
Исследовательское тестирование не предназначено для тестирования до продакшна
Исследовательское тестирование — это подход к тестированию, который применяется с 80-ых. Практикуют его в основном тестировщики-профессионалы; данный подход требует меньшей подготовки от тестировщика, позволяет находить критические баги и показал себя «более стимулирующим на интеллектуальном уровне, чем выполнение скриптовых тестов». Я никогда не была профессиональным тестировщиком и не работала в организации, в которой есть отдельная команда тестирования, и поэтому узнала про этот вид тестирования лишь недавно.
В уже упоминавшейся книге «Lessons Learned in Software Testing» в главе »Думай, как тестировщик» есть один очень толковый совет, который звучит так: чтобы тестировать, вы должны исследовать.
Чтобы протестировать что-то как следует, вы должны с ним поработать. Вы должны разобраться. Это исследовательский процесс, даже если у вас на руках есть идеальное описание продукта. До тех пор, пока вы не исследуете эту спецификацию, прокрутив ее в своей голове или поработав с самим продуктом, тесты, которые вы решите написать, будут поверхностными. Даже после того, как вы изучите продукт на достаточно глубоком уровне, вам предстоит продолжить исследование уже ради поиска проблем. Поскольку все тестирование представляет собой анализ выборки, и ваша выборка никогда не будет полной, подобный способ мышления позволяет максимизировать пользу от тестирования проекта.Под исследованием мы подразумеваем целенаправленное блуждание — навигацию сквозь пространство с определенной миссией, но без обозначенного пути. Исследование включает в себя обучение и экспериментирование; оно подразумевает бэктрекинг, повторение и другие процессы, которые стороннему наблюдателю могут показаться пустой потерей времени.
Если в приведенной выше цитате вы замените каждое слово «продукт» словом «сервис», то, согласно моим представлениям, это будет максимумом того, чего мы можем добиться с помощью тестирования микросервисов перед продакшном — учитывая то, что по большей части тесты в пре-продакшне бывают крайне поверхностными.
Более того, пусть я и абсолютно согласна со значимостью возможности исследовать сервис, я не думаю, что данную технику следует обязательно применять лишь в фазе релиза перед продакшном. В книге есть дополнительные подробности о том, как включить исследования в свое тестирование:
Исследование — это работа детектива. Это свободный поиск. Думайте об исследовании как о передвижении через пространство. Оно подразумевает прямое, обратное и латеральное мышление. Вы продвигаетесь вперед за счет построения лучших моделей продукта. Эти модели в последующем позволяют вам проектировать более эффективные тесты.Прямое мышление: Двигайтесь в работе от того, что вы хорошо знаете, к тому, чего вы не знаете.
Обратное мышление: Начинайте работу с того, о чем вы подозреваете или имеете некоторое представление, и двигайтесь к тому, что вы знаете, пытаясь подтвердить или опровергнуть свои гипотезы.
Латеральное мышление: Давайте себе отвлекаться от работы на идеи, которые лезут вам в голову, исследуя задачи, связанные с основной «по касательной», после чего возвращайтесь к основной теме.
Возможно, данный вид тестирования действительно необходимо выполнять до релиза при построении систем, критических с точки зрения безопасности, систем, связанных с финансами и, может быть, даже мобильных приложений. Однако, при создании инфраструктурных сервисов метод исследования гораздо лучше подходит для отладки проблем или проведения экспериментов в продакшне;, но вот применение исследования на этапе разработки сервиса можно сравнить с попыткой бежать впереди паровоза.
Это связано с тем, что понимание характеристик производительности сервиса часто приходит после наблюдения за ним в продакшне, а исследование становится гораздо более продуктивным, когда мы проводим его базируясь на каких-либо доказательствах, а не на чистых гипотезах. Также важно заметить, что в отсутствие исключительно опытных и хорошо разбирающихся в эксплуатации разработчиков, которым можно доверить выполнение подобного исследования в продакшне, подобные эксперименты потребуют от вас не только наличие современного инструментария, который обеспечит вам безопасность, но и хорошего понимания между продуктовой и инфраструктурной/эксплуатационной командами.
Вот одна из причин, по которой разработчики и эксплуатация должны тесно работать вместе в пределах организации. Соперничество между ними убивает всю идею. У вас даже не получится начать ее применять, если ответственность за так называемое «качество» повешено на одну из сторон. Определенно возможны и гибридные подходы, в которых небольшие, быстрые наборы тестов пробегают по критическому коду, а все остальное мониторится в проде.Сара Мей
Разработчики должны свыкнуться с идеей тестирования и развития их систем на основании той разновидности точного фидбека, который они могут получить лишь наблюдая за поведением системы в продакшне. Если они будут полагаться исключительно на тестирование до продакшна, то это может сослужить им плохую службу — не только в будущем, но даже и в набирающем распределенные обороты настоящем — в том момент, когда им придется столкнуться с чуть менее тривиальной архитектурой.
Я не считаю, что каждый из нас — инженер эксплуатации. Но вот в чем я точно уверена, так это в том, что эксплуатация — это общая ответственность. Понимание основ того, как работает «железо», позволяет разработчику продвинуться дальше в своем развитии — равно как и понимание того, как сервисы работают в продакшне.
1000% Failure gonna happen. Hell, it may not even be something you did. (I«m looking at you S3zure) The reason is not deployment, the reason is Internets. Unless you put your software in a box you work in ops now. Code accordingly.
— Byron Ellis (@fdaapproved) December 25, 2017
Даю 1000%, что рано или поздно сбой случится. Черт побери, возможно даже, что вы к этому не будете иметь никакого отношения (это я про тебя говорю, S3zure). И причина этого не в деплое — причина в интернете. Если ваше ПО не работает в «коробке», то вы теперь тоже работаете в Ops. Пишите ваш код соответствующим образом.
Разработчики должны научиться писать (и тестировать!) код соответствующим образом. Впрочем, подобное заявление можно считать поверхностным; давайте все-таки определимся, что же это скрывается под предложением «писать код соответствующим образом».
По моему мнению, все сводится к трем основным принципам:
- пониманию эксплуатационной семантики приложения;
- пониманию эксплуатационные характеристик зависимостей;
- написанию отлаживаемого кода.
Эксплуатационная семантика приложений
Это понятие предполагает написание кода, во время которого вы озадачиваетесь следующими вопросами:
- как осуществляется деплой сервиса, с помощью каких инструментов;
- сервис забинден на порт 0 или на стандартный порт?
- как приложение обрабатывает сигналы?
- как стартует процесс на выбранном хосте;
- как сервис регистрируется в service discovery?
- как сервис обнаруживает апстримы?
- как сервису отключают коннекты, когда он собирается завершиться;
- должен ли производиться graceful restart или нет;
- как конфиги — статические и динамические — скармливаются процессу;
- модель конкурентности приложения (многопоточное, или чисто однопоточное, event driven, или на акторах, или гибридной модели);
- каким образом реверс-прокси на фронте приложения держит соединения (пре-форк или потоки или процессы).
Во многих компаниях принято считать, что эти вопросы нужно снимать с плеч разработчиков и перекладывать на платформы или станд
