[Перевод] Terraform для инженерии данных
 Если перед нами стоит задача построить надёжную платформу для работы с данными, то для неё требуется предусмотреть множество компонентов: инструменты, логику обработки данных, методологии, архитектуру и инфраструктуру. Что касается инфраструктуры, здесь есть самые разные варианты: физические серверы на территории предприятия и облачные решения. Основное внимание в этом посте будет уделено эффективному использованию облачной инфраструктуры на базе Microsoft Azure.
Если перед нами стоит задача построить надёжную платформу для работы с данными, то для неё требуется предусмотреть множество компонентов: инструменты, логику обработки данных, методологии, архитектуру и инфраструктуру. Что касается инфраструктуры, здесь есть самые разные варианты: физические серверы на территории предприятия и облачные решения. Основное внимание в этом посте будет уделено эффективному использованию облачной инфраструктуры на базе Microsoft Azure.
В облачной инфраструктуре вам на выбор предлагаются виртуальные машины (инфраструктура как услуга — IaaS) или бессерверные службы, такие как Azure SQL и Databricks. Мне кажется, что бессерверные сервисы не только обеспечивают гибкость, но и упрощают и конфигурирование системы, и её техническую поддержку. В этой статье будут показаны сильные стороны Terraform, надёжного инструмента для обслуживания инфраструктуры на уровне кода (IaaC). При помощи Terraform можно без труда обустроить облачную платформу для работы с данными.
При помощи Terraform можно прописывать инфраструктуру как код — это гораздо удобнее, чем конфигурировать ресурсы через Azure Portal. Храня всю конфигурацию системы в базе кода, которая поддаётся управлению через Git-репозиторий, можно реплицировать нужные варианты конфигурации в разных окружениях и бесшовно интегрировать эти конфигурации в конвейеры DevOps. Этот подход идеально сочетается с современными паттернами непрерывной интеграции /непрерывного развёртывания (CI/CD).
В этой статье мы сосредоточимся на построении базовой платформы для обработки данных, в которую инкорпорируем все важнейшие сервисы Azure: Storage Account, Key Vault, Databricks, Azure Synapse, and Azure Data Factory (ADF). На примере Terraform я продемонстрирую, как, допустим, держать секреты в хранилище ключей Key Vault, как развертывать ноутбуки и конвейеры, монтировать аккаунты для хранения данных в кластере Databricks, управлять безопасностью, а также как всё это бесшовно автоматизировать.
Terraform
Terraform — это инструмент для автоматизации облачной инфраструктуры и управления ею. С его помощью можно прописать всю инфраструктуру в коде, а затем поддерживать эти ресурсы на различных облачных платформах, в частности, AWS, Azure и Google Cloud. При таком подходе предоставление инфраструктуры и управление ею легко эффективно организовать и воспроизводить.
Вот самые важные элементы сценария Terraform:
Провайдеры
При помощи провайдеров Terraform может взаимодействовать с облаками, поставщиками SaaS и другими API. Кроме того, во всех конфигурациях Terraform следует объявлять, какие провайдеры для них требуются, чтобы Terraform мог их установить и использовать.
required_providers {
azurerm = {
source = "hashicorp/azurerm"
version = "3.37.0"
}
}
provider "azurerm" {
features {}
}Источники данных
Благодаря источникам данных Terraform может пользоваться информацией, определённой вне Terraform. В следующем примере он считывает информацию о конфигурации Azure (например, tenant_id, client_id, т.д.) и узнает service principal.
data "azurerm_client_config" "current" {
}
data "azuread_service_principal" "this" {
display_name = "sp-mk-test"
}Ресурсы
Ресурсы — это важнейший элемент языка Terraform. В каждом ресурсном блоке описаны один или более инфраструктурных объектов, например, аккаунт для хранения данных, рабочее пространство Synapse или более высокоуровневые компоненты, например, записи DNS.
# Azure Data Factory
resource "azurerm_data_factory" "adf_transform" {
resource_group_name = var.resource_group
location = var.region
name = "mk-${var.project}-adf01"
identity {
type = "SystemAssigned"
}
}
Переменные
В Terraform есть несколько типов переменных, при помощи которых удобно управлять кодом и кастомизировать его. Когда вы объявляете переменные в корневом модуле вашей конфигурации, можно установить их значения при помощи опций интерфейса командной строки (CLI) и переменных окружения. Если определяете их в дочерних модулях, то родительский модуль должен сам передать значения в блоке этого модуля. Модули Terraform можно сравнить с определениями функций:
- Вводные переменные подобны аргументам функций,
- Выходные значения подобны возвращаемым значениям функций,
- Локальные значения сравнимы с временными локальными переменными, используемыми в функции.
Как показано в следующем примере, при помощи переменных можно указывать в инфраструктуре группу ресурсов, а также регионы Azure.
variable "region" {
type = string
}
variable "resource_group" {
type = string
}Модули
Модули — это контейнеры, в которых содержатся ресурсы, используемые вместе. В Terraform есть модули двух типов:
- Корневой модуль: у каждого скрипта Terraform есть минимум один модуль, и он называется корневым. В его состав входят ресурсы, определённые в файлах .tf.
- Дочерние модули: их можно сравнить с функциями, содержащими определения ресурсов, входные и выходные переменные. Внутри корневого модуля дочерние модули можно вызывать многократно.
Строим платформу данных
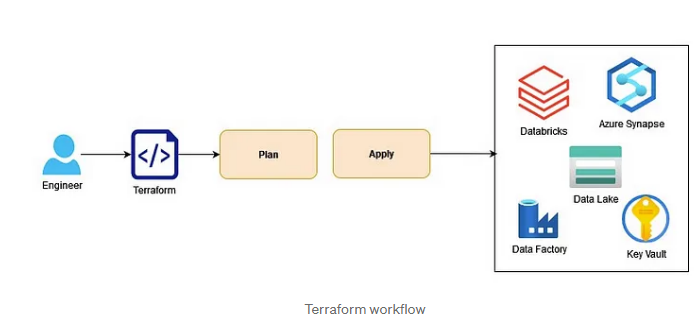
Установка и конфигурирование Terraform
В этом разделе будет рассказано, как при помощи Terraform создать жизненно важные компоненты для платформы с данными. Чтобы приступить к работе с Terraform, его нужно скачать с официального сайта. Скачав файлы, сохраните их в специально подготовленной папке «terraform». Обязательно добавьте расположение этой папки в вашу переменную окружения PATH, чтобы обращаться к этой папке можно было легко и быстро. Кроме того, вам потребуется установить интерфейс командной строки Azure и через него аутентифицировать вашу подписку Azure при помощи az login.
В рамках подписки Azure принципиально важно создать первичное имя сервиса (service principal), которое будет использоваться в Databricks, а также выделенную группу ресурсов. Когда справитесь с этими первыми шагами, клонируйте мой репозиторий. После этого откорректируйте файл «test.tfvar» так, чтобы он соответствовал именно вашим требованиям.
После этого запустите Terraform в каталоге вашего проекта. Затем, наконец, выполните сценарий Terraform. Эти щаги послужат основой для эффективной сборки вашей платформы данных.
# test.tfvar
resource_group = "mk-test"
region = "West Europe"
client_id = "xxxx" # Service principal client id
object_id = "xxx"# Service principal object id
secrete = "xxx"# Service principal secrete
project = "az" # Project name
acr_enable = false
Аутентифицируем подписку Azure: 
Инициализируем Terraform: 
Применяем Terraform: 
На первом шаге можно выполнить terraform plan, чтобы предварительно просмотреть те ресурсы, что будут созданы. Как вариант, можно выполнить terraform apply для предпросмотра изменений, а когда появится приглашение — ввести в эту строку слово 'yes'.
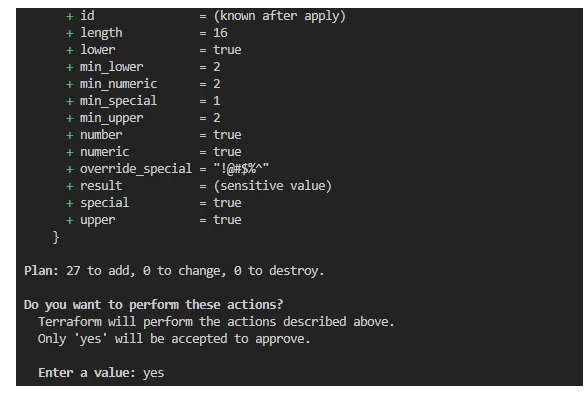
После того, как Terraform завершит работу, на экране должен быть выведен следующий результат.
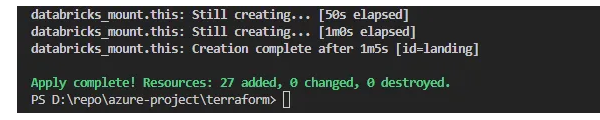
Удостовериться, что всё прошло правильно, можно на портале Azure.
Обзор сценария Terraform
Ниже в качестве примера ресурса разобран аккаунт от хранилища данных, присутствующий в нашем сценарии Terraform. Тип ресурса указываем как azurerm_storage_account и называем его datalake. Внутри блока видим детали, описывающие конфигурацию аккаунта для хранения данных. Обратите внимание: для передачи важнейших параметров (например, имени группы ресурсов, региона Azure) я пользуюсь переменными. Имя собирается на основе переменной project_name.
resource "azurerm_storage_account" "datalake" {
name = "mk${var.project}sa001"
resource_group_name = var.resource_group
location = var.region
account_kind = "StorageV2"
account_tier = "Standard"
account_replication_type = "LRS"
access_tier = "Hot"
enable_https_traffic_only = true
is_hns_enabled = true
network_rules {
default_action = "Allow"
bypass = ["Metrics"]
}
identity {
type = "SystemAssigned"
}
}
В рамках того же файла main.tf вы найдёте определения, при помощи которых создаются контейнеры аккаунтов хранилища и создаётся первичное имя сервиса для роли контрибьютора больших двоичных объектов. В данном примере мы увидим, как используется свойство for_each, при помощи которого из единственного ресурса Terraform можно создать четыре контейнера.
resource "azurerm_storage_container" "container" {
for_each = toset( ["landing","bronze", "silver", "gold"] )
name = each.key
storage_account_name = azurerm_storage_account.datalake.name
}
resource "azurerm_role_assignment" "data_contributor_role" {
scope = azurerm_storage_account.datalake.id
role_definition_name = "Storage Blob Data Contributor"
principal_id = data.azuread_service_principal.this.object_id
}
Когда при помощи Terraform создаётся хранилище ключей Azure Key Vault, далее можно бесшовно устанавливать политики для пользователей и хранить конфиденциальные значения. Также мы рассмотрим, как при помощи ресурсов данных извлекать наиболее важные параметры, например, ID клиента (tenant ID) и ID первичного имени сервиса как объекта. Располагая возможностями Terraform, можно эффективно управлять конфигурациями хранилища ключей Azure, обеспечивая безопасный и оптимизированный процесс обращения с секретной информацией.
# Key Vault
resource "azurerm_key_vault" "kv" {
name = "mk-${var.project}-kv002"
resource_group_name = var.resource_group
location = var.region
sku_name = "standard"
tenant_id = data.azurerm_client_config.current.tenant_id
}
# Key Vault police
resource "azurerm_key_vault_access_policy" "sp" {
key_vault_id = azurerm_key_vault.kv.id
tenant_id = data.azurerm_client_config.current.tenant_id
object_id = data.azuread_service_principal.this.object_id
secret_permissions = ["Get", "List", "Set", "Delete"]
depends_on = [ azurerm_key_vault.kv]
}
# Key Vault secrete
resource "azurerm_key_vault_secret" "secrete_id" {
name = "secreteid"
value = var.secrete
key_vault_id = azurerm_key_vault.kv.id
depends_on = [azurerm_key_vault_access_policy.user]
}
Terraform предоставляет надёжные возможности автоматизации для развёртывания Databricks. При помощи Terraform можно без труда смонтировать аккаунт для хранения данных, создавать кластеры и развёртывать ноутбуки, выравнивать процессы конфигурирования ресурсов и управления ими в вашем окружении Databricks.
# Развёртывание ноутбука
resource "databricks_notebook" "this" {
path = "/Shared/test/test"
language = "PYTHON"
source = "./test.py"
}
# Монтирование
resource "databricks_mount" "this" {
name = "landing"
cluster_id = databricks_cluster.this.id
uri = "abfss://${azurerm_storage_container.container["landing"].name}@${azurerm_storage_account.datalake.name}.dfs.core.windows.net"
extra_configs = {
"fs.azure.account.auth.type" : "OAuth",
"fs.azure.account.oauth.provider.type" : "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id" : var.client_id,
"fs.azure.account.oauth2.client.secret" : "${var.secrete}", # here should be secrete scoup
"fs.azure.account.oauth2.client.endpoint" : "https://login.microsoftonline.com/${data.azurerm_client_config.current.tenant_id}/oauth2/token",
"fs.azure.createRemoteFileSystemDuringInitialization" : "false",
}
depends_on = [
databricks_cluster.this,
azurerm_role_assignment.data_contributor_role,
azurerm_storage_container.container
]
}
В приведённом коде продемонстрировано, как используются ссылки на другие ресурсы, в частности, на аккаунт для хранения данных и контейнер. Опираясь на тип и имя ресурса, можно обращаться к таким свойствам как имя или ID кластера. Кстати, в этом коде наглядно показано свойство depend_on, позволяющее определять зависимости и обеспечивать создание ресурсов в правильном порядке.
Когда работа построена таким образом, Terraform приступает к монтированию только после того, как будут созданы кластеры, контейнеры и роли. Тем самым обеспечивается бесшовный и синхронизированный процесс развёртывания.
Конвейеры Azure Data Factory традиционно развёртываются с применением Azure DevOps, и хорошая альтернатива при этом — именно Terraform. При таком подходе приобретается значительная гибкость, хотя и требуется вставлять в файл код JSON, скопированный из Azure Data Factory Studio. Работая с Terraform, можно не только развёртывать конвейеры, но и создавать связанные сервисы. Получается многостороннее решение для управления конфигурациями Azure Data Factory.
resource "azurerm_data_factory_pipeline" "databricks_pipe" {
name = "databricks_pipeline"
data_factory_id = azurerm_data_factory.adf_transform.id
description = "Databricks"
depends_on = [
databricks_cluster.this,
azurerm_data_factory_linked_service_azure_databricks.at_linked
]
activities_json = <
Наконец, познакомлю вас с ресурсом Azure Synapse, который можно создать при помощи сценария. В коде продемонстрировано, как сгенерировать пароль, безопасно сохранить его в Azure Key Vault и передать как параметр в конфигурацию Azure Synapse. Безопасность так только повышается, поскольку мы обходимся без передачи пароля в переменных и не допускаем, чтобы его совместно использовали разные люди.
# генератор паролей
resource "random_password" "sql_administrator_login_password" {
length = 16
special = true
override_special = "!@#$%^"
min_lower = 2
min_upper = 2
min_numeric = 2
min_special = 1
}
# сохраняем в хранилище ключей
resource "azurerm_key_vault_secret" "sql_administrator_login" {
name = "synapseSQLpass"
value = random_password.sql_administrator_login_password.result
key_vault_id = azurerm_key_vault.kv.id
content_type = "string"
expiration_date = "2111-12-31T00:00:00Z"
depends_on = [
azurerm_key_vault.kv,
azurerm_key_vault_access_policy.user
]
}
# Azure Synapse
resource "azurerm_synapse_workspace" "this" {
name = "mk${var.project}syn001"
resource_group_name = var.resource_group
location = var.region
storage_data_lake_gen2_filesystem_id = azurerm_storage_data_lake_gen2_filesystem.sym.id
sql_administrator_login = "mariusz"
sql_administrator_login_password = azurerm_key_vault_secret.sql_administrator_login.value
identity {
type = "SystemAssigned"
}
depends_on = [
azurerm_storage_account.datalake,
azurerm_key_vault_secret.sql_administrator_login
]
}Итоги
В этом посте было рассказано, как при помощи Terraform можно развёртывать компоненты вашей платформы для работы с данными. Данная простейшая конфигурация показывает, что работать с Terraform вполне не сложно, и при этом Terraform способствует автоматизации разработки и процессов CI/CD. Можно взять сценарий с локальной машины или из конвейера DevOps, и на основе этой информации выстраивать более детализированные конвейеры. При помощи этих конвейеров удобно собирать инфраструктуру, тестировать её и автоматизировать ввод изменений в производство, без какого-либо ручного вмешательства. Ещё раз подчеркну, что представленные примеры максимально просты, ими можно пользоваться на небольшой платформе. Но, если требуется решать задачи уровня большого предприятия, то также понадобится наладить сетевую конфигурацию, которая позволит предохранить ваше окружение от нежелательного доступа извне.
