[Перевод] Строим OCR-ферму на базе айфонов для скрапинга мемов в Интернете
Каждый, кто провел какое-то время в Интернете хорошо представляет насколько популярным стало использование мемов в онлайне. Находить новые мемы о последних событиях и делиться ими с друзьями, — это мое давнее времяпрепровождение.
Большинству мемов свойственна ироническая двойственность: чем более они нишевые, тем более забавными они кажутся. Некоторые из лучших мемов — это просто глупые шутки между моими друзьями или из невероятно нишевой индустрии информационной безопасности.
Это представляло чрезвычайно распространенную проблему: я постоянно не мог найти нужные мемы, который хотел бы отправить, когда они мне больше всего были нужны. Найти нужный мем в середине разговора — практически невозможная задача. Прокрутка сотен сохраненных изображений в телефоне, как оказалось, не самый эффективный поиск, поэтому я решил попытаться решить проблему иначе.
Реализация OCR
Предыдущие попытки написать механизм поиска мемов в конечном итоге привели к одной основной проблеме: отсутствию масштабируемого OCR. Все существующие решения были либо крайне плохи в распознавании искаженного и сильно разнообразного текста большинства мемов, либо были непомерно дорогими.
Например, Tesseract OCR — это бесплатная библиотека с открытым исходным кодом для извлечения текста из изображений. При тестировании с этой библиотекой она нормально распознавала мемы с очень стандартными шрифтами и цветовыми схемами:

Пример простого для OCR-распознавания мема, результат Tesseract: i'm supposed to feel refreshed after waking up from a nap but instead i end up feeling like this
However, remixing, watermarking, and resharing of memes makes their format anything but standard. Take the following meme, for example:
Однако фотошоп, водяные знаки и решеринг мемов делают их формат совсем не стандартным. Возьмем, к примеру, следующий мем:

Tesseract распознает этот мем как: 30 BLUE man41;? S4-5?'flew/ — V [IL ' . ",2; g" .'Sj /B"f;T"EArmDand [red] mvslmunlm: sawmills.
Это мало похоже на то, как мог бы сказать человек. Казалось, что у меня есть варианты либо с дорогими облачными сервисами OCR, либо с такими неэффективными решениями.
Однако однажды ночью я понял, когда пытался отправить кому-то пример изображения CAPTCHA старой школы на своем iPhone:
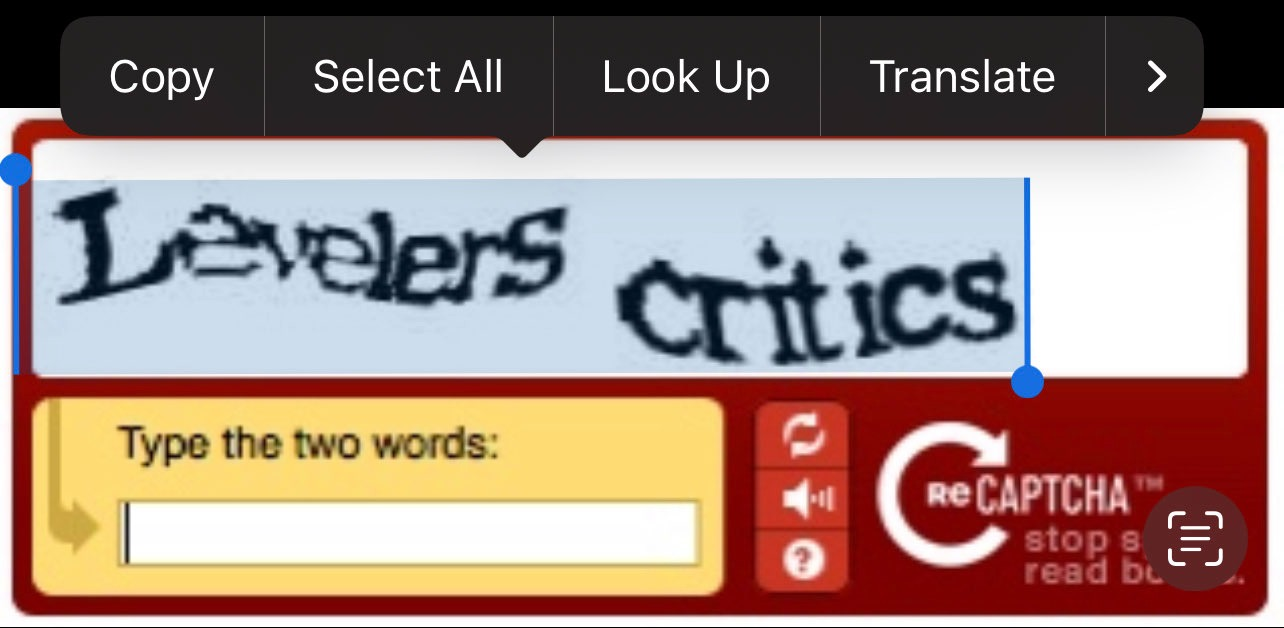 Случайно выбранный обфусцированный текст на reCAPTCHA предыдущего поколения.Случайно выбранный обфусцированный текст на reCAPTCHA предыдущего поколения.
Случайно выбранный обфусцированный текст на reCAPTCHA предыдущего поколения.Случайно выбранный обфусцированный текст на reCAPTCHA предыдущего поколения.
К моему удивлению, iOS была легко выделила намеренно зашифрованный и искаженный текст капчи. Что еще более удивительно, она отлично расшифровала текст:
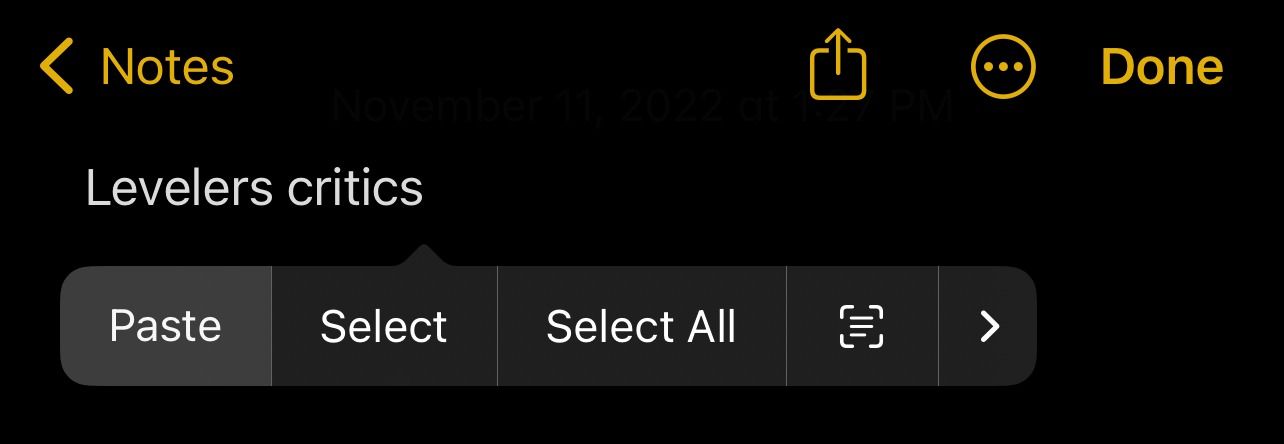 Скопированный текст из reCAPTCHA.Скопированный текст из reCAPTCHA.
Скопированный текст из reCAPTCHA.Скопированный текст из reCAPTCHA.
Если она хорошо справляется с намеренно запутанными текстовыми изображениями, что было бы с различными форматами, в которых представлено большинство мемов? После тестирования OCR на куче сохраненных мемов в моем телефоне ответ был «очень хорошо».
Еще лучше то, что после небольшого поиска в Google я обнаружил, что эта функциональность представлена в iOS Vision Framework. Это означает, что это OCR может быть полностью автоматизировано в виде специального приложения для iOS. Наконец-то появилось масштабируемое решение проблемы, с которой я столкнулся!
Дешевое и масштабируемое OCR для миллиона мемов
Хотя я написал много кода, я никогда не писал ничего серьезного на Swift или Objective C. Мне не удалось найти плагины Vision Framework для Apache Cordova, поэтому я не мог просто написать приложение на JavaScript. Похоже, пришло время стиснуть зубы и написать сервер OCR для iOS на Swift.
Объединив мощь интенсивного поиска в Google, обратного проектирования различных репозиториев Swift на Github и случайного вопроса Xcode моему другу iOS, я смог собрать работающее решение:
 Очень простой iOS Vision OCR сервер, запущенный на iPhone.
Очень простой iOS Vision OCR сервер, запущенный на iPhone.
Предварительные тесты скорости были довольно медленными на моем Macbook. Однако, как только я развернул приложение на реальном iPhone, скорость OCR была чрезвычайно многообещающей (возможно, из-за того, что фреймворк Vision использует GPU). Затем я смог выполнить чрезвычайно точное распознавание тысяч изображений в кратчайшие сроки, даже на бюджетных моделях iPhone, таких как SE 2-го поколения.
В целом сервер API, построенный поверх GCDWebServer, работал довольно хорошо, но имел небольшую утечку памяти. После 20K-40K изображений, обработанных OCR, приложение обычно аварийно завершало работу, что довольно сильно раздражало. Опять же, мое знакомство со Swift было примерно на уровне понимания финансов золотистого ретривера, поэтому отладка проблемы оказалась довольно сложной. Изучив более «хакерские» варианты, я понял, что могу использовать «Управляемый доступ» на iOS для автоматического перезапуска приложения при его сбое. По сути, он работал как демон, чтобы гарантировать, что сервер OCR будет продолжать обслуживать запросы, а также защищать от других неизвестных сбоев из-за поврежденных изображений, останавливающих конвейер.
Полнотекстовый поиск на ElasticSearch
Теперь, когда появился способ правильно извлечь текст из всех изображений мемов, проблема заключалась в том, как быстро искать в огромном массиве текстов. Первоначальное тестирование с функцией индексирования полнотекстового поиска Postgres оказалось неприемлемо медленным при масштабировании любого изображения, превышающего миллион, даже при выделении соответствующих аппаратных ресурсов.
Я решил попробовать ElasticSearch, так как он специально создан именно для этой проблемы. После чтения документации, раннего тестирования и чтения сообщений в блогах о реальном использовании я пришел к некоторым выводам о его реализации для моего варианта использования:
ElasticSearch очень требователен к оперативной памяти и системным ресурсам, особенно при работе с несколькими узлами. Наличие нескольких узлов обеспечивает устойчивость к сбоям в случае их возникновения, что является обычным явлением в любой распределенной системе.
Я мог запустить ElasticSearch в кластере с одним узлом, поскольку объединенный текст даже миллионов мемов все еще был сравнительно небольшим для обычного кейса использования ElasticSearch. Это было бы экономически выгодно, но, конечно, за счет надежности.
Поскольку я использовал Postgres для остальных структурированных данных для мемов (например, контекст, источник и т. д.), сохранение текста мема в ElasticSearch беспокоило меня тем, что это могло бы исказить парадигму «единственного источника правды». По прошлому опыту, необходимость убедиться, что два источника правды совпадают, может быть источником чрезвычайной сложности и головной боли.
Выполнив поиск, я обнаружил, что могу использовать PGSync для автоматической синхронизации выбранных столбцов Postgres с ElasticSearch. Это казалось отличным компромиссом для сохранения единого источника достоверной информации (Postgres) и экономичного запуска ElasticSearch в конфигурации с одним узлом. Если бы произошла потеря данных, я мог бы снести ElasticSearch, а PGSync позволил бы мне легко перестроить индекс текстового поиска.
У ElasticSearch было огромное количество настроек для текстового поиска и полный REST API, позволяющий мне легко интегрировать его в мой сервис.
Мой окончательный дизайн выглядел примерно так:
 Крайне бессистемная схема финальной реализации
Крайне бессистемная схема финальной реализации
Тестирование сгенерированных наборов данных показало, что он действительно хорошо масштабируется, позволяя искать миллионы мемов менее чем за секунду даже на относительно скромном оборудовании. На момент написания этой статьи я могу индексировать и искать текст примерно в 17 миллионах мемов на общем экземпляре Linode всего с 6 ядрами и 16 ГБ ОЗУ. Это удерживает затраты на относительно низком уровне, что важно для pet проектов, если вы намерены поддерживать их работу в течение любого периода времени.
Видео-мемы, ffmpeg, и OCR
Как оказалось, мемы — это не только изображения. Многие мемы теперь представляют собой видео с аудиодорожками. Это, без сомнения, связано с улучшениями в мобильных сетях, позволяющими быстро доставлять большие файлы. В некоторых случаях, таких как GIF, видео даже лучше, потому что они имеют гораздо лучшее сжатие и, следовательно, могут быть намного меньше по размеру.
Чтобы проиндексировать мемы этого типа, видео нужно было разбить на наборы скриншотов, которые затем распознавались как обычные мемы. Чтобы решить эту проблему, я написал небольшой микросервис, который делает следующее:
Апгрейд iPhone OCR фермы до OCR кластера
Неудивительно, что это значительно увеличило нагрузку на службу OCR. Для каждого видеомема требовалось в 10 раз больше работы по распознаванию текста. Несмотря на скорость сервера приложений OCR, это стало основным узким местом, в конечном итоге я решил обновить службу OCR iOS до кластера:
 Не волнуйтесь, есть вентилятор, который их охлаждает.
Не волнуйтесь, есть вентилятор, который их охлаждает.
Эта установка выглядит довольно дорого из-за большого количества используемых iPhone. Тем не менее, есть некоторые вещи, которые сыграли в мою пользу, чтобы сделать это намного дешевле, чем вы ожидаете:
Поскольку они предназначены для распознавания текста через iOS Vision API, я мог бы использовать более старые (и более дешевые) модели iPhone, такие как iPhone SE (2-го поколения).
У меня есть преимущество, так как я не забочусь о таких вещах, как трещины на экране, царапины и другие косметические проблемы, что еще больше снижает стоимость.
Более того, я даже не хочу использовать их в качестве телефонов, поэтому даже iPhone с заблокированным IMEI или привязанным к непопулярным сетям вполне подходят для моего использования.
Принимая во внимание все эти факторы, я смог найти iPhone по значительно более низкой цене. Например, вот товар, который соответствует моим критериям и вполне доступен:
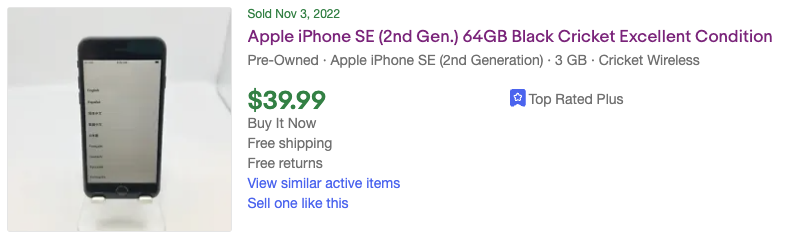 Этот телефон, вероятно, стоил всего 40 долларов, потому что он был привязан к непопулярному американскому оператору связи (Cricket), и поэтому большинство людей не хотели бы связываться с ним.
Этот телефон, вероятно, стоил всего 40 долларов, потому что он был привязан к непопулярному американскому оператору связи (Cricket), и поэтому большинство людей не хотели бы связываться с ним.
В любом случае, как эти затраты соотносятся с облачными сервисами OCR? GCP Cloud Vision API взимает с вас 1,50 доллара США за каждую тысячу изображений, которые вы распознаете. Это означает, что, используя это самодельное решение, мы окупим стоимость iPhone после ~27 тыс. изображений. Конечно, возможно, служба OCR GCP намного качественнее, но в моем тестировании результаты оказались очень сопоставимыми для этого варианта использования. Попытка использовать Cloud API в масштабе десятков миллионов запросов OCR и затрат была бы непомерно высокой для этого проекта.
Внимательно следя за аукционами eBay, я купил все iPhone, которые продавались по такой низкой цене. Используя старый Raspberry Pi, который был у меня дома, я настроил его для работы в качестве балансировщика нагрузки Nginx для равномерного распределения запросов между iPhone. Добавив немного сети и дешевый вентилятор для охлаждения, я получил работающий OCR кластер, который мог легко справиться с гораздо большей нагрузкой.
Окончательная (сложная) архитектура
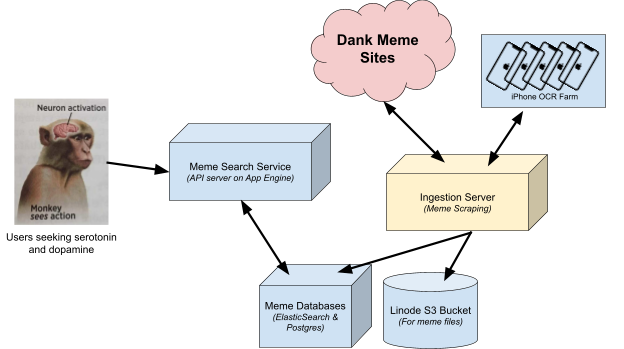
Окончательная архитектура выглядит примерно так, как показано на диаграмме выше. Несмотря на то, что из-за моей оптимизации стоимости определенно есть некоторая дополнительная сложность, более дешевая инфраструктура позволит мне держать этот pet проект работающим гораздо дольше.
В целом это был забавный проект с бонусом в виде большого количества личной пользы. Я много узнал о различных темах, включая настройку ElasticSearch, разработку приложений для iOS и немного о машинном обучении. В будущих постах я надеюсь подробно рассказать о некоторых других функциях, которые я создал для него, включая такие вещи, как:
«Поиск по изображению»/«Сходство изображений» поиск в масштабе миллионов мемов.
Автоматическое обнаружение и маркировка мемов NSFW.
Создание инфраструктуры парсинга для фактического индексирования всех мемов.
Если вы хотите попробовать, зайдите на сайт https://findthatmeme.com и дайте мне знать, что вы думаете!
Автор оригинального текста: @IAmMandatory
