[Перевод] Стек DOTS: C++ & C#

Это краткое введение в наш новый дата-ориентированный технологический стек (DOTS). Мы поделимся некоторыми инсайтами, помогающими понять, как и почему Unity сегодня стала именно такой, а также расскажем, в каком направлении планируем развиваться. В дальнейшем мы планируем публиковать в блоге Unity новые статьи о DOTS.
Давайте поговорим о C++. Это язык, на котором написана современная Unity.
Одна из наиболее сложных проблем разработчика игр, с которой так или иначе приходится иметь дело, такова: программист должен предоставить исполняемый файл с инструкциями, понятными целевому процессору и, когда процессор выполнит эти инструкции, должна запуститься игра.
В той части кода, которая чувствительна к производительности, мы заранее знаем, каковы должны быть конечные инструкции. Нам всего лишь нужен простой путь, позволяющий непротиворечиво описать нашу логику, а затем проверить и убедиться, что сгенерированы именно те инструкции, которые нам нужны.
Мы считаем, что язык C++ не слишком хорош для этой задачи. Например, я хочу, чтобы мой цикл был векторизован, но может найтись миллион причин, по которым компилятору не удастся его векторизовать. Либо сегодня он векторизуется, а завтра — нет, из-за какого-то, казалось бы, пустякового изменения. Сложно даже убедиться, что все мои компиляторы C/C++ вообще станут векторизовывать мой код.
Мы решили разработать наш собственный «вполне удобный способ генерации машинного кода», который отвечал бы всем нашим пожеланиям. Можно было бы потратить массу времени, чтобы немножечко изогнуть всю последовательность проектирования на C++ в нужном нам направлении, но мы решили, что гораздо разумнее инвестировать силы в разработку тулчейна, который бы полностью решал все встающие перед нами проблемы проектирования. Мы же разработали бы его с учетом именно тех задач, которые приходится решать разработчику игр.
Каким же факторам мы уделяем первостепенное внимание?
- Производительность = правильность. У меня должна быть возможность сказать: «если этот цикл по какой-то причине не векторизуется, то это, должно быть, ошибка компилятора, а не ситуация из разряда «ой, код стал работать всего в восемь раз медленнее, но по-прежнему выдает верные значения, делов-то!».
- Кросс-платформенность. Входной код, который я пишу, должен оставаться совершенно одинаковым независимо от целевой платформы — будь то iOS или Xbox.
- У нас должен быть аккуратный цикл итераций, в котором я легко могу просмотреть машинный код, генерируемый для любых архитектур по мере того, как я меняю мой исходный код. «Просмотрщик» машинного кода должен хорошо помогать с обучением/объяснением, когда требуется разобраться, что же делают все эти машинные инструкции.
- Безопасность. Как правило, разработчики игр не ставят безопасность на высокие позиции в своем списке приоритетов, но мы считаем, что одна из самых классных черт Unity — в ней действительно очень сложно повредить память. Должен быть такой режим, в котором мы запускаем любой код — и однозначно фиксируем ошибку, по которой большими буквами выводится сообщение о том, что же здесь произошло: например, я вышел за границы при считывании/записи или попытался разыменовать нуль.
Итак, разобравшись, что же для нас важно, перейдем к следующему вопросу: на каком языке лучше писать программы, из которых затем будет генерироваться такой машинный код? Допустим, у нас есть следующие варианты:
- Собственный язык
- Некоторая адаптация/подмножество C или C++
- Подмножество C#
Что-что, C#? Для наших внутренних циклов, производительность которых особенно критична? Да. C# — совершенно естественный выбор, с которым в контексте Unity связано множество очень приятных вещей:
- Это язык, с которым уже сегодня работают наши пользователи
- В нем отлично оснащена IDE, как для редактирования/рефакторинга, так и для отладки.
- Уже существует компилятор, преобразующий C# в промежуточный IL (речь о компиляторе Roslyn для C# от Microsoft), и можно попросту воспользоваться им, а не писать собственный. У нас богатый опыт преобразования промежуточного языка в IL, поэтому нам просто выполнять генерацию кода и постпроцессинг конкретной программы.
- C# лишен многих проблем C++ (ад с включением заголовков, паттерны PIMPL, продолжительное время компиляции)
Мне самому весьма нравится писать код на C#. Однако традиционный C# — не самый лучший язык с точки зрения производительности. Команда разработчиков C#, команды, отвечающие за стандартную библиотеку и среду исполнения за последние пару лет достигли огромного прогресса в этой области. Тем не менее, работая с C#, невозможно контролировать, где именно в памяти размещаются ваши данные. А именно эту проблему нам и необходимо решить для повышения производительности.
Вдобавок, стандартная библиотека этого языка организована вокруг «объектов в куче» и «объектов, имеющих ссылки-указатели на другие объекты».
При этом, работая с фрагментом кода, в котором критична производительность, можно почти полностью обойтись без стандартной библиотеки (прощайте Linq, StringFormatter, List, Dictionary), запретить операции выделения (=никаких классов, только структуры), рефлексию, отключить сборщик мусора и виртуальные вызовы, а также добавить несколько новых контейнеров, которые разрешено использовать (NativeArray и компания). В таком случае, оставшиеся элементы языка C# выглядят уже очень хорошо. Примеры посмотрите в блоге Араса, где он описывает кустарный проект трассировщика путей.
Такое подмножество поможет нам легко справляться со всеми задачами, актуальными при работе с горячими циклами. Поскольку это полноценное подмножество C#, работать с ним можно как с обычным C#. Мы можем получать ошибки, связанные с выходом за границу при попытке доступа, получим отличные сообщения об ошибках, у на будет поддерживаться отладчик, а скорость компиляции будет такая, о которой вы уж и позабыли, работая с C++. Мы часто называем такое подмножество «Высокопрозводительный C#» или HPC#.
Компилятор Burst: что на сегодняшний день?
Мы написали генератор/компилятор кода под названием Burst. Он доступен в версии Unity 2018.1 и выше как пакет в режиме «предпросмотра». С ним еще предстоит много работы, но мы довольны им уже сегодня.
Иногда у нас получается работать быстрее, чем на C++, зачастую — все еще медленнее, чем на C++. Ко второй категории относятся баги производительности, с которыми, убеждены, нам удастся справиться.
Однако простого сравнения производительности недостаточно. Не менее важно, что приходится сделать, чтобы достичь такой производительности. Пример: мы взяли код отсечения (culling) из нашего нынешнего рендерера C++ и портировали его в Burst. Производительность не изменилась, но в версии на C++ нам приходилось заниматься невероятной эквилибристикой, чтобы уговорить наши компиляторы C++ заняться векторизацией. Версия с Burst оказалась примерно вчетверо компактнее.
Честно говоря, вся эта история с «вам следует переписать на C# ваш код, критичный по части производительности» на первый взгляд никому не приглянулась и во внутренней команде Unity. Для большинства из нас это прозвучало как «поближе к железу!», когда работаешь с C++. Но теперь ситуация изменилась. Используя C#, мы полностью контролируем весь процесс от компиляции исходного кода вплоть до генерации машинного кода, а если какая-то деталь нам не нравится — мы просто берем и фиксим ее.
Мы собираемся медленно, но верно портировать весь код, критичный по производительности, с C++ на HPC#. На этом языке проще добиться нужной нам производительности, сложнее написать баг и легче работать.
Вот скриншот инспектора Burst, на котором можно без труда просмотреть, какие инструкции сборки были сгенерированы для ваших различных горячих циклов:
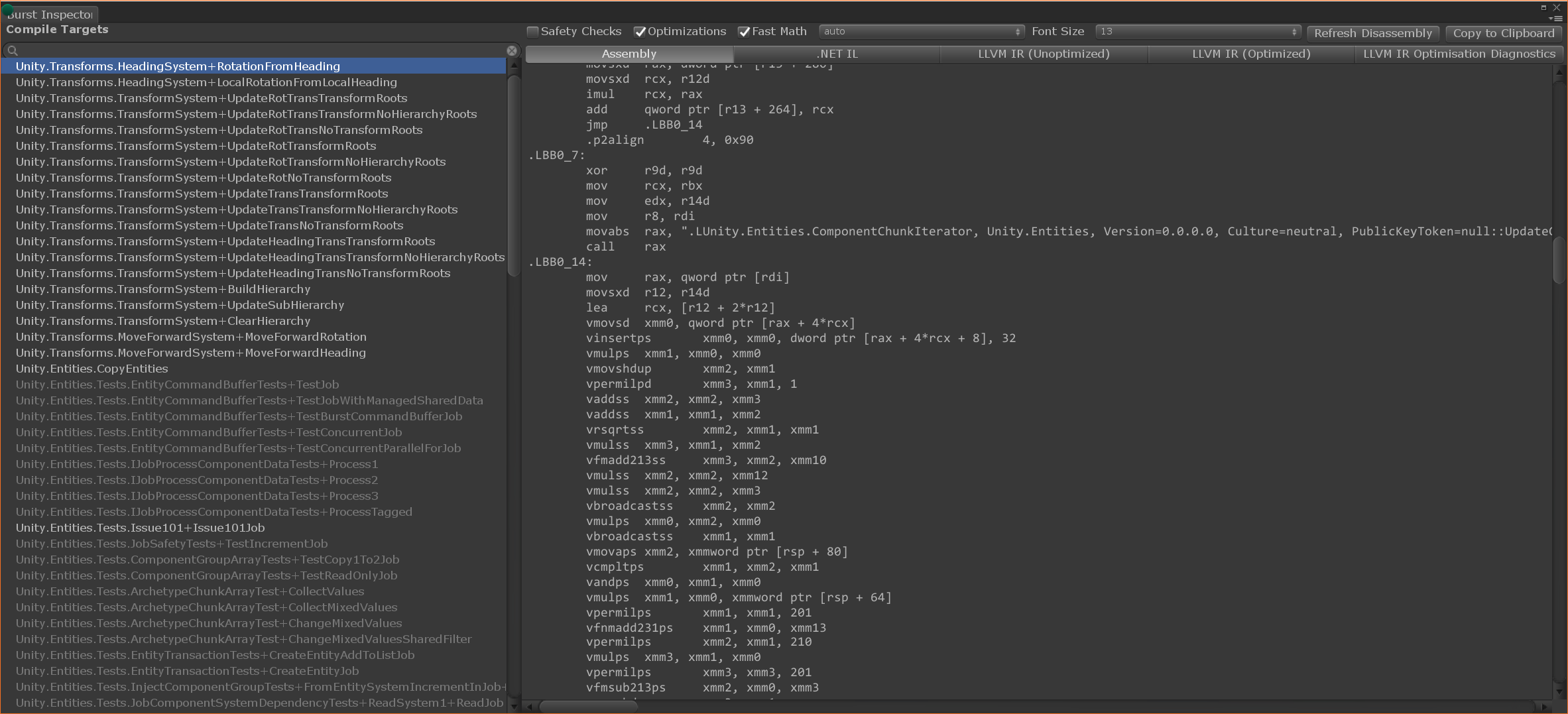
У Unity множество разных пользователей. Некоторые могут по памяти перечислить весь набор инструкций arm64, другие просто увлеченно творят, даже не имея PhD по информатике.
Все пользователи выигрывают, когда та ускоряется доля времени кадра, что тратится на выполнение кода движка (обычно это 90%+). Та доля, на которую приходится работа с исполняемым кодом пакета Asset Store, действительно ускоряется, так как авторы пакета Asset Store берут на вооружение HPC#.
Продвинутые пользователи дополнительно выиграют и от того, что сами смогут писать собственный высокопроизводительный код на HPC#.
Точечная оптимизация
В C++ очень сложно заставить компилятор принимать неодинаковые компромиссные решения по оптимизации кода в разных частях вашего проекта. Максимально детальная оптимизация, на которую можно рассчитывать — пофайловое указание уровня оптимизации.
Burst спроектирован так, чтобы можно было принимать на вход единственный метод этой программы, а именно: точку входа в горячий цикл. Burst скомпилирует эту функцию, а также все, что она вызывает (такие вызываемые элементы должны быть гарантированно известны заранее: мы не допускаем виртуальных функций или указателей функций).
Поскольку Burst оперирует лишь относительно небольшой частью программы, мы устанавливаем уровень оптимизации 11. Burst встраивает практически каждое место вызова. Удалите if-проверки, которые в противном случае удалены не будут, так как во встраиваемой форме мы получаем более полную информацию об аргументах функции.
Как это помогает решать распространенные проблемы с многопоточностью
C++ (равно как и C#) не особенно помогают разработчикам писать потокобезопасный код.
Даже сегодня, более чем десятилетие спустя после того, как типичный игровой процессор стал оснащаться двумя и более ядрами, очень сложно писать программы, эффективно использующие несколько ядер.
Гонки данных, недетерминированность и взаимные блокировки — вот основные вызовы, из-за которых так сложно писать многопоточный код. В данном контексте нам нужны фичи из разряда «убедиться, что эта функция и все, что она вызывает, никогда не станут читать или записывать глобальное состояние». Мы хотим, чтобы все нарушения этого правила давали ошибки компилятора, а не оставались «правилами, которых, надеемся, станут придерживаться все программисты». Burst выдает ошибку компиляции.
Мы настоятельно рекомендуем пользователям Unity (и придерживаемся того же в своем кругу) писать код так, чтобы все запланированные в нем преобразования данных подразделялись на задания. Каждое задание «функционально», и, в качестве побочного эффекта — свободно. В нем явно указываются буферы только для чтения и буферы для чтения/записи, с которыми ему приходится работать. Любая попытка обратиться к иным данным вызовет ошибку компиляции.
Планировщик заданий гарантирует, что никто не будет записывать в ваш буфер, предназначенный только для чтения, пока работает ваше задание. А мы гарантируем, что на период выполнения задания никто не будет считывать из вашего буфера, предназначенного для считывания и записи.
Всякий раз, когда вы назначите задание, нарушающее эти правила, вы получите ошибку компиляции. Не только в столь неудачном случае как условия гонки. В сообщении об ошибке будет объяснено, что вы пытаетесь назначить задание, которое должно считывать из буфера A, но ранее вы уже назначили задание, которое будет записывать в A. Поэтому, если вы действительно хотите это сделать, то предыдущее задание необходимо указать в качестве зависимости.
Мы считаем, что такой страховочный механизм помогает отловить множество багов, прежде, чем они будут зафиксированы, поэтому обеспечивает эффективное использование всех ядер. Становится невозможно спровоцировать условия гонки или взаимную блокировку. Результаты гарантированно получатся детерминированными, независимо от того, сколько потоков у вас работает, либо сколько раз в потоке происходит прерывание из-за вмешательства какого-то другого процесса.
Осваиваем весь стек
Когда мы можем докопаться до всех этих компонентов, мы также можем обеспечить, чтобы им было известно друг о друге. Например, распространенная причина срыва векторизации такова: компилятор не может гарантировать, что два указателя не будут указывать в одну и ту же точку памяти (алиасинг). Мы знаем, что два NativeArray ни в коем случае не будут вот так накладываться друг на друга, поскольку написали библиотеку коллекций, и можем воспользоваться этими знаниями в Burst, поэтому не станем отказываться от оптимизации лишь из опасений, что два указателя могут быть направлены на один и тот же участок памяти.
Аналогично, мы написали математическую библиотеку Unity.Mathematics. Burst она известна «досконально» Burst (в будущем) сможет точечно отказываться от оптимизации в случаях наподобие math.sin (). Поскольку для Burst math.sin () — не просто рядовой метод C#, который нужно скомпилировать, он «поймет» и тригонометрические свойства sin (), поймет, что sin (x) == x для малых значений x (что Burst самостоятельно сможет доказать), поймет, что его можно заменить на разложение в ряд Тейлора, отчасти пожертвовав при этом точностью. В перспективе в Burst также планируется реализовать кроссплатформенность и спроектировать детерминизм с плавающей точкой — мы верим, что такие цели вполне достижимы.
Стираются различия между кодом игрового движка и кодом игры
Когда мы пишем код среды исполнения Unity на HPC#, игровой движок и игра как таковая оказываются написаны на одном и том же языке. Мы можем распределять в виде исходного кода системы времени исполнения, преобразованные нами в HPC#. Каждый сможет учиться на них, улучшать их, адаптировать их под себя. У нас будет игровое поле определенного уровня, и ничто не помешает нашим пользователям написать более качественную систему частиц, игровую физику или рендерер, чем написали мы. Сближая наши внутренние процессы разработки с пользовательскими процессами разработки, мы также сможем лучше почувствовать себя в шкуре пользователя, поэтому бросим все силы на выстраивание единого рабочего потока, а не двух разных.
