[Перевод] Становится ли поп-музыка менее осмысленной?

Недавно я много размышлял о том, как изменилась поп-музыка. В частности, я хотел понять, становится ли поп-музыка в США менее осмысленной (это распространенная тема для критики со стороны старшего поколения). Чтобы доказать или опровергнуть это утверждение, я принял определение «менее осмысленный», означающим наличие в тексте менее выразительных и разнообразных слов.
Изучая поп-музыку, можно многое понять, ведь она повлияла на культуру большого числа американцев. Утверждать, что поп-музыка является неосмысленной, значит ставить под сомнение интеллектуальный уровень американского населения.
Поискав информацию в интернете, я нашел статью на сайте Huffington Post, которая анализирует основные слова, используемые в поп-песнях, написанных в различное время. Думаю, данные из этой статьи говорят о многом касательно того, как изменился подход к написанию текстов в Америке за определенный период. В частности, в текстах популярных песен стали чаще употребляться слова, связанные с сексом, насилием и наркотиками.
Мне же захотелось поучаствовать в выяснении истины, получив более общую статистику, которая бы больше сосредотачивалась на смысловом наполнении текстов в целом, нежели на использовании тех или иных тем в песнях. Я отыскал статью за авторством Вильяма Бриггса (William Briggs), в которой он утверждает, что музыка попросту стала намного глупее чем раньше. Он анализирует отношение числа уникальных слов [в данном случае под «уникальными» словами, вероятно, понимаются слова, которые встречаются в песне не больше одного раза — прим. перев.] в популярных песнях к общему числу слов в них, и использует результаты исследования в качестве доказательства снижающегося уровня осмысленности текстов.
Желая отсрочить работу над своим дипломномом, проверить результаты исследования Бриггса и написать программу на Python, я решил провести подобное исследование, используя списки 40 лучших хитов за каждый год, начиная с 1950 года до нынешнего момента. Бриггс не говорит, какую конкретно музыку он использовал для анализа, однако выяснилось, что его исходный материал был примерно таким же как и у меня.
На сайте Top40 Charts можно найти все списки 40 лучших музыкальных хитов за каждый год, начиная с 1950 года, оформленные в виде простых таблиц. Я мог без труда использовать каждый элемент из списков при помощи простого цикла и проекта Beautiful Soup. Таким образом, я загружал имена исполнителей и названия песен в MongoDB, используя PyMongo в качестве драйвера.
Итак, в моем распоряжении были почти все музыкальные хиты из всех списков топ-40, кроме некоторого некачественного материала: в отдельных названиях песен, найденных мной, оказались опечатки и прочие ошибки. После этого мне нужно было найти тексты песен. И вот тут начинались трудности: я не cмог найти доступный и бесплатный API для работы с текстами песен, а также не горел желанием писать программу-скрапер, которая бы собирала результаты поиска в Google. Оказалось, что на ресурсе lyrics.wikia.com можно найти множество текстов песен и структура страниц позволяет эффективно искать необходимые файлы среди большого числа композиций.
Единственной проблемой было то, что адрес каждой песни очень специфичен и малейшая неточность приводила к появлению ошибки 404. В 50-х годах среди больших музыкальных коллективов было очень популярным называть себя «Такой то и такой то», «Такой-то и такой-то и оркестр» или «Такой-то и такой-то и его оркестр» и т.д., а это затрудняет поиск файлов. Я ускорил этот процесс, использовав в работе с названиями песен и именами исполнителей различные регулярные выражения, которые, к примеру, удаляли указанные названия или фразы в скобках. В итоге это оказалось решающим фактором для успешного нахождения текстов песен. Я решил, что результатов такого поиска будет достаточно для проведения анализа.
После этого было несложно проанализировать тексты из песен разных лет и сравнить их друг с другом. Сперва я выяснил число уникальных слов в каждой песне, общее число слов в каждой песне и нашел отношение между двумя этими показателями. Результаты моего исследования подтвердили то, что описал Бриггс: число уникальных слов и общее их число увеличивалось со временем, тогда как значение их отношения стало значительно меньше. Это могло означать, что уровень смыслового наполнения текстов в популярных песнях действительно понизился.
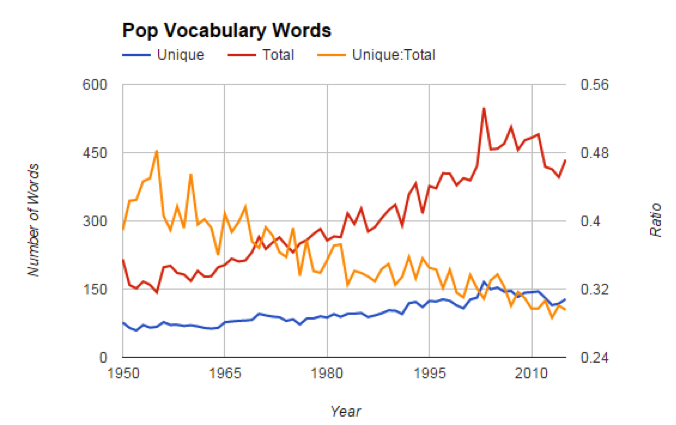
Повышение общего числа слов в текстах, вероятно, можно объяснить переходом к другим жанрам: в текстах песен больших джазовых оркестров и песен в жанре диско наверняка меньше слов, чем в композициях музыкантов, читающих рэп или исполняющих рок-н-ролл. Кроме того, крупные джазовые оркестры прежних лет не использовали поддержку хора, что значительно уменьшало количество повторяемых слов в песне.
Интересно, что общее число слов и число уникальных слов в песнях достигли максимального значения в 2003 году, причиной чему, возможно, служит большое количество хитов в жанре рэп и R&B, появившихся в это время. Верхние строчки в списке из 40 лучших хитов этого года пестрят песнями 50 Cent, Eminem, Jay Z и других. Последующее снижение показателей может быть результатом популярности электронной музыки и танцевальных хитов.
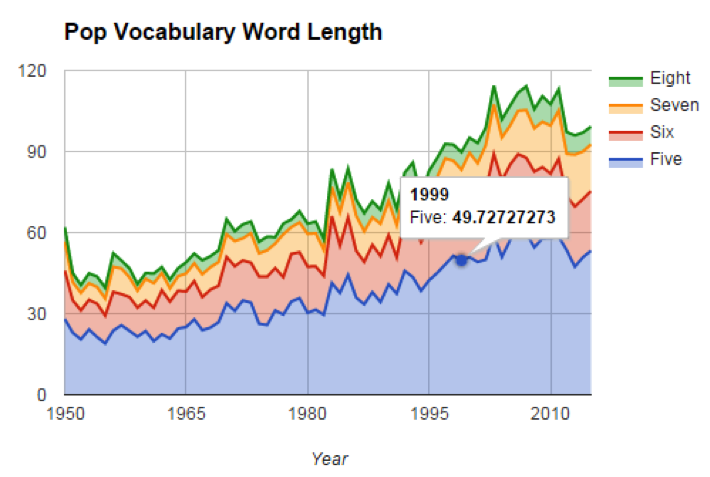
Я захотел немного глубже разобраться в этой теме, поэтому проанализировал среднюю длину слов в текстах песен. Ее значение в каждом году было очень близко к четырем символам. Я также подсчитал среднее число слов различной длины в песнях. Точно так же доля слов из четырех, пяти, шести, семи и восьми букв среди всех слов каждый год оставалась почти неизменной.
Таким образом, хотя отношение уникальных слов к общему числу слов в песнях на сегодняшний день может быть и меньше, тем не менее, слова более старых песен необязательно были при этом «более осмысленными». Учитывая сказанное, можно сделать вывод, что сама по себе длина слов мало что говорит об их качестве.
Я провел контрольную проверку, чтобы окончательно убедиться в том, что полученные мной данные были достаточно корректными. Мне было бы стыдно, если бы мои выводы можно было легко опровергнуть несколькими примерами нестандартных текстов с большим количеством длинных или уникальных слов. Я учел такую возможность, рассчитав коэффициент вариации для длины слов и числа уникальных слов в каждой песне. Общее правило гласит: если коэффициент вариации меньше единицы, считается, что данные вполне корректны.
Вы можете прочитать больше о значении этого коэффициента в посте StackExchange, который содержит другие полезные источники по этой теме. Выяснилось, что содержание текстов оставалось довольно стабильным в течение указанного периода, поэтому какие-либо «контрпримеры» не могли сделать результаты исследования некорректными.

Более детальный анализ уровня смысловой нагруженности популярных песен потребовал бы углубленного понимания содержания текстов, однако вышеуказанные общие сведения позволяют предположить, что тексты поп-исполнителей с течением времени стали менее креативными. Определенно, в текстах стало больше повторов. Общее увеличение количества слов и уникальных слов в песнях, вероятно, можно объяснить более интенсивным словесным наполнением песен в таких жанрах, как рэп или инди-рок, по сравнению с музыкой больших джазовых оркестров 50-х годов или диско 70-х.
Поскольку средняя длина слов не сильно изменилась со временем, я считаю невозможным с уверенностью утверждать, что нынешняя музыка стала «более глупой», как говорит Бриггс. Более корректным и более объективным было бы утверждение о том, что песни стали многословнее, и в них чаще используют повторы в припевах.
Код, созданный в рамках этого эксперимента, целиком выложен на Github. База данных также находится в свободном доступе (там же) — на случай, если вам интересно получить доступ к текстам песен.
