[Перевод] Сравнение векторных расширений ARM и RISC-V
Сравнение векторного расширения RISC-V (RVV) и масштабируемого векторного расширения ARM (SVE/SVE2).

Микропроцессоры с векторными командами ожидает большое будущее. Почему? Беспилотные автомобили, распознавание речи, распознавание образов, всё это основано на машинном обучении, а машинное обучение — на матрицах и векторах.
Но это не единственная причина. Мы годами бьёмся головой о стену, чтобы выжать больше производительности с тех пор, как полуофициальный закон Мура перестал работать. В старое золотое время мы могли просто удваивать тактовую частоту процессора каждый год, и все были счастливы. Но это больше так не работает.
 Увеличение производительности остановилось, что делает необходимым распараллеливать вычисления различными способами, либо с помощью многоядерности, либо с помощью векторизации, либо с помощью исполнения не в порядке очереди (out-of-order).
Увеличение производительности остановилось, что делает необходимым распараллеливать вычисления различными способами, либо с помощью многоядерности, либо с помощью векторизации, либо с помощью исполнения не в порядке очереди (out-of-order).
Сейчас мы придумали тысячи умных способов получить большую производительность, будь то создание многоядерных процессоров, внеочередное (out-of-order) исполнение, более совершенное предсказание переходов и SIMD-команды.
Все эти способы основаны на одной центральной идее: пытаться различными способами распараллеливать работу. Когда вы выполняете какие-то вычисления в цикле над массивом элементов, у вас появляется возможность параллелизма данных. Этот цикл при достаточно умном компиляторе может быть превращён в последовательность SIMD или векторных команд.
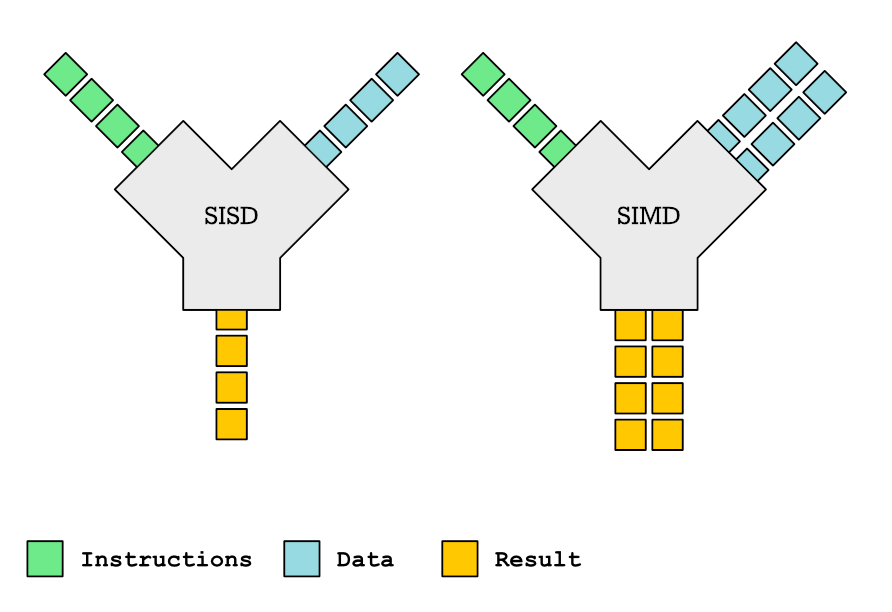 SIMD-инструкции, в отличие от SISD-инструкций, каждая инструкция (зелёный цвет) обрабатывает множество независимых потоков данных (синий цвет).
SIMD-инструкции, в отличие от SISD-инструкций, каждая инструкция (зелёный цвет) обрабатывает множество независимых потоков данных (синий цвет).SIMD-команды, такие, как Neon, MMX, SSE2 и AVX замечательно сработали в мультимедийных приложениях, в таких вещах, как кодирование видео и т.п. Но нам нужно получить большую производительность во многих областях. Векторные команды предлагают большую гибкость в превращении почти любого цикла в векторные команды. Однако есть много различных способов это сделать.
Я описал векторные команды RISC-V здесь: RISC-V Vector Instructions vs ARM and x86 SIMD.
Позже я описал векторные команды ARM: ARMv9: What is the Big Deal?.
Когда я писал последнюю статью, я впал в замешательство. Кажется, ничто не работает таким образом, как меня учили. Я считал, что я знаю, как работают векторные команды, изучая их для моей первой статьи. После окончания последней статьи, я начал писать статью об их сравнении.
Это заставило меня обнаружить, что ARM и RISC-V следуют принципиально разным стратегиям. Стоит написать об этом, потому что это одна из моих любимых тем. Я люблю простые, элегантные и эффективные технологии: The Value of Simplicity.
Векторное расширение RISC-V по сравнению с ARM SVE — это элемент элегантности и простоты.
Проблема с масштабируемыми векторными командами ARM (Scalable Vector Instructions, SVE)
В процессе изучения SVE, было неочевидно, почему это так трудно для понимания, но когда я взял книгу по RISC-V и перечитал главу по векторному расширению, это стало ясно.
Честно говоря, ARM является большим шагом вперёд по сравнению с большим сложным и беспорядочным ассемблером Intel x86. Давайте не будем про это забывать. Также мы не можем пройти мимо того факта, что ARM не молодая платформа, и содержит много легаси. Когда мы имеем дело с ARM, у нас есть три различных набора команд: ARM Thumb2, ARM32 и ARM64. Когда вы гуглите руководства и пытаетесь их читать, возникает ряд проблем. Люди не всегда понимают, какой набор команд изучать.
Инструкции Neon SIMD имеют две разновидности: 32- и 64-битные. Проблема, конечно, не в ширине слова, а в том, что для 64-битной архитектуры ARM перепроектировал весь набор команд и изменил многие вещи, даже соглашение об именовании регистров.
Вторая проблема в том, что ARM большой. Система команд содержит свыше 1000 команд. Сравните с базовым набором RISC-V, в котором всего лишь 48 команд. Это означает, что читать ассемблер ARM не так просто. Посмотрим на команду SVE:
LD1D z1.D, p0/Z, [x1, x3, LSL #3]Здесь делается много. Если у вас есть опыт в ассемблере, вы можете догадаться, что префикс LD означает LoaD. Но что означает 1D? Вы должны это выяснять. Дальше вы должны выяснить, что означают странные суффиксы имён регистров, такие как .D and /Z. Дальше вы видите скобки[]. Вы можете догадаться, что они составляют адрес, зачем там странная запись LSL #3, что означает логический сдвиг влево (Logic Shift Left)три раза. Что сдвигается? Все данные? Или только содержимое регистраx3? Это снова нужно смотреть в справочнике.
Команды ARM SVE содержат множество концепций, не являющихся очевидными, от которых голова идёт кругом. Мы сделаем глубокое сравнение, но сначала скажем несколько слов о RISC-V.
Красота векторного набора команд RISC-V
Обзор всех команд векторных расширений RISC-V (RVV) помещается на одной странице. Команд немного, и, в отличие от ARM SVE, они имеют очень простой синтаксис. Вот команда загрузки вектора в RISC-V:
VLD v0, x10Команда загружает векторный регистр v данными, находящимися по адресу, который хранится в обычном целочисленном регистреx10. Но сколько данных загружается? В наборе команд SIMD, таком, как ARM Neon это определяется именем векторного регистра.
LD1 v0.16b, [x10] # Load 16 byte values at address in x10Есть другой способ сделать это. Такой же результат достигается таким образом:
LDR d0, [x10] # Load 64-bit value from address in x10Эта команда загружает младшую 64-битную часть 128-битного регистраv0. Для SVE2 у нас есть другой вариант:
LD1D z0.b, p0/z, [x10] # Load ? number of byte elements
LD1D z0.d, p0/z, [x10] # Load double word (64-bit) elementsВ этом случае регистр предиката p0 определяет в точности, сколько элементов мы загружаем. Если p0 = 1110000, мы загружаем три элемента. v0— это 128-битная младшая частьz0.
Регистры имеют одинаковые имена?
Причина этому в том, что регистры d, v и z находятся в одной ячейке. Давайте поясним. У вас есть блок памяти, называемый регистровый файл в каждом CPU. Или, если быть более точным, в CPU расположено много регистровых файлов. Регистровый файл, это память, в которой расположены регистры. Вы не можете получить доступ к ячейкам памяти в регистровом файле, так же как в обычной памяти, вместо этого вы обращаетесь к области памяти, используя имя регистра.
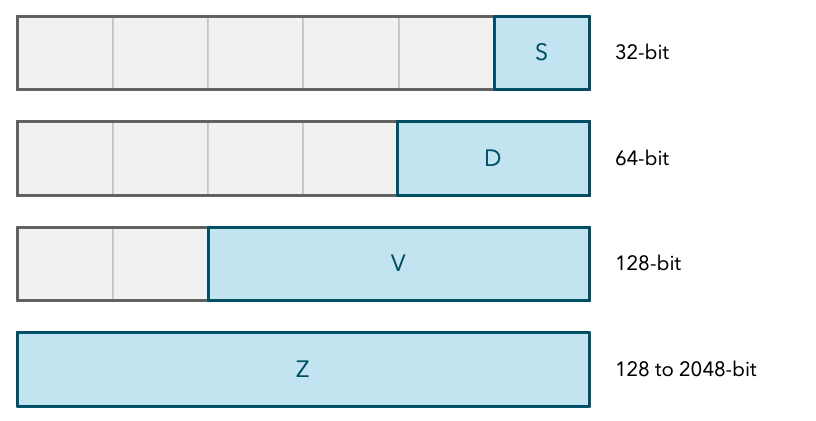 ARM floating point registers are overlapping in the same register file (memory in CPU holding registers).
ARM floating point registers are overlapping in the same register file (memory in CPU holding registers).
Различные регистры могут отображаться на одну и ту же область регистрового файла. Когда мы используем скалярную операцию с плавающей точкой, мы используем часть векторных регистров. Рассмотрим 4-й векторный регистр, и рассмотрим, как ещё он используется:
z3— регистр SVE2 переменной длины.v3— младшие 128 битz3. Регистр Neon.d3— младшие 64 битаv3.s3— младшие 32 битd3
RISC-V, однако, устроен не так. Векторные регистры RISC-V находятся в отдельном регистровом файле, не разделяемом с регистрами скалярной плавающей точки.
x0—x31— скалярные целочисленные регистры.f0—f31— скалярные регистры с плавающей точкой.v0—v31— векторные регистры. Длина не зависит от ISA.
Сложность векторных команд ARM
Я только поцарапал поверхность векторных команд ARM, потому что их очень много. Просто найти, что делает команда загрузки Neon и SVE2, занимает много времени. Я просмотрел много документации ARM и записей в блогах. Сделать то же самое для RISC-V очень просто. Практически все команды RISC-V можно разместить на двойном листе бумаги. У него есть только три команды загрузки вектора VLD, VLDS и VLDX.
Я не могу сказать, сколько этих команд у ARM. Их очень много, и я не собираюсь становиться профессионалом по программированию ARM. на ассемблере.
Как ARM и RISC-V обрабатывают вектора переменной длины
Это довольно интересный вопрос, так как ARM и RISC-V используют существенно различные подходы и я считаю, что простота и гибкость решения RISC-V просто блестящая.
Вектора переменной длины в RISC-V
Чтобы начать обработку векторов, вы делаете две вещи:
VSETDCFG— Vector SET Data ConFiGuration. Устанавливает битовый размер каждого элемента, тип, который может быть вещественным, знаковым целым или беззнаковым целым. Также конфигурация определяет, сколько векторных регистров используется.SETVL— SET Vector Length. Устанавливает, сколько элементов содержит вектор. Максимальное количество элементов, которое вы не можете превысить —MVL(max vector length).
 Регистровый файл RISC-V может быть скофигурирован так, чтобы иметь меньше 32 регистров. Может быть, например, 8 регистров или 2 регистра большего размера. Регистры могут занимать весь объём регистрового файла.
Регистровый файл RISC-V может быть скофигурирован так, чтобы иметь меньше 32 регистров. Может быть, например, 8 регистров или 2 регистра большего размера. Регистры могут занимать весь объём регистрового файла.И здесь всё становится интереснее. В отличие от ARM SVE, я могу разделить файл векторных регистров именно так, как я хочу. Пусть регистровый файл имеет размер 512 байт. Я могу теперь объявить, что я хочу иметь два векторных регистра, по 256 байт каждый. Далее я могу сказать, что я хочу использовать 32-битные элементы, другими словами, элементы по 4 байта. Получаем следующее:
Два регистра: 512 байт / 2 = 256 байт на регистр
256 байт / 4 байта на элемент = 128 элементовЭто означает, что я могу складывать или умножать 128 элементов просто одной командой. В ARM SVE вы этого сделать не можете. Количество регистров фиксировано, и память аллоцирована для каждого регистра. И RISC-V, и ARM позволяют вам использовать максимум 32 векторных регистра, но RISC-V позволяет вам отключать регистры и отдавать используемую ими память оставшимся регистрам, увеличивая их размер.
Вычисление максимальной длины вектора (Max Vector Length, MVL)
Давайте посмотрим, как это работает на практике. Процессор, конечно, знает размер регистрового файла. Программист этого не знает, и не предполагается, что знает.
Когда программист использует VSETDCFG, чтобы установить типы элементов и количество используемых регистров, процессор использует эту информацию, чтобы вычислить максимальную длину вектора Max Vector Length (MVL).
LI x5, 2<<25 # Load register x5 with 2<<25
VSETDCFG x5 # Set data configuration to x5В примере выше происходят две вещи:
Включаем два регистра:
v0иv1.Устанавливаем тип элементов в 64-битные вещественные числа. Давайте сравним это с ARM Neon, в котором каждый регистр имеет длину 128 бит. Это означает, что Neon может обрабатывать два таких числа параллельно. Но в RISC-V 16 таких регистров можно объединить в один. Это позволяет обрабатывать 32 значения параллельно.
На самом деле это не буквально так. За сценой у нас есть конечное число вещественных умножителей, блоков АЛУ и т.п., что ограничивает число параллельных операций. Однако всё это уже детали реализации.
Итак, мы получили значение MVL, равное 32. Разработчик не должен напрямую знать это число. Команда SETVL работает так:
SETVL rd, sr ; rd ← min(MVL, sr), VL ← rdЕсли вы попытаетесь установить Vector Length (VL) в значение 5, это сработает. Однако, если вы попытаетесь установить значение 60, вы получите вместо этого значение 32. Итак, величина Max Vector Length (MVL) важна, она не фиксирована конкретным значением при изготовлении процессора. Она может быть вычислена исходя из конфигурации (типа элементов и количества включенных регистров).
Вектора переменной длины в ARM
В ARM вы не устанавливаете длину вектора явным образом. Вместо этого вы устанавливаете длину вектора косвенно, используя предикатные регистры. Они являются битовыми масками, которыми вы включаете и выключаете элементы в векторном регистре. Регистры предикатов также существуют в RISC-V, но не имеют центральной роли, как в ARM.
Чтобы получить эквивалент SETVL на ARM, используйте команду WHILELT , что является сокращением от While Less Than:
WHILELT p3.d, x1, x4Довольно сложно объяснить словами, что делает эта команда, и я использую псевдокод, чтобы объяснить её работу.
i = 0
while i < M
if x1 < x4
p3[i] = 1
else
p3[i] = 0
end
i += 1
x1 += 1
endКонцептуально, мы переворачиваем биты в регистре предиката p3 в зависимости от того, меньше ли x1, чем x4. В данном случае x4 содержит длину вектора. Если p3 выглядит так, то длину вектора можно считать равной 3.
1110000То есть вектор переменной длины реализуется за счёт того, что все операции используют предикат. Рассмотрим эту операцию сложения. Представьте, чтоv0[p0] извлекает из v0 только те элементы, для которых p0 истинно.
ADD v4.D, p0/M, v0.D, v1.D ; v4[p0] ← v0[p0] + v1[p0]Итак, мы сделали некоторое вступление. Сейчас рассмотрим более полный пример кода, чтобы увидеть, как эти наборы команд работают на практике.
Пример кода DAXPY
Рассмотрим сейчас, как функции C могут быть реализованы различными векторными командами:
void daxpy(size_t n, double a, double x[], double y[]) {
for (int64_t i = 0; i < n; ++i) {
y[i] = x[i] * a + y[i];
}
}Почему такое странное имя — daxpy? Это простая функция в библиотеке линейной алгебры BLAS, популярной в научной работе. В BLAS эта функция называется daxpy и она очень популярна для демонстрации примеров работы разнообразных SIMD и векторных команд. Она реализует такую формулу:
aX + Yгде a — скаляр, а X и Y — вектора. Без векторных команд нужно было бы обрабатывать все элементы в цикле. Но с умным компилятором, эти команды могут быть векторизованы в код, который выглядит на RISC-V так, как показано ниже. Комментарии показывают, какой регистр какой переменной соответствует:
daxpy(size_t n, double a, double x[], double y[])
n - a0 int register (alias for x10)
a - fa0 float register (alias for f10)
x - a1 (alias for x11)
y - a2 (alias for x12Код:
LI t0, 2<<25
VSETDCFG t0 # enable two 64-bit float regs
loop:
SETVL t0, a0 # t0 ← min(mvl, a0), vl ← t0
VLD v0, a1 # load vector x
SLLI t1, t0, 3 # t1 ← vl * 2³ (in bytes)
VLD v1, a2 # load vector y
ADD a1, a1, t1 # increment pointer to x by vl*8
VFMADD v1, v0, fa0, v1 # v1 += v0 * fa0 (y = a * x + y)
SUB a0, a0, t0 # n -= vl (t0)
VST v1, a2 # store Y
ADD a2, a2, t1 # increment pointer to y by vl*8
BNEZ a0, loop # repeat if n != 0
RET Это код, скопированный из примера. Отметим, что мы не используем имена f и x для целочисленных и вещественных регистров. Чтобы помочь разработчикам лучше помнить соглашения, ассемблер RISC-V определяет ряд псевдонимов. Например, аргументы функции передаются в регистрах x10 — x17. Но нет необходимости запоминать эти номера, для аргументов предусмотрены псевдонимы a0 — a7.
t0 — t6 — псевдонимы регистров временных переменных. Они не сохраняются между вызовами.
Для сравнения мы приведём ниже код ARM SVE. Пометим, какой регистр какую переменную содержит.
daxpy(size_t n, double a, double x[], double y[])
n - x0 register
a - d0 float register
x - x1 register
y - x2 register
i - x3 register for the loop counterКод:
daxpy:
MOV z2.d, d0 // a
MOV x3, #0 // i
WHILELT p0.d, x3, x0 // i, n
loop:
LD1D z1.d, p0/z, [x1, x3, LSL #3] // load x
LD1D z0.d, p0/z, [x2, x3, LSL #3] // load y
FMLA z0.d, p0/m, z1.d, z2.d
ST1D z0.d, p0, [x2, x3, LSL #3]
INCD x3 // i
WHILELT p0.d, x3, x0 // i, n
B.ANY loop
RETКод ARM немного короче, так как команды ARM делают больше, чем одно действие. Это является причиной того, что код RISC-V гораздо проще читать. Команды в RISC-V делают что-то одно, и не требуют специального сложного синтаксиса. Такая простая вещь, как загрузка векторного регистра в ARM выглядит сложно:
LD1D z1.d, p0/z, [x1, x3, LSL #3]Часть в квадратных скобках вычисляет адрес, из которого происходит загрузка:
[x1, x3, LSL #3] = x1 + x3*2³ = x[i * 8]Итак, здесь видно, чтоx1 представляет базовый адрес переменной x. x3 — счётчик i. Сдвигом влево на три бита мы умножаем на 8, то есть на количество байт в 64-битном вещественно числе.
Заключение
Как начинающий в векторном кодинге, я должен сказать, что ARM переусложнён. Это не значит, что ARM плохой. Я также изучал систему команд Intel AVX, и она в 10 раз хуже. Я совершенно определённо не хочу тратить время на изучение AVX, принимая во внимание, сколько усилий отняли SVE и Neon.
Для меня совершенно ясно, что любой, кто хочет изучать кодинг на ассемблере, должен начать с RISC-V. Для начинающих это на порядки проще в освоении. И это не удивительно. Эта система команд специально разработана для преподавания в университете.
Архитектура сложна, потому что это легаси. Эта архитектура развивалась десятилетиями, и пыталась сохранять обратную совместимость. ARM имеет более ясный дизайн, но он усложнён просто потому, что дизайн продиктован в первую очередь требованиями отрасли, а не дружественностью к новичкам.
Если для вас, как и для меня, это хобби, и вы просто хотите понимать, как развивается технология, и как работают вещи, такие, как векторная обработка, сберегите свои усилия и просто прочитайте книгу по RISC-V.
Люди могут поспорить, что ARM или Intel или что-то ещё проще, потому что по ним больше книг и больше ресурсов. Ничего подобного! Я могу сказать вам на своём собственном опыте, что документация часто представляет собой препятствие, а не помощь. Это означает, что вам нужно раскопать больше материала. Вы найдёте много противоречий, корни которых лежат в устаревших принципах работы.
Если вы хотите погрузиться в ассемблер, вы можете прочитать некоторые из моих статей и руководств:
