[Перевод] Сравнение производительности YDB, CockroachDB и YugabyteDB на бенчмарке YCSB

Привет! Меня зовут Евгений Иванов, я разработчик YDB. Мне очень нравится заниматься задачами, связанными с производительностью: бенчить, анализировать, оптимизировать. И в YDB мы придаем очень большое значения тому, чтобы быть эффективными. В этом посте я хочу представить Вашему вниманию перевод нашей свежей статьи «YCSB performance series: YDB, CockroachDB, and YugabyteDB».
Реализовать распределённую систему управления базами данных (СУБД), высокопроизводительную, масштабируемую и консистентную, — настоящий вызов. В YDB успешно с ним справились, и наши пользователи могут это подтвердить. Мы ещё не делились показателями нашей производительности на широкую аудиторию, но понимаем их значимость. Поэтому сегодня мы расскажем о результатах нашего исследования производительности.
YDB — это распределённая реляционная СУБД. Производительность распределённых транзакций в TPC-C и других сложных бенчмарках во многом зависит от реализации хранения данных по ключу. В этом посте посте мы сравним результаты тестов YCSB для YDB и двух других известных распределённых SQL-баз данных — CockroachDB и YugabyteDB. Спойлер: YDB превзойдёт конкурентов по многим нагрузкам YCSB.
Подробное описание тестовой конфигурации и обоснование её использования вы найдёте ниже, а пока просто покажем результаты для трёхузлового кластера с 2 млрд строк (а это около 2 ТБ данных). У кластера 1,5 ТБ оперативной памяти и 240 ГБ кэша, а значит, все данные в оперативную память не вместить. Мы исключили результаты CockroachDB для нагрузок A, B и F. Почему — расскажем вместе с другими подробностями в разделе результатов.

График показывает пропускную способность в тысячах операций в секунду (чем выше, тем лучше), а время задержки на 99% составляет менее 50 мс
Не стесняйтесь сразу переходить к разделу с результатами, если вам важны только они.
Введение в YCSB
YCSB — популярный бенчмарк для нагрузок при чтении и записи данных по ключу. Сначала расскажем о более простых нагрузках: вряд ли можно достичь быстрого выполнения распределённых транзакций при неэффективной организации работы с данными по ключу. К тому же такой вид нагрузок часто встречается в реальных сценариях.
Итак, почти все конкурирующие СУБД демонстрируют базовую производительность на YCSB. Именно поэтому официальный репозиторий YCSB поддерживает более 20 СУБД, а его многочисленные форки — ещё несколько десятков. Многие БД NewSQL тоже используют YCSB для базового измерения, несмотря на то, что предназначены не только для прямого обращения к данным по ключу.
Вот один из примеров. В 2019 году CockroachDB опубликовали статью под названием «Yugabyte vs. CockroachDB: Unpacking Competitive Benchmark Claims», в которой сообщили о значительном превосходстве своей БД над YugabyteDB. В мае 2020-го в YugabyteDB подготовили ответное исследование в двух частях (1, 2) с говорящим названием «Bringing Truth to Competitive Benchmark Claims — YugabyteDB vs CockroachDB».
В 2021 году ScyllaDB сопоставили свою БД с CockroachDB, несмотря на то, что они относятся к разным классам. Пост назвали «An Apples and Oranges Comparison» («Сравнение яблок с апельсинами»). В марте того же года в ScyllaDB опубликовали свой список лучших бенчмарков: YCSB вошёл в число «надёжных фреймворков с открытым исходным кодом».
Мы не можем пройти мимо и включаемся в это «соревнование YCSB». Здоровая конкуренция полезна всем сторонам: победители мотивируют проигравших становиться лучше, а проигравшие выявляют слабые стороны для дальнейшего улучшения.Именно поэтому мы хотим соревноваться с лучшими: у нас есть ценные идеи, которыми можно поделиться, и мы понимаем, что нам тоже есть чему учиться.
Почему мы выбрали CockroachDB и YugabyteDB? Это одни из лучших open-source распределённых реляционных СУБД. CockroachDB создали бывшие сотрудники Google, чтобы достичь производительности, подобной Spanner, но на обычном оборудовании (для работы БД Spanner требовались сложные аппаратные средства, такие как атомные и GPS-часы). А YugabyteDB придумали бывшие сотрудники Facebook, которые работали над Cassandra и HBase.
Мы отправили результаты тестирования разработчикам CockroachDB и YugabyteDB до публикации этой статьи и надеемся, что они помогут им стать ещё лучше.
Итак, назначение YCSB — создавать рабочую нагрузку (workload) с заданным распределением ключа и соотношением операций чтения, обновления, вставки и сканирования. Длина строки данных по умолчанию фиксирована и равна 1 КБ.
У YCSB есть набор основных рабочих нагрузок:
A — нагрузка с частыми обновлениями: 50% чтения и 50% обновления;
B — нагрузка, в которой чаще выполняются операции чтения: 95% чтения и 5% обновления;
C — только чтение;
D — чтение свежих данных: 95% чтения и 5% вставки;
F — чтение-изменение-запись: 50% чтения и 50% операций чтения-обновления;
E — короткие диапазоны: 95% сканирования и 5% вставки.
У всех нагрузок, кроме D, — распределение Zipfian. Это статистическое распределение, при котором некоторые элементы встречаются очень часто, а большинство редко — подобно принципу Парето, при котором 20% усилий отвечают за 80% результата. Нагрузка D использует распределение, где больше всего читаются свежие данные.
Тестовый стенд
Наш тестовый стенд производительности — это кластер из восьми физических машин со следующей конфигурацией каждой:
128 ядер: 2 32-ядерных процессора Intel Xeon Gold 6338 с частотой 2,00 ГГц с включённым гипертредингом;
4xNVMe Intel-SSDPE2KE032T8;
512 ГБ ОЗУ;
скорость передачи данных в сети 50 Гб/с;
включены transparent huge pages;
Ubuntu 20.04.3 LTS.
Мы не использовали виртуализацию при тестировании производительности, чтобы достичь воспроизводимости результатов для точной их оценки. При этом есть и другие важные практические причины использовать именно такую конфигурацию.
Во-первых, масштабируемость — ключевая характеристика современных распределённых БД. Легко быть быстрыми на маленьком кластере с несколькими узлами, но гораздо сложнее достичь высокой производительности на кластере из десятков или сотен узлов (у нас есть кластеры YDB с тысячами серверов). Хотя мы не использовали в тестовой конфигурации всю нашу серверную мощь, но можем оценить масштабирование с восемью 128-ядерными серверами, в том числе вертикальное.
Во-вторых, YDB поддерживает разные топологии (модели репликации). Вот самые распространённые:
mirror-3-dc — записываем три реплики аналогично CockroachDB и YugabyteDB.
block 4+2 — используем erasure coding для хранения данных на дисках. Этот режим рекомендуется для кластеров в пределах одной зоны доступности. Для block 4+2 понадобится вдвое меньше дискового пространства по сравнению с mirror-3-dc и минимум восемь серверов.
К сожалению, ни CockroachDB, ни YugabyteDB не поддерживают block 4+2, хотя такой режим работы полезен для кластеров в одном дата-центре. Но в сравнении мы используем YDB block 4+2 и YDB mirror-3-dc.
Итак, мы тестируем следующие версии:
YDB trunk (от 24 марта), которая на тот момент была почти идентична YDB 23–1 с несколькими новымм функциями;
CockroachDB 22.2.7;
YugabyteDB 2.17.1.0-b439.
Настройка YDB
YDB состоит из узлов хранения данных (статических узлов) и вычислительных узлов (динамических узлов). На каждом сервере мы запускаем один узел хранилища YDB и четыре вычислительных — каждый ограничиваем 32 ядрами. Устанавливаем общий размер кэша в 20 ГБ для каждого динамического узла.
Версия YDB trunk поддерживает автоконфигурацию своих компонентов, таких как акторная система и gRPC (это улучшение будет перенесено в версию 23–1 в ближайшее время). Эти настройки мы включили в наши конфигурационные файлы: отдельно для статического и динамического узлов.
Настройка CockroachDB
Насколько мы знаем, CockroachDB не разделяет слои вычисления и хранения данных. Мы считаем это недостатком, потому что не получится использовать бездисковые серверы для расширения вычислительных мощностей. К тому же, по нашим данным, количество экземпляров CockroachDB для запуска на одном узле ограничено количеством подключённых дисков. На многоядерном сервере достаточно запустить несколько экземпляров для масштабирования, но представьте, если у вас всего один или два диска! К счастью, у нас четыре диска, на каждом из которых мы запускаем свой экземпляр CockroachDB.
При запуске большого количества клиентов YCSB CockroachDB стал выдавать ошибки на запросы. Нам посоветовали снизить gc.ttlseconds до 600 секунд. Это уменьшает MVCC-окно и может привести к проблемам с ручным резервным копированием, но без него мы не сможем достичь реально высокой нагрузки. Размер кэша каждого экземпляра CockroachDB ограничили 20 ГБ, а памяти под SQL — 30 ГБ. Почему именно так? Ответ здесь.
Настройка YugabyteDB
В YugabyteDB заявляют, что тестировали систему на машинахна машинах, у которых было от 2 до 64 ядер. Вот что они пишут:»…производительность YugabyteDB увеличивается за счёт большей агрегированной процессорной мощности в кластере. Вы можете достичь этого путём использования более мощных узлов или добавления большего количества узлов в кластер».
Нам не удалось использовать все 128 ядер при запуске одного tserver: в YugabyteDB подтвердили, что нашли несколько узких мест. В результате мы использовали три машины, на которых работали как master, так и tserver, а ещё пять машин, на каждой из которых работал только tserver.
Тестирование
YDB и YugabyteDB тестировали с помощью форка оригинальной реализации YCSB с драйверами YDB и YugabyteDB СQL. Обратите внимание, что мы взяли драйверы YugabyteDB из их собственного форка YCSB. Так как запускали несколько экземпляров YCSB параллельно, то применили этот патч, чтобы убедиться, что у всех экземпляров одинаковое распределение Zipfian.
Вот инструкции по запуску YCSB на YDB и инструкции по запуску YCSB на YugabyteDB.
Статья о YCSB описывает абстрактный интерфейс для драйверов баз данных в виде следующих операций:
read()— чтение одной записи из базы данных и возврат указанного набора полей или всех полей.insert()— вставка одной записи в базу данных.update()— обновление одной записи в базе данных, добавление или замена указанных полей.delete()— удаление одной записи из базы данных.scan()— выполнение сканирования диапазона, чтение указанного количества записей, начиная с заданного ключа записи.
По этому описанию в реализации можно использовать UPSERT или INSERT в функции insert() и UPDATE или UPSERT в функции update(). Вот цитата из оригинальной статьи, которая описывает нагрузку с чтением-модификацией-записью F и сравнивает её с нагрузкой с большим количеством обновлений A:»…мы также выполняем нагрузку с чтением-модификацией-записью, которая отражает часто используемый шаблон чтения записи, её изменения и сохранения изменений обратно в базу данных. Эта нагрузка схожа с нагрузкой A (соотношение чтение/запись — 50/50), за исключением того, что обновления выполняются через «чтение-модификация-запись», а не посредством слепой записи».
Этот выбор критически влияет на производительность, ведь UPSERT — это слепая запись, которая выполняется намного быстрее. По умолчанию YDB использует INSERT в функции insert () и UPSERT в функции update (). При правильном использовании эта комбинация может обеспечивать гораздо большую пропускную способность/задержку в неоднородных распределениях Zipfian или hot spot. Yugabyte CQL-драйвер использует UPSERT в обоих случаях.
Для измерения CockroachDB взяли их собственную реализацию YCSB, которая использует INSERT и UPDATE. При этом мы не нашли способ изменить его на комбинацию INSERT/UPSERT или UPSERT/UPSERT. Комбинация INSERT/UPDATE приводит к существенному снижению производительности. Особенно это влияет на нагрузку F с чтением-модификацией-записью, потому что она выполняется как чтение-чтение-модификация-запись.
В ходе тестирования при следующих нагрузках использовались одинаковые операции:
нагрузка C одинакова для всех баз данных;
нагрузки A, B и F одинаковы в YDB и Yugabyte;
нагрузки D и E одинаковы в YDB и CockroachDB.
Сравнивать результаты CockroachDB на нагрузках A, B и F с результатами других систем — всё равно что сравнивать яблоки с апельсинами. Приводим цифры только для того, чтобы продемонстрировать влияние пользовательского выбора операций на производительность.
YDB и YugabyteDB показывают аналогичные результаты при переключении на INSERT/UPDATE. Представим эти результаты в отдельном посте, а здесь сосредоточимся на самом быстром и масштабируемом решении, которое могут использовать разработчики приложений.
В нашем исследовании мы следовали рекомендуемому порядку загрузки данных и выполнения нагрузок. Мы загружаем исходные данные YCSB, затем запускаем нагрузки A, B, C, F и D. После этого мы загружаем данные снова (поскольку нагрузка D изменяет размер набора данных) и запускаем нагрузку E. Это позволяет нам сравнить результаты нагрузки C в базах данных со множеством строк, изменённых при выполнении нагрузок A и В. Это крайне важно, поскольку производительность чтения в «чистом» и «грязном» состояниях может сильно отличаться.
Наша цель — достичь максимальной пропускной способности при сохранении задержки ниже 50 мс. Поскольку кластер настолько велик, что один экземпляр YCSB не может генерировать соответствующую частоту запросов, мы запускаем несколько экземпляров YCSB на разных машинах. Так можно запускать все нагрузки, кроме D и E, для которых мы можем использовать только один экземпляр YCSB. Это означает, что если мы увеличим количество машин в кластере, то невозможно будет увеличить количество клиентов для создания более высокой нагрузки. Поэтому измеряем D и E только на кластере из трёх узлов и исключаем при увеличении размера кластера до восьми узлов.
Результаты

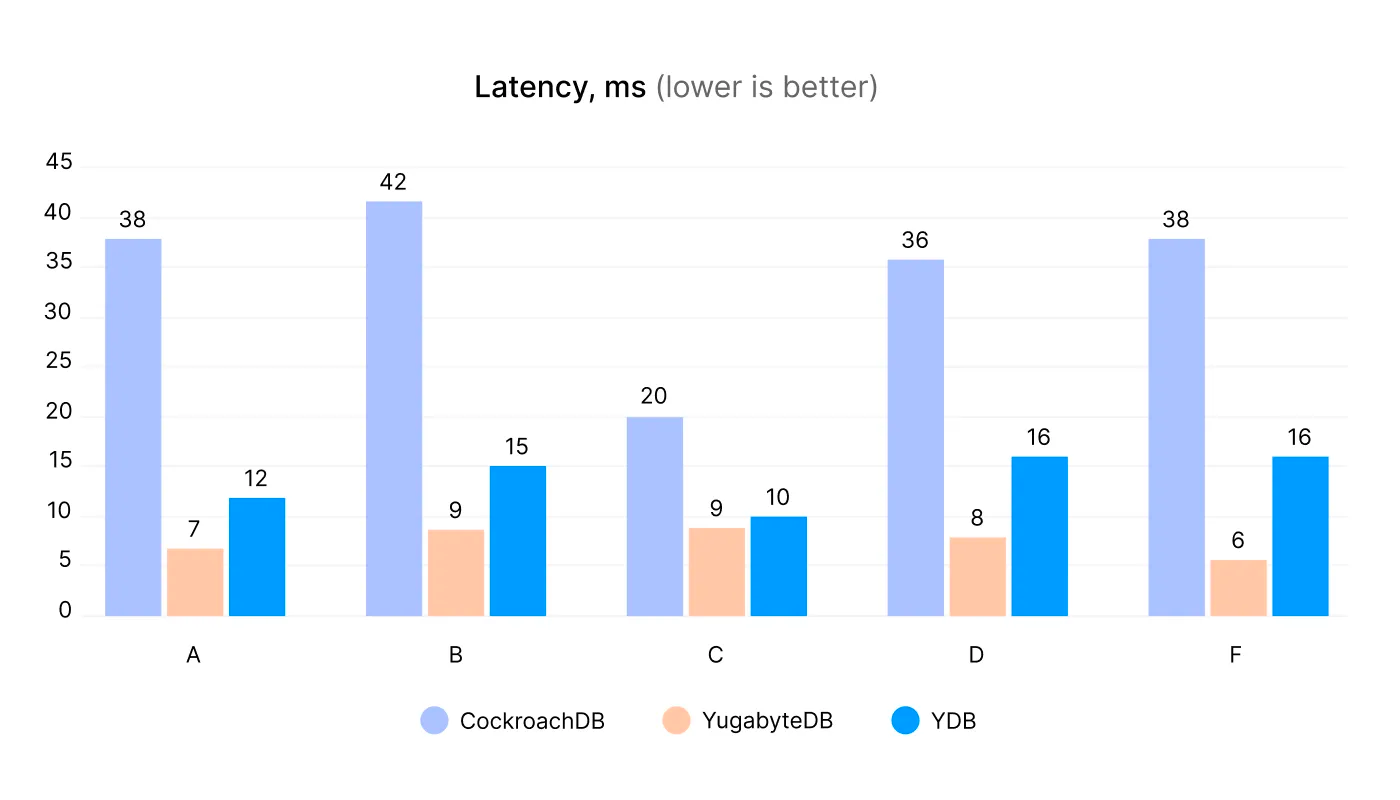
YCSB с размером данных в 300 млн строк, кластер из трёх серверов
300 миллионов строк — это примерно 300–400 ГБ данных. На графике показана пропускная способность в тысячах операций в секунду и задержка операций на 99%. Результаты:
YDB значительно превосходит своих оппонентов в нагрузке C (только чтение), одинаковой во всех реализациях YCSB.
YDB превосходит Yugabyte в нагрузках B и F, но проигрывает в нагрузке A (у всех одинаковая реализация).
YDB превосходит Yugabyte в нагрузке D (чтение последних значений), даже несмотря на то, что у них есть преимущество из-за использования UPSERT, а не INSERT.
YDB превосходит CockroachDB в нагрузке D и проигрывает в нагрузке E с короткими диапазонами.
Вертикальное масштабирование
300 миллионов строк — это не так уж много для кластера с 1,5 ТБ оперативной памяти. Даже при использовании NVMe чтение с диска по сравнению с кэшем может привести к снижению пропускной способности чтения. Поэтому мы увеличили размер данных с 300 млн до 2 млрд строк (около 2—3 ТБ данных). Помните, что это INSERT, а не UPSERT, как в YugabyteDB и YDB!


YCSB с размером данных в 2 млрд строк, кластер из трёх серверов
Первоначально мы хотели измерить только нагрузку C, состоящую исключительно из операций чтения, на которую в основном влияет нехватка оперативной памяти для кэширования. Запустили нагрузки A и B, только чтобы в базе были изменённые строки. Обнаружили, что у YugabyteDB странно и значительно снизилась производительность в нагрузках A и F с интенсивной записью.
Мы использовали точно такую же конфигурацию и перепроверили её с командой YugabyteDB. Обнаружили много неиспользуемых ресурсов. Сейчас команда YugabyteDB разбирается с этой проблемой — вот тикет в GitHub, можете на него подписаться.
Из-за этого ухудшения YDB превосходит обе БД во всех нагрузках, кроме нагрузки E. Мы обнаружили проблему с производительностью в реализации сканов и в ближайшее время планируем выпустить исправление, после чего повторно измерим эту нагрузку.
Горизонтальное масштабирование
Теперь мы увеличили количество машин с трёх до восьми и дополнительно запустили YDB с топологией block 4+2. На этот раз снова на 300 млн строк. Обратите внимание, что увеличить нагрузку, создаваемую D и E, невозможно, и мы исключили их в этом тестировании.

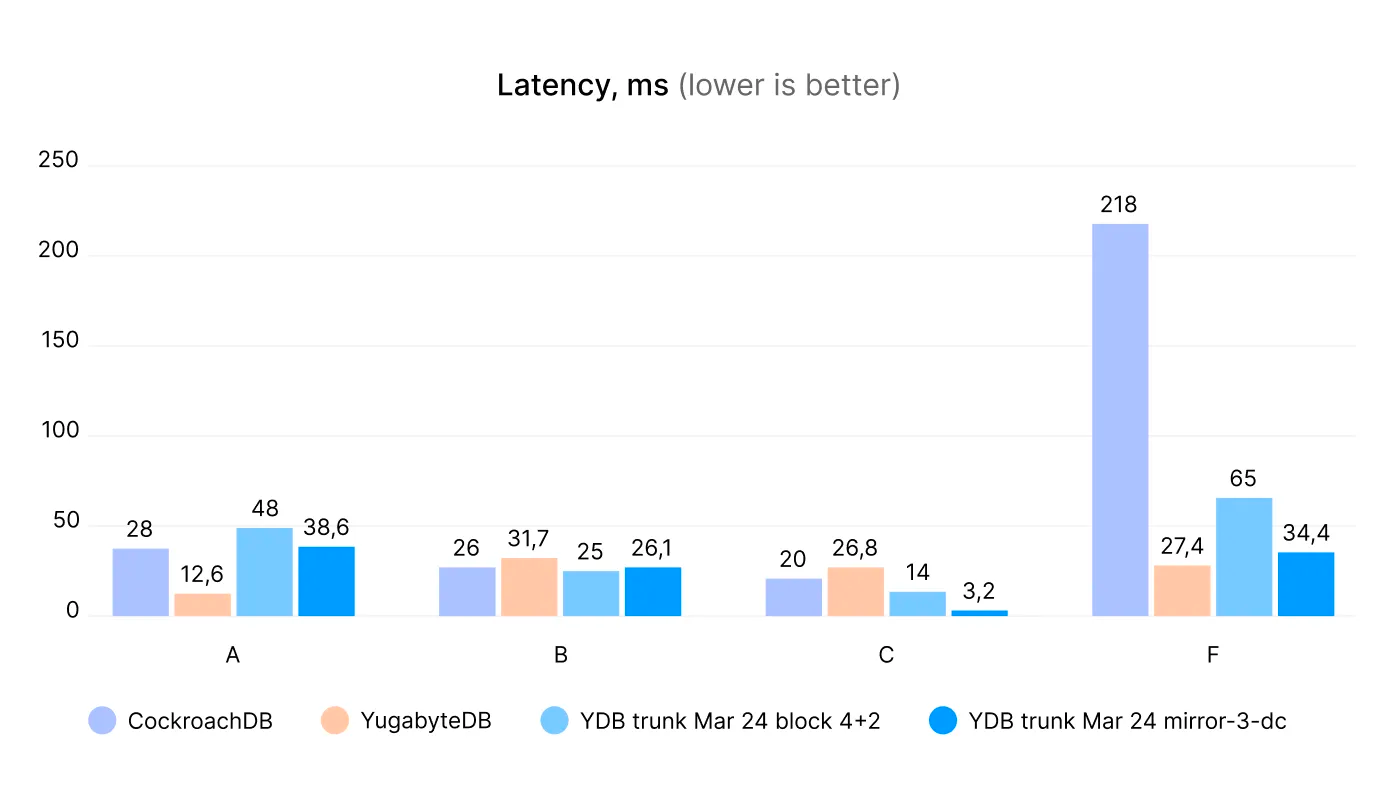
YCSB с размером данных в 300 млн строк, кластер из восьми серверов
Результаты схожи, за исключением того, что теперь Yugabyte немного превосходит YDB в нагрузке F:
YDB mirror-3-dc выигрывает в нагрузке C с большим отрывом, демонстрируя фантастически низкие задержки.
YDB block 4+2 немного медленнее, чем YDB mirror-3-dc, поскольку использует больше вычислительных ресурсов для выполнения erasure coding (напомним, что благодаря этому потребляетcя половина дискового пространства по сравнению с mirror-3-dc). Это компромисс между дисковым пространством и нагрузкой на процессор.
YDB block 4+2 п значительно превосходит CockroachDB и Yugabyte в нагрузке C и некоторых других.
Чтобы оценить масштабируемость, мы рассчитали запросы на ядро на основе результатов для кластера из трёх узлов и данных в 300 млн строк. Затем умножили это значение на количество ядер в восьмиузловом кластере, чтобы оценить пропускную способность в случае идеального линейного масштабирования.
Yugabyte продемонстрировала неоптимальное масштабирование в нагрузке C. YDB и CockroachDB показали отличную масштабируемость, достигнув коэффициентов 0,81 и 0,79 соответственно, в то время как YugabyteDB удалось достичь только 0,65.
Выводы
Все три СУБД показали хорошую производительность, но ни одна из них не выиграла во всех видах нагрузок и на всех размерах данных.
Мы рекомендуем YDB для нагрузок с преобладающим чтением, поскольку, согласно результатам YCSB, она отлично справляется с этими сценариями. Не стоит беспокоиться, если паттерн нагрузки со временем изменится: YDB обеспечивает производительность, сопоставимую с YugabyteDB и CockroachDB.
Если у вас только один дата-центр или зона доступности, стоит всерьёз подумать об использовании YDB block 4+2. Это обеспечит отличную производительность и потребует вдвое меньше дискового пространства по сравнению с тройной репликацией при том же уровне допустимых отказов. SSD и NVMe-диски довольно дорогие, а YDB block 4+2 позволяет значительно сократить расходы на них.
Благодарим разработчиков CockroachDB и YugabyteDB за помощь в настройке систем и анализе результатов.
