[Перевод] Сравнение Google TPUv2 и Nvidia V100 на ResNet-50

Недавно Google добавила к списку облачных услуг Tensor Processing Unit v2 (TPUv2) — процессор, специально разработанный для ускорения глубокого обучения. Это второе поколение первого в мире общедоступного ускорителя глубокого обучения, который претендует на альтернативу графическим процессорам Nvidia. Недавно мы рассказывали о первых впечатлениях. Многие просили провести более детальное сравнение с графическими процессорами Nvidia V100.
Объективно и осмысленно сравнить ускорители глубокого обучения — нетривиальная задача. Но из-за будущей важности этой категории продуктов и отсутствия подробных сравнений мы чувствовали необходимость провести самостоятельные тесты. Сюда входит и учёт мнений потенциально противоположных сторон. Вот почему мы связались с инженерами Google и Nvidia — и предложили им прокомментировать черновик этой статьи. Чтобы гарантировать отсутствие предвзятости, мы пригласили также независимых экспертов. Благодаря этому получилось, насколько нам известно, самое полное на сегодняшний день сравнение TPUv2 и V100.
Экспериментальная установка
Ниже сравниваются четыре TPUv2 (которые образуют один Cloud TPU) с четырьмя Nvidia V100. У обоих полная память 64 ГБ, поэтому на них можно обучать одинаковые модели с одинаковым объёмом обучающей выборки. В экспериментах мы обучаем модели одинаково: четыре TPUv2 в Cloud TPU и четыре V100 выполняют задачу синхронного параллельного распределённого обучения.
В качестве модели мы выбрали ResNet-50 на ImageNet, стандарт де-факто и ориентир для классификации изображений. Эталонные реализации ResNet-50 являются общедоступными, но ни одна из них не поддерживает обучение одновременно и на Cloud TPU, и на нескольких GPU.
Nvidia рекомендует для нескольких V100 использовать MXNet или реализации TensorFlow, доступные в виде образов Docker на облаке Nvidia GPU Cloud. К сожалению, выяснилось, что обе реализации не очень хорошо сходятся с настройками по умолчанию при работе на нескольких GPU с большими обучающими выборками. Необходимо вносить изменения, в частности, в скорость обучения (learning rate schedule).
Вместо этого, мы взяли реализацию ResNet-50 из репозитория бенчмарков TensorFlow и запустили её как образ Docker (tensorflow/tensorflow:1.7.0-gpu, CUDA 9.0, CuDNN 7.1.2). Она значительно быстрее, чем рекомендованная Nvidia реализация TensorFlow и лишь немного уступает (примерно на 3%, см. ниже) реализации MXNet. Зато хорошо сходится. К тому же появляется дополнительное преимущество, что мы сравниваем две реализации на одинаковой версии фреймворка (TensorFlow 1.7.0).
Google рекомендует использовать для Cloud TPU реализацию bfloat16 с TensorFlow 1.7.0 из официального репозитория TPU. В обеих реализациях — TPU и GPU — используются вычисления смешанной точности на соответствующей архитектуре, а большинство тензоров хранится в числах половинной точности.
Тесты V100 запускались на инстансе p3.8xlarge (16 ядер Xeon E5–2686@2.30GHz, 244 ГБ памяти, Ubuntu 16.04) на AWS с четырьмя V100 GPU (у каждого по 16 ГБ памяти). Тесты TPU запускались на маленьком инстансе n1-standard-4 (2 ядра Xeon@2.3GHz, 15 ГБ памяти, Debian 9), для которых выделен Cloud TPU (v2–8) из четырёх TPUv2 (у каждого по 16 ГБ памяти).
Мы провели два разных сравнения. Во-первых, изучили производительность с точки зрения пропускной способности (изображений в секунду) на синтетических данных без аугментации, то есть без создания дополнительных обучающих данных из имеющихся данных. Это сравнение не зависит от сходимости, здесь нет узких мест в I/O, а аугментация данных не влияет на результат. Во втором сравнении рассмотрели точность и сходимость двух реализаций на ImageNet.
Тест пропускной способности
Мы измерили пропускную способность по количеству изображений в секунду на синтетических данных, то есть с созданием данных для обучения на лету, при различных размерах выборки (batch size). Заметьте, что для TPU рекомендуется только размер выборки 1024, но по многочисленным просьбам читателей мы сообщаем и остальные результаты.

Производительность (изображений в секунду) на различных размерах выборки на синтетических данных и без аугментации. Размеры выборки «глобальные», то есть 1024 означает размер 256 на каждом из чипов GPU/TPU на каждом шаге
При размере обучающей выборки 1024 практически отсутствует разница в пропускной способности! TPU лишь немного впереди с разницей около 2%. На меньших размерах обучающей выборки происходит падение пропускной способности на обеих платформах, а графические процессоры работают чуть лучше. Но как упоминалось выше, такие размеры обучающей выборки в настоящее время не рекомендуются для TPU.
Следуя рекомендации Nvidia, мы провели эксперимент с GPU на MXNet. Использовалась реализация ResNet-50 в образе Docker (mxnet:18.03-py3), доступном в облаке Nvidia GPU Cloud. С размером обучающей выборки 768 (1024 слишком много) GPU обрабатывают около 3280 изображений в секунду. Это примерно на 3% быстрее, чем лучший результат для TPU. Но как упоминалось выше, реализация MXNet не очень хорошо сходится на нескольких GPU с таким размером обучающей выборки, поэтому здесь и ниже сосредоточимся на реализации TensorFlow.
Стоимость в облаке
Cloud TPU (четыре микросхемы TPUv2) в настоящее время доступен только в облаке Google. Он подключается по запросу к любому инстансу VM только когда требуются такие вычисления. Для V100 мы рассмотрели облачное решение от AWS (V100 ещё не доступны в облаке Google). Основываясь на результатах выше, мы можем нормализовать количество изображений в секунду за доллар для каждой платформы и провайдера.
Производительность: изображений в секунду на доллар
| Cloud TPU | 4 × V100 | 4 × V100 | |
|---|---|---|---|
| Облако | Облако Google | AWS | Зарезервированный инстанс AWS |
| Цена за час | $6,7 | $12,2 | $8,4 |
| Изображений в секунду | 3186 | 3128 | 3128 |
| Производительность (изображений в секунду на доллар) | 476 | 256 | 374 |
С такими ценами Cloud TPU выходит явным победителем. Тем не менее, ситуация может выглядеть по-другому, если вы рассматриваете аренду на более длительный срок или покупку оборудования (хотя в данный момент такой вариант недоступен для Cloud TPU). Таблица вверху также включает цену зарезервированного инстанса p3.8xlarge на AWS при аренде на 12 месяцев (без предоплаты). Это значительно снижает цену до 374 изображений/с на $.
Для GPU есть и другие интересные варианты. Например, Cirrascale предлагает ежемесячную аренду сервера с четырьмя V100 примерно за $7500 (около ~$10,3 в час). Но для прямого сравнения требуются дополнительные тесты, поскольку это оборудование отличается от оборудования на AWS (тип CPU, память, поддержка NVLink и т.д.).
Точность и сходимость
В дополнение к отчётам производительности мы хотели проверить, что вычисления на самом деле «осмысленны», то есть реализации сходятся к хорошим результатам. Поскольку сравнивались две разные реализации, можно ожидать некоторого отклонения. Поэтому наше сравнение — это не только показатель скорости оборудования, но и качества реализации. Например, реализация TPU предполагает очень ресурсоёмкие шаги предварительной обработки и фактически жертвует пропускной способностью. По информации Google, это ожидаемое поведение. Как увидим ниже, оно оправдано.
Мы обучили модели на наборе данных ImageNet, где задача состоит в том, чтобы классифицировать изображение в одну из 1000 категорий, таких как колибри, буррито или пицца. Набор данных состоит из 1,3 миллиона изображений для обучения (~142 ГБ) и 50 000 изображений для валидации (~7 ГБ).
Обучение идёт 90 эпох с размером выборки 1024, после чего результаты сравниваются с контрольными данными. Реализация TPU последовательно обрабатывает около 2796 изображений в секунду, а реализация GPU — около 2839 изображений в секунду. Это отличается от предыдущих результатов пропускной способности, где мы отключили аугментацию и использовали синтетические данные для сравнения чистой скорости TPU и GPU.

Точность топ-1 (т.е. для каждого изображения учитывается только предсказание с наибольшей уверенностью) двух реализаций после 90 эпох
Как показано выше, точность топ-1 после 90 эпох для реализации TPU на 0,7 п.п. лучше. Это может показаться незначительным, но добиться улучшения на этом очень высоком уровне чрезвычайно сложно. В зависимости от приложения такие небольшие улучшения могут значительно повлиять на результат.
Давайте посмотрим на точность топ-1 в разных эпохах во время обучения моделей.
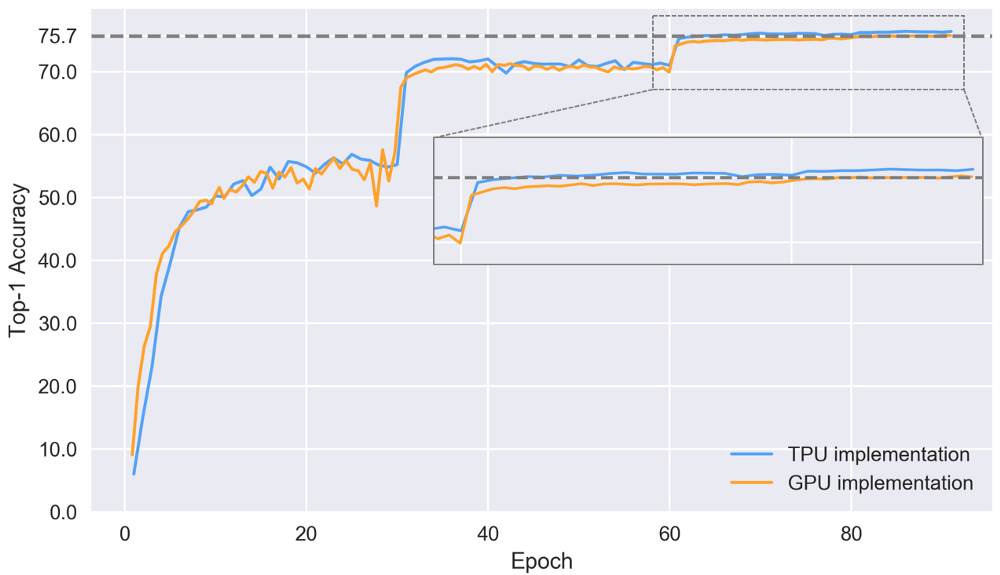
Точность топ-1 на контрольном наборе для двух реализаций
Резкие изменения в приведённом выше графике совпадают с изменениями в скорости обучения. Тенденция сходимости лучше в реализации TPU. Здесь финальная точность достигается 76,4% после 86 эпох. Реализация GPU отстаёт и достигает финальной точности 75,7% после 84 эпох, тогда как для достижения такой точности на TPU требуются лишь 64 эпохи. Вероятно, улучшение конвергенции TPU связано с лучшей предварительной обработкой и аугментацией данных, но для подтверждения этой гипотезы необходимы дополнительные эксперименты.
Экономически выгодное решение на основе облачных цен
В конечном счёте имеют значение время и стоимость, необходимые для достижения определённой точности. Если взять решение на уровне 75,7% (лучшая точность, достигнутая реализацией GPU), то можно рассчитать стоимость достижения этой точности на основе требуемых эпох и скорости обучения в изображениях в секунду. Это исключает время для оценки модели в промежутках между эпохами и время на запуск обучения.

Цена для достижения точности топ-1 75,7%. *Зарезервирован на 12 месяцев
Как показано выше, текущая ценовая политика Cloud TPU позволяет обучить модель с нуля до точности 75,7% по ImageNet менее чем за 9 часов за $55! Обучение до сходимости 76,4% стоит $73. Хотя V100 работают так же быстро, но более высокая цена и более медленная сходимость приводят к значительно более высокой стоимости решения.
Опять же, обратите внимание, что сравнение зависит от качества реализации, а также от цены облака.
Интересно было бы сравнить разницу в энергопотреблении. Но в настоящее время нет общедоступной информации о потреблении энергии TPUv2.
Вывод
Что касается базовой производительности на ResNet-50, то четыре чипа TPUv2 (один модуль Cloud TPU) и четыре графических процессора V100 в наших тестах одинаково быстры (разница в пределах 2%). Вероятно, за счёт будущих оптимизаций ПО (например, TensorFlow или CUDA) производительность улучшится, а соотношение изменится.
Однако на практике чаще всего главное — это время и финансовые затраты, необходимые для достижения определённой точности на конкретной задаче. Текущее ценообразование Cloud TPU в сочетании с великолепной реализацией ResNet-50 приводят к впечатляющим результатам по времени и стоимости на ImageNet, что позволяет обучить модель до точности 76,4% примерно за 73 доллара.
Для детального сравнения нужны бенчмарки на моделях из других областей и с разными сетевыми архитектурами. Ещё интересно понять, сколько усилий требуется, чтобы эффективно использовать каждую аппаратную платформу. Например, вычисления со смешанной точностью сопровождаются существенным увеличением производительности, но по-разному реализуются на GPU и TPU.
