[Перевод] Создание облачной сети: не все так просто
 Примечание переводчика: Инженер сервиса сетевого мониторинга Ruxit Алоиз Майр написал интересный материал о сложностях, с которыми могут столкнуться новички при организации сети в облаке, а мы подготовили его адаптированный перевод.
Примечание переводчика: Инженер сервиса сетевого мониторинга Ruxit Алоиз Майр написал интересный материал о сложностях, с которыми могут столкнуться новички при организации сети в облаке, а мы подготовили его адаптированный перевод.
Если ваши приложения работают на AWS [англ. Amazon Web Services] или одной из подобных облачных платформ (таких, как 1cloud), значит, вы, помимо прочего, успешно «переложили» работу со своей сетью на облачные сервисы. Естественно, для вас это может быть очень ценным, в первую очередь потому, что вам не нужно поддерживать физическую инфраструктуру сети. Однако отсутствие непосредственного доступа к сети не означает, что за ней совсем не нужно следить.
Немного историиВ традиционных типах архитектуры приложений инфраструктура сети находилась под строгим контролем команды специалистов. Такие команды отвечали за замену перегруженного оборудования до возникновения каких-либо проблем, выявление и устранение слабых звеньев в сети, решение проблем ограничения производительности, отслеживание параметров задержки при передаче данных и даже обнаружение угроз безопасности сети. Другими словами, обычные команды специалистов по работе с сетями следили за всеми семью уровнями модели OSI.Современные архитектуры нуждаются в сетевых технологиях сильнее, чем когда-либо В архитектурах с использованием облачных технологий ситуация обстоит иначе, и теперь применение сетей играет гораздо большую роль. Представьте себе обычную архитектуру, использующую облачные сервисы. Вы управляете дата-центром с непостоянным числом выделенных для работы вычислительных машин (зависящим, например, от механизма ценообразования и меняющихся требований к процессору). Ваш дата-центр обслуживает распределенные приложения, которые разработаны, к примеру, на основе микросервисов. Кроме этого, ваши приложения распределены, скажем, с помощью Docker-контейнеров, что дает вашей команде, придерживающейся методологии DevOps [англ. Development Operations], некоторую свободу действий. В таких ситуациях наличие сетей необходимо как никогда. Ваша сеть должна взять на себя все коммуникации, необходимые для связи микросервисов. Она служит виртуальной «нервной системой» для ваших приложений.Даже несмотря на то, что системные администраторы не имеют непосредственного доступа к сети, тем не менее, она работает и требует к себе внимания. Зачастую сложно выяснить, где ваши серверы размещаются физически или как они связаны с другими узлами в вашей сети. Виртуальные машины и службы, связанные между собой, могут даже размещаться на одном виртуальном хосте; в этом случае ваша сеть сможет лишь считывать данные из памяти. Это значит, что довольно часто физическая сеть связана с несколькими виртуальными сетями.
Сложности при работе с сетями, использующими облачные сервисы Из-за отсутствия непосредственного доступа к сети (уровни 1–2 модели OSI) командам, придерживающимся принципов DevOps, довольно сложно за ней следить. Они могут воспользоваться средствами для мониторинга, предлагаемыми облачными провайдерами, например, Cloud Watch, считывающим такие показатели работы сети, как NetworkIn и NetworkOut, однако этих показателей может быть недостаточно для выявления проблем в сети.Ниже перечислены некоторые из основных сложностей, возникающих при использовании методологии DevOps для поддержания производительности виртуальных сетей:
Распределение сетевых ресурсов между конкурирующими процессами (например, проблема, известная под названием TCP Incast);
Изменяющаяся сетевая инфраструктура при наличии новых или приостановленных объектов;
Масштабируемость сети при помощи сетевых интерфейсов ENI [англ. Elastic Network Interfaces];
Качество внутренних соединений дата-центра;
Качество соединений с частными сетями, расположенными вне дата-центра.
Мониторинг использования сети
При осуществлении мониторинга сети вы должны уметь адаптироваться к изменениям в инфраструктуре, упомянутым выше. В частности, нужно уметь работать с виртуальными сетевыми интерфейсами. В связи с этим мониторинг необходимо осуществлять на своих хостах, и при этом постоянно следить за изменениями виртуальной инфраструктуры. В этом случае вы можете отслеживать сетевые соединения между процессами, связанными с другими процессами и службами, таким образом осуществляя мониторинг фактического использования сети, не только сетевых устройств.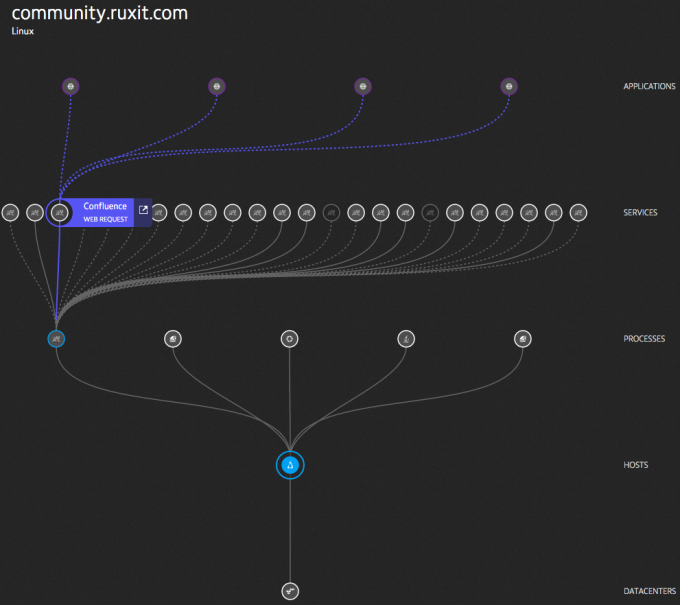
Мониторинг ресурсов очень важен… и прост!
При таком подходе к мониторингу ваша сеть не будет рассматриваться лишь как совокупность сетевых интерфейсов, таблиц маршрутизации и групп безопасности. Вместо этого ваша сеть будет рассматриваться как ограниченный ресурс, используемый процессами и приложениями. С точки зрения процессов, этот ресурс поддается мониторингу наряду с центральным процессором, оперативной и внешней памятью, и даже может быть оценен количественно. Кроме этого, проводится мониторинг производительности полностекового приложения и появляется возможность обнаружения неполадок в сети вплоть до уровня приложений.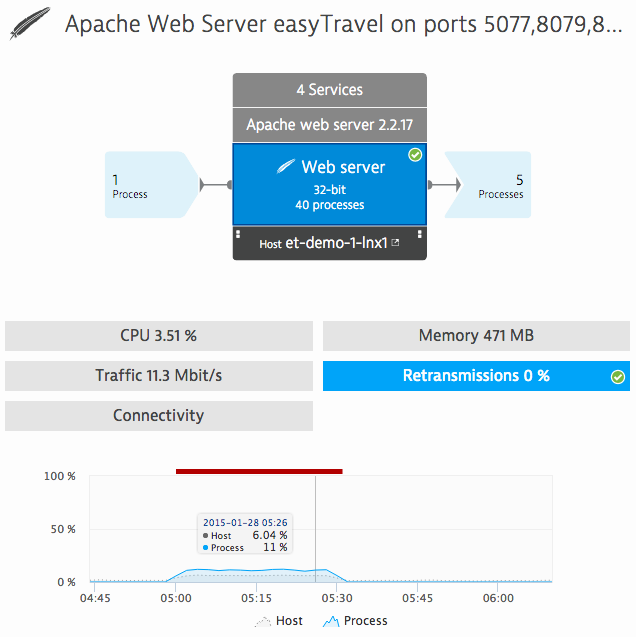
Ниже представлены несколько основных показателей производительности сети, которые следует учитывать:
Основным показателем производительности сети является трафик данных в сети (пропускная способность). Показатель сетевого взаимодействия определяет долю успешно завершенных соединений по протоколу TCP и свидетельствует о доступности служб. Соединение по протоколу TCP может быть прервано или завершено с тайм-аутами, поэтому отсутствие подключения является ярким признаком возникновения проблем между отправителем и получателем в сети. При определении качества установленных соединений по протоколу TCP также следует обратить внимание на частоту повторной передачи данных. Назначением протокола TCP является надежное соединение и обнаружение ошибок при передаче данных. Это означает, что получатель должен дать согласие на получение пакетов данных, пересылаемых по сетевой линии связи; в противном случае они считаются потерянными и затем повторно пересылаются отправителем. Таким образом, частота повторной передачи данных указывает на наличие слабых звеньев в сети и перегруженность ее инфраструктуры. Виртуализированные сети не поддаются более или менее традиционным методам управления. За ними нужно следить, по крайней мере, с точки зрения ваших хостов и процессов, чтобы у вас имелись эффективные показатели производительности сети.
