[Перевод] Создание мультидокументного ридера и чат-бота с помощью LangChain и ChatGPT
Что самое интересное — чат-бот будет помнить историю ваших разговоров.
Мы начнём с простого чат-бота, который может взаимодействовать только с одним документом; и закончим более продвинутым чат-ботом, который может взаимодействовать с несколькими различными документами и типами документов, а также сохранять историю чата — чтобы он мог отвечать на вопросы в контексте последних бесед.
Содержание
Как работает чат-бот?
Взаимодействие с одним PDF-файлом
Взаимодействие с одним PDF с использованием эмбеддингов и векторных хранилищ
Добавление истории чата
Взаимодействие с несколькими документами
Улучшения
Заключение
Как это работает?
Если говорить в общем, как функционирует чат-бот для работы с документами? По своей сути это то же самое, что и ChatGPT. В ChatGPT вы можете в промпт поместить большой отрывок текста и попросить ChatGPT дать написать краткое содержание или сгенерировать ответы на основе текста.
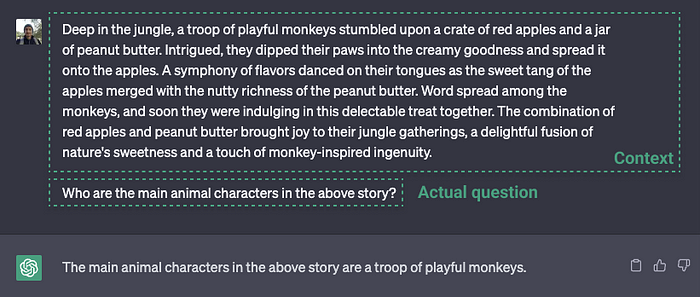
Пример передачи контекста и вопроса в ChatGPT
Взаимодействие с отдельным документом, например PDF, Microsoft Word или текстовым файлом, происходит аналогичным образом. Мы извлекаем весь текст из документа, передаём его в качестве промпта в LLM, например ChatGPT, а затем задаём вопросы по тексту. Точно так же работает пример с ChatGPT, приведённый выше.
Взаимодействие с несколькими документами
Когда документ очень большой или их несколько, становится немного интереснее. Передать всю информацию из этих документов в промпте к LLM невозможно, так как запросы обычно имеют ограничения по размеру (определённый лимит по токенам), поэтому передать слишком много информации — не получится.
Чтобы выйти из ситуации, можно отправить в промпте только релевантную информацию. Но как её получить из документов? Здесь на помощь приходят эмбеддинги и векторные хранилища.
Эмбеддинги и векторные хранилища
Итак, нам нужно отправлять в промпте только релевантную информацию из документов. В этом помогут эмбеддинги и векторные хранилища.
Эмбеддинг позволяет организовать и классифицировать текст на основе его семантического значения. Поэтому мы разбиваем документы на множество маленьких текстовых фрагментов и используем эмбеддинги, чтобы охарактеризовать каждый фрагмент текста по его семантическому значению. Для преобразования фрагмента текста в эмбеддинг используется трансформер.
Эмбеддинг классифицирует фрагмент текста, придавая ему векторное (координатное) представление. Это означает, что векторы (координаты), расположенные близко друг к другу, представляют фрагменты информации, которые имеют схожее значение. Векторы хранятся в векторном хранилище вместе с фрагментами текста, соответствующими каждому эмбеддингу.
Подготовив промпт, мы можем использовать трансформер, чтобы создать из него эмбеддинг (вектор). Далее сопоставить его с наиболее семантически релевантными ему фрагментами текста, найдя другие близлежащие эмбеддинги (векторы). Итак, теперь у нас есть способ сопоставить наш промпт с другими фрагментами текста из хранилища векторов. Мы используем трансформер от OpenAI, который применяет метод косинусного сходства для расчёта сходства между документами и вопросом.
Теперь, когда у нас есть небольшое подмножество информации, релевантной промпту, мы можем сделать запрос к LLM с помощью первоначального промпта, передавая только релевантную информацию в качестве контекста для нашего промпта.
Именно это позволяет нам преодолеть ограничение по размеру промптов к LLM. Мы используем эмбеддинги и векторное хранилище, чтобы передать только релевантную информацию, связанную с запросом, и позволить ему ответить нам на основе этой информации.
Как же это сделать в LangChain? К счастью, LangChain предоставляет эту функциональность из коробки, и с помощью нескольких коротких вызовов методов мы можем приступить к работе. Давайте начнём!
Взаимодействие с одним PDF-файлом
Начнём с обработки одного PDF-файла, а позже перейдём к обработке нескольких документов.
Первым шагом будет создание Document из PDF. Document — это базовый класс в LangChain, который цепочки используют для взаимодействия с информацией. Если мы посмотрим на определение класса Document, то увидим, что это очень простой класс, только с методом page_content, который позволяет получить доступ к текстовому содержимому Document.
class Document(BaseModel):
"""Interface for interacting with a document."""
page_content: str
metadata: dict = Field(default_factory=dict)Мы используем DocumentLoaders, предоставляемый LangChain, чтобы преобразовать источник контента в список Documents, по одному Document на страницу.
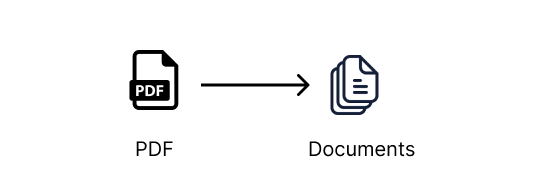
Например, есть DocumentLoaders, которые можно использовать для преобразования PDF, документов в формате Word, текстовых файлов, CSV, источников Reddit, Twitter, Discord и многого другого в список документов, с которыми затем смогут работать цепочки LangChain. Это крутые источники, так что нам есть с чем поэкспериментировать.
Для начала давайте создадим директорию для проекта. Вы можете создать всё это по ходу дела или клонировать этот репозиторий GitHub со всеми примерами и документацией с помощью команды, приведённой ниже. Если вы клонируете репозиторий, обязательно следуйте инструкциям в файле README.md, чтобы правильно настроить ключ OpenAI API.
git clone git@github.com:smaameri/multi-doc-chatbot.gitЛибо можно следовать командам:
mkdir multi-doc-chatbot
cd multi-doc-chatbot
touch single-doc.py
mkdir docs
# lets create a virtual environement also to install all packages locally only
python3 -m venv .venv
. .venv/bin/activateЗатем скачайте образец CV RachelGreenCV.pdf отсюда и сохраните его в папке docs.
Давайте установим все пакеты, которые нам понадобятся для установки:
pip install langchain langchain-openai pypdf openai chromadb tiktoken docx2txtТеперь, когда папки наших проектов настроены, преобразуем наш PDF в документ. Для этого будем использовать класс PyPDFLoader. Также настроим API-ключ OpenAI — он понадобится нам позже.
import os
from langchain_community.document_loaders import PyPDFLoader
os.environ["OPENAI_API_KEY"] = "sk-"
pdf_loader = PyPDFLoader('./docs/RachelGreenCV.pdf')
documents = pdf_loader.load()Это возвращает список Document’s, по одному документу для каждой PDF-страницы. С точки зрения типов Python, он вернёт List[Document]. Таким образом, индекс списка будет соответствовать странице документа, например, documents[0]для первой страницы, documents[1]для второй и так далее.
Самая простая реализация цепочки вопросов и ответов, которую можно использовать, — это load_qa_chain. Она загружает цепочку, в которую можно передать все документы, к которым вы хотите сделать запрос.
from langchain.chains.question_answering import load_qa_chain
from langchain_openai import OpenAI
# указываем, что OpenAI - это LLM, который мы хотим использовать в нашей цепочке
chain = load_qa_chain(llm=OpenAI())
query = 'Who is the CV about?'
response = chain.invoke({"input_documents": documents, "question": query})
print(response["output_text"])Чтобы получить ответ, запустите этот скрипт:
➜ multi-doc-chatbot: python3 single-doc.py
The CV is about Rachel Green.На самом деле в фоновом режиме текст документа (т. е. PDF) отправляется в OpenAPI Chat API вместе с запросом, и всё это в одном запросе.
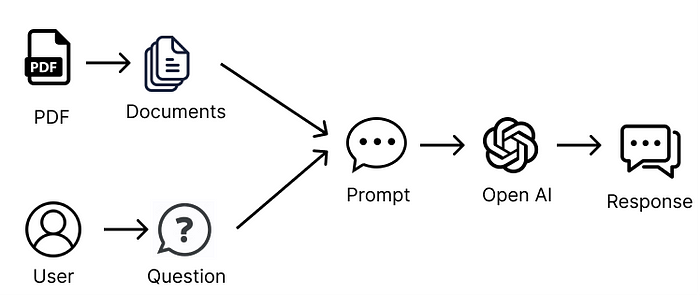
Передача всего текста из исходных документов в промпт
Кроме того, load_qa_chain фактически оборачивает весь промпт в текст, указывая LLM использовать только информацию из предоставленного контекста. Таким образом, промпт, отправляемый в OpenAI, выглядит примерно так (прим. пер: приводим на английском и русском языке):
Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to
make up an answer.
{context} // i.e the pdf text content
Question: {query} // i.e our actualy query, 'Who is the CV about?'
Helpful Answer:Используй следующие фрагменты контекста, чтобы ответить на вопрос в конце.
Если не знаешь ответа — просто скажи, что не знаешь, не пытайся
придумывать ответ.
{context} // т. е. текстовое содержимое pdf.
Вопрос: {запрос} // т.е. наш актуальный запрос «Чьё это CV?»
Полезный ответ:Поэтому, если вы попробуете задать случайные вопросы, например «Где находится Париж?», чат-бот ответит, что не знает.
Чтобы отобразить весь промпт, который отправляется в LLM, можно установить флаг verbose=True в методе load_qa_chain(), который выведет в консоль всю информацию, которая на самом деле отправляется в промпте. Это поможет понять, как всё работает в фоновом режиме, и какой промпт на самом деле отправляется в OpenAI API.
chain = load_qa_chain(llm=OpenAI(), verbose=True)Как мы уже говорили в начале, этот метод хорош, когда нужно отправить в контексте небольшой объём информации. Большинство LLM имеют ограничение на количество информации, которое можно отправить в одном запросе. Поэтому отправить всю информацию из документов за один запрос не получится.
Чтобы решить эту проблему, нам нужен умный способ отправить только ту информацию, которая, по нашему мнению, будет иметь отношение к нашему вопросу/промпту.
Взаимодействие с одним PDF-файлом с помощью эмбеддингов
Эмбеддинги — в помощь!
Как объяснялось ранее, мы можем использовать эмбеддинги и векторные хранилища для отправки только релевантной информации в промпте. Для этого нужно выполнить следующие шаги:
Разделить все документы на небольшие фрагменты текста;
Передать каждый фрагмент текста в трансформер, чтобы превратить его в эмбеддинг;
Хранить эмбеддинги и связанные с ними фрагменты текста в векторном хранилище.
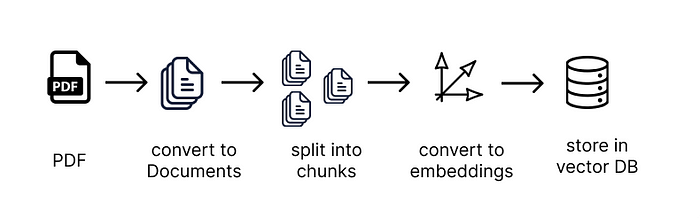
Давайте приступим!
Для начала создадим новый файл single-long-doc.py, чтобы обозначить, что этот скрипт можно использовать для работы со слишком длинными PDF-файлами, чтобы передать их в качестве контекста в промпт.
touch single-long-doc.pyТеперь добавьте в файл следующий код. Шаги объясняются в комментариях к коду. Не забудьте добавить API-ключ.
import os
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
os.environ["OPENAI_API_KEY"] = "sk-"
# загрузите документ, как раньше
loader = PyPDFLoader('./docs/RachelGreenCV.pdf')
documents = loader.load()
# Мы разбили данные на фрагменты по 1 000 символов с перекрытием 200 символов
# между фрагментами, что позволяет получить более точные результаты и
# сохранить контекст информации между фрагментами
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
documents = text_splitter.split_documents(documents)
# мы создаём векторную базу данных, используя трансформер OpenAIEmbeddings
# для создания эмбеддингов из текстовых фрагментов. Мы установили, что
# вся информация о БД будет храниться в директории ./data, чтобы
# не загромождать наши исходные файлы
vectordb = Chroma.from_documents(
documents,
embedding=OpenAIEmbeddings(),
persist_directory='./data'
)
vectordb.persist()После загрузки контента в виде эмбеддингов в векторное хранилище мы возвращаемся к ситуации, аналогичной той, когда у нас был только один PDF-файл. Теперь мы готовы передать информацию в промпте. Однако вместо того, чтобы передавать цепочке все documents в качестве источника контекста, как мы делали изначально, мы передадим наше векторное хранилище в качестве источника, который цепочка будет использовать для извлечения только релевантного текста, основанного на нашем вопросе, и отправит эту информацию только в промпте.
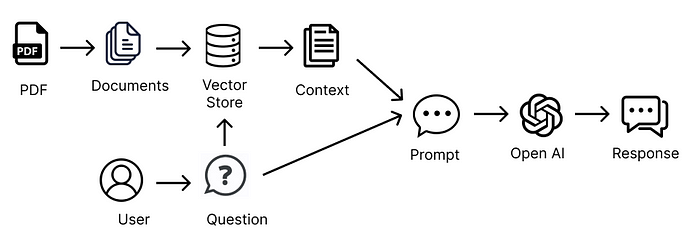
Построение промпта с использованием только релевантной информации из источников-документов
На этот раз мы воспользуемся цепочкой RetrievalQA, которая может использовать векторное хранилище в качестве источника контекстной информации.
И снова цепочка обернёт наш промпт текстом, предписывающим ей использовать только предоставленную информацию для ответа на вопросы. Таким образом, в итоге мы отправим промпт, который будет выглядеть примерно так:
Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to
make up an answer.
{context} // i.e the chunks of text retrieved deemed to be moset semantically
// relevant to our question
Question: {query} // i.e our actualy query
Helpful Answer:Используй следующие фрагменты контекста, чтобы ответить на вопрос в конце.
Если не знаешь ответа — просто скажи, что не знаешь, не пытайся придумывать
ответ.
{context} // т. е. извлеченные фрагменты текста, которые считаются семантически
// релевантными нашему вопросу.
Вопрос: {запрос} // т.е. наш реальный запрос
Полезный ответ:Итак, давайте создадим цепочку RetrievalQA и сделаем несколько запросов к LLM. Мы создаём цепочку RetrievalQA, передавая в качестве источника информации векторное хранилище. По сути, она будет извлекать из векторного хранилища только релевантные данные, основываясь на семантическом сходстве между промптом и хранимой информацией.
Обратите внимание, что мы задали search_kwargs={‘k’: 7}на нашем ретривере (retriever), что означает, что мы хотим отправить семь фрагментов текста из векторного хранилища в промпт. Если мы отправим больше, то превысим лимит токенов в OpenAI. Но чем больше у нас будет информации, тем точнее будут ответы, поэтому мы хотим отправлять как можно больше. В этой статье вы найдёте полезную информацию о настройке параметров LLM.
from langchain.chains import RetrievalQA
from langchain_openai import OpenAI
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(),
retriever=vectordb.as_retriever(search_kwargs={'k': 7}),
return_source_documents=True
)
# Теперь можно выполнять запросы к нашей цепочке вопросов и ответов
result = qa_chain.invoke({'query': 'Who is the CV about?'})
print(result['result'])Теперь запустите скрипт, и вы увидите результат.
➜ multi-doc-chatbot python3 single-long-doc.py
Rachel Green.Отлично! Теперь у нас есть устройство для чтения документов и чат-бот, работающий с использованием эмбеддингов и векторных хранилищ!
Обратите внимание, что мы установили persist_directory для векторного хранилища в ./data. Таким образом, это место, где база данных векторов будет хранить всю свою информацию, включая векторы эмбеддингов, которые она генерирует, и фрагменты текста, связанные с каждым из эмбеддингов.
Если вы откроете каталог data в корневой папке проекта, то увидите в нём все файлы DB. Круто, конечно! Как и у базы данных MySQL или Mongo, у неё есть свои собственные каталоги, в которых хранится вся информация.
Если вы изменили код или хранимые документы, и ответы чат-бота стали выглядеть странно, попробуйте удалить эту директорию, и она воссоздастся при следующем запуске скрипта. Иногда это помогает справиться со странными ответами.
Добавление истории чата
Теперь, если мы хотим продвинуться на ещё один шаг, можно сделать так, чтобы наш чат-бот запоминал все предыдущие вопросы.
Реализация заключается в том, что при каждом взаимодействии с чат-ботом вся предыдущая история разговора, включая вопросы и ответы, должна быть передана в промпт. Это происходит потому, что LLM не имеет возможности хранить информацию о наших предыдущих запросах, поэтому мы должны передавать всю информацию при каждом обращении к LLM.
К счастью, в LangChain есть набор классов, которые позволяют делать это из коробки. Он называется ConversationalRetrievalChain и позволяет передавать дополнительный параметр chat_history, который содержит список наших предыдущих разговоров с LLM.
Давайте создадим для этого новый скрипт под названием multi-doc-chatbot.py (поддержку мультидоков мы добавим чуть позже).
touch multi-doc-chatbot.pyНастройте загрузчик PDF, разделитель текста, эмбеддинги и векторное хранилище, как и раньше. Теперь запустим цепочку вопросов и ответов.
from langchain.chains import ConversationalRetrievalChain
from langchain_openai import ChatOpenAI
qa_chain = ConversationalRetrievalChain.from_llm(
ChatOpenAI(),
vectordb.as_retriever(search_kwargs={'k': 6}),
return_source_documents=True
)Команда chain run принимает в качестве параметра chat_history. Итак, прежде всего, давайте включим «непрерывный разговор» через терминал, вложив команды stdin и stout в цикл While. Далее нужно вручную сформировать этот список на основе разговора с LLM. Цепочка не делает этого из коробки — поэтому для каждого вопроса и ответа мы создадим список chat_history, который каждый раз будем передавать обратно в команду chain run.
import sys
chat_history = []
while True:
# выводит на терминал и ожидает ввода от пользователя
query = input('Prompt: ')
# даёт возможность выйти из сценария
if query == "exit" or query == "quit" or query == "q":
print('Exiting')
sys.exit()
# Мы передаём запрос в LLM и выводим ответ. Вместе с запросом будет
# передан контекст семантически релевантной информации из нашего
# векторного хранилища, а также список истории наших чатов.
result = qa_chain({'question': query, 'chat_history': chat_history})
print('Answer: ' + result['answer'])
# Формируем список chat_history, основываясь на нашем вопросе
# и ответе LLM, после чего скрипт возвращается в начало цикла
# и снова становится готов к приёму пользовательского ввода.
chat_history.append((query, result['answer']))Удалите директорию data, чтобы при следующем запуске он создался заново. Иногда ответы могут вести себя странно, когда вы меняете цепочки и настройки кода, не удаляя данные, созданные при предыдущих настройках.
Запустите скрипт,
python3 multi-doc-chatbot.pyи начните взаимодействовать с документом. Обратите внимание, что он может распознавать контекст из предыдущих вопросов и ответов. Чтобы выйти из скрипта, можно отправить команду exit или q.
multi-doc-chatbot python3 multi-doc-chatbot.py
Prompt: Who is the CV about?
Answer: The CV is about Rachel Green.
Prompt: And their surname only?
Answer: Rachel Greens surname is Green.
Prompt: And first?
Answer: Rachel.Ну вот и всё! Теперь мы создали чат-бота, который может взаимодействовать с несколькими нашими собственными документами, а также вести историю чата. Но подождите, мы ведь взаимодействуем только с одним PDF-документом, верно?
Взаимодействие с несколькими документами
Работать с несколькими документами очень просто. Если вы помните, Documents, созданные с помощью PDF Document Loader, — это просто список Documents, то есть List[Document]. Поэтому, чтобы увеличить количество документов, нужно просто добавить больше Documents в этот список.
Давайте добавим ещё несколько файлов в папку docs. Вы можете скопировать оставшиеся примеры документов из папки docs репозитория GitHub. Теперь в папке docs должны быть файлы .pdf, .docx и .txt.
Теперь можно просто перебрать все файлы в этой папке и преобразовать содержащуюся в них информацию в Documents. Далее процесс будет таким же, как и раньше. Мы просто передаём список documents в текстовый разделитель, который передаёт разбитую информацию в трансформер и векторное хранилище.
В нашем случае мы хотим иметь возможность работать с PDF-файлами, документами Microsoft Word и текстовыми файлами. Мы будем итеративно просматривать папку docs, обрабатывать файлы на основе их расширений, использовать для них соответствующие загрузчики и добавлять их в список documents, который затем передадим текстовому разделителю.
from langchain_community.document_loaders import Docx2txtLoader
from langchain_community.document_loaders import TextLoader
documents = []
for file in os.listdir('docs'):
if file.endswith('.pdf'):
pdf_path = './docs/' + file
loader = PyPDFLoader(pdf_path)
documents.extend(loader.load())
elif file.endswith('.docx') or file.endswith('.doc'):
doc_path = './docs/' + file
loader = Docx2txtLoader(doc_path)
documents.extend(loader.load())
elif file.endswith('.txt'):
text_path = './docs/' + file
loader = TextLoader(text_path)
documents.extend(loader.load())
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=10)
chunked_documents = text_splitter.split_documents(documents)
# we now proceed as earlier, passing in the chunked_documents to the
# to the vectorstore
# ...Теперь вы можете снова запустить скрипт и задать вопросы обо всех кандидатах. Кажется, помогает удаление папки /data после добавления новых файлов в папку docs. В противном случае чат-бот не воспринимает новую информацию.
python3 multi-doc-chatbot.pyИтак, у нас есть чат-бот, способный взаимодействовать с информацией из нескольких документов, а также вести историю чата. Можно немного его оживить, добавив немного цвета к выводам терминала и обработав ввод пустых строк. Вот полная версия скрипта:
import os
import sys
from dotenv import load_dotenv
from langchain.chains import ConversationalRetrievalChain
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.document_loaders import Docx2txtLoader
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
os.environ["OPENAI_API_KEY"] = "sk-XXX"
documents = []
# Create a List of Documents from all of our files in the ./docs folder
for file in os.listdir("docs"):
if file.endswith(".pdf"):
pdf_path = "./docs/" + file
loader = PyPDFLoader(pdf_path)
documents.extend(loader.load())
elif file.endswith('.docx') or file.endswith('.doc'):
doc_path = "./docs/" + file
loader = Docx2txtLoader(doc_path)
documents.extend(loader.load())
elif file.endswith('.txt'):
text_path = "./docs/" + file
loader = TextLoader(text_path)
documents.extend(loader.load())
# Split the documents into smaller chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=10)
documents = text_splitter.split_documents(documents)
# Convert the document chunks to embedding and save them to the vector store
vectordb = Chroma.from_documents(documents, embedding=OpenAIEmbeddings(), persist_directory="./data")
vectordb.persist()
# create our Q&A chain
pdf_qa = ConversationalRetrievalChain.from_llm(
ChatOpenAI(temperature=0.7, model_name='gpt-3.5-turbo'),
retriever=vectordb.as_retriever(search_kwargs={'k': 6}),
return_source_documents=True,
verbose=False
)
yellow = "\033[0;33m"
green = "\033[0;32m"
white = "\033[0;39m"
chat_history = []
print(f"{yellow}---------------------------------------------------------------------------------")
print('Welcome to the DocBot. You are now ready to start interacting with your documents')
print('---------------------------------------------------------------------------------')
while True:
query = input(f"{green}Prompt: ")
if query == "exit" or query == "quit" or query == "q" or query == "f":
print('Exiting')
sys.exit()
if query == '':
continue
result = pdf_qa.invoke(
{"question": query, "chat_history": chat_history})
print(f"{white}Answer: " + result["answer"])
chat_history.append((query, result["answer"]))The LangChain repositoryЧтобы лучше понять, что происходит за кулисами, рекомендую загрузить исходный код LangChain и посмотреть, как он работает.
git clone https://github.com/hwchase17/langchainЕсли вы просматриваете исходный код с помощью IDE, например PyCharm (кажется, Community Edition бесплатна): нажатие горячей клавиши (CMD + click) на каждом из вызовов методов и классов поможет перейти к месту, где они написаны — что очень полезно для просмотра кодовой базы. Это помогает увидеть, как всё работает.
Улучшения
Когда вы начнёте экспериментировать с чат-ботом и посмотрите, как он отвечает на разные вопросы, вы заметите, что он не всегда даёт правильные ответы.
У нашего текущего метода есть ограничения. Например, лимит токенов OpenAI составляет 4 096 токенов, что означает, что мы не можем отправить более 6–7 фрагментов текста из векторной базы данных. Это означает, что мы можем отправить информацию даже не из всех документов — что было бы важно, если бы мы хотели узнать, например, имена всех людей в наших документах CV. Например, один из документов может быть полностью пропущен, и в таком случае мы упустим важную часть информации.
У нас здесь всего три документа. Представьте, что у вас их сотни. В какой-то момент ограничения в 4096 символов будет недостаточно для точного ответа. Возможно, вам потребуется использовать другой LLM, например, отличный от OpenAI, в котором вы можете использовать более высокий лимит токенов, чтобы передать больше контекста. Одна из особенностей, о которой часто говорят в последнее время, — это LLM со всё большими лимитами токенов.
Если размер исходного текста слишком велик, возможно, стоит обучить LLM на ваших данных, а не отправлять информацию через контексты промптов. Или, может быть, можно внести какие-то другие умные изменения в параметры цепочки или методы поиска в векторном хранилище. Может быть, стоит использовать умную инженерию промптов (smart prompt engineering) или агентов для рекурсивного поиска (agents for recursive lookups). Эта статья даёт представление о том, как писать промпты для получения лучших ответов.
Скорее всего, это будет комбинация всего перечисленного, и ответ может также зависеть от типов документов, которые нужно разобрать. Если вы решили сосредоточиться на определённом типе документов, например резюме, руководстве пользователя или данных с веб-ресурсов — могут существовать определённые виды оптимизации, более подходящие для конкретных типов контента.
В целом, чтобы получить многодокументный работающий ридер, я думаю, вам нужно выйти за рамки поверхностного подхода и начать придумывать некоторые из этих улучшений, которые могут сделать его гораздо более способным и полезным чат-ботом.
Заключение
Вот и всё. Мы создали однодокументный чат-бот и закончили многодокументным чат-ботом, который помнит историю диалога. Надеюсь, эта статья помогла снять часть вопросов касательно эмбеддингов, векторных хранилищ, настройки параметров цепочек и ретриверов векторных хранилищ.
Освоить все необходимые инструменты и лучшие практики, которые помогут в разработке и тестировании чат-ботов и не только можно на онлайн-курсах OTUS. По ссылке вы можете ознакомиться с полным каталогом курсов, а также записаться на бесплатные открытые уроки.
