[Перевод] Создание in-memory кэша первого уровня для .NET-клиентов StackExchange.Redis
Джонатан Карди написал .NET-библиотеку StackRedis.L1 с открытым исходным кодом, которая позволяет создавать кэш первого уровня для Redis. Иными словами, используя библиотеку StackExchange.Redis в .NET-приложении, вы можете подключить к ней StackRedis.L1 для ускорения работы за счет локального кэширования данных в оперативной памяти. Это позволяет избежать лишних обращений к Redis в тех случаях, когда данные не подвергались изменениям. Библиотека доступна на GitHub и NuGet.
В этой статье рассказывается о том, как и почему она была создана.

Предыстория
Последние пару лет я работал над приложением Repsor custodian под управлением SharePoint. Если вы знакомы с SharePoint, то знаете, что ее модель требует запускать приложения на отдельном сервере. Это позволяет повысить стабильность и упростить архитектуру. Тем не менее, данная модель работает в ущерб производительности, так как вам приходится каждый раз обращаться за данными к серверу SharePoint, и задержки в сети в данном случае играют не в вашу пользу.
По этой причине мы решили добавить в приложение Redis-кэширование, используя StackExchange.Redis в качестве .NET-клиента. Для полного кэширования всех моделей данных приложения мы используем множества, упорядоченные множества и хэш-таблицы.
Как и следовало ожидать, это значительно ускорило работу приложения. Теперь страницы возвращались примерно за 500 мс вместо 2 с, как прежде. Но анализ показал, что даже из этих 500 мс немалая часть времени уходила на отправку или получение данных от Redis. Более того, основная часть данных, получаемых каждый раз по запросу со страницы, не подвергалась изменениям.
Кэширование кэша
Redis — это не только невероятно быстрое средство кэширования, но и набор инструментов для управления кэшированными данными. Эта система хорошо развита и весьма широко поддерживается. Библиотека StackExchange.Redis бесплатна и имеет открытый исходный код, а ее сообщество активно растет. Stack Exchange агрессивно кэширует все данные Redis, притом что это один из самых загруженных сайтов в интернете. Но главным козырем является то, что она выполняет in-memory кэширование всех доступных данных на сервере Redis и, таким образом, ей обычно даже не приходится обращаться к Redis.
Следующая цитата в некоторой степени объясняет принцип работы механизма кэширования в Stack Exchange:
http://meta.stackexchange.com/questions/69164/does-stack-exchange-use-caching-and-if-so-how
«Несомненно, самый оптимальный объем данных, который можно быстрее всего отправить по сети, — это 0 байт».
Когда вы кэшируете данные прежде, чем они попадают в другой кэш, вы создаете несколько уровней кэша. Если вы выполняете in-memory кэширование данных перед их кэшированием в Redis, in-memory кэшу присваивается первый уровень L1.
Поэтому, если Redis — самая медленная часть вашего приложения, вы на правильном пути и определенно сможете ускорить этот недостаток в дальнейшем.
In-memory кэширование
В самой простой ситуации при использовании Redis ваш код будет выглядеть примерно так:
//Try and retrieve from Redis
RedisValue redisValue = _cacheDatabase.StringGet(key);
if(redisValue.HasValue)
{
return redisValue; //It's in Redis - return it
}
else
{
string strValue = GetValueFromDataSource(); //Get the value from eg. SharePoint or Database etc
_cacheDatabase.StringSet(key, strValue); //Add to Redis
return strValue;
}
А если вы решите применить in-memory кэширование (т. е. L1-кэш), код немного усложнится:
//Try and retrieve from memory
if (_memoryCache.ContainsKey(key))
{
return key;
}
else
{
//It isn't in memory. Try and retrieve from Redis
RedisValue redisValue = _cacheDatabase.StringGet(key);
if (redisValue.HasValue)
{
//Add to memory cache
_memoryCache.Add(key, redisValue);
return redisValue; //It's in redis - return it
}
else
{
string strValue = GetValueFromDataSource(); //Get the value from eg. SharePoint or Database etc
_cacheDatabase.StringSet(key, strValue); //Add to Redis
_memoryCache.Add(key, strValue); //Add to memory
return strValue;
}
}
И хотя это не так трудно реализовать, всё становится гораздо сложнее, стоит вам попробовать проделать те же действия для других моделей данных в Redis. Вдобавок возникнут следующие проблемы:
• Redis позволяет нам управлять данными посредством функций вроде StringAppend. В таком случае нам придется объявить элемент in-memory недействительным.
• Если удалить ключ через KeyDelete, его также необходимо удалить из in-memory кэша.
• Если другой клиент изменит или удалит какое-либо значение, оно станет устаревшим в in-memory кэше нашего клиента.
• Когда ключ устаревает, его необходимо удалить из in-memory кэша.
Методы доступа к данным и обновления данных библиотеки StackExchange.Redis определены в интерфейсе IDatabase. Выходит, мы можем переписать реализацию IDatabase так, чтобы решить все приведенные выше проблемы. Вот как это можно сделать:
• StringAppend — добавим данные в in-memory строку, а затем передадим ту же операцию в Redis. При более сложных операциях с данными необходимо будет удалить in-memory ключ.
• KeyDelete, KeyExpire, и т. д. — удаляет in-memory данные.
• Операции через другой клиент — уведомления пространства ключей в Redis сделаны так, чтобы обнаруживать изменения данных и соответствующим образом объявлять их недействительным.
Вся красота этого подхода в том, что вы продолжаете использовать тот же интерфейс, что и ранее. Получается, внедрение L1-кэша не требует никаких изменений в коде.
Архитектура
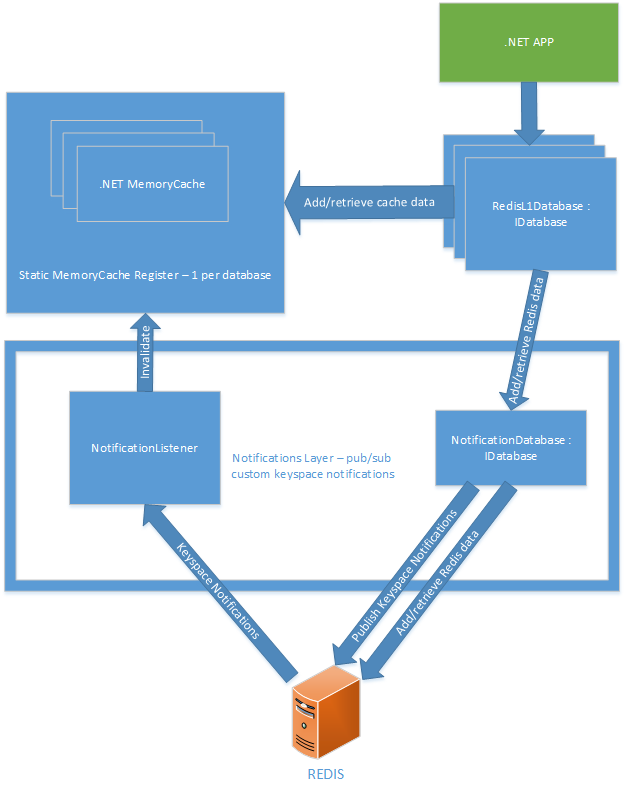
Я выбрал следующее решение с такими основными элементами:
Статический регистр MemoryCache
Вы можете создавать новые сущности RedisL1Database, передавая в Redis IDatabase готовую сущность, и она продолжит использовать любой in-memory кэш, который ранее создала для этой базы данных.
Уровень уведомлений
• NotificationDatabase — публикует специальные события пространства ключей, необходимые для поддержания актуальности in-memory кэша. Стандартные уведомления пространства ключей в Redis не позволяют достичь того же результата, поскольку они не предоставляют достаточно информации, чтобы объявить недействительной нужную часть кэш-памяти. К примеру, если вы удаляете хэш-ключ, вы получаете HDEL-уведомление с информацией о том, из какого хэша он был удален. Но оно не указывает, каким элементом хэша он был. В свою очередь, специальные события также содержат информацию о самом элементе хэша.
• NotificationListener — подписывается на специальные события пространства ключей и обращается к статической кэш-памяти, чтобы объявить недействительным необходимый ключ. Он также подписывается на встроенное событие пространства ключей Redis под названием expire. Это позволяет оперативно удалять из памяти все истекшие ключи Redis.
Далее мы рассмотрим способы кэширования различных моделей данных в Redis.
Строка
Работать со строкой относительно просто. Метод IDatabase StringSet выглядит так:
public bool StringSet(RedisKey key, RedisValue value, TimeSpan? expiry = default(TimeSpan?), When when = When.Always, CommandFlags flags =
CommandFlags.None)
• Key и Value — названия говорят сами за себя.
• Expiry — произвольный промежуток времени, а потому нам нужно использовать in-memory кэш со сроком действия.
• When — позволяет определить условия создания строки: задать строку только если она уже существует или еще не существует.
• Flags — позволяет уточнить детали кластера Redis (не является актуальным).
Для хранения данных мы используем System.Runtime.Caching.MemoryCache, что позволяет реализовать автоматическое истечение ключей. Метод StringSet выглядит так:
public bool StringSet(RedisKey key, RedisValue value, TimeSpan? expiry = default(TimeSpan?), When when = When.Always, CommandFlags flags = CommandFlags.None)
{
if (when == When.Exists && !_cache.Contains(key))
{
//We're only supposed to cache when the key already exists.
return;
}
if (when == When.NotExists && _cache.Contains(key))
{
//We're only supposed to cache when the key doesn't already exist.
return;
}
//Remove it from the memorycache before re-adding it (the expiry may have changed)
_memCache.Remove(key);
CacheItemPolicy policy = new CacheItemPolicy()
{
AbsoluteExpiration = DateTime.UtcNow.Add(expiry.Value)
};
_memCache.Add(key, o, policy);
//Forward the request on to set the string in Redis
return _redisDb.StringSet(key, value, expiry, when, flags);
Затем StringGet может читать in-memory кэш перед попыткой обратиться к Redis:
public RedisValue StringGet(RedisKey key, CommandFlags flags = CommandFlags.None)
{
var cachedItem = _memCache.Get(key);
if (cachedItem.HasValue)
{
return cachedItem;
}
else
{
var redisResult = _redisDb.StringGet(key, flags);
//Cache this key for next time
_memCache.Add(key, redisResult);
return redisResult;
}
}
Redis поддерживает множество операций для строк. В каждом случае их применение связано либо с обновлением in-memory значения, либо с объявлением его недействительным. В целом второй вариант подходит лучше, поскольку в противном случае вы рискуете напрасно усложнить многие операции Redis.
• StringAppend — очень простая операция. К in-memory строке, если таковая существует и не объявлена неактивной, добавляются данные.
• StringBitCount, StringBitOperation, StringBitPosition — операция осуществляется в Redis, задействование in-memory не требуется.
• StringIncrement, StringDecrement, StringSetBit, StringSetRange — in-memory строка объявляется недействительной до перенаправления операции в Redis.
• StringLength — возвращает длину строки, если она находится в in-memory кэше. Если нет, операция получает ее из Redis.
Множество
Множества немного сложнее в обращении. Метод SetAdd выполняется по следующей схеме:
1. Проверить MemoryCache на HashSet с данным ключом
• Если такового не существует, создать его.
2. Добавить каждое значение Redis во множество.
Добавлять и удалять значения из множеств довольно просто. Метод SetMove — это SetRemove, за которым следует SetAdd.
Большинство других запросов множеств могут кэшироваться. Например:
• SetMembers — возвращает все элементы множества, чтобы результат сохранился в памяти.
• SetContains, SetLength — проверяет in-memory множество перед обращением к Redis.
• SetPop — выталкивает элемент данных из множества Redis и затем удаляет этот элемент из in-memory множества, если таковой там имеется.
• SetRandomMember — получает от Redis случайный элемент множества, затем выполняет его in-memory кэширование и возвращает.
• SetCombine, SetCombineAndStore — задействование in-memory не требуется.
• SetMove — удаляет элемент данных из in-memory множества, добавляет его в другое in-memory множество и перенаправляет в Redis.
Хэш-таблицы
Хэш-таблицы тоже относительно просты, так как их in-memory реализация — это всего лишь Dictionary
Базовая операция:
1. Если хэш-таблица не доступна в in-memory, нужно создать Dictionary
2. Произвести операции над in-memory словарем, если это возможно.
3. Перенаправить запрос в Redis, если это необходимо.
• Кэшировать результат.
Для хэш-таблиц доступны такие операции:
• HashSet — сохраняет значения в словаре, сохраняемого в ключе, и затем перенаправляет запрос в Redis.
• HashValues, HashKeys, HashLength — in-memory применение отсутствует.
• HashDecrement, HashIncrement, HashDelete — удаляет значение из словаря и перенаправляет в Redis.
• HashExists — возвращает true, если значение находится в in-memory кэше. В противном случае перенаправляет запрос в Redis.
• HashGet — запрашивает данные из in-memory кэша. В противном случае перенаправляет запрос в Redis.
• HashScan — получает результаты из Redis и добавляет их в in-memory кэш.
Упорядоченное множество
Упорядоченные множества — это, несомненно, самая сложная модель данных по части создания in-memory кэша. В данном случае процесс in-memory кэширования подразумевает использование так называемых «непересекающихся упорядоченных множеств». То есть каждый раз, когда локальный кэш видит небольшой фрагмент упорядоченного множества Redis, этот фрагмент добавляется в «непересекающееся» упорядоченное множество. Если в дальнейшем будет запрашиваться подсекция упорядоченного множества, в первую очередь будет проверяться непересекающееся упорядоченное множество. Если оно целиком содержит необходимую секцию, ее можно вернуть с полной уверенностью, что там нет отсутствующих компонентов.
Упорядоченные in-memory множества сортируются не по значению, а по особому параметру score. Теоретически можно было бы расширить реализацию непересекающихся упорядоченных множеств, чтобы была возможность сортировать их по значению, но на данный момент это пока не реализовано.
Операции используют непересекающиеся множества следующим образом:
• SortedSetAdd — значения добавляются в in-memory множество дискретно, а значит мы не знаем, связаны ли они с точки зрения score.
• SortedSetRemove — значение удаляется как из памяти, так и из Redis.
• SortedSetRemoveRangeByRank — всё in-memory множество объявляется недействительным.
• SortedSetCombineAndStore, SortedSetLength, SortedSetLengthByValue, SortedSetRangeByRank, SortedSetRangeByValue, SortedSetRank — запрос передается напрямую в Redis.
• SortedSetRangeByRankWithScores, SortedSetScan — из Redis запрашиваются и затем дискретно кэшируются данные.
• SortedSetRangeByScoreWithScores — наиболее кэшируемая функция, так как scores возвращаются по порядку. Кэш проверяется, и если он может обработать запрос, то возвращается. В противном случае отправляется запрос к Redis, после чего scores кэшируются в памяти как непрерывное множество данных.
• SortedSetRangeByScore — данные берутся из кэша, если это возможно. В противном случае они берутся из Redis и не кэшируются, так как scores не возвращаются.
• SortedSetIncrement, SortedSetDecrement — in-memory данные обновляются, и запрос перенаправляется в Redis.
• SortedSetScore — значение берется из памяти, если это возможно. В противном случае отправляется запрос к Redis.
Сложность работы с упорядоченными множествами обусловлена двумя причинами: во-первых, характерная сложность построения in-memory реализации для имеющихся подмножеств упорядоченных множеств (т. е. построения разрывных множеств). А во-вторых, ввиду числа доступных операций в Redis, которые требуют выполнения. В некоторой степени сложность сбавляется за счет возможности реализовать целенаправленное кэширование запросов, включающих Score. Так или иначе, необходимо серьезное модульное тестирование всех компонентов.
Список
Списки не так-то легко кэшировать в оперативной памяти. Причина в том, что операции с ними, как правило, подразумевают работу либо с головой, либо с хвостом списка. И это не так просто, как может показаться на первый взгляд, потому что у нас нет стопроцентной возможности убедиться, что in-memory список имеет такие же данные в начале и в конце, как и список в Redis. Частично эту трудность можно было бы решить с помощью уведомлений пространства ключей, но пока что эта возможность не реализована.
Обновления со стороны других клиентов
До этого момента мы исходили из соображения, что имеем всего один клиент базы данных Redis. На самом деле клиентов может быть много. В таких условиях вполне вероятна ситуация, когда у одного клиента есть данные в in-memory кэше, а другой их обновляет, что делает данные первого клиента недействительными. Существует всего один способ решить эту проблему — настроить коммуникацию между всеми клиентами. К счастью, Redis предоставляет механизм обмена сообщениями в виде шаблона «издатель–подписчик». Этот шаблон имеет 2 типа уведомлений.
Уведомления пространства ключей
Эти уведомления публикуются в Redis автоматически, когда меняется ключ.
Специально опубликованные уведомления
Публикуются на уровне уведомлений, реализованном как часть кэширующего механизма для клиента. Их цель — подкреплять уведомления пространства ключей дополнительной информацией, необходимой, чтобы объявлять недействительными отдельные мелкие части кэша.
Работа с множеством клиентов — основная причина возникновения проблем кэширования.
Риски и проблемы
Затерянные уведомления
Redis не гарантирует доставку уведомлений ключевого пространства. Соответственно уведомления могут затеряться, а в кэше останутся недействительные данные. Это один из самых основных рисков, но, к счастью, такие ситуации случаются редко. Тем не менее, при работе с двумя и более клиентами, эту опасность нужно учитывать.
Решение: использовать надежный механизм обмена сообщениями между клиентами с гарантированной доставкой. К сожалению, такого пока нет, поэтому смотрите альтернативное решение.
Альтернативное решение: выполнять in-memory кэширование только на короткое время, скажем, на один час. В таком случае все данные, к которым мы обращаемся в течение часа, будут грузиться быстрее. А если какое-либо уведомление затеряется, это упущение в скором времени восполнится. Вызовите метод Dispose для базы данных, а затем инстанцируйте ее повторно, чтобы очистить.
Использует один — используют все
Если один клиент использует этот уровень кэширования (L1), его должны использовать и все остальные клиенты, чтобы уведомлять друг друга в случае изменения данных.
Отсутствие лимита для in-memory данных
На данный момент всё, что может кэшироваться, будет отправлено в кэш. В такой ситуации у вас может быстро закончиться память. В моем случае это не проблема, но просто имейте это в виду.
Вывод
Говорят, в программировании всего 10 сложных проблем: инвалидация кэша, присвоение имен и двоичная система… Уверен, этот проект может пригодиться во многих ситуациях. Исходный код библиотеки доступен на GitHub. Следите за проектом и принимайте в нем участие!
