[Перевод] Создаём и настраиваем собственную CDN
Задача этого репозитория — создать свод знаний о том, как работают CDN, написав одну из них «с нуля». CDN, которую мы будем проектировать, использует следующие технологии: Nginx, Lua, Docker, docker-compose, Prometheus, Grafana и wrk.
Мы начнём с создания одного бэкенд-сервиса, а затем расширим его до многоузловой CDN с симуляцией задержек, а также возможностью наблюдений и тестирования. В каждом из разделов мы обсудим сложности и компромиссы при создании/управлении/эксплуатации CDN.
Что такое CDN?
Content Delivery Network — это сеть компьютеров, пространственно распределённая для обеспечения высокого уровня доступности и повышенной производительности систем, работа которых кэшируется в этой сети.
Зачем вам нужна CDN?
CDN помогает:
- снизить время загрузки (более плавное потоковое воспроизведение, мгновенное открытие страницы для покупки, быстрая загрузка ленты друзей и так далее);
- сглаживать всплески трафика (чёрная пятница, выпуск популярного стримингового видео, срочные новости и так далее);
- снизить затраты (разгрузка трафика);
- масштабировать сеть до миллионов узлов.
Как работает CDN?
CDN способны ускорить работу сервисов, размещая контент (медиафайлы, страницы, игры, javascript, json-ответы и так далее) ближе к пользователям.
Когда пользователь хочет использовать сервис, система маршрутизации CDN предоставляет ему «наилучший» узел, в котором контент с большой вероятностью уже кэширован и расположен ближе к клиенту. Пока не стоит беспокоиться о расплывчатости понятия «наилучший», надеюсь, в процессе чтения статьи вы поймёте его значение.
Стек CDN
Создаваемая нами CDN будет состоять из следующих компонентов:
Linux/GNU/Kernel— ядро/операционная система с выдающимися сетевыми возможностями, а также превосходным уровнем ввода-вывода.Nginx— превосходный веб-сервер, который можно использовать в качестве обратного прокси, обеспечивающего возможность кэширования.Lua(jit)— простой и мощный язык для добавления функций в Nginx.Prometheus— система с пространственной моделью данных, гибким языком запросов и эффективной базой данных временных рядов.Grafana— опенсорсный инструмент аналитики и мониторинга, способный подключаться ко многим источникам, включая Prometheus.Контейнеры— технологии упаковки, развёртывания и изолирования приложений (мы используем docker и docker compose).
Первоисточник — бэкенд-сервис
Первоисточник (origin) — это система, в которой создаётся контент, или, по крайней мере, это источник данных для CDN. Пример сервиса, который мы будем создавать, будет простым JSON API. Бэкенд-сервис сможет возвращать изображение, видео, javascript, HTML-страницу, игру или любые другие данные, которые вы хотите доставить клиентам.
Для проектирования бэкенд-сервиса мы воспользуемся Nginx и Lua. Это отличный повод познакомиться с Nginx и Lua, потому что в дальнейшем мы будем активно их использовать.
Подсказка: бэкенд-сервис можно написать на любом языке на выбор.
Nginx: краткое введение
Nginx — это веб-сервер, работающий в соответствии со своей конфигурацией. Файл конфигурации использует в качестве доминирующего фактора директивы. Директива — это простая конструкция, задающая свойства Nginx. Существует два типа директив: простые и блочные (контекстные).
Простая директива состоит из её имени, за которым следуют параметры, и заканчивается точкой с запятой.
# Синтаксис: <имя> <параметры>;
# Пример
add_header X-Header AnyValue;
Блочная директива соответствует тому же паттерну, однако она заканчивается не точкой с запятой, а фигурными скобками. Кроме того, внутри блочной директивы могут находиться другие директивы. Этот блок также называется контекстом.
# Синтаксис: <имя> <параметры> <блок>
location / {
add_header X-Header AnyValue;
}
Для обработки запросов Nginx использует воркеры (процессы). Существенное влияние на производительность сервера оказывает архитектура Nginx.
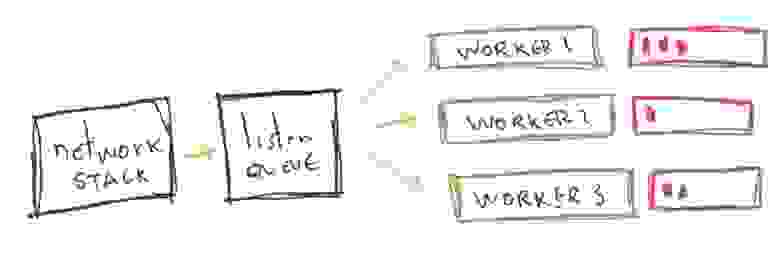
Подсказка: хотя чаще всего используется единая принимающая очередь, обслуживающая множество воркеров, существуют и другие модели для балансировки загрузки входящих запросов.
Конфигурация бэкенд-сервиса
Давайте разберём конфигурацию Nginx бэкенда JSON API. Думаю, будет гораздо проще, если мы увидим её в действии.
events {
worker_connections 1024;
}
error_log stderr;
http {
access_log /dev/stdout;
server {
listen 8080;
location / {
content_by_lua_block {
ngx.header['Content-Type'] = 'application/json'
ngx.say('{"service": "api", "value": 42}')
}
}
}
}
Смогли ли вы понять, что делает эта конфигурация? Давайте разберём её, прокомментировав каждую директиву.
events обеспечивает контекст для конфигураций обработки соединений, а worker_connections определяет максимальное количество одновременных подключений, которые могут быть открыты процессом воркера.
events {
worker_connections 1024;
}error_log конфигурирует логирование ошибок. Здесь мы просто отправляем все ошибки на stdout (error)
error_log stderr;http предоставляет корневой контекст, чтобы настроить все http/s-серверы.
http {}access_log конфигурирует путь (а также опционально формат и так далее) для логирования доступа.
access_log /dev/stdout;server задаёт конфигурацию рута для сервера, то есть указывает, где мы будем настраивать конкретное поведение сервера. В каждом контексте http может быть несколько блоков server.
server {}
В server мы можем задать директиву listen, контролирующую адрес и/или порт, по которому сервер будет принимать запросы.
listen 8080;
В конфигурации сервера мы можем указать маршрут при помощи директивы location. Он будет использоваться для предоставления специфической конфигурации для соответствующего пути запроса.
location / {}
В этом местоположении (кстати, / обрабатывает все запросы) для создания ответов мы будем использовать Lua. Существует директива content_by_lua_block, предоставляющая контекст того, где будет работать код на Lua.
content_by_lua_block {}
Наконец, мы используем Lua и базовый Nginx Lua API для задания требуемого поведения.
-- ngx.header задаёт текущий заголовок ответа, который должен отправляться.
ngx.header['Content-Type'] = 'application/json'
-- ngx.say записывает тело ответа
ngx.say('{"service": "api", "value": 42}')
Обратите внимание, что большинство директив имеет область действия. Например, location применима только в контексте location (рекурсивно) и server.

В дальнейшем мы не будем комментировать каждую добавляемую директиву, и станем описывать только самые релевантные теме соответствующего раздела.
Настало время для демо CDN 1.0.0
Давайте посмотрим, что же мы сделали.
git checkout 1.0.0 # возвращаемся к конкретной конфигурации
docker-compose run --rm --service-ports backend # запускаем контейнеры, раскрывающие сервисы
http http://localhost:8080/path/to/my/content.ext # то, что потребляет сервис, я использовал httpie, но вы можете воспользоваться curl или чем-то иным
# вы должны увидеть json-ответ▍ Добавление функций кэширования
Чтобы бэкенд-сервис был кэшируемым, нам нужно задать политику кэширования. Для настройки нужного нам поведения кэширования мы воспользуемся HTTP-заголовком Cache-Control.
-- мы хотим, чтобы контент кэшировался через 10 секунд ИЛИ через указанный max_age (пример: /path/to/service?max_age=40 - это 40 секунд)
ngx.header['Cache-Control'] = 'public, max-age=' .. (ngx.var.arg_max_age or 10)
При желании можно проверять возвращаемый заголовок ответа Cache-Control.
git checkout 1.0.1 # возвращаемся к конкретной конфигурации
docker-compose run --rm --service-ports backend
http "http://localhost:8080/path/to/my/content.ext?max_age=30"▍ Добавляем метрики
Для отладки вполне достаточно будет изучения логов, однако когда трафика станет больше, мы практически никак не сможем понять, как работает сервис. Чтобы справиться с этим, мы используем VTS — модуль Nginx, добавляющий отслеживание метрик.
vhost_traffic_status_zone shared:vhost_traffic_status:12m;
vhost_traffic_status_filter_by_set_key $status status::*;
vhost_traffic_status_histogram_buckets 0.005 0.01 0.05 0.1 0.5 1 5 10; # buckets указываются в секундахvhost_traffic_status_zone задаёт пространство памяти, требуемое для метрик. vhost_traffic_status_filter_by_set_key группирует метрики по заданной переменной (например, мы решили сгруппировать метрики по status), а vhost_traffic_status_histogram_buckets позволяет группировать метрики по секундам. Мы решили создать группы от 0,005 до 10 секунд, потому что они помогут нам создавать перцентили (p99, p50 и так далее).
location /status {
vhost_traffic_status_display;
vhost_traffic_status_display_format html;
}
Также мы должны отобразить метрики в location. Для этого мы используем /status.
git checkout 1.1.0
docker-compose run --rm --service-ports backend
# если перейти по адресу http://localhost:8080/status/format/html, то можно увидеть информацию о сервере 8080
# обратите внимание, что VTS также предоставляет другие форматы, например, status/format/prometheus, что пригодится нам в ближайшем будущем
Настроив метрики, мы можем выполнять тесты (нагрузочные) и наблюдать, приводят ли внесённые изменения конфигурации к повышению производительности.
Подсказка: можно сгруппировать метрики под отдельным пространством имён. Это полезно, если у вас есть одно местоположение, которое в зависимости от контекста ведёт себя иным образом.
▍ Рефакторинг конфигурации Nginx
С увеличением размера конфигурации в ней становится труднее разобраться. У Nginx есть удобная директива include, позволяющая создавать частичные файлы конфигурации и включать их в корневой файл конфигурации.

include basic_vts_location.conf;
Мы можем перенести в файл местоположение, групповые конфигурации по схожести и всё остальное, что сочтём нужным. Подобное можно сделать и для кода на Lua.
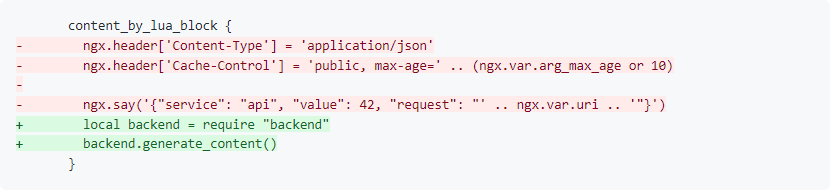
content_by_lua_block {
local backend = require "backend"
backend.generate_content()
}
Все эти модификации внесены для повышения читаемости, но в то же время позволяют использовать код многократно.
CDN: то, что находится перед бэкендом
Прокси
Всё, что мы пока сделали, никак не связано с CDN. Теперь настало время приступать к созданию CDN. Для этого мы создадим один её узел с Nginx, просто добавив несколько новых директив для соединения узла edge (CDN) с узлом backend.
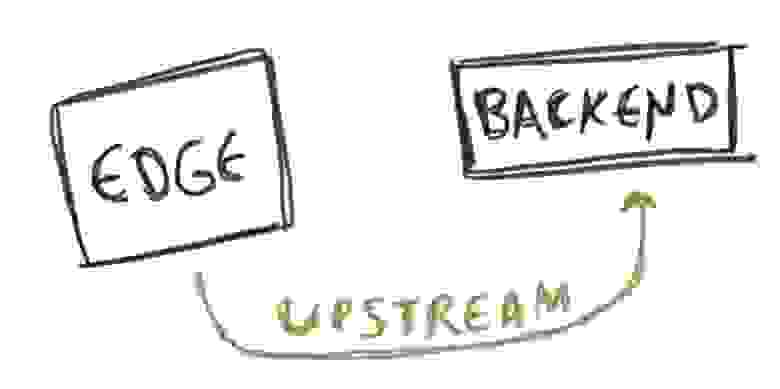
На самом деле здесь нет ничего сложного, это просто блок upstream с сервером, указывающим на конечную точку бэкенда. В location мы не предоставляем контент, а вместо этого указываем на upstream при помощи только что созданного proxy_pass.
upstream backend {
server backend:8080;
keepalive 10; # пул соединений для повторного использования
}
server {
listen 8080;
location / {
proxy_pass http://backend;
add_header X-Cache-Status $upstream_cache_status;
}
}
Также мы добавили новый заголовок (X-Cache-Status), указывающий, используется ли кэш.
- HIT: когда контент есть в CDN, то
X-Cache-Statusдолжен вернуть попадание. - MISS: когда контента нет в CDN,
X-Cache-Statusдолжен вернуть промах.
git checkout 2.0.0
docker-compose up
# мы по-прежнему можем получать контент от бэкенда
http "http://localhost:8080/path/to/my/content.ext"
# но на самом деле мы хотим получать доступ к контенту через edge (CDN)
http "http://localhost:8081/path/to/my/content.ext"Кэширование
Когда мы пытаемся получить контент, заголовок X-Cache-Status отсутствует. Похоже, что узел edge всегда неизменно запрашивает бэкенд. Но ведь на самом деле CDN работает не так, правда?
backend_1 | 172.22.0.4 - - [05/Jan/2022:17:24:48 +0000] "GET /path/to/my/content.ext HTTP/1.0" 200 70 "-" "HTTPie/2.6.0"
edge_1 | 172.22.0.1 - - [05/Jan/2022:17:24:48 +0000] "GET /path/to/my/content.ext HTTP/1.1" 200 70 "-" "HTTPie/2.6.0"
Edge просто перебрасывает клиентов через прокси на бэкенд. Что же мы упустили? Есть ли вообще причины использовать «простой» прокси? На самом деле, возможно, есть, если вы хотите обеспечить троттлинг, аутентификацию, авторизацию, терминирование tls-соединений или шлюз для нескольких сервисов, но нам сейчас нужно другое.
Нам нужно создать на Nginx область кэша при помощи директивы proxy_cache_path. Среди прочего, она задаёт путь, по которому будет находиться кэш, key_zone общей памяти и политики наподобие inactive, max_size для управления тем, какое поведение кэша нам нужно.
proxy_cache_path /cache/ levels=2:2 keys_zone=zone_1:10m max_size=10m inactive=10m use_temp_path=off;
После настройки кэша нам также нужно настроить proxy_cache, указывающий на правильную зону (при помощи proxy_cache_path keys_zone=), и proxy_pass, указывающий на созданный нами upstream.
location / {
# ...
proxy_pass http://backend;
proxy_cache zone_1;
}
Существует ещё один важный аспект кэширования, которым управляет директива proxy_cache_key. Когда клиент запрашивает контент у Nginx, то он выполняет следующие действия (в очень упрощённом виде):
- Получает запрос (допустим:
GET /path/to/something.txt). - Применяет хеш-функцию md5 к значению ключа кэша (допустим, ключ кэша — это
uri): md5(»/path/to/something.txt») =>b3c4c5e7dc10b13dc2e3f852e52afcf3. Можете проверить это в терминале следующим образом:echo -n "/path/to/something.txt" | md5. - Эта команда проверяет, кэширован ли контент (hash
b3c4..). - Если он кэширован, то она просто возвращает объект, а в противном случае получает контент у бэкенда. Также она выполняет локальное сохранение (в памяти и на диске), чтобы избежать запросов в будущем.
Давайте создадим переменную с именем cache_key при помощи директивы Lua set_by_lua_block. Она будет для каждого входящего запроса заполнять cache_keyзначением uri. Кроме этого мы также должны модифицировать proxy_cache_key.
location / {
set_by_lua_block $cache_key {
return ngx.var.uri
}
# ...
proxy_cache_key $cache_key;
}Подсказка: при использованииuriв качестве ключа кэша два следующих запроса http://example.com/path/to/content.ext и http://example.edu/path/to/content.ext будут выполняться так, как будто один являются одним объектом (если они используют одинаковый прокси кэша). Если вы не укажете ключ кэша, Nginx будет использовать разумное значение по умолчанию$scheme$proxy_host$request_uri.
Теперь кэширование будет работать правильно.
git checkout 2.1.0
docker-compose up
http "http://localhost:8081/path/to/my/content.ext"
# второй запрос должен получать контент от CDN, не переходя к бэкенду
http "http://localhost:8081/path/to/my/content.ext"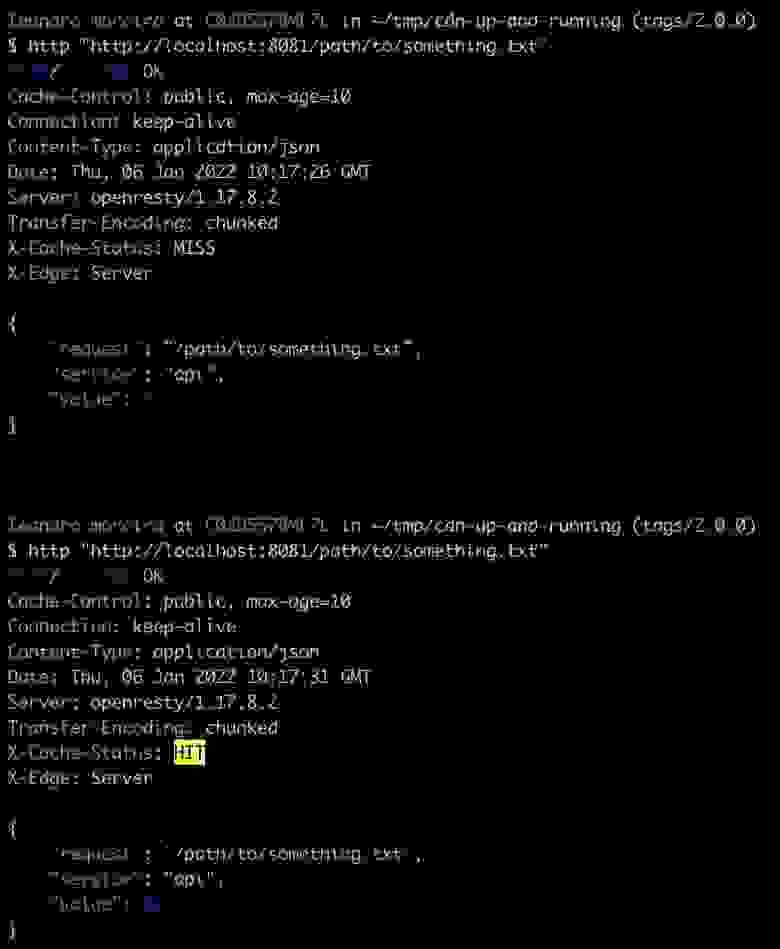
Инструменты мониторинга
Проверять эффективность кэша при помощи командной строки не очень удобно. Для этого лучше использовать специальный инструмент. Для скрейпинга метрик на всех серверах мы возьмём Prometheus, а Grafana будет отображать графики на основании собранных Prometheus метрик.
Конфигурация Prometheus будет выглядеть вот так.
global:
scrape_interval: 10s # prometheus будет выполнять скрейпинг каждые 10 с
evaluation_interval: 10s
scrape_timeout: 2s
external_labels:
monitor: 'CDN'
scrape_configs:
- job_name: 'prometheus'
metrics_path: '/status/format/prometheus'
static_configs:
- targets: ['edge:8080', 'backend:8080'] # список серверов, которые будут скрейпиться scrap_path
Теперь нам нужно добавить источник Prometheus для Grafana.
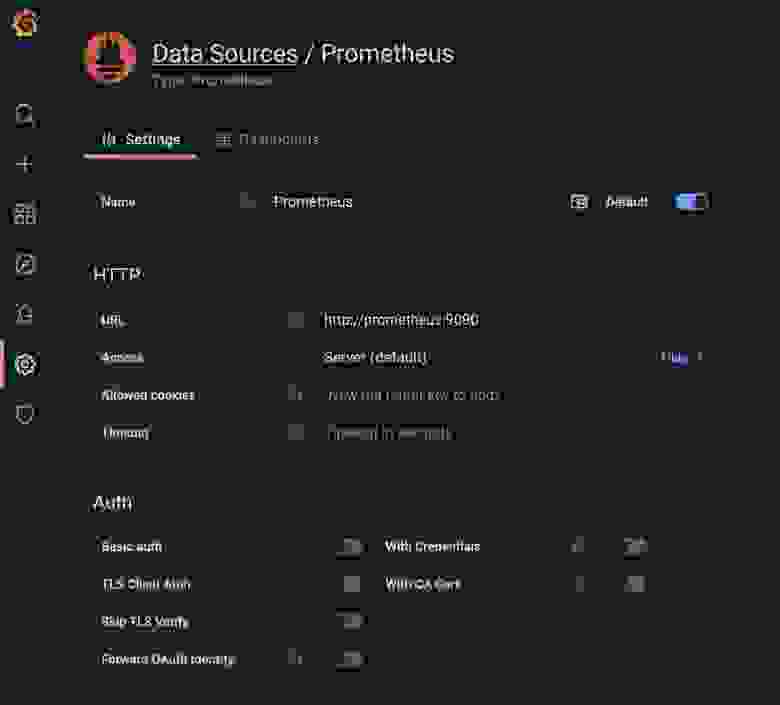
И настроить сервер Prometheus.
Симуляция работы (задержка)
Бэкенд-сервер создаёт ответы искусственным образом. При помощи Lua мы добавим симулируемую задержку. Смысл в том, чтобы приблизить систему к реальному миру. Мы будем моделировать задержки при помощи перцентилей.
percentile_config={
{p=50, min=1, max=20,}, {p=90, min=21, max=50,}, {p=95, min=51, max=150,}, {p=99, min=151, max=500,},
}
Мы случайным образом выбираем число от 1 до 100, а затем применяем ещё одно случайное значение при помощи соответствующего профиля перцентилей в интервале от min до max. Наконец, мы выполняем sleep в течение этого времени.
local current_percentage = random(1, 100) -- решаем, в каком перцентиле будет этот запрос
-- допустим, мы выбрали 94
-- следовательно, используем percentile_config с p90
local sleep_duration = random(p90.min, p90.max)
sleep(sleep_seconds)
Эта модель позволяет нам эмулировать задержки, наблюдаемые в реальном мире.
Нагрузочное тестирование
Мы выполним нагрузочное тестирование, чтобы больше узнать о создаваемом нами решении. Wrk — это инструмент HTTP-бенчмаркинга, который можно динамически конфигурировать при помощи Lua. Мы выбираем случайное число от 1 до 100 и запрашиваем этот элемент.
request = function()
local item = "item_" .. random(1, 100)
return wrk.format(nil, "/" .. item .. ".ext")
end
Командная строка будет выполнять тесты в течение 10 минут (600s), используя два потока и 10 соединений.
wrk -c10 -t2 -d600s -s ./src/load_tests.lua --latency http://localhost:8081
Разумеется, можно запустить их и на своей машине:
docker-compose up
# выполняем тесты
./load_test.sh
# проверяем в grafana, как себя ведёт система
http://localhost:9091
Вывод wrk показан ниже. Было выполнено 37 тысяч запросов, 674 из которых оказались сбойными.
Running 10m test @ http://localhost:8081
2 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 218.31ms 236.55ms 1.99s 84.32%
Req/Sec 35.14 29.02 202.00 79.15%
Latency Distribution
50% 162.73ms
75% 350.33ms
90% 519.56ms
99% 1.02s
37689 requests in 10.00m, 15.50MB read
Non-2xx or 3xx responses: 674
Requests/sec: 62.80
Transfer/sec: 26.44KB
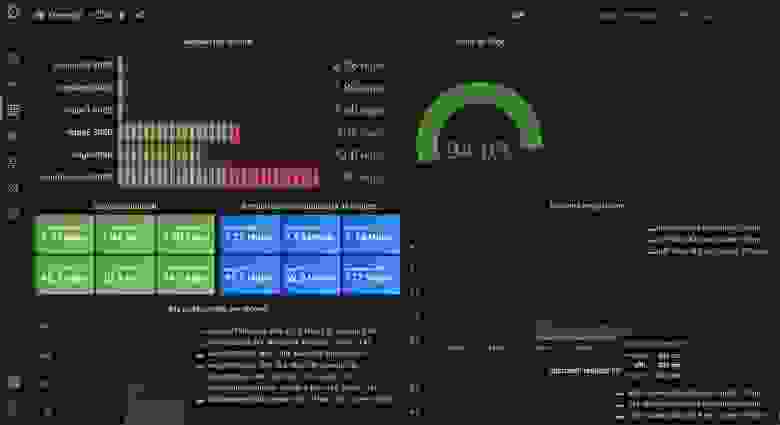
Grafana показывает, что единовременно edge отвечал на 68 запросов. Из этих запросов 16 прошли через backend. Эффективность кэша составила 76%, 1% задержки запроса был дольше 3,6 с, у 5% наблюдаемых — более чем 786 мс, а медианное значение оказалось примерно равным 73 мс.
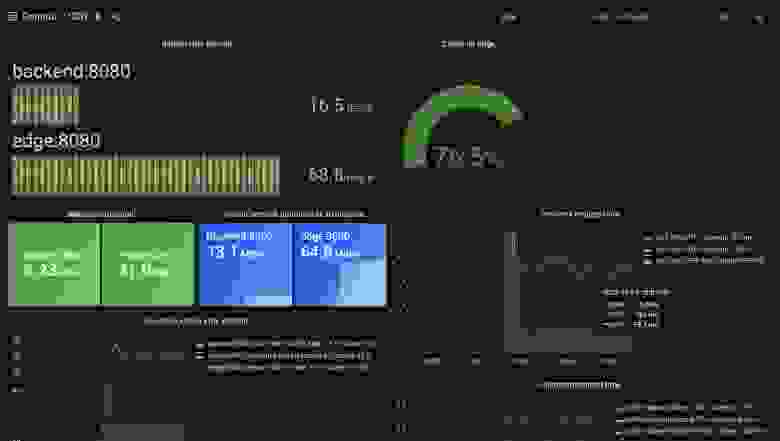
Учимся, тестируя: поменяем TTL (max age) кэша
Этот проект должен мотивировать вас экспериментировать, менять значения параметров, выполнять нагрузочное тестирование и проверять результаты. Думаю, этот цикл отлично подойдёт для обучения. Давайте попробуем проверить, что происходит, когда мы меняем поведение кэша.
1 секунда
Используем в качестве срока валидности кэша значение в 1 с.
request = function()
local item = "item_" .. random(1, 100)
return wrk.format(nil, "/" .. item .. ".ext?max_age=1")
end
После выполнения тестов мы получим следующий результат: всего 16 тысяч запросов с 773 ошибками.
Running 10m test @ http://localhost:8081
2 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 378.72ms 254.21ms 1.46s 68.40%
Req/Sec 15.11 9.98 90.00 74.18%
Latency Distribution
50% 396.15ms
75% 507.22ms
90% 664.18ms
99% 1.05s
16643 requests in 10.00m, 6.83MB read
Non-2xx or 3xx responses: 773
Requests/sec: 27.74
Transfer/sec: 11.66KB
Также мы заметили, что количество попаданий кэша существенно снизилось (23%), и гораздо больше запросов начало утекать в бэкенд.
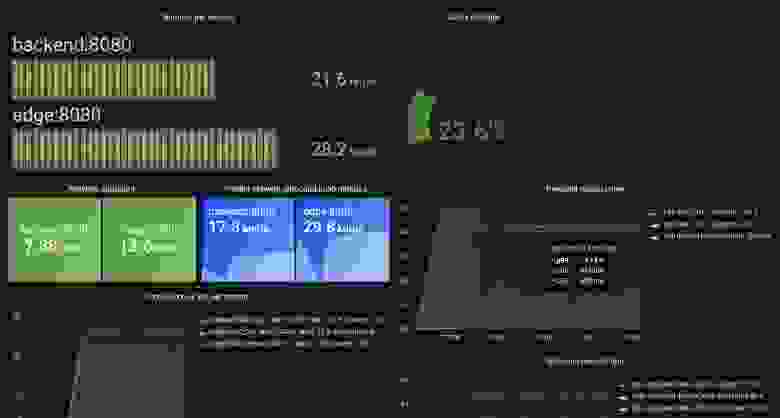
60 cекунд
Что, если мы увеличим срок жизни кэша до целой минуты?
request = function()
local item = "item_" .. random(1, 100)
return wrk.format(nil, "/" .. item .. ".ext?max_age=60")
end
После выполнения тестов результат оказался таким: 45 тысяч запросов с 551 ошибкой.
Running 10m test @ http://localhost:8081
2 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 196.27ms 223.43ms 1.79s 84.74%
Req/Sec 42.31 34.80 242.00 78.01%
Latency Distribution
50% 79.67ms
75% 321.06ms
90% 494.41ms
99% 1.01s
45695 requests in 10.00m, 18.79MB read
Non-2xx or 3xx responses: 551
Requests/sec: 76.15
Transfer/sec: 32.06KB
Мы видим существенно увеличившуюся эффективность кэша (80% вместо 23%) и пропускную способность (45 тысяч вместо 16 тысяч).
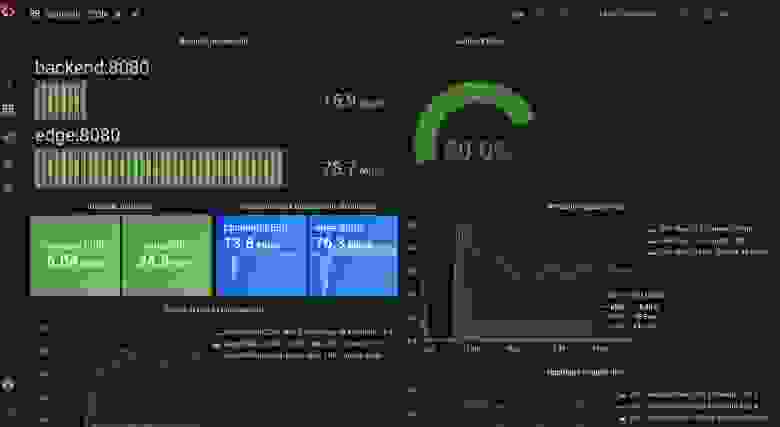
Подсказка: более долгий срок валидности кэша помогает повысить производительность, однако ценой устаревания контента.
Тонкая настройка: блокировка кэша, устаревание, таймаут, сеть
Для многих небольших нагрузок вполне подойдут стандартные конфигурации Nginx, Linux и других инструментов. Однако если ваша задача более амбициозна, то вам неизбежно придётся подстраивать CDN под свои требования.
Процесс тонкой настройки веб-сервера — очень трудоёмкая задача. Он простирается от управления обработкой сокетов в nginx/Linux до опрашивания сети в Linux и влияния ввода-вывода на производительность, а также учитывает ещё множество других аспектов. Существует сильный симбиоз между приложением и ОС, непосредственно влияющий на производительность, например, экономия переключения контекста пространства пользователя при помощи ktls.
Вам придётся изучать множество страниц документации, в основном для настройки таймаутов и буферов. Цикл тестирования позволит вам проверять свои идеи. Пример:
- у вас есть гипотеза или вы заметили что-то странное и хотите протестировать значение параметра (каждый раз используйте единый набор связанных с ним параметров);
- задаёте новое значение;
- выполняете тесты;
- сравниваете результаты для того же сервера со старым параметром.
Подсказка: локальное выполнение тестов вполне подходит для обучения, однако чаще всего вам придётся доверять только результатам в продакшене. Будьте готовы к необходимости выполнения частичного развёртывания, сравнению старых систем/конфигураций с новыми тестируемыми параметрами.
Вы заметили, что ошибки были связаны с таймаутами? Похоже, бэкенду нужно больше времени для ответа, чем готов ждать edge.
edge_1 | 2021/12/29 11:52:45 [error] 8#8: *3 upstream timed out (110: Operation timed out) while reading response header from upstream, client: 172.25.0.1, server: , request: "GET /item_34.ext HTTP/1.1", upstream: "http://172.25.0.3:8080/item_34.ext", host: "localhost:8081"">edge_1 | 2021/12/29 11:52:45 [error] 8#8: *3 upstream timed out (110: Operation timed out) while reading response header from upstream, client: 172.25.0.1, server: , request: "GET /item_34.ext HTTP/1.1", upstream: "http://172.25.0.3:8080/item_34.ext", host: "localhost:8081"
Чтобы решить эту проблему, мы можем попробовать увеличить таймауты прокси. Также можно использовать удобную директиву proxy_cache_use_stale, передающую устаревший контент, пока Nginx работает с ошибками, таймаутами или даже с обновлением кэша.
proxy_cache_lock_timeout 2s;
proxy_read_timeout 2s;
proxy_send_timeout 2s;
proxy_cache_use_stale error timeout updating;
Когда мы читали о прокси-кэшировании, кое-что привлекло наше внимание. Существует директива proxy_cache_lock, объединяющая множественные запросы пользователей к одному контенту в единый запрос, идущий upstream для получения контента одновременно. Часто это называют coalescing.
proxy_cache_lock on
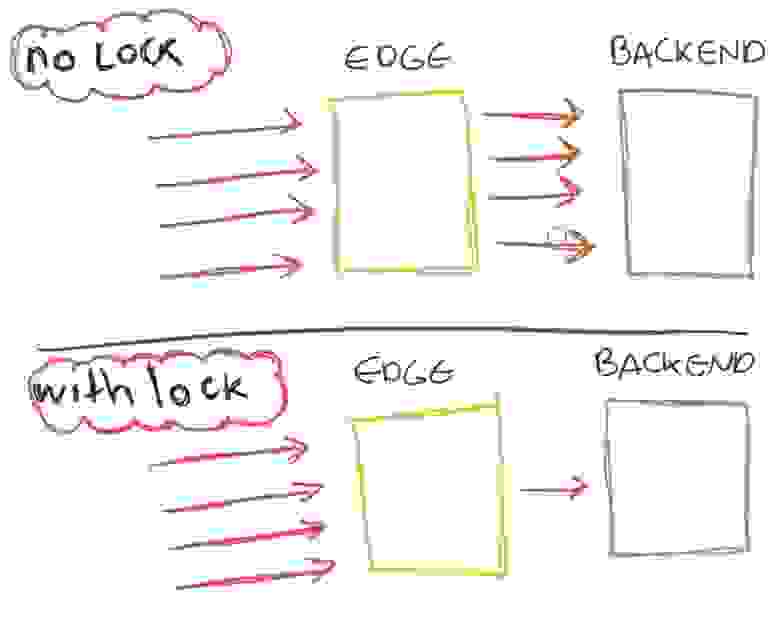
Выполняя тесты, мы заметили, что уменьшаем ошибки таймаута, но также снижаем и пропускную способность. Почему? Возможно, это вызвано конфликтом при блокировках (lock contention). Большое преимущество этой функции заключается в том, что она позволяет избегать несметных орд запросов в бэкенде. Трафик снизился с 6 тысяч до 3 тысяч, а запросы — с 16 до 8.
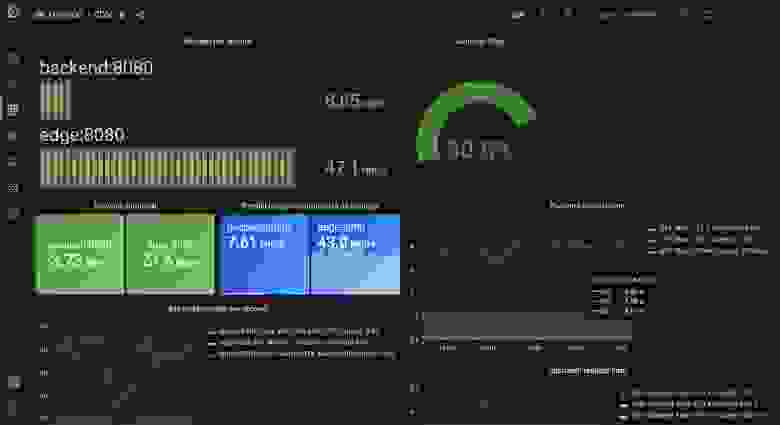
От нормального распределения к распределению длинного хвоста
Мы выполняли нагрузочное тестирование, исходя из нормального распределения, однако это далеко от реальности. В продакшене мы можем увидеть, что большинство запросов обращено к малому количеству элементов. Чтобы ближе симулировать это, мы можем дополнить свой код так, чтобы он случайно выбирал число от 1 до 100, а потом решал, популярный ли это элемент.
local popular_percentage = 96 -- 96% пользователей запрашивают пять самых популярных элементов контента
local popular_items_quantity = 5 -- количество популярных элементов контента
local max_total_items = 200 -- общее количество элементов, запрашиваемых клиентами
request = function()
local is_popular = random(1, 100) <= popular_percentage
local item = ""
if is_popular then -- если он популярный, будем выбирать один из популярных элементов
item = "item-" .. random(1, popular_items_quantity)
else -- в противном случае выбираем любой из оставшихся элементов
item = "item-" .. random(popular_items_quantity + 1, popular_items_quantity + max_total_items)
end
return wrk.format(nil, "/path/" .. item .. ".ext")
end
Подсказка: мы можем смоделировать длинный хвост при помощи формулы, но для нашего примера такой интерполяции может быть вполне достаточно.
Теперь давайте снова выполним тест с отключённой и включённой proxy_cache_lock.
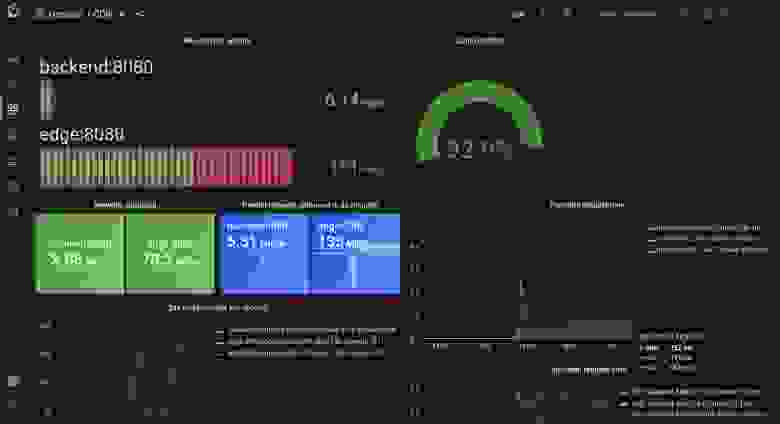
Отключённая proxy_cache_lock длинного хвоста
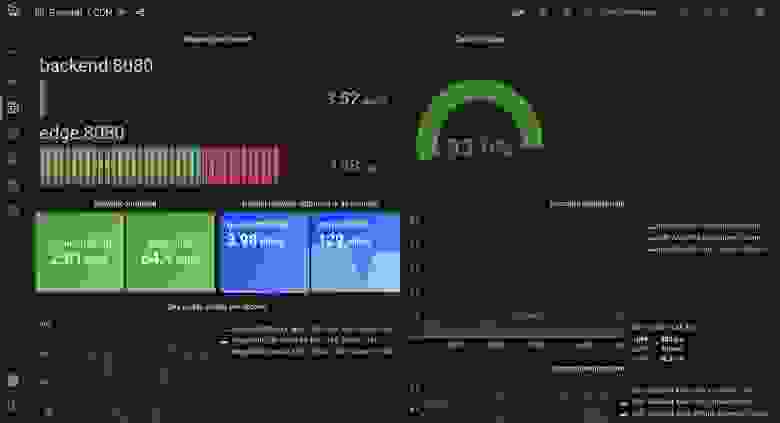
Включённая proxy_cache_lock длинного хвоста
Показатели довольно близки, хотя lock off и чуть лучше. Возможно, стоит проверить эту функцию в продакшене.
Подсказка: proxy_cache_lock_timeout опасна, но необходима. Если истечёт сконфигурированное время, все запросы будут отправляться в бэкенд.
Сложности маршрутизации
Мы тестировали один edge, но в реальности будут существовать сотни узлов. Наличие большего количества узлов edge необходимо для масштабируемости, надёжности и обеспечения близости к ответам пользователей. При добавлении множества узлов мы добавляем и новые сложности: клиентам нужно каким-то образом понять, с какого узла получать контент.
Для решения этой проблемы существуют различные способы, и мы попробуем изучить некоторые из них.
Балансировка нагрузки
Балансировщик нагрузки распределяет запросы клиентов по всем edge.
▍ Циклический перебор
Циклический перебор (Round-robin) — это политика балансировки, получающая упорядоченный список edge и обрабатывающая запросы, каждый раз выбирая сервер и начиная сначала после завершения списка серверов.
# если мы не указываем ничего в nginx, то по умолчанию будет использоваться политика взвешенного round-robin
# http://nginx.org/en/docs/http/ngx_http_upstream_module.html#upstream
upstream backend {
server edge:8080;
server edge1:8080;
server edge2:8080;
}
server {
listen 8080;
location / {
proxy_pass http://backend;
add_header X-Edge LoadBaalancer;
}
}
Что же хорошего в round-robin? Все запросы почти равномерно распределяются по всем серверам. Могут существовать медленные серверы или ответы, ставящие в очередь множество запросов. Существует директива least_conn, также учитывающая количество соединений.
Что в ней плохого? Она не учитывает кэширование, то есть множество клиентов может столкнуться с повышенными задержками, потому что они запрашивают некэшированные серверы.
# время для демонстрации
git checkout 4.0.0
docker-compose up
./load_test.sh
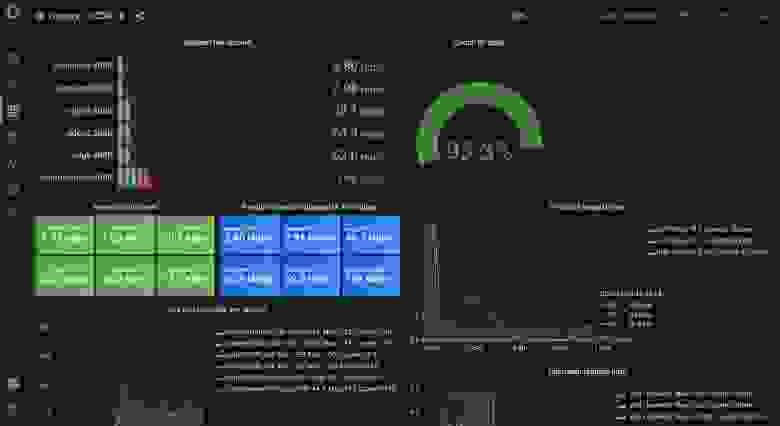
Подсказка: сам балансировщик нагрузки играет здесь роль единой точки отказа. У Facebook* есть отличный доклад, в котором рассказывается, как компания создала надёжный, удобный в обслуживании и масштабируемый балансировщик нагрузок. [*Запрещённая в России социальная сеть.]
▍ Согласованное хеширование
Учёт кэширования важен для CDN, поэтому сложно использовать round-robin в её исходном виде. Существует способ балансировки под названием согласованное хеширование, предназначенный для решения этой проблемы при помощи выбора сигнала (например, uri) и сопоставления его с хеш-таблицей при согласованной отправке всех запросов одному серверу.
В Nginx для этого тоже есть директива под названием hash.
upstream backend {
hash $request_uri consistent;
server edge:8080;
server edge1:8080;
server edge2:8080;
}
server {
listen 8080;
location / {
proxy_pass http://backend;
add_header X-Edge LoadBaalancer;
}
}
Что хорошего в согласованном хешировании? Оно реализует политику, увеличивающую вероятность попадания в кэш.
Что в нём плохого? Представьте, что возникло пиковое использование одного контента (видео, игры), и теперь у нас возникла проблема: большинству клиентов отвечает малое количество серверов.
Подсказка: для решения этой проблемы придумали согласованное хеширование с ограничением нагрузки.
# время для демонстрации
git checkout 4.0.1
docker-compose up
./load_test.sh
Подсказка: изначально я использовал библиотеку Lua, потому что думал, что согласованное хеширование доступно только в коммерческой версии Nginx.
▍ Узкое место балансировщика нагрузок
У балансировщика нагрузок есть как минимум две проблемы (кроме того, что это единая точка отказа):
- Network egress — ёмкость полосы пропускания ввода/вывода балансировщика нагрузок должна быть не меньше суммы для всех его серверов. Можно использовать DSR или 307.
- Распределённые edge — могут существовать географически разбросанные узлы, представляющие трудности для балансировщика нагрузок.
Достижимость сети
Многие из проблем, которые мы рассматривали в разделе о балансировщике нагрузок, связаны с достижимостью сети. Здесь мы рассмотрим некоторые способы устранения этой трудности, каждый из которых имеет свои плюсы и минусы.
▍ API
Мы можем добавить API (cdn-маршрутизацию), и все клиенты будут узнавать, где искать контент (конкретный узел edge), только спросив у этого API. Возможно, клиентам придётся иметь дело с аварийным переключением (failover).
Подсказка: решая проблему на стороне ПО, можно объединить лучшее из двух миров — начать балансировку с использованием согласованного хеширования, а когда контент станет популярным, использовать естественное распределение получше.
▍ DNS
Для этого можно использовать DNS. Это решение кажется похожим на использование API, но здесь мы будем полагаться на TTL DNS-кэширования. Аварийное переключение в таком случае будет ещё более жёстким.
▍ Anycast
Также можно использовать единый домен/IP, оповещая об IP все места, где есть узлы, уходя от протоколов сетевой маршрутизации, чтобы находить ближайший узел для конкретного пользователя.
Прочее
Мы не рассмотрели множество важных аспектов CDN, например:
- Пиринг — CDN хостят свои узлы/контент у Интернет-провайдеров, в публичных местах пиринга и частных местах.
- Безопасность — CDN подвергаются множествам атак, DDoS, отравлению кэширования и прочему.
- Стратегии кэширования — в некоторых случаях вместо получения контента из бэкенда сам бэкенд передаёт контент на edge.
- Арендаторы/изоляция — CDN хостят множество клиентов на одинаковых узлах, поэтому изоляция обязательна. Метрики, площадь кэширования, конфигурации (политики кэширования, бэкенд) и так далее.
- Токены — CDN обеспечивают защиту токенами для контента от неавторизованных клиентов.
- Проверка состояния (обнаружение сбоев) — информирование о функциональности узла.
- HTTP-заголовки — очень часто (например, CORS) клиенту нужно добавлять какие-то заголовки (иногда динамически)
- Геоблокировка — для экономии средств или реализации договорных ограничений CDN используют политики ограничений по местоположению пользователей.
- Очистка — способность очистки контента из кэша.
- Троттлинг — ограничение количества одновременных запросов.
- Edge-вычисления — способность выполнять код в качестве фильтра для хостящегося контента.
- и так далее…
Заключение
Надеюсь, вы чуть больше узнали о том, как работает CDN. Это сложная система, сильно зависящая от того, как близко к клиентам расположены узлы и насколько хорошо распределена нагрузка, требующая учёта кэширования для сглаживания пиков и падений трафика.
Играй в нашу новую игру прямо в Telegram!

