[Перевод] Современные накопители очень быстры, но плохие API это не учитывают

Почти десять лет я проработал в компании, создающей довольно специализированный продукт — высокопроизводительные системы ввода-вывода. Я имел возможность наблюдать за быстрой и решительной эволюцией технологий хранения данных.
В этом году я сменил работу. Окружённый в новой большой компании инженерами, имевшими опыт в разных сферах работы, я удивился тому, что у каждого из моих коллег, несмотря на выдающийся ум, сложились ложные представления о том, как наилучшим способом использовать современные технологии хранения. Даже если они и были в курсе совершенствования технологий, такие представления приводили к созданию неоптимальных архитектур.
Поразмышляв о причинах этой неувязки, я понял, что в основном устойчивость таких заблуждений вызвана следующим: даже если они проверяли свои предположения при помощи бенчмарков, то данные показывали их (кажущуюся) истинность.
Вот самые распространённые примеры таких заблуждений:
- «Вполне нормально скопировать память здесь и выполнить эти затратные вычисления, потому что это сэкономит нам одну операцию ввода-вывода, которая была бы ещё более затратной».
- «Я проектирую систему, которая должна быть быстрой. Поэтому она должна находиться в памяти».
- «Если мы разобьём эти данные на несколько файлов, то выполнение будет медленным, поскольку возникнут паттерны произвольного ввода-вывода. Нам нужно оптимизировать выполнение под последовательный доступ и осуществлять считывание из одного файла».
- «Прямой ввод-вывод очень медленный. Он подходит только для очень специализированных областей применения. Если у тебя нет собственного кэша, ты обречён».
Однако если изучить спецификации современных NVMe-устройств, то мы увидим, что даже в потребительском классе это устройства с задержками, измеряемыми в единицах микросекунд, и пропускной способностью в несколько ГБ/с, поддерживающие несколько сотен тысяч произвольных IOPS. Так в чём же нестыковка?
В этой статье я покажу, что несмотря на то, что за прошедшее десятилетие «железо» значительно изменилось, программные API остались прежними или почти не поменялись. Устаревшие API, заполненные копиями памяти, распределением памяти, чрезмерно оптимистичным упреждающим кэшированием при чтении, а также другими всевозможными затратными операциями, мешают нам использовать большинство функций современных устройств.
В процессе написания статьи мне довелось насладиться преимуществами раннего доступа к одному из устройств следующего поколения Optane компании Intel. Хотя они пока ещё не заняли своё место на рынке, эти устройства определённо станут венцом современных тенденций по стремлению ко всё более быстрому оборудованию. Перечисленные в статье показатели были получены на этом устройстве.
В целях экономии времени я буду рассматривать только считывание. Операции записи имеют собственный уникальный спектр тонкостей, а также возможностей совершенствования, которые я рассмотрю в следующей статье.
У традиционных API на основе файлов есть три основные проблемы:
- Они выполняют множество затратных операций, потому что «ввод-вывод — это слишком затратно».
Когда устаревшим API нужно считать данные, которые не кэшированы в памяти, они генерируют page fault. Потом, когда данные готовы, они генерируют прерывание. Наконец, для традиционного считывания на основе системного вызова требуется дополнительная копия в буфере пользователя, а для операций на основе mmap нужно обновлять распределение виртуальной памяти.
Ни одна из этих операций (page fault, прерывания, копии или распределение виртуальной памяти) не является малозатратной. Однако многие годы назад они всё равно были примерно в сто раз «дешевле», чем затраты на сам ввод-вывод, из-за чего такой подход был приемлемым. Но сегодня это уже не так — задержки устройств приближаются к единицам микросекунд. Такие операции сейчас имеют тот же порядок величин, что и сама операция ввода-вывода.
Приблизительный подсчёт показывает, что в наихудшем случае меньше половины общих затрат на занятость приходится на затраты самого общения с устройством. И это не считая всей пустой траты ресурсов, что приводит нас ко второй проблеме:
- Увеличение объёмов считывания.
Я опущу некоторые подробности (например, память, используемую дескрипторами файлов, и различные кэши метаданных в Linux), но если современные NVMe поддерживают множественные параллельные операции, то нет причин полагать, что считывание из нескольких файлов более затратно, чем считывание из одного. Однако определённо важно общее количество считываемых данных.
Операционная система считывает данные с глубиной детализации в страницу, это означает, что она может считывать минимум по 4 КБ за раз. Это значит, что если нам нужно считать 1 КБ, разделённый на два файла по 512 байта каждый, то мы, по сути, для передачи 1 КБ считываем 8 КБ, впустую тратя 87% операции чтения. На практике, ОС также выполняет упреждающее чтение (по умолчанию на 128 КБ), ожидая, что это сэкономит такты позже, когда вам понадобятся оставшиеся данные. Но если они вам никогда не понадобятся, как это часто бывает в случае произвольного ввода-вывода, то вы просто считываете 256 КБ для передачи 1 КБ, тратя впустую 99% данных.
Если вы решите проверить моё заявление о том, что считывание из нескольких файлов не должно быть фундаментально медленнее считывания из одного файла, то, возможно, докажете собственную правоту, но только потому, что объём считывания значительно увеличивается на величину фактически считываемых данных.
Поскольку проблема заключается в страничном кэше ОС, то что произойдёт, если мы просто откроем файл прямым вводом-выводом, при всех прочих равных условиях? К сожалению, так тоже не будет быстрее. Но в этом и заключается наша третья, и последняя, проблема:
- Традиционные API не пользуются параллельной обработкой данных.
Файл рассматривается как последовательный поток байтов, и считывающий не знает, находятся ли данные в памяти, или нет. Традиционные API ждут, пока вы не затронете данные, не находящиеся в памяти, и только потом отдают команду на выполнение операции ввода-вывода. Из-за упреждающего считывания операция ввода-вывода может быть больше, чем затребовал пользователь, но это всё равно только одна операция.
Однако, как бы ни были быстры современные устройства, они по-прежнему медленнее, чем процессор. Пока устройство ожидает возврата операции ввода-вывода, процессор ничего не делает.
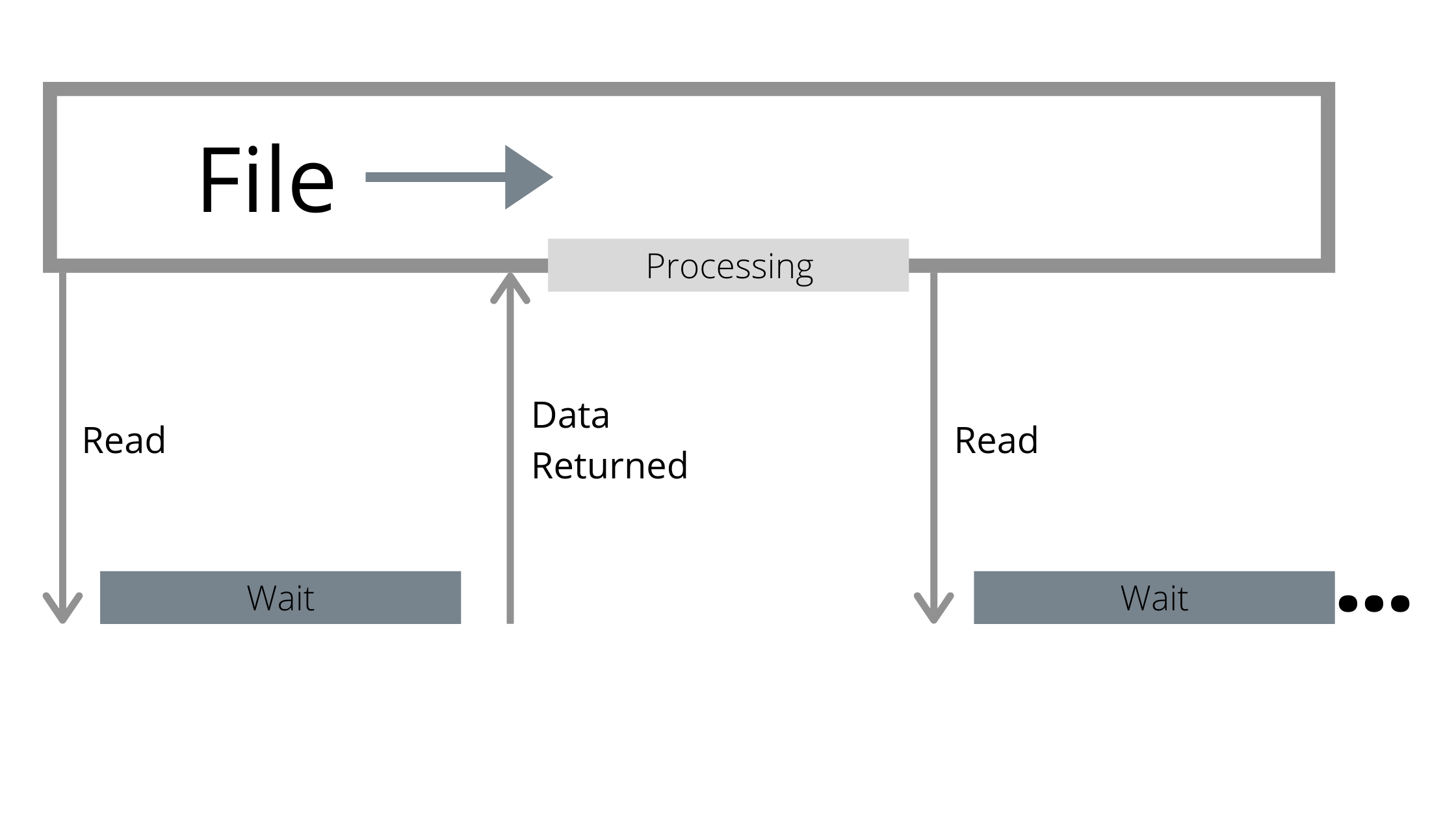
Отсутствие параллельной обработки данных в традиционных API приводит к тому, что процессоры простаивают, ожидая возврата данных операцией ввода-вывода.
Использование нескольких файлов является шагом в правильном направлении, потому что оно позволяет более эффективно выполнять параллельную обработку: пока один считывающий процесс ожидает, другой может продолжать работу. Но если не быть аккуратным, то можно усугубить одну из предыдущих проблем:
- Работа с несколькими файлами подразумевает наличие нескольких буферов упреждающего считывания, что повышает показатель пустой траты ресурсов при произвольном вводе-выводе.
- В API на основе опроса потоков использование нескольких файлов означает несколько потоков, что увеличивает объём работы, выполняемой на каждую операцию ввода-вывода.
Не говоря уже о том, что во многих ситуациях нам нужно что-то другое, например, у нас может и не быть большого количества файлов.
В прошлом я подробно писал о том, насколько революционен интерфейс io_uring. Но поскольку это довольно низкоуровневый интерфейс, он является только одним фрагментом паззла API. И вот почему:
- Ввод-вывод, выполняемый через io_uring, всё равно будет страдать от большинства описанных выше проблем, если он использует буферизованные файлы.
- У прямого ввода-вывода есть множество нюансов, а io_uring, являясь «сырым» интерфейсом, не стремится скрывать эти проблемы (да и не должен этого делать): например, память должна быть правильно выровнена, как и места, из которых выполняется чтение.
- Кроме того, он очень низкоуровневый и «сырой». Чтобы он был полезным, нужно накапливать операции ввода-вывода и управлять ими пакетно. Это требует политик определения моментов, когда это нужно выполнять, а также некого цикла событий, поэтому он будет лучше работать с фреймворком, у которого уже есть вся необходимая функциональность.
Для решения проблемы с API я спроектировал Glommio (ранее известную как Scipio) — библиотеку Rust, ориентированную на прямой ввод-вывод с одним потоком на каждое ядро. Glommio построена на основе io_uring и поддерживает множество его продвинутых возможностей, позволяющих пользоваться всеми преимуществами прямого ввода-вывода. Ради удобства Glommio поддерживает буферизованные файлы с поддержкой страничного кэша Linux, напоминающей стандартные API Rust (которые мы ниже используем для сравнения), однако основной упор она делает на прямой ввод-вывод (Direct I/O).
В Glommio существует два класса файлов: файлы с произвольным доступом и потоки.
Файлы с произвольным доступом получают в качестве аргумента позицию, то есть хранение seek cursor не требуется. Но важнее всего то, что они не получают в качестве параметра буфер. Вместо этого они используют заранее зарегистрированную буферную область io_uring для выделения буфера и возврата пользователю. Это означает отсутстие необходимости выделения памяти и копирования буфера пользователя — есть только копия с устройства на буфер glommio, а пользователь получает указатель с подсчётом ссылок на неё. И поскольку мы знаем, что ввод-вывод произвольный, не требуется считывать данных больше, чем было запрошено.
pub async fn read_at<'_>(&'_ self, pos: u64, size: usize) -> Result
Потоки подразумевают, что вы постепенно пройдёте по всему файлу, поэтому они могут позволить использовать больший размер блоков и упреждающего считывания.
Потоки спроектированы таким образом, чтобы быть похожими на стандартные AsyncRead языка Rust, поэтому в них реализовано поведение AsyncRead и они считывают данные в буфер пользователя. Все преимущества сканирования на основе прямого ввода-вывода по-прежнему можно использовать, но теперь существует копия между нашими внутренними буферами упреждающего считывания и буфером пользователя. Это цена, которую приходится платить за удобство пользования стандартным API.
Если вам нужна дополнительная производительность, glommio предоставляет API для потока, который также обеспечивает доступ к сырым буферам, избавляя от необходимости лишней копии.
pub async fn get_buffer_aligned<'_>(
&'_ mut self,
len: u64
) -> Result
Для демонстрации этих API у glommio есть пример программы, выполняющий ввод-вывод с различными параметрами с использованием всех этих API (буферизованный, прямой ввод-вывод, произвольный, последовательный) и оценивающий их производительность.
Мы начнём с файла, который примерно в 2,5 раза больше объёма памяти. Для начала просто считаем его последовательно, как обычный буферизованный файл:
Буферизованный ввод-вывод: отсканировано 53 ГБ за 56 с, 945,14 МБ/с
Вполне неплохо, учитывая, что этот файл не помещается в память, но здесь все преимущества обеспечивает исключительная производительность Intel Optane и бекэнд io_uring. Эффективность параллельной обработки данных всё равно проявляется при выполнении ввода-вывода и хотя размер страницы ОС составляет 4 КБ, упреждающее считывание позволяет нам эффективно увеличить размер ввода-вывода.
Если бы мы попробовали эмулировать похожие параметры при помощи Direct I/O API (буферы 4 КБ, параллельная обработка одного файла), то результаты бы нас разочаровали, «подтверждая» наши подозрения о том, что прямой ввод-вывод и в самом деле намного медленнее.
Прямой ввод-вывод: отсканировано 53 ГБ за 115 с, 463,23 МБ/с
Но как мы говорили, файловые потоки прямого ввода-вывода в glommio могут принимать явно заданный параметр упреждающего считывания. Активная glommio может передавать запросы ввода-вывода для позиции с опережением текущего считывания для использования возможностей параллельной обработки данных устройства.
Работа упреждающего считывания в Glommio отличается от принципа упреждающего считывания в ОС: наша цель — использовать параллельную обработку данных, а не просто увеличить размеры ввода-вывода. Вместо того, чтобы потреблять весь буфер упреждающего считывания и только после этого отправлять запрос на новый пакет, glommio отправляет новый запрос сразу после потребления содержимого буфера и всегда старается поддерживать постоянное количество действующих буферов, как показано на рисунке ниже.
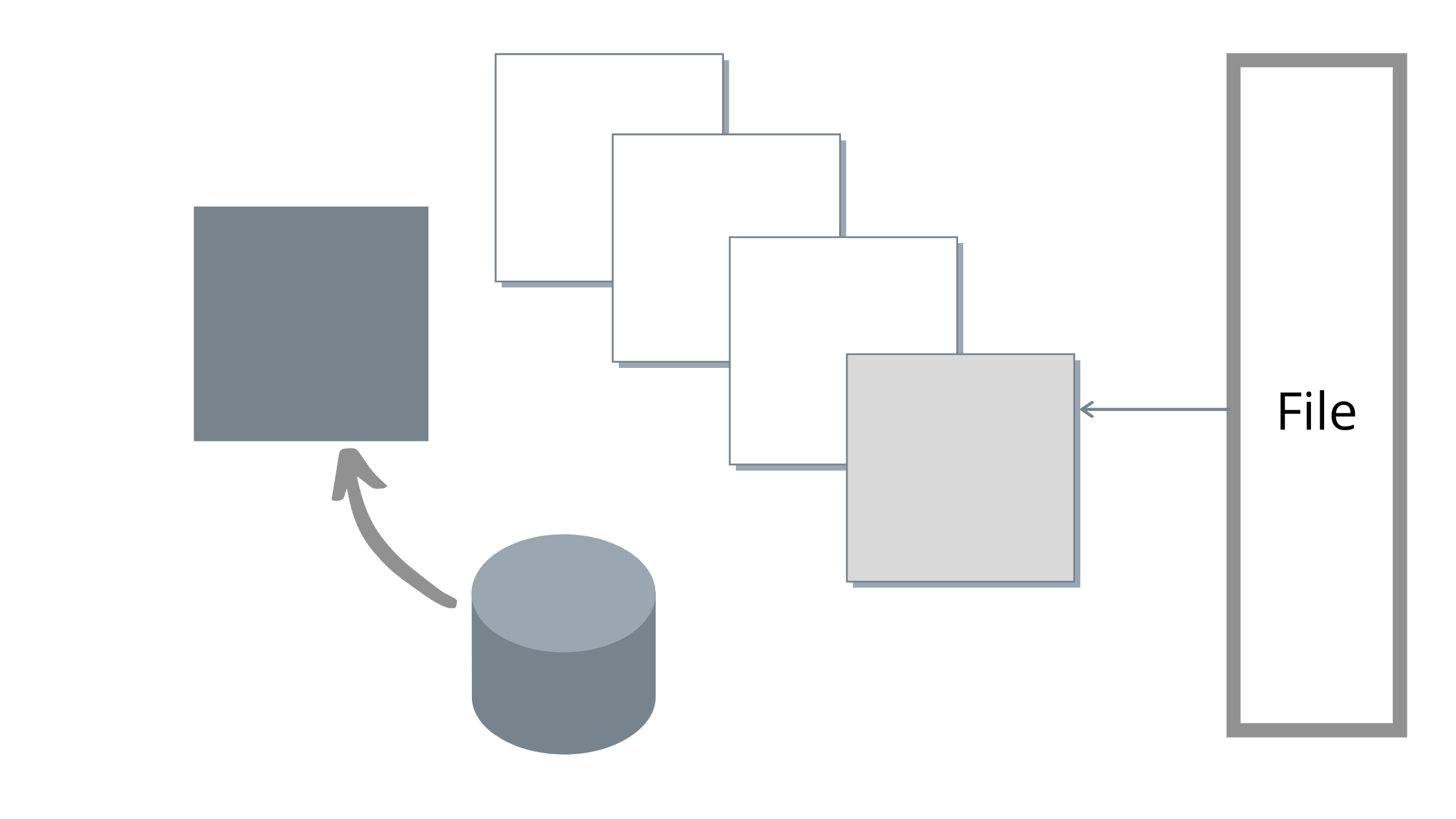
В процессе опустошения одного буфера уже запрашивается ещё один буфер. Благодаря этому повышается параллельность обработки.
Как изначально и ожидалось, после правильной реализации параллельной обработки заданием показателя упреждающего считывания, прямой ввод-вывод не только сравнялся с буферизованным вводом-выводом, но и стал на самом деле намного быстрее.
Прямой ввод-вывод, упреждающее считывание: отсканировано 53 ГБ за 22 с, 2,35 ГБ/с
Эта версия всё ещё использует интерфейсы AsyncReadExt языка Rust, что заставляет создавать дополнительную копию из буферов glommio в буферы пользователя.
При помощи get_buffer_aligned API предоставляет «сырой» доступ к буферу, позволяющему избежать последнего копирования в память. Если мы используем его сейчас для теста считывания, то получим солидную прибавку производительности в 4%.
Прямой ввод-вывод, API glommio: отсканировано 53 ГБ за 21 с, 2,45 ГБ/с
Последним шагом будет увеличение размера буфера. Поскольку это последовательное сканирование, мы не обязаны ограничиваться размером буфера в 4 КБ; это можно сделать только для сравнения с производительностью страничного кэша ОС.
Давайте подведём итог тому, что происходит внутри glommio и io_uring при помощи следующего теста:
- каждый запрос ввода-вывода имеет размер 512 КБ,
- многие из них (5) остаются активными для обеспечения параллельной обработки,
- память выделяется и регистрируется предварительно
- в буфер пользователя не выполняется дополнительной копии
- io_uring переключен в режим опроса, то есть отсутствуют копии в память, прерывания и переключения контекста.
Какими же получились результаты?
Прямой ввод-вывод, API glommio, большой буфер: отсканировано 53 ГБ за 7 с, 7,29 ГБ/с
Это в семь с лишним раз лучше, чем стандартное решение с буферизацией. Более того, использование памяти никогда не бывает выше, чем заданный показатель упреждающего считывания, умноженный на размер буфера. В нашем примере это 2,5 МБ.
Сканирование сильно снижает производительность страничного кэша ОС. А как мы справимся с произвольным вводом-выводом? Чтобы проверить это, мы считаем столько, сколько успеем за 20 с, сначала ограничившись первыми 10% доступной памяти (1,65 ГБ)
Буферизованный ввод-вывод: размер 1,65 ГБ, в течение 20 с, 693870 IOPS
Для прямого ввода-вывода:
Прямой ввод-вывод: размер 1,65 ГБ, в течение 20 с, 551547 IOPS
Прямой ввод-вывод на 20% медленнее буферизованного считывания. Хотя считывание целиком из памяти по-прежнему быстрее, что никого не должно удивлять, разница далеко не так катастрофична, как можно было ожидать. На самом деле, если помнить, что буферизованная версия хранит 1,65 ГБ резидентной памяти для достижения этого результата, а прямой ввод-вывод использует всего 80 КБ (буферы 20×4 КБ), он может даже быть предпочтительным для определённых областей применения, в которых память лучше тратить на что-то другое.
Как вам скажет любой инженер по эксплуатации, хороший бенчмарк чтения должен считывать данные настолько, чтобы дойти до накопителя. Ведь, в конце концов, «накопители медленные». Если теперь мы выполним считывание из всего файла, то производительность буферизованного ввода-вывода значительно упадёт (на 65%)
Буферизованный ввод-вывод: размер 53,69 ГБ, в течение 20 с, 237858 IOPS
При этом прямой ввод-вывод, как и ожидалось, имеет ту же производительность и тот же уровень использования памяти вне зависимости от объёма считываемых данных.
Прямой ввод-вывод: размер 53,69 ГБ, в течение 20 с, 547479 IOPS
Если сравнивать по более объёмному сканированию, то прямой ввод-вывод в 2,3 раза быстрее, а не медленнее буферизованных файлов.
Современные NVMe-устройства меняют баланс наилучшей производительности ввода-вывода в приложениях с отслеживанием состояния. Эта тенденция развивалась уже долгое время, но пока её скрывал тот факт, что API (особенно высокоуровневые) не эволюционировали достаточно, чтобы соответствовать тому, что происходит в устройстве, а в последнее время и в слоях ядра Linux. При правильном подборе API прямой ввод-вывод обретает новую жизнь.
Самые новые устройства, например, последнее поколение Intel Optane, просто констатируют этот факт. Всегда найдётся ситуация, когда прямой ввод-вывод может быть лучше стандартного буферизованного ввода-вывода.
При сканировании хорошо продуманные API на основе прямого ввода-вывода просто не имеют равных. И хотя стандартные API на основе буферизованного ввода-вывода были на 20% быстрее при произвольных считываниях целиком помещающихся в памяти данных, за это приходится расплачиваться в 200 раз бОльшим размером используемой памяти, что не всегда является наилучшим решением.
Приложения, которым требуется дополнительная производительность, всё равно могут требовать кэширования части своих результатов, а скоро в glommio будет реализован простой способ интеграции специализированных кэшей для использования с прямым вводом-выводом.
На правах рекламы
Эпичные серверы для разработчиков и не только! Дешёвые VDS на базе новейших процессоров AMD EPYC и хранилища на основе NVMe дисков от Intel для размещения проектов любой сложности, от корпоративных сетей и игровых проектов до лендингов и VPN.

