[Перевод] Скорость времени
Сколько нужно времени, чтобы снять показания времени? Каков хронометраж времени? Эти странные вопросы выплыли в публичную плоскость еще в 2014 году, когда Netflix переносил свои сервисы с CentOS Linux на Ubuntu, а автору этой статьи довелось помогать в отладке некоторых причудливых проблем с производительностью. Одна из этих проблем и будет описана ниже. Конечно, маловероятно, что вы когда-нибудь столкнетесь с именно такой проблемой, но интересен сам тип данной проблемы и метод отладки, позволивший с ней справиться — на самом деле, очень простой. Прагматичное сочетание инструментов для наблюдения за ситуацией и постановки экспериментов. Автор этого текста, Брендан Грегг, делился множеством постов о суперсиле наблюдательных инструментов, но часто бывает и так, что непритязательный хакинг не менее эффективен.
Cassandra, кластер для работы с базами данных, переключили на Ubuntu — и стало заметно, что задержка при записи возросла более чем на 30%. Экспресс-проверка базовой статистики по производительности показала, что потребление ресурсов ЦП возросло более чем на 30%. Что же такое выделывает Ubuntu, если ей на это требуется на 30% больше процессорного времени?!
1. Инструменты CLI
Системы Cassandra представляли собой виртуализованные на Xen инстансы EC2. Автор этой статьи попробовал зайти на один из них и для начала прогнать некоторые базовые инструменты для работы с интерфейсом командной строки (составил для этой цели специальный чеклист). Может быть, это какая-то другая программа пожирает ЦП, например, распоясавшийся сервис Ubuntu, которого не было в CentOS? top (1) показала, что ЦП потребляет только база данных Cassandra.
Что насчет короткоживущих процессов, например, циклически перезапускаемого сервиса? Такие вещи могут оставаться невидимы для top (8). Автор попробовал инструмент execsnoop (8) (в те времена это еще была версия Ftrace), но он ничего не показал.
Казалось, что лишнее процессорное время тратится именно в Cassandra, но как?
2. Профиль ЦП
Будет легко составить впечатление о процессорном времени, если сравнить ступенчатые графики ЦП. Поскольку рассматриваемые инстансы, как CentOS, так и Ubuntu, работали параллельно, удалось одновременно снять с них ступенчатые графики и сопоставить их.
Ступенчатый график CentOS:
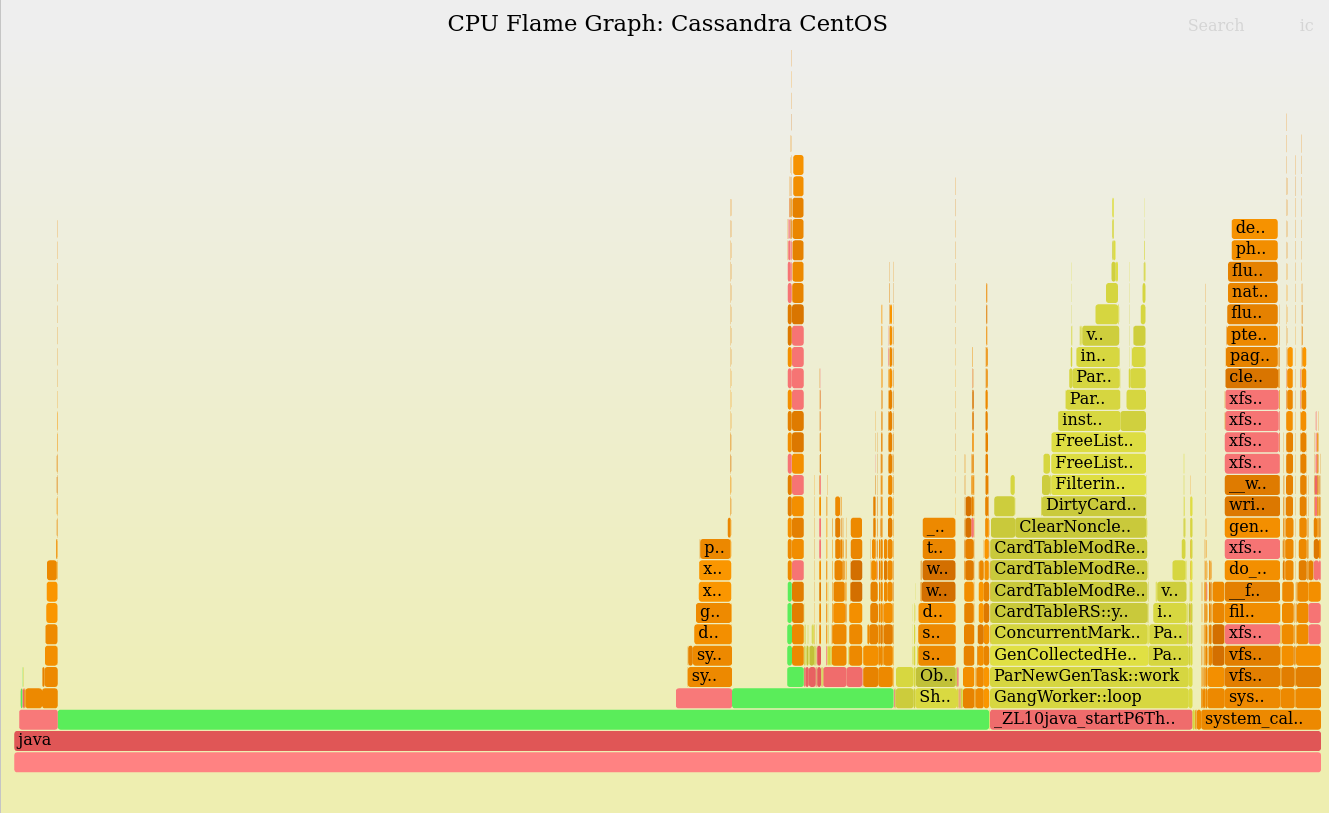
Ступенчатый график Ubuntu:

Черт возьми, да они же не работают. Здесь нет никакого стека Java — иначе зеленые методы Java должны были выситься как башня –, а найдется всего один, максимум два зеленых кадра. Вот как ступенчатые графики Java выглядели в то время. Несколько позже автору довелось прототипировать заплатку для указателя кадров c2; в результате получилась -XX:+PreserveFramePointer, фиксирующая стеки Java в этих профилях.
Даже с незафиксированными стеками Java была заметна большая разница: на Ubuntu куча процессорного времени тратится на вызов libjvm: os: javaTimeMillis (). 30,14% в середине ступенчатого графика. Поиск показывает, что и в другом месте на него тратилось лишнее время, в сумме 32,1%. Этот сервер тратит около трети циклов процессора, просто проверяя время!
Если задуматься, сама эта проблема кажется дикой: время превратилось в ресурс и в материал, требующий анализа производительности.
Оказалось, что поврежденные стеки Java даже пригодились. Благодаря ним вызовы os: javaTimeMillis () объединились в группы, а в противном случае они могли бы быть рассеяны поверх различных путей кода в Java, лежали бы повсюду как тоненькие стеки. Чтобы проверить, не так ли обстоит дело, автор специально прошерстил код, чтобы найти их суммарный процент, а также обратил порядок слияния, так, чтобы получился график-сосулька, где один из листьев сцеплен с корнем. Но в данном случае почти ничего делать не пришлось, потому что порядок объединения оказался в основном случайным. (Это была одна из причин, чтобы переключиться на ступенчатые графики от d3, поскольку библиотека d3 интерактивна и позволяет скрывать часть кадров: например, все кадры Java, все кадры из пользовательского режима, т.д.). Такой подход позволил высветить различные группы, например, упомянутую выше.
3. Изучение ступенчатого графика
os: javaTimeMillis выбирает текущее время. Обзор ступенчатого графика показывает, что системный вызов gettimeofday (2) выполняется при входе в функции ядра tracesys () и syscall_trace_enter/exit (). Вырисовывается две теории, позволяющие это объяснить: А) В Ubuntu включена некая трассировка системных вызовов (аудит? apparmor?). B) В Ubuntu выбор времени идет немного медленнее, это может быть связано с изменениями в библиотеке или ядре/источнике тактов.
Теория (A), вероятнее всего, основана на ширине кадров в ступенчатом графике. Но не вполне убедительна. Этот профиль в Xen — гостевой, поэтому информация собиралась при помощи perf (1) и мягких прерываний программы cpu-clock из ядра, а не на уровне аппаратного немаскируемого прерывания (NMI). Без NMI (с отключенными прерываниями) некоторые пути кода в ядре не поддаются профилированию. Кроме того, по причине гостевого статуса в Xen, время гипервизора вообще не профилируется. В силу двух этих факторов ступенчатый график может не учитывать время, потраченное в ядре и гипервизоре, поэтому истинные потери времени в os: javaTimeMillis могут быть немного иными.
Обратите внимание: в Ubuntu также есть кадр, в котором показывается вход в vDSO (виртуальный динамический разделяемый объект). Это ускоритель системных вызовов, относящийся к пользовательскому режиму, а gettimeofday (2) — классический вариант его использования, даже процитированный на странице справки man, посвященной vdso (7). Было время, когда источник pvclock в Xen не поддерживал vDSO, поэтому код системного вызова просматривался над кадром vdso. Такая же ситуация складывается и в CentOS, хотя, там кадр vdso не включается в ступенчатый график (предположительно, только из-за разницы в perf (1)).
4. Коллеги/Интернет
Инструменты для анализа производительности в Linux хороши. Но иногда проблемы нужно решать быстро, поэтому целесообразнее просто обратиться к коллегам или поискать в Интернете. Нужно об этом сказать, просто в качестве напоминания для всех, кто привык самостоятельно выполнять анализ такого рода.
5. Эксперименты
Для дальнейшего анализа ситуации при помощи наблюдательных инструментов, можно было:
A. Зафиксировать стеки Java, чтобы посмотреть, есть ли разница в использовании времени на Ubuntu. Может быть, Java по какой-то причине выполняет вызовы чаще.
B. Отслеживать путь gettimeofday () и других подобных ему системных вызовов, чтобы посмотреть, есть ли какая-либо разница там. Например, ошибки.
Но, как резюмировано в посте What is Observability, сам феномен «наблюдаемости» — это напоминание не увлекаться единственным типом анализа. Вот еще некоторые экспериментальные подходы, которые стоит изучить:
C. Отключить tracesys/syscall_trace.
D. Провести микробенчмаркинг os: javaTimeMillis () в обеих системах.
E. Попытаться изменить источник тактов для ядра.
Поскольку © выглядит как пересборка ядра, лучше начать с (D) и (E).
6. Измеряем скорость времени
Есть ли уже микробенчмаркинг для os: javaTimeMillis ()? В таком случае можно было бы убедиться, что на Ubuntu эти вызовы действительно притормаживают.
Автору такой микробенчмарк найти не удалось, поэтому он сам написал довольно простой код. Не пытаясь делать вызовы «до» и «после», чтобы измерить длительность времени (хотя, такой подход должен сработать, если учесть при анализе те излишки времени, которые тратятся на сами замеряющие вызовы), автор решил просто сделать цикл, в котором миллионы раз вызывается показатель времени и проверить, сколько времени на это уходит (сорри, тавтология тут неизбежна):
$ cat TimeBench.java
public class TimeBench {
public static void main(String[] args) {
for (int i = 0; i < 100 * 1000 * 1000; i++) {
long t0 = System.currentTimeMillis();
if (t0 == 87362) {
System.out.println("Bingo");
}
}
}
}
Этот код 100 миллионов раз вызывает currentTimeMillis (). Затем этот код выполняется при помощи оболочечной команды time (1), позволяющей определить общее время выполнения всех этих 100 миллионов вызовов. В цикле также есть тест и println (). Остается надеяться, что компилятор не выкинет при оптимизации этот цикл, ведь в остальном он пуст. Поэтому тест немного замедляется.
Попробуем:
centos$ time java TimeBench
real 0m12.989s
user 0m3.368s
sys 0m18.561s
ubuntu# time java TimeBench
real 1m8.300s
user 0m38.337s
sys 0m29.875s
Сколько длится каждый вызов времени? Предполагая, что именно на вызовы времени уходит львиная доля цикла, имеем около 0,13 μs на Centos и 0,68 μs на Ubuntu. Ubuntu работает впятеро медленнее. Поскольку нас интересует относительное сравнение, можно просто сравнить общие значения времени исполнения («реальное» время) и получить такой же результат.
Вот тот же самый код на C, в нем gettimeofday (2) вызывается напрямую:
$ cat gettimeofdaybench.c
#include
int
main(int argc, char *argv[])
{
int i, ret;
struct timeval tv;
struct timezone tz;
for (i = 0; i < 100 * 1000 * 1000; i++) {
ret = gettimeofday(&tv, &tz);
}
return (0);
} Компилируем это с -O0, чтобы цикл не отбрасывался. При прогоне этого кода на двух системах результаты получаются схожими.
Такие короткие бенчмарки хороши тем, что результирующий двоичный код можно дизассемблировать и убедиться, что скомпилированные инструкции именно такие, какими мы ожидаем их увидеть, и компилятор с ними не запутался.
7. Эксперименты с clocksource
Второй эксперимент заключается в изменении источника кадров (clocksource). На выбор есть такие:
$ cat /sys/devices/system/clocksource/clocksource0/available_clocksource
xen tsc hpet acpi_pm
$ cat /sys/devices/system/clocksource/clocksource0/current_clocksource
xenОкей, по умолчанию выбирается xen, который мы уже видели в ступенчатом графике (башня заканчивается pvclock_clocksource_read ()). Давайте попробуем tsc, этот вариант должен быть быстрее всех:
# echo tsc > /sys/devices/system/clocksource/clocksource0/current_clocksource
$ cat /sys/devices/system/clocksource/clocksource0/current_clocksource
tsc
$ time java TimeBench
real 0m3.370s
user 0m3.353s
sys 0m0.026sИзменения наступают немедленно, и теперь микробенчмарк на Java бегает в 20 с лишним раз быстрее, чем раньше! (Причем, почти вчетверо быстрее, чем на CentOS.) Теперь он достигает 33 ns, по-видимому, этот результат даже раздут из-за инструкций цикла. При желании большей точности можно было бы частично свернуть цикл, так, чтобы инструкции цикла стали пренебрежимы.
8. Обходной маневр
Счетчик временных меток (TSC) в качестве источника тактов быстр, так как извлекает время при помощи одной лишь инструкции RDTSC, тогда как при использовании vDSO здесь не обойтись без системного вызова. Традиционно TSC не выставляется из-за опасений, связанных с разбежкой времени. Эти проблемы можно было бы исправить при помощи программных источников тактов и обеспечить точное, монотонно текущее время.
Как раз в период отладки этой проблемы автору довелось выступать на технической конференции, и там он поделился этой проблемой с инженером по процессорам. Тот сказал, что tsc стабилен долгие годы, и совет избегать этого источника уже устарел. Правда, никакой ссылки на это из открытых источников он привести не смог.
Благодаря этой случайной встрече, а также тому, насколько отказоустойчиво облако Netflix, с которым работал автор, мы вслед за ним рекомендуем попробовать tsc в продакшене в качестве обходного маневра при решении описываемой проблемы.
Изменения в продакшен-графиках очевидны; заметно, насколько упала задержка при записи:

При более обширном тестировании выясняется, что задержка при записи падает на 43%, поэтому достигается производительность чуть выше, чем на CentOS.
Ступенчатый график ЦП на Ubuntu приобретает следующий вид:

os: javaTimeMillis () теперь составляет всего 1,6%. Обратите внимание: теперь она входит в »[[vdso]]» — и все: никаких вызовов ядра поверх нее.
9. Что было после
Автор сообщил подробности в AWS и Canonical, а потом переключился на решение других проблем с производительностью в рамках миграции. Майк Хуан, коллега автора, также столкнулся с описанной проблемой при работе над другой службой Netflix и включил tsc. В итоге этот вариант был выбран в BaseAMI во всех облачных сервисах.
По состоянию на 2022 год эта проблема с источником тактов на виртуальных машинах широко известна. В 2021 году в Amazon даже выпустили официальную рекомендацию:
«Для инстансов EC2, запущенных на гипервизоре AWS Xen, лучше всего использовать tsc в качестве источника тактов. На инстансах EC2 других типов, например, C5 или M5, используйте в качестве гипервизора AWS Nitro. Рекомендуемый источник тактов для гипервизора AWS Nitro — kvm-clock.»
Соответственно, дела изменились в Nitro, где источники тактов гораздо быстрее (и это здорово!). В 2019 году автору с коллегами довелось тестировать kvm-clock и убедиться, что он всего на 20% уступает в скорости tsc. Уже гораздо лучше, чем источник тактов xen, но автор по-прежнему сохраняет верность tsc за неимением причин с него уходить (например, чтобы снова не возникли разбежки по времени с часами tsc).
Комплект для бенчмаркинга JMH также позволяет тестировать System.currentTimeMillis (), поэтому уже нет необходимости выкатывать собственный вариант (если, конечно, не собираетесь его дизассемблировать, но на такой случай лучше взять что-нибудь короткое и простое).
Что касается tracesys: автор изучил издержки, затрачиваемые на другие системные вызовы и счел их пренебрежимыми, а когда вернулся к работе над этими вызовами, пути кода в ядре уже изменились. В чем было дело — возникла ли ошибка конфигурации в новом релизе Ubuntu, либо эти изменения возникли при аудите и позже были исправлены? Автору хотелось докопаться до сути этих проблем, а они взяли и исчезли. Как бы то ни было, он все равно рекомендует использовать в качестве источника тактов tsc, а не вариант xen, так как в таком случае производительность вчетверо выше.
10. Заключение
При работе с некоторыми источниками тактов сама процедура измерения времени может стать узким местом. Много лет назад, на гостевых профилях в виртуальных машинах Xen ситуация была гораздо хуже. В Linux tsc многие годы остается самым быстрым источником тактов, но только вендор процессоров может уверенно судить о том, возникают ли в tsc какие-либо проблемы с разбежкой часов. По крайней мере, официальная рекомендация AWS по-прежнему актуальна.
Кроме того, даже при наличии сверхмощных трассировочных инструментов, иногда лучше просто сесть и разобраться с системой вручную. Как в этом случае — расставить пару импровизированных бенчмарков, каждый длиной всего несколько строк кода. Всякий раз при исследовании производительности некого небольшого дискретного системного компонента, старайтесь найти и выкатить собственный ситуативный бенчмарк и добывать нужную информацию собственными изысканиями. Наблюдение и эксперимент всегда идут рука об руку.

