[Перевод] Самая простая в мире lock-free хеш-таблица

Безблокировочная хеш-таблица — это медаль о двух сторонах. В некоторых случаях они позволяют достигать такой производительности, которой не получить другими способами. С другой стороны, они довольно сложны.
Первая работающая безблокировочная таблица, о которой я услышал, была написана на Java доктором Клиффом Кликом. Его код увидел свет еще в 2007, в том же году автор выступил с презентацией в Google. Признаюсь, когда я впервые смотрел эту презентацию, большую часть ее я не понял. Главное, что я уяснил — это то, что доктор Клифф Клик, должно быть, какой-то чародей.

К счастью, шести лет мне хватило, чтобы (почти) догнать Клиффа в этом вопросе. Как оказалось, не нужно быть волшебником, чтобы понять и реализовать простейшую, но в то же время идеально работающую безблокировочную хеш-таблицу. Здесь я поделюсь исходным кодом одной из них. Уверен, что любой, у кого есть опыт многопоточной разработки на С++ и кто готов внимательно изучить предыдущие посты этого блога, без проблем в ней разберется.
Хеш-таблица написана с использованием Mintomic — переносимой библиотеки для разработки без блокировок на C/C++, которую я зарелизил в прошлом месяце. Она собирается и запускается из коробки на нескольких x86/64, PowerPC и ARM платформах. И так как каждая функция Mintomic имеет эквивалент в C++11, перевести эту таблицу на C++11 — тривиальная задача.
Ограничения
Нам, программистам, присущ инстинкт писать структуры данных сразу максимально универсальными, так, чтобы их было удобно переиспользовать. Это не плохо, но может сослужить нам дурную службу, если с самого начала превратить это в цель. Для данного поста я ударился в другую крайность, создав настолько ограниченную и узко специализированную безблокировочную хеш-таблицу, насколько смог. Вот ее ограничения:
- Хранит только 32-битные целые ключи и 32-битные целые значения.
- Все ключи должны быть ненулевыми.
- Все значения должны быть ненулевыми.
- У таблицы есть фиксированное максимальное количество записей, которое она может хранить, и это число должно быть степенью двойки.
- Есть только две операции: SetItem и GetItem.
- Нет операции удаления.
Будьте уверены, когда вы освоите ограниченную версию этой хеш-таблицы, станет возможно последовательно убрать все ограничения, не меняя подхода кардинально.
Подход
Существует множество способов реализации хеш-таблиц. Подход, который я выбрал, — всего лишь простая модификация класса
ArrayOfItems, описанного в моем предыдущем посте, A Lock-Free… Linear Search? Настоятельно рекомендую ознакомиться с ним, прежде чем продолжать.Аналогично ArrayOfItems, этот класс хеш-таблицы, который я назвал HashTable1, реализован с помощью простого гигантского массива пар ключ/значение.
struct Entry
{
mint_atomic32_t key;
mint_atomic32_t value;
};
Entry *m_entries;В
HashTable1 нет связных списков для разрешения хеш-коллизий вне таблицы; есть только сам массив. Нулевой ключ в массиве обозначает пустую запись, и сам массив проинициализирован нулями. И в точности как в ArrayOfItems, значения добавляются и располагаются в HashTable1 с помощью линейного поиска.Единственное отличие ArrayOfItems и HashTable1 в том, что ArrayOfItems всегда начинает линейный поиск с нулевого индекса, в то время как HashTable1 начинает каждый линейный поиск с индекса, вычисляемого как хеш от ключа. В качестве хеш-функции я выбрал MurmurHash3«s integer finalizer, так как она достаточно быстра и хорошо кодирует целочисленные данные.
inline static uint32_t integerHash(uint32_t h)
{
h ^= h >> 16;
h *= 0x85ebca6b;
h ^= h >> 13;
h *= 0xc2b2ae35;
h ^= h >> 16;
return h;
}В результате каждый раз, когды мы вызываем
SetItem или GetItem с одним и тем же ключом, линейный поиск будет начинаться с одного и того же индекса, но когда мы будем передавать разные ключи, поиск в большинстве случаем будет начинаться с абсолютно разных индексов. Таким образом, значения гораздо лучше распределены по массиву, чем в ArrayOfItems, и вызывать SetItem и GetItem из нескольких параллельных потоков становится безопасно.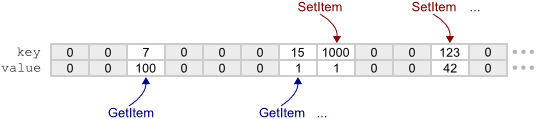
HashTable1 использует круговой поиск, что означает, что когда SetItem или GetItem достигает конца массива, она просто возвращается к нулевому индексу и продолжает поиск. Так как массив никогда не будет заполнен, каждый поиск гарантированно завершится либо обнаружением искомого ключа, либо обнаружением записи с ключом 0, что означает, что искомого ключа не существует в хеш-таблице. Такой прием называется открытой адресацией с линейным пробированием, и по-моему, это самая lock-free-friendly хеш-таблица из существующих. На самом деле доктор Клик использует этот же прием в его безблокировочной хюш-таблице на Java.
Код
Вот функция, реализующая
SetItem. Она проходит через массив и сохраняет значение в первой записи, ключ которой равен 0 или совпадает с желаемым ключом. Ее код почти идентичен коду ArrayOfItems::SetItem, описанному в предыдущем посте. Отличия — только целочисленный хеш и побитовое «и», примененное к idx, что не позволяет ему выйти за границы массива.void HashTable1::SetItem(uint32_t key, uint32_t value)
{
for (uint32_t idx = integerHash(key);; idx++)
{
idx &= m_arraySize - 1;
uint32_t prevKey = mint_compare_exchange_strong_32_relaxed(&m_entries[idx].key, 0, key);
if ((prevKey == 0) || (prevKey == key))
{
mint_store_32_relaxed(&m_entries[idx].value, value);
return;
}
}
}Код
GetItem также почти совпадает с ArrayOfItems::GetItem за исключением небольших модификаций.uint32_t HashTable1::GetItem(uint32_t key)
{
for (uint32_t idx = integerHash(key);; idx++)
{
idx &= m_arraySize - 1;
uint32_t probedKey = mint_load_32_relaxed(&m_entries[idx].key);
if (probedKey == key)
return mint_load_32_relaxed(&m_entries[idx].value);
if (probedKey == 0)
return 0;
}
}Обе вышеописанные функции потокобезопасны и без блокировок по тем же причинам, что и их аналоги в
ArrayOfItems: все операции с элементами массива выполняются с помощью функций атомарной библиотеки, значения ставятся в соответствие ключам с помощью compare-and-swap (CAS) над ключами, и весь код устойчив против переупорядочения памяти (memory reordering). И снова, для более полного понимания советую обратиться к предыдущему посту.И наконец, совсем как в предыдущей статье, оптимизируем SetItem, сначала проверяя, действительно ли CAS необходим, и если нет — не применяя его. Благодаря этой оптимизации, пример приложения, который вы найдете ниже, работает почти на 20% быстрее.
void HashTable1::SetItem(uint32_t key, uint32_t value)
{
for (uint32_t idx = integerHash(key);; idx++)
{
idx &= m_arraySize - 1;
// Load the key that was there.
uint32_t probedKey = mint_load_32_relaxed(&m_entries[idx].key);
if (probedKey != key)
{
// The entry was either free, or contains another key.
if (probedKey != 0)
continue; // Usually, it contains another key. Keep probing.
// The entry was free. Now let's try to take it using a CAS.
uint32_t prevKey = mint_compare_exchange_strong_32_relaxed(&m_entries[idx].key, 0, key);
if ((prevKey != 0) && (prevKey != key))
continue; // Another thread just stole it from underneath us.
// Either we just added the key, or another thread did.
}
// Store the value in this array entry.
mint_store_32_relaxed(&m_entries[idx].value, value);
return;
}
}Все готово! Теперь у вас есть самая простая безблокировочная хеш-таблица в мире. Вот ссылки на исходный код и заголовочный файл.
Короткое предупреждение: как и в ArrayOfItems, все операции с HashTable1 производятся со слабыми (relaxed) ограничениями упорядочения памяти. Поэтому, если вы захотите сделать какие-либо данные доступными для других потоков, записав флаг в HashTable1, необходимо, чтобы эта запись обладала «семантикой освобождения» (release semantics), что можно гарантировать, поставив release fence («барьер освобождения») непосредственно перед инструкцией. Аналогично, обращение к GetItem в том потоке, который хочет получить данные, необходимо снабдить acquire fence («барьером приобретения»).
// Shared variables
char message[256];
HashTable1 collection;
void PublishMessage()
{
// Write to shared memory non-atomically.
strcpy(message, "I pity the fool!");
// Release fence: The only way to safely pass non-atomic data between threads using Mintomic.
mint_thread_fence_release();
// Set a flag to indicate to other threads that the message is ready.
collection.SetItem(SHARED_FLAG_KEY, 1)
}Пример приложения
Чтобы оценить
HashTable1 в работе, я создал еще одно простейшее приложение, очень похожее на пример из предыдущего поста. Оно каждый раз выбирает из двух экспериментов: - Каждый из двух потоков добавляет 6000 значений с уникальными ключами,
- Каждый поток добавляет 12000 различных значений с одинаковыми ключами.
Код лежит на GitHub, так что вы можете собрать его и запустить самостоятельно. Инструкции по сборке вы найдете в README.md.

Так как хеш-таблица никогда не переполнится — допустим, будет использовано меньше 80% массива — HashTable1 будет показывать замечательную производительность. Пожалуй, мне следовало бы подтвердить это измерениями, но исходя из предыдущего опыта измерений производительности однопоточных хеш-таблиц, могу поспорить, у вас не получится создать более быструю безблокировочную хеш-таблицу, чем HashTable1. Может показаться удивительным, но ArrayOfItems, который лежит в ее основе, показывает ужасную производительность. Конечно, как и с любой хеш-таблицей, существует ненулевой риск захешировать большое количество ключей в один индекс массива, и тогда производительность сравняется со скоростью ArrayOfItems. Но с достаточно большой таблицей и хорошей хеш-функцией, такой как MurmurHash3, вероятность такого сценария ничтожно мала.
Я использовал безблокировочные таблицы, похожие на эту, в реальных проектах. В одном случае в игре, над которой я работал, суровая конкуренция потоков за разделяемую блокировку создавала узкое место каждый раз, когда включался мониторинг использования памяти. После перехода на безблокировочные хеш-таблицы частота кадров в самом неблагоприятном случае улучшилась с 4 FPS до 10 FPS.
