[Перевод] Rust в деталях: пишем масштабируемый чат с нуля, часть 1
Часть 1: Реализуем WebSocket. Введение.
В этом цикле статей мы рассмотрим процесс создания масштабируемого чата, который будет работать в реальном времени.
Целью данного обзора является пошаговое изучение основ быстро набирающего популярность языка программирования Rust на практике, с попутным охватом системных интерфейсов.
В первой части мы рассмотрим начальную настройку окружения и реализацию простейшего WebSocket-сервера. Чтобы понять технические детали статьи вам не потребуется опыта работы с языком Rust, хотя знание основ системных API (POSIX) и C/C++ лишним не будет. Прежде чем начинать чтение, заготовьте немного времени (и кофе) — статья описывает все максимально подробно и поэтому довольно длинная.
1 Rust — причина выбора
Я заинтересовался языком программирования Rust из-за давнего увлечения системным программированием, которое дело хоть и занимательное, но и весьма сложное — все потому что и новичков, и опытных разработчиков поджидает большое количество совершенно неочевидных моментов и каверзных проблем.
 И, пожалуй, наиболее сложной проблемой тут можно назвать безопасную работу с памятью. Именно некорректная работа с памятью является причиной множества багов: переполнения буфера, утечки памяти, двойных освобождений памяти, висячих ссылок, разыменований указателей на уже освобожденную память, и т.п. И подобные ошибки порой влекут за собой серьезные проблемы в безопасности — например, причиной не так давно нашумевшего бага в OpenSSL, Heartbleed, является ни что иное как небрежное обращение с памятью. И это только верхушка айсберга — никому неизвестно, сколько подобных брешей таится в программном обеспечении которым мы пользуемся ежедневно.
И, пожалуй, наиболее сложной проблемой тут можно назвать безопасную работу с памятью. Именно некорректная работа с памятью является причиной множества багов: переполнения буфера, утечки памяти, двойных освобождений памяти, висячих ссылок, разыменований указателей на уже освобожденную память, и т.п. И подобные ошибки порой влекут за собой серьезные проблемы в безопасности — например, причиной не так давно нашумевшего бага в OpenSSL, Heartbleed, является ни что иное как небрежное обращение с памятью. И это только верхушка айсберга — никому неизвестно, сколько подобных брешей таится в программном обеспечении которым мы пользуемся ежедневно.
В C++ было придумано несколько путей решения подобных проблем — например, использование умных указателей[1] или аллокации на стэке[2]. К сожалению, даже применяя подобные подходы все равно есть вероятность, что называется, “прострелить себе ногу” — выйти за границы буфера либо использовать низкоуровневые функции для работы с памятью, которые всегда остаются доступными.
То есть, на уровне языка нет обязательного условия применять подобные практики — вместо этого считается, что “хорошие разработчики” их всегда используют сами и никогда не делают ошибок. Однако я же считаю, что наличие подобных критических проблем в коде никак не связано с уровнем разработчиков, потому что люди не могут досконально проверять вручную большие объемы кода — это задача компьютера. В какой-то степени здесь помогают инструменты статического анализа — но, опять же, их используют далеко не все и не всегда.
Именно по этой причине и существует другой фундаментальный метод избавления от проблем в работе с памятью: сборка мусора — отдельная сложная область знаний в информатике. Почти все современные языки и виртуальные машины имеют ту или иную форму автоматической сборки мусора, и несмотря на то, что в большинстве случаев это достаточно неплохое решение, у него есть свои недостатки: во-первых, автоматические сборщики мусора сложны в понимании и реализации[3]. Во-вторых, использование сборки мусора подразумевает наличие паузы для высвобождения неиспользуемой памяти[4], что как правило влечет за собой необходимость тонкой настройки для сокращения времени ожидания в высоконагруженных приложениях.
У языка Rust другой подход к проблеме — можно сказать, золотая середина — автоматическое освобождение памяти и ресурсов без дополнительного потребления памяти или процессорного времени и без необходимости самостоятельного отслеживания каждого шага. Достигается это за счет применения концепций владения и заимствования.
В основе языка лежит утверждение, что у каждого значения может быть исключительно один владелец — то есть, может существовать только одна изменяемая переменная указывающая на определенную область памяти:
let foo = vec![1, 2, 3];
// Мы создаем новый вектор (массив), содержащий элеметы 1, 2, и 3,
// и привязываем его к локальной переменной `foo`.
let bar = foo;
// Передаем владение объектом переменной `bar`.
// После этого мы не можем получить доступ к переменной `foo`,
// поскольку она теперь ничем не "владеет" - т.е., не имеет никакой привязки.
У такого подхода есть интересные последствия: поскольку значение связано исключительно с одной переменной, ресурсы связанные с этим значением (память, файловые дескрипторы, сокеты, и т.п.) автоматически освобождаются при выходе переменной из области видимости (которая задается блоками кода внутри фигурных скобок, { и }).
Такие искусственные ограничения могут выглядеть ненужными и излишне переусложненными, но если хорошо подумать, то, по большому счету, это и есть “киллер-фича” Rust, которая появилась исключительно из практических соображений. Именно такой подход позволяет Rust выглядеть языком высокого уровня при сохранении эффективности низкоуровневого кода, написанного на C/C++.
Однако, несмотря на все свои интересные возможности, до недавнего времени у Rust’а были свои серьезные недостатки — например, очень нестабильный API, в котором никто не мог гарантировать сохранение совместимости. Но создатели языка прошли долгий путь почти в десятилетие[5], и теперь, с выходом стабильной версии 1.0, язык развился до того состояния, когда его можно начинать применять на практике в реальных проектах.
2 Цели
Я предпочитаю изучать новые языки и концепции разрабатывая относительно простые проекты с применением в реальном мире. Таким образом, возможности языка изучаются именно тогда, когда они становятся нужными. В качестве проекта для изучения Rust’а я выбрал сервис анонимных чатов наподобие Chat Roulette и многих других. На мой взгляд, это подходящий выбор по той причине, что чаты, как правило, требовательны к низкому времени отклика от сервера и подразумевают наличие большого количества одновременных подключений. Мы будем рассчитывать на несколько тысяч — так мы сможем посмотреть на потребление памяти и производительность программ написанных на Rust’е в реальном окружении.
Конечным результатом должен стать бинарный файл программы со скриптами для развертывания нашего сервера на различных облачных хостингах.
Но прежде чем мы начнем писать код, нужно сделать небольшое отступление для пояснения некоторых моментов с вводом-выводом, так как правильная работа с ним — ключевой момент при разработке сетевых сервисов.
3 Варианты работы с вводом-выводом
Для выполнения поставленных задач нашему сервису необходимо отправлять и получать данные через сетевые сокеты.
На первый взгляд, задача простая, но на самом деле существует множество возможных способов ее решения различной сложности и различной эффективности. Основное различие между ними кроется в подходе к блокировкам: стандартной практикой тут является прекращение работы процессора во время ожидания поступления новых данных в сокет.
Так как мы не можем строить сервис для одного пользователя, который будет блокировать остальных, мы должны их как-то друг от друга изолировать. Типичное решение — создавать по отдельному потоку выполнения на каждого пользователя. Таким образом, блокироваться будет не весь процесс целиком, а лишь один из его потоков. Недостатком данного подхода, несмотря на его относительную простоту, является повышенное потребление памяти — каждый поток при его создании резервирует некоторую часть памяти для стека[6]. Помимо того, дело усложняется необходимостью в переключении контекста выполнения — в современных серверных процессорах обычно есть от 8 до 16 ядер, и если мы создаем больше потоков, чем позволяет “железо”, то планировщик ОС перестает справляться с переключением задач с достаточной скоростью.
Поэтому смасштабировать многопоточную программу до большого количества подключений может быть довольно сложно, и в нашем случае это вообще вряд ли разумно — ведь мы планируем несколько тысяч одновременно подключенных пользователей. В конце концов, надо быть готовыми к Хабраэффекту!
4 Цикл обработки событий
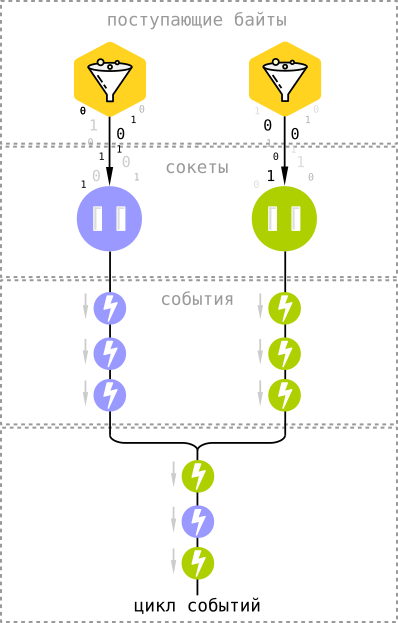 Для эффективной работы с вводом-выводом мы будем использовать мультиплексирующие системные API, в основе которых лежит цикл обработки событий. В ядре Linux для этого есть механизм epoll[7], а во FreeBSD и OS X — kqueue[8].
Для эффективной работы с вводом-выводом мы будем использовать мультиплексирующие системные API, в основе которых лежит цикл обработки событий. В ядре Linux для этого есть механизм epoll[7], а во FreeBSD и OS X — kqueue[8].
Оба этих API устроены довольно похожим образом, и общая идея проста: мы, вместо того чтобы ждать, когда в сокеты через сеть поступят новые данные, просим сокеты оповещать нас о пришедших байтах.
Оповещения в форме событий поступают в общий цикл, который в данном случае и выступает блокировщиком. То есть, вместо того, чтобы постоянно проверять тысячи сокетов на наличие в них новых данных, мы просто ждем, когда сокеты сами нам об этом сообщат — и разница довольно существенна, поскольку довольно часто подключенные пользователи находятся в режиме ожидания, ничего не отправляя и не получая. Особенно это характерно для приложений, использующих WebSocket. К тому же, используя асинхронный ввод-вывод мы практически не имеем накладных расходов — все, что требуется хранить в памяти — это файловый дескриптор сокета и состояние клиента (в случае чата это несколько сотен байт на одно подключение).
Любопытной особенностью такого подхода является возможность использовать асинхронный ввод-вывод не только для сетевых подключений, но и, например, для чтения файлов с диска — цикл обработки событий принимает любые типы файловых дескрипторов (а сокеты в мире *NIX именно ими и являются).
Цикл событий в Node.js и гем EventMachine в Ruby работают точно таким же образом.
То же самое верно и в случае веб-сервера nginx, в котором используется исключительно асинхронный I/O[9].
5 Начинаем проект
Дальнейший текст подразумевает, что у вас уже установлен Rust. Если еще нет — то следуйте документации на официальном сайте.
В стандартной поставке Rust’а имеется программа под названием cargo, которая выполняет функции схожие с Maven, Composer, npm, или rake — она управляет зависимостями нашего приложения, занимается сборкой проекта, запускает тесты, и главное — упрощает процесс создания нового проекта.
Именно это нам и нужно в данный момент, так что давайте попробуем открыть терминал и набрать такую команду:
cargo new chat --bin
Аргумент --bin указывает Cargo, что надо создавать запускаемое приложение, а не библиотеку.
В результате у нас появятся два файла:
Cargo.toml
src/main.rs
Cargo.toml содержит описание и ссылки на зависимости проекта (схоже с package.json в JavaScript).src/main.rs — главный исходный файл и точка входа в нашу программу.
Больше ничего для начала нам не потребуется, так что можно попробовать скомпилировать и запустить программу одной командой — cargo run. Эта же команда выводит ошибки в коде при их наличии.
Если вы счастливый пользователь Emacs, то будете рады узнать, что он совместим с Cargo «из коробки» — достаточно установить пакет
rust-modeиз репозитория MELPA и сконфигурировать команду compile на запускcargo build.
6 Обработка событий в Rust
Перейдем от теории к практике. Давайте попробуем запустить простейший цикл событий, который будет ожидать появления новых сообщений. Для этого нам не нужно вручную подключать различные системные API — достаточно воспользоваться уже существующей библиотекой для работы с асинхронным I/O под названием “Metal IO” или mio.
Как вы помните, зависимостями занимается программа Cargo. Она загружает библиотеки из репозитория crates.io, но помимо того позволяет получать их и из Git-репозиториев напрямую — такая возможность бывает полезна в тех случаях, когда нам нужно использовать последнюю версию библиотеки, которая еще не была загружена в репозиторий пакетов.
На момент написания статьи у mio в репозитории доступна только уже устаревшая версия 0.3 — в находящейся в разработке версии 0.4 появилось много полезных изменений, к тому же, несовместимых со старыми версиями. Поэтому подключим ее напрямую через GitHub, добавив такие строки в Cargo.toml:
[dependencies.mio]
git = "https://github.com/carllerche/mio"
После того, как мы определили зависимость в описании проекта, добавим импорт в main.rs:
extern crate mio;
use mio::*;
Использовать mio достаточно просто. В первую очередь, давайте создадим цикл событий, вызвав функцию EventLoop::new(). От пустого цикла, впрочем, пользы никакой, поэтому давайте сразу добавим в него обработку событий для нашего чата, определив структуру с функциями, которая будет соответствовать интерфейсу Handler.
Хотя в языке Rust нет поддержки “традиционного” объектно-ориентированного программирования, структуры во многом аналогичны классам, и они похожим на классический ООП образом могут имплементировать интерфейсы, которые регламентируются в языке через типажи.
Давайте определим новую структуру:
struct WebSocketServer;
И реализуем типаж Handler для нее:
impl Handler for WebSocketServer {
// У типажей может существовать стандартная реализация для их функций, поэтому
// интерфейс Handler подразумевает описание только двух свойств: указания
// конкретных типов для таймаутов и сообщений.
// В ближайшее время мы не будем описывать все эти детали, поэтому давайте просто
// скопируем типовые значения из примеров mio:
type Timeout = usize;
type Message = ();
}
Теперь запустим цикл событий:
fn main() {
let mut event_loop = EventLoop::new().unwrap();
// Создадим новый экземпляр структуры Handler:
let mut handler = WebSocketServer;
// ... и предоставим циклу событий изменяемую ссылку на него:
event_loop.run(&mut handler).unwrap();
}
Здесь нам впервые встречается применение заимствований (borrows): обратите внимание на &mut на последней строчке. Это обозначает, что мы временно передаем “право владения” значением, связывая его с другой переменной с возможностью изменения (mutation) данных.
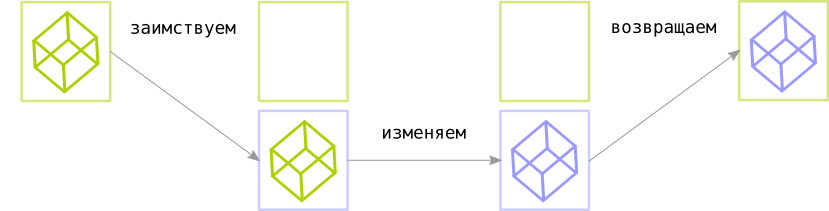
Проще говоря, можно представить себе принцип работы заимствований следующим образом (псевдокод):
// Связываем значение с его "владельцем" - переменной owner:
let mut owner = value;
// Создаем новую область видимости и заимствуем значение у его владельца:
{
let mut borrow = owner;
// Теперь у владельца нет доступа к его значению.
// Но заимствующая переменная может его читать и изменять:
borrow.mutate();
// Теперь мы можем вернуть измененное значение владельцу:
owner = borrow;
}
Вышеприведенный код эквивалентен этому:
// Связываем значение с его "владельцем" - переменной owner:
let owner = value;
{
// Заимствуем значение у его владельца:
let mut borrow = &mut owner;
// Теперь владелец может читать значение, но не может изменять его.
// А вот заимствующая переменная имеет полный доступ:
borrow.mutate();
// Все значения автоматически возвращаются их владельцам при выходе
// заимствующих переменных из области видимости.
}
На каждую область видимости у переменной может быть только одно изменяемое заимствование (mutable borrow), и даже владелец значения не может его читать или изменять до тех пор, пока заимствование не выйдет из области видимости.
Помимо того существует более простой способ заимствовать значения через неизменяемые заимствования (immutable borrow), которые позволяют использовать значение только для чтения. И, в отличие от &mut, изменяемого заимствования, оно не устанавливает никаких лимитов на чтение, только на запись — до тех пор, пока в области видимости есть неизменяемые заимствования, значение не может меняться и перезаимствоваться через &mut.
Ничего страшного, если такое описание показалось вам недостаточно понятным — рано или поздно наступит интуитивное понимание, поскольку заимствования в Rust используются повсеместно, и по ходу чтения статьи вы найдете больше практических примеров.
Теперь давайте вернемся к нашему проекту. Запускайте команду “cargo run” и Cargo скачает все необходимые зависимости, скомпилирует программу (с некоторыми предупреждениями, которые мы можем пока проигнорировать), и запустит ее.
В итоге мы увидим окно терминала с мигающим курсором. Не очень интересный результат, но он, по крайней мере, показывает, что программа выполняется корректно — мы успешно запустили цикл событий, хоть он пока ничего полезного и не делает. Давайте это положение дел исправим.
Чтобы прервать выполнение программы, воспользуйтесь комбинацией клавиш Ctrl+C.
7 TCP-сервер
Для запуска TCP-сервера, который будет принимать соединения через протокол WebSocket, мы воспользуемся предназначенной для этого структурой (struct) — TcpSocket из пакета mio::tcp. Процесс создания серверного TCP-сокета достаточно прямолинеен — мы привязываемся к определенному адресу (IP + номер порта), слушаем сокет и принимаем соединения. Мы не будем от него сильно отходить.
Взлянем на код:
use mio::tcp::*;
use std::net::SocketAddr;
...
let server_socket = TcpSocket::v4().unwrap();
let address = "0.0.0.0:10000".parse::<SocketAddr>().unwrap();
server_socket.bind(&address).unwrap();
let server_socket = server_socket.listen(128).unwrap();
event_loop.register_opt(&server_socket,
Token(0),
EventSet::readable(),
PollOpt::edge()).unwrap();
Давайте рассмотрим его построчно.
В первую очередь мы должны импортировать в область видимости нашего модуля main.rs пакет для работы с TCP и структуру SocketAddr, описывающую адрес сокета — добавим такие строки в начало файла:
use mio::tcp::*;
use std::net::SocketAddr;
Создадим потоковый сокет IPv4 (то есть, TCP):
let server_socket = TcpSocket::v4().unwrap();
Распарсим строку "0.0.0.0:10000" в структуру, описывающую адрес и привяжем к этому адресу сокет:
let address = "0.0.0.0:10000".parse::<SocketAddr>().unwrap();
server_socket.bind(&address).unwrap();
Обратите внимание, как компилятор выводит необходимый тип структуры за нас: поскольку server_socket.bind ожидает аргумент типа SockAddr, нам не нужно указывать его явно и засорять код — компилятор Rust способен самостоятельно его определить.
Запускаем прослушивание сокета:
server_socket.listen(128).unwrap();
Вызов функции listen принимает единственный аргумент: размер очереди ожидающих соединения сокетов (backlog)[10]. И в Линуксе, и во FreeBSD по умолчанию установлен максимум в 128 ожидающих соединений, поэтому мы просто используем это стандартное значение.
Вы также могли заметить, что мы почти везде вызываем unwrap для результата выполнения функции — это паттерн обработки ошибок в Rust, и мы скоро вернемся к этой теме.
Теперь давайте добавим созданный сокет в цикл событий:
event_loop.register(&server_socket,
Token(0),
EventSet::readable(),
PollOpt::edge()).unwrap();
Вызов register посложнее — функция принимает следующие аргументы:
- Token — уникальный идентификатор сокета. Когда событие попадает в цикл, мы должны каким-то образом понять, к какому сокету оно относится — в этом случае токен служит связующим звеном между сокетами и генерируемыми ими событиями. В приведенном примере мы связываем токен
Token(0)с ожидающим соединения серверным сокетом. - EventSet описывает, на какие события мы подписываемся: поступление новых данных в сокет, доступность сокета для записи, или на то и другое.
EventSet::readable()в случае серверного сокета подписывает нас только на одно событие — установление соединения с новым клиентом. - PollOpt устанавливает настройки подписки на события.
PollOpt::edge()означает, что события срабатывают по фронту (edge-triggered), а не по уровню (level-triggered).Разница между двумя подходами, названия которых позаимствованы из электроники, заключается в моменте, когда сокет оповещает нас о произошедшем событии — например, при событии поступления данных (т.е. если мы подписаны на событие
readable()) в случае срабатывания по уровню мы получаем оповещение, если в буфере сокета есть доступные для чтения данные. В случае же сигнала по фронту оповещение мы получим в тот момент, когда в сокет поступят новые данные — т.е., если при обработке события мы не прочитали все содержимое буфера, то мы не получим новых оповещений до тех пор, пока не поступят новые данные. Более подробное описание (на английском) есть в ответе на Stack Overflow.
Теперь скомпилируем полученный код и запустим программу с помощью команды cargo run. В терминале мы по прежнему не увидим ничего, кроме мигающего курсора — но если мы отдельно выполним команду netstat, то увидим, что наш сокет ожидает подключений на порт под номером 10000:
$ netstat -ln | grep 10000 tcp 0 0 127.0.0.1:10000 0.0.0.0:* LISTEN
8 Принимаем соединения
Все соединения по протоколу WebSocket начинаются с подтверждения установления связи (т.н. handshake) — специальной последовательности запросов и ответов, передаваемых по HTTP. Это означает, что прежде чем приступить к реализации ВебСокета мы должны научить наш сервер общаться по базовому протоколу, HTTP/1.1.
Но нужна нам будет лишь малая часть HTTP: клиент, желающий установить соединение через ВебСокет отправляет запрос с заголовками Connection: Upgrade и Upgrade: websocket, и на этот запрос мы должны ответить определенным образом. И на этом все — нам не нужно писать полноценный веб-сервер с раздачей файлов, статического контента, и т.д. — для этого есть более продвинутые и подходящие инструменты (например, тот же nginx).
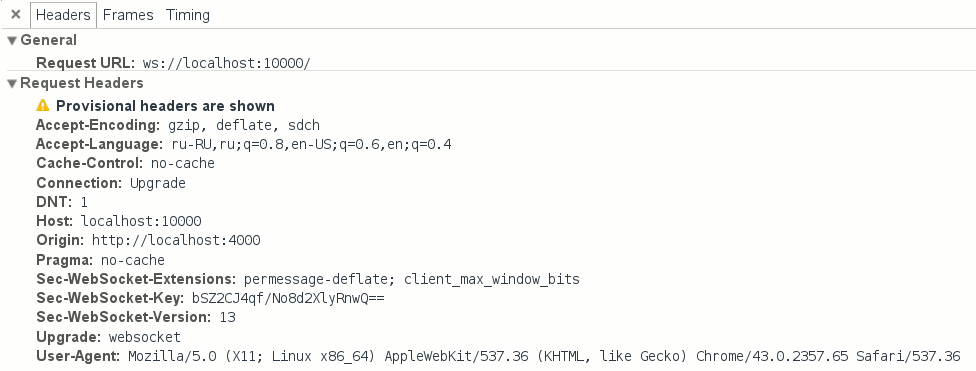
Заголовки запроса на соединение по протоколу WebSocket.
Но прежде чем мы начнем реализовать HTTP, нам необходимо написать код для установления соединений с клиентами и подписки на поступающие от них события.
Рассмотрим базовую реализацию:
use std::collections::HashMap;
struct WebSocketServer {
socket: TcpListener,
clients: HashMap<Token, TcpStream>,
token_counter: usize
}
const SERVER_TOKEN: Token = Token(0);
impl Handler for WebSocketServer {
type Timeout = usize;
type Message = ();
fn ready(&mut self, event_loop: &mut EventLoop<WebSocketServer>,
token: Token, events: EventSet)
{
match token {
SERVER_TOKEN => {
let client_socket = match self.socket.accept() {
Err(e) => {
println!("Ошибка установления подключения: {}", e);
return;
},
Ok(None) => panic!("Вызов accept вернул 'None'"),
Ok(Some(sock)) => sock
};
self.token_counter += 1;
let new_token = Token(self.token_counter);
self.clients.insert(new_token, client_socket);
event_loop.register_opt(&self.clients[&new_token],
new_token, EventSet::readable(),
PollOpt::edge() | PollOpt::oneshot()).unwrap();
}
}
}
}
Кода получилось много, поэтому давайте рассмотрим его детальнее — шаг за шагом.
В первую очередь нам нужно добавить состояние в серверную структуру WebSocketServer — она будет хранить серверный сокет и сокеты подключенных клиентов.
use std::collections::HashMap;
struct WebSocketServer {
socket: TcpListener,
clients: HashMap<Token, TcpStream>,
token_counter: usize
}
Для хранения клиентских сокетов используем структуру данных HashMap из стандартной библиотеки коллекций, std::collections — это стандартная реализация для хеш-таблиц (также известных как словари и ассоциативные массивы). В качестве ключа мы будем использовать уже знакомые нам токены, которые должны быть уникальными для каждого подключения.
Генерировать токены для начала мы можем простым способом — с помощью счетчика, который мы будем увеличивать на единицу для каждого нового подключения. Для этого нам в структуре и нужна переменная token_counter.
Далее нам снова пригождается типаж Handler из библиотеки mio:
impl Handler for WebSocketServer
В реализации типажа нам нужно переопределить функцию обратного вызова (коллбэк) — ready. Под переопределением понимается, что типаж Handler уже содержит функцию-пустышку ready и заготовки для некоторых других функций-коллбэков. Определенная в типаже реализация, разумеется, не делает ничего полезного, так что нам нужно определить собственную версию функции для обработки интересующих нас событий:
fn ready(&mut self, event_loop: &mut EventLoop<WebSocketServer>,
token: Token, events: EventSet)
Эта функция будет вызываться каждый раз, когда сокет становится доступным для чтения или записи (в зависимости от подписки), и через ее параметры вызова мы получаем всю необходимую информацию: экземпляр структуры цикла событий, токен, связанный с источником события (в данном случае — с сокетом), и специальную структуру EventSet, которая содержит набор флагов с информацией о событии (readable в случае оповещения о доступности сокета для чтения, или writable — соответственно, для записи).
Слушающий сокет генерирует события типа readable в тот момент, когда новый клиент поступил в очередь ожидающих соединения. Но прежде, чем мы начнем соединяться, нам нужно убедиться в том, что источник события — именно слушающий сокет. Мы легко можем это проверить используя сопоставление с образцом:
match token {
SERVER_TOKEN => {
...
}
}
Что это значит? Синтаксис match напоминает стандартную конструкцию switch из “традиционных” императивных языков программирования, но дает намного больше возможностей. Например, в Java конструкция switch ограничена определенным набором типов и работает только для чисел, строк, и перечислений enum. В Rust же match позволяет делать сопоставление практически для любого типа, включая множественные значения, структуры, и т.п. Помимо сопоставления match также позволяет захватывать содержимое или части образцов, схожим с регулярными выражениями образом.
В вышеприведенном примере мы сопоставляем токен с образцом Token(0) — как вы помните, он связан со слушающим сокетом. И чтобы наши намерения были более понятными при чтении кода, мы определили этот токен в виде константы SERVER_TOKEN:
const SERVER_TOKEN: Token = Token(0);
Таким образом, приведенный пример выражения match в данном случае эквивалентен такому: match { Token(0) => ... }.
Теперь, когда мы уверены, что имеем дело с серверным сокетом, мы можем установить соединение с клиентом:
let client_socket = match self.socket.accept() {
Err(e) => {
println!("Ошибка установления соединения: {}", e);
return;
},
Ok(None) => unreachable!(),
Ok(Some(sock)) => sock
};
Здесь мы снова делаем сопоставление с образцом, на этот раз проверяя результат выполнения функции accept(), которая возвращает клиентский сокет в “обертке” типа Result<Option<TcpStream>>. Result это специальный тип, который является основополагающим в обработке ошибок в Rust — он представляет собой обертку над “неопределенными” результатами, такими, как ошибки, таймауты (истечение времени ожидания), и т.п.
В каждом отдельном случае мы можем самостоятельно решить, что делать с такими результатами, но корректно обрабатывать все ошибки хоть, конечно, и правильно, но довольно утомительно. Тут на помощь нам приходит уже знакомая нам функция unwrap(), которая предоставляет стандартное поведение: прерывание выполнения программы в случае возникновения ошибки, и “распаковку” результата выполнения функции из контейнера Result в том случае, если все в порядке. Таким образом, используя unwrap(), мы подразумеваем, что заинтересованы только в непосредственном результате, и ситуация с тем, что программа прекратит свое выполнение при ошибке нас устраивает.
Это допустимое поведение в некоторых моментах, однако, в случае с accept() было бы неразумно использовать unwrap(), так как при неудачном стечении обстоятельств ее вызов может обернуться остановкой нашего сервера и отключением всех пользователей. Поэтому мы просто выводим ошибку в лог и продолжаем выполнение:
Err(e) => {
println!("Ошибка установления соединения: {}", e);
return;
},
Тип Option — похожая на Result “обертка”, которая определяет наличие или отсутствие какого-либо значения. Отсутствие значения обозначается как None, в обратном же случае значение принимает вид Some(value). Как вы, наверное, догадываетесь, такой тип сравним с типами null или None в других языках, только Option более безопасен за счет того, что все null-значения локализованы и (как и Result) требуют обязательной “распаковки” перед использованием — поэтому вы никогда не увидите “знаменитую” ошибку NullReferenceException, если сами того не захотите.
Так что давайте распакуем возвращенный accept()‘ом результат:
Ok(None) => unreachable!(),
В данном случае ситуация, когда в результате возвращается значение None невозможна — accept() его вернет только если мы попытаемся вызвать эту функцию в применении к клиентскому (т.е., не слушающему) сокету. А поскольку мы уверены в том, что имеем дело с сокетом серверным, то и до выполнения этого куска кода в нормальной ситуации дело дойти не должно — поэтому мы используем специальную конструкцию unreachable!(), которая с ошибкой прерывает выполнение программы.
Продолжаем сопоставлять результаты с образцами:
let client_socket = match self.socket.accept() {
...
Ok(Some(sock)) => sock
}
Здесь самое интересное: поскольку match является не просто инструкцией, а выражением (то есть, match также возвращает результат), помимо сопоставления он позволяет заодно и захватывать значения. Таким образом, мы можем использовать его для присвоения результатов переменным — что мы и делаем выше, распаковывая значение из типа Result<Option<TcpStream>> и присваивая его переменной client_socket.
Полученный сокет мы сохраняем в хеш-таблице, не забывая увеличить счетчик токенов:
let new_token = Token(self.token_counter);
self.clients.insert(new_token, client_socket);
self.token_counter += 1;
Наконец, нам нужно подписаться на события от сокета, с которым мы только что установили соединение — давайте зарегистрируем его в цикле событий. Делается это точно таким же образом, как и с регистрацией серверного сокета, только теперь мы в качестве параметров предоставим другой токен, и, конечно же, другой сокет:
event_loop.register_opt(&self.clients[&new_token],
new_token, EventSet::readable(),
PollOpt::edge() | PollOpt::oneshot()).unwrap();
Вы могли заметить и другое отличие в наборе аргументов: в дополнение к PollOpt::edge() мы добавили новую опцию, PollOpt::oneshot(). Она инструктирует временно убирать регистрацию сокета из цикла при срабатывании какого-либо события, что полезно для упрощения серверного кода. Без этой опции нам нужно было бы вручную отслеживать текущее состояние сокета — можно ли сейчас писать, можно ли сейчас читать, и т.д. Вместо этого мы просто будем каждый раз регистрировать сокет заново, с нужным нам в данный момент набором опций и подписок. Вдобавок ко всему, такой подход пригодится для многопоточных циклов событий, но об этом в следующий раз.
Ну и, наконец, из-за того, что наша структура WebSocketServer усложнилась, нам нужно поменять код регистрации сервера в цикле событий. Изменения достаточно простые и в основном касаются инициализации новой структуры:
let mut server = WebSocketServer {
token_counter: 1, // Начинаем отсчет токенов с 1
clients: HashMap::new(), // Создаем пустую хеш-таблицу, HashMap
socket: server_socket // Передаем владение серверным сокетом в структуру
};
event_loop.register_opt(&server.socket,
SERVER_TOKEN,
EventSet::readable(),
PollOpt::edge()).unwrap();
event_loop.run(&mut server).unwrap();
9 Парсим HTTP
Теперь, когда мы установили соединение с клиентом, согласно протоколу нам нужно распарсить входящий HTTP-запрос и “переключить” (upgrade) соединение на протокол WebSocket.
Поскольку это довольно скучное занятие, мы не будем все это делать вручную — вместо этого воспользуемся библиотекой http-muncher для парсинга HTTP, добавив ее в список зависимостей. Библиотека адаптирует для Rust парсер HTTP из Node.js (он же по совместительству парсер в nginx), который позволяет обрабатывать запросы в потоковом режиме, что как раз будет очень полезным для TCP-соединений.
Давайте добавим зависимость в Cargo.toml:
[dependencies]
http-muncher = "0.2.0"
Не будем рассматривать API библиотеки в деталях, и сразу перейдем к написанию парсера:
extern crate http_muncher;
use http_muncher::{Parser, ParserHandler};
struct HttpParser;
impl ParserHandler for HttpParser { }
struct WebSocketClient {
socket: TcpStream,
http_parser: Parser<HttpParser>
}
impl WebSocketClient {
fn read(&mut self) {
loop {
let mut buf = [0; 2048];
match self.socket.try_read(&mut buf) {
Err(e) => {
println!("Ошибка чтения сокета: {:?}", e);
return
},
Ok(None) =>
// В буфере сокета больше ничего нет.
break,
Ok(Some(len)) => {
self.http_parser.parse(&buf[0..len]);
if self.http_parser.is_upgrade() {
// ...
break;
}
}
}
}
}
fn new(socket: TcpStream) -> WebSocketClient {
WebSocketClient {
socket: socket,
http_parser: Parser::request(HttpParser)
}
}
}
И еще нам нужно внести некоторые изменения в реализацию функции ready в структуре WebSocketServer:
match token {
SERVER_TOKEN => {
...
self.clients.insert(new_token, WebSocketClient::new(client_socket));
event_loop.register_opt(&self.clients[&new_token].socket, new_token, EventSet::readable(),
PollOpt::edge() | PollOpt::oneshot()).unwrap();
...
},
token => {
let mut client = self.clients.get_mut(&token).unwrap();
client.read();
event_loop.reregister(&client.socket, token, EventSet::readable(),
PollOpt::edge() | PollOpt::oneshot()).unwrap();
}
}
Давайте опять попробуем рассмотреть новый код построчно.
Первым делом мы импортируем библиотеку и добавляем контролирующую структуру для парсера:
extern crate http_muncher;
use http_muncher::{Parser, ParserHandler};
struct HttpParser;
impl ParserHandler for HttpParser { }
Здесь мы добавляем реализацию типажа ParserHandler, который содержит некоторые полезные функции-коллбэки (так же, как и Handler из mio в случае структуры WebSocketServer). Эти коллбэки вызываются сразу же, как только у парсера появляется какая-либо полезная информация — HTTP-заголовки, содержимое запроса, и т.п. Но сейчас нам нужно только узнать, отправил ли клиент набор специальных заголовков для переключения соединения HTTP на протокол WebSocket. В структуре парсера уже есть нужные для этого функции, поэтому мы пока не будем переопределять коллбэки, оставив их стандартные реализации.
Однако, тут есть одна деталь: парсер HTTP имеет свое состояние, а это значит, что нам нужно будет создавать новый экземпляр структуры HttpParser для каждого нового клиента. Учитывая, что каждый клиент будет хранить у себя состояние парсера, давайте создадим новую структуру, описывающую отдельного клиента:
struct WebSocketClient {
socket: TcpStream,
http_parser: Parser<HttpParser>
}
Так как теперь мы можем там же хранить и клиентский сокет, можно заменить определение HashMap<Token, TcpStream> на HashMap<Token, WebSocketClient> в структуре сервера.
Кроме того, было бы удобно переместить код, который относится к обработке клиентов в эту же структуру — если держать все в одной функции ready, то код быстро превратится в “лапшу”. Так что давайте добавим отдельную реализацию read в структуре WebSocketClient:
impl WebSocketClient {
fn read(&mut self) {
...
}
}
Этой функции не нужно принимать никаких параметров — у нас уже есть вне необходимое состояние внутри самой структуры.
Теперь мы можем начать читать поступающие от клиента данные:
loop {
let mut buf = [0; 2048];
match self.socket.try_read(&mut buf) {
...
}
}
Что здесь происходит? Мы начинаем бесконечный цикл (конструкция loop { ... }), выделяем 2 КБ памяти для буфера, куда мы будем записывать данные, и пытаемся записать в него поступающие данные.
Вызов try_read может завершиться ошибкой, поэтому мы проводим сопоставление с образцом по типу Result:
match self.socket.try_read(&mut buf) {
Err(e) => {
println!("Ошибка чтения сокета: {:?}", e);
return
},
...
}
Затем мы провереяем, остались ли еще байты для чтения в буфере TCP-сокета:
match self.socket.try_read(&mut buf) {
...
Ok(None) =>
// В буфере сокета больше ничего нет.
break,
...
}
try_read возвращает результат Ok(None) в том случае, если мы прочитали все доступные данные, поступившие от клиента. Когда это происходит, мы прерываем бесконечный цикл и продолжаем ждать новых событий.
И, наконец, вот обработка случая, когда вызов © Habrahabr.ru
