[Перевод] Руководство по решению проблем с памятью в Ruby

Наверняка есть везучие Ruby-разработчики, которые никогда не страдали от проблем с памятью. Но всем остальным приходится тратить невероятно много сил, чтобы разобраться, почему использование памяти вышло из-под контроля, и устранить причины. К счастью, если у вас достаточно современная версия Ruby (начиная с 2.1), то вам доступны замечательные инструменты и методики для решения распространённых проблем. Мне кажется, что оптимизация памяти может приносить радость и удовлетворение, но я могу быть одинок в своём мнении.
Как бывает со всеми формами оптимизации, возможно, это приведёт к усложнению кода. Так что не сто̒ит этим заниматься, если вы не получите измеряемые и значительные преимущества.
Все описанные ниже процедуры выполнены с помощью канонического MRI Ruby 2.2.4, но и другие версии 2.1+ должны работать аналогично.
Это не утечка памяти!Когда возникает проблема с памятью, то сперва в голову приходит только одно — утечка. Например, вы можете увидеть в веб-приложении, что после запуска сервера повторяющиеся вызовы одной и той же функции с каждым разом потребляют всё больше памяти. Конечно, случаются и в самом деле утечки, но я готов спорить, что куда чаще встречаются проблемы, которые выглядят как утечки, но ими не являются.
Рассмотрим выдуманный пример: раз за разом будем создавать и сбрасывать большой массив хешей. Вот часть кода, которая будет использоваться в разных примерах в этой статье:
# common.rb
require "active_record"
require "active_support/all"
require "get_process_mem"
require "sqlite3"
ActiveRecord::Base.establish_connection(
adapter: "sqlite3",
database: "people.sqlite3"
)
class Person < ActiveRecord::Base; end
def print_usage(description)
mb = GetProcessMem.new.mb
puts "#{ description } - MEMORY USAGE(MB): #{ mb.round }"
end
def print_usage_before_and_after
print_usage("Before")
yield
print_usage("After")
end
def random_name
(0...20).map { (97 + rand(26)).chr }.join
end
Строим массив:
# build_arrays.rb
require_relative "./common"
ARRAY_SIZE = 1_000_000
times = ARGV.first.to_i
print_usage(0)
(1..times).each do |n|
foo = []
ARRAY_SIZE.times { foo << {some: "stuff"} }
print_usage(n)
end
get_process_mem — удобный способ получить информацию о памяти, используемой текущим Ruby-процессом. Мы видим описанное выше поведение: постепенное увеличение потребления памяти.
$ ruby build_arrays.rb 10
0 - MEMORY USAGE(MB): 17
1 - MEMORY USAGE(MB): 330
2 - MEMORY USAGE(MB): 481
3 - MEMORY USAGE(MB): 492
4 - MEMORY USAGE(MB): 559
5 - MEMORY USAGE(MB): 584
6 - MEMORY USAGE(MB): 588
7 - MEMORY USAGE(MB): 591
8 - MEMORY USAGE(MB): 603
9 - MEMORY USAGE(MB): 613
10 - MEMORY USAGE(MB): 621
Но если выполнить больше итераций, то рост потребления прекратится.
$ ruby build_arrays.rb 40
0 - MEMORY USAGE(MB): 9
1 - MEMORY USAGE(MB): 323
...
32 - MEMORY USAGE(MB): 700
33 - MEMORY USAGE(MB): 699
34 - MEMORY USAGE(MB): 698
35 - MEMORY USAGE(MB): 698
36 - MEMORY USAGE(MB): 696
37 - MEMORY USAGE(MB): 696
38 - MEMORY USAGE(MB): 696
39 - MEMORY USAGE(MB): 701
40 - MEMORY USAGE(MB): 697
Это говорит о том, что мы имеем дело не с утечкой. Либо утечка так мала, что мы её не замечаем по сравнению с остальной используемой памятью. Но непонятно, почему после первой итерации растёт потребление памяти. Да, мы создаём большой массив, но потом корректно его обнуляем и начинаем создавать новый такого же размера. Разве нельзя взять ту же память, которая использовалась предыдущим массивом?
Нет.
Помимо настройки сборщика мусора вы не можете управлять временем его запуска. В нашем примере build_arrays.rb мы видим, что новые распределения памяти делаются до того, как сборщик мусора уберёт наши старые, сброшенные объекты.
Не волнуйтесь, если обнаружите неожиданное увеличение потребления памяти вашим приложением. Тому может быть множество причин, не только утечки.
Должен отметить, что речь не идёт о каком-то кошмарном управлении памятью, характерном для Ruby. Но вопрос в целом имеет отношение ко всем языкам, использующим сборщики мусора. Чтобы удостовериться в этом, я воспроизвёл приведённый пример на Go и получил аналогичный результат. Правда, там используются библиотеки Ruby, которые могли стать причиной этой проблемы с памятью.
Разделяй и властвуйИтак, если нам нужно работать с большими объёмами данных, то мы обречены терять кучу оперативной памяти? К счастью, это не тот случай. Если взять предыдущий пример и уменьшить размер массива, то мы обнаружим, что потребление памяти выровняется раньше.
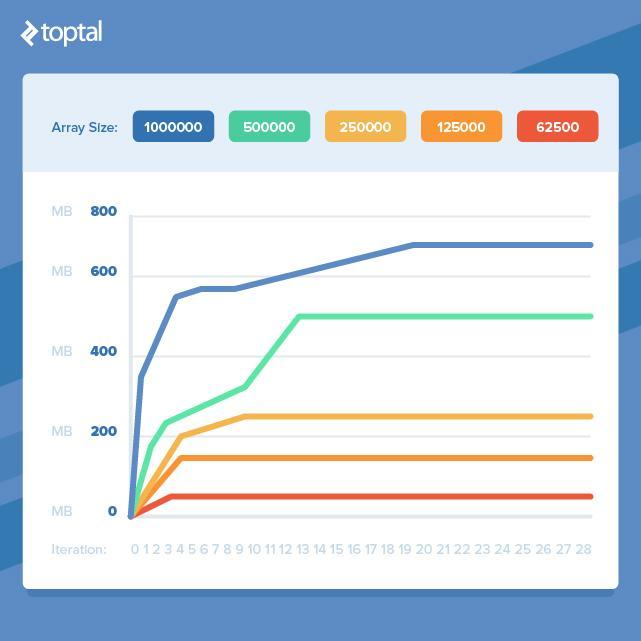
Это означает, что если мы можем разбить нашу работу на более мелкие фрагменты и обработать, чтобы исключить одновременное использование большого количества объектов, то мы избежим сильного увеличения потребления памяти. К сожалению, для этого часто приходится взять чистый и красивый код и превратить его в более громоздкий, который делает всё то же самое, но эффективнее с точки зрения памяти.
Изолирование горячих точек потребления памятиЧасто в коде источник проблемы с памятью не столь очевиден, как в примере
build_arrays.rb. Необходимо сначала изолировать причину и только затем приступать к её изучению, потому что легко можно сделать ошибочные выводы о причине проблемы.
Обычно для выявления проблем с памятью я использую два подхода, зачастую комбинируя:
- оставляю код без изменений и оборачиваю его в профилировщик;
- отслеживаю использование памяти процессом, убирая/добавляя разные части кода, которые могут быть причиной проблемы.
Здесь в качестве профилировщика я воспользуюсь memory_profiler (также популярен ruby-prof), а для мониторинга возьму derailed_benchmarks, имеющий некоторые замечательные возможности, характерные для Rails.
Вот пример кода, использующего большой объём памяти. Здесь не ясно с ходу, на каком этапе потребляется больше всего:
# people.rb
require_relative "./common"
def run(number)
Person.delete_all
names = number.times.map { random_name }
names.each do |name|
Person.create(name: name)
end
records = Person.all.to_a
File.open("people.txt", "w") { |out| out << records.to_json }
end
С помощью get_process_mem можно быстро выяснить, что больше всего памяти используется при создании записей
Person.# before_and_after.rb
require_relative "./people"
print_usage_before_and_after do
run(ARGV.shift.to_i)
end
Результат:
$ ruby before_and_after.rb 10000
Before - MEMORY USAGE(MB): 37
After - MEMORY USAGE(MB): 96
В этом коде есть несколько мест, которые могут отнимать много памяти: создание большого массива строк, вызов
#to_a для создания большого массива из объектов Active Record (не лучшая идея, но это сделано ради демонстрации) и сериализация массива из объектов Active Record.Выполним профилирование кода, чтобы понять, где осуществляются распределения памяти:
# profile.rb
require "memory_profiler"
require_relative "./people"
report = MemoryProfiler.report do
run(1000)
end
report.pretty_print(to_file: "profile.txt")
Обратите внимание, что
run здесь скармливается в десять раз меньшее количество, чем в предыдущем примере. Профилировщик сам по себе потребляет много памяти, и это может привести к её исчерпанию во время профилирования кода, который уже занял большой объём.Файл получается довольно длинным, включает в себя распределение и удержание памяти и объектов в gem«е, файлы, а также уровни размещения. Настоящее обилие информации, в которой есть пара интересных частей:
allocated memory by gem
-----------------------------------
17520444 activerecord-4.2.6
7305511 activesupport-4.2.6
2551797 activemodel-4.2.6
2171660 arel-6.0.3
2002249 sqlite3-1.3.11
...
allocated memory by file
-----------------------------------
2840000 /Users/bruz/.rvm/gems/ruby-2.2.4/gems/activesupport-4.2.6/lib/activ
e_support/hash_with_indifferent_access.rb
2006169 /Users/bruz/.rvm/gems/ruby-2.2.4/gems/activerecord-4.2.6/lib/active
_record/type/time_value.rb
2001914 /Users/bruz/code/mem_test/people.rb
1655493 /Users/bruz/.rvm/gems/ruby-2.2.4/gems/activerecord-4.2.6/lib/active
_record/connection_adapters/sqlite3_adapter.rb
1628392 /Users/bruz/.rvm/gems/ruby-2.2.4/gems/activesupport-4.2.6/lib/activ
e_support/json/encoding.rb
Большинство распределений происходят внутри Active Record. Похоже, это указывает либо на создание экземпляров всех объектов в массиве
records, либо на сериализацию с помощью #to_json. Далее мы можем протестировать использование памяти без профилировщика, убрав подозрительные места. Мы не можем отключить извлечение records, так что начнём с сериализации.# File.open("people.txt", "w") { |out| out << records.to_json }
Результат:
$ ruby before_and_after.rb 10000
Before: 36 MB
After: 47 MB
Похоже, именно здесь потребляется больше всего памяти: соотношение между до и после составляет 81%. Можно посмотреть, что будет, если мы перестанем принудительно создавать большой архив записей.
# records = Person.all.to_a
records = Person.all
# File.open("people.txt", "w") { |out| out << records.to_json }
Результат:
$ ruby before_and_after.rb 10000
Before: 36 MB
After: 40 MB
Потребление памяти тоже снижается, хотя и на порядок меньше, чем при отключении сериализации. Теперь нам известен главный виновник, и можно принять решение об оптимизации.
Хотя это и выдуманный пример, описанные здесь подходы применимы и в реальных задачах. Результаты профилирования могут не дать внятного результата и конкретного источника проблемы, да к тому же могут быть интерпретированы неверно. Так что лучше дополнительно проверить реальное использование памяти, включая и отключая части кода.
Далее мы рассмотрим некоторые распространённые ситуации, когда использование памяти становится проблемой, и узнаем, какие оптимизации можно сделать.
ДесериализацияПроблемы с памятью часто возникают при десериализации больших объёмов данных из XML, JSON или других форматов сериализации данных. Методы вроде
JSON.parse или Hash.from_xml из Active Support крайне удобны, но если данных много, то в память может загрузиться гигантская структура.Если у вас есть контроль над источником данных, вы можете ограничить объём получаемой информации, добавив фильтрацию или поддержку загрузки частями. Но если источник внешний или вы не можете его контролировать, то можно воспользоваться потоковым десериализатором. В случае с XML можно взять Ox, а для JSON подойдёт yajl-ruby. Судя по всему, они работают примерно одинаково.
То, что у вас ограниченный объём памяти, не означает, что вы не можете безопасно парсить большие XML- или JSON-документы. Потоковые десериализаторы позволяют постепенно извлекать то, что вам нужно, сохраняя низкое потребление памяти.
Вот пример парсинга XML-файла размером 1,7 Мб с помощью Hash#from_xml.
# parse_with_from_xml.rb
require_relative "./common"
print_usage_before_and_after do
# From http://www.cs.washington.edu/research/xmldatasets/data/mondial/mondial-3.0.xml
file = File.open(File.expand_path("../mondial-3.0.xml", __FILE__))
hash = Hash.from_xml(file)["mondial"]["continent"]
puts hash.map { |c| c["name"] }.join(", ")
end
$ ruby parse_with_from_xml.rb
Before - MEMORY USAGE(MB): 37
Europe, Asia, America, Australia/Oceania, Africa
After - MEMORY USAGE(MB): 164
111 Мб на файл 1,7 Мб! Совершенно неуместное соотношение. А вот версия с потоковым парсером.
# parse_with_ox.rb
require_relative "./common"
require "ox"
class Handler < ::Ox::Sax
def initialize(&block)
@yield_to = block
end
def start_element(name)
case name
when :continent
@in_continent = true
end
end
def end_element(name)
case name
when :continent
@yield_to.call(@name) if @name
@in_continent = false
@name = nil
end
end
def attr(name, value)
case name
when :name
@name = value if @in_continent
end
end
end
print_usage_before_and_after do
# From http://www.cs.washington.edu/research/xmldatasets/data/mondial/mondial-3.0.xml
file = File.open(File.expand_path("../mondial-3.0.xml", __FILE__))
continents = []
handler = Handler.new do |continent|
continents << continent
end
Ox.sax_parse(handler, file)
puts continents.join(", ")
end
$ ruby parse_with_ox.rb
Before - MEMORY USAGE(MB): 37
Europe, Asia, America, Australia/Oceania, Africa
After - MEMORY USAGE(MB): 37
Потребление памяти увеличивается незначительно, и теперь мы можем обрабатывать гораздо более крупные файлы. Но компромисса избежать не удалось: теперь у нас 28 строк кода обработки, который раньше был не нужен. Это повышает вероятность ошибок, так что в производстве эту часть нужно дополнительно тестировать.Сериализация
Как мы видели в главе про изолирование горячих точек потребления памяти, сериализация может проводить к большим потерям. Вот ключевая часть из приведённого выше примера
people.rb.# to_json.rb
require_relative "./common"
print_usage_before_and_after do
File.open("people.txt", "w") { |out| out << Person.all.to_json }
end
Если запустить его с базой данных на 100 000 записей, то мы получим:
$ ruby to_json.rb
Before: 36 MB
After: 505 MB
Здесь проблема с
#to_json заключается в том, что он создаёт экземпляр объекта для каждой записи, а затем кодирует в JSON. Можно существенно снизить потребление памяти, если генерировать JSON запись за записью, чтобы в каждый отрезок времени существовал только один объект записи. Похоже, этого не умеет делать ни одна из популярных Ruby JSON библиотек, и обычно рекомендуется вручную создавать JSON-строку. Хороший API для этого предоставляет gem json-write-stream, и тогда наш пример можно конвертировать: # json_stream.rb
require_relative "./common"
require "json-write-stream"
print_usage_before_and_after do
file = File.open("people.txt", "w")
JsonWriteStream.from_stream(file) do |writer|
writer.write_object do |obj_writer|
obj_writer.write_array("people") do |arr_writer|
Person.find_each do |people|
arr_writer.write_element people.as_json
end
end
end
end
end
В очередной раз оптимизация потребовала написать больше кода, но результат того стоит:
$ ruby json_stream.rb
Before: 36 MB
After: 56 MB
Быть ленивым
Начиная с Ruby 2.0 появилась замечательная возможность делать ленивые перечислители (lazy enumerator). Это позволяет сильно уменьшить потребление памяти при вызове цепочки методов перечислителя. Начнём с неленивого кода:
# not_lazy.rb
require_relative "./common"
number = ARGV.shift.to_i
print_usage_before_and_after do
names = number.times
.map { random_name }
.map { |name| name.capitalize }
.map { |name| "#{ name } Jr." }
.select { |name| name[0] == "X" }
.to_a
end
Результат:
$ ruby not_lazy.rb 1_000_000
Before: 36 MB
After: 546 MB

На каждой стадии цепочки выполняется итерация по всем элементам и создаётся новый массив, у которого есть вызываемый им следующий метод в цепочке, и т. д. Давайте посмотрим, что происходит, когда мы делаем это ленивым способом, просто добавляя вызов lazy в получаемый из times перечислитель:
# lazy.rb
require_relative "./common"
number = ARGV.shift.to_i
print_usage_before_and_after do
names = number.times.lazy
.map { random_name }
.map { |name| name.capitalize }
.map { |name| "#{ name } Jr." }
.select { |name| name[0] == "X" }
.to_a
end
Результат:
$ ruby lazy.rb 1_000_000
Before: 36 MB
After: 52 MB
Наконец-то пример, дающий нам огромный выигрыш в потреблении памяти без добавления большого количества кода! Обратите внимание, что если нам не нужно в конце аккумулировать результаты, например если каждый элемент был сохранён в базу данных и может быть забыт, то памяти будет тратиться ещё меньше. Для получения результата перечислителя в конце цепочки просто добавьте финальный вызов
force.Также нужно отметить, что сначала вызывается times, а потом lazy, ведь первый потребляет очень мало памяти, всего лишь возвращая перечислитель, который генерирует целочисленное при каждом вызове. Так что если в начале цепочки вместо массива можно использовать перечислитель, то это также является плюсом, снижая потребление памяти.
Удобно держать всё в огромных массивах и коллекциях (map), но в реальных ситуациях это допускается только в редких случаях.
Создавать enumerable для ленивой обработки данных можно, например, при работе с данными, разделёнными на страницы. Вместо того чтобы запрашивать все страницы и класть их в один большой массив, можно выдавать их через перечислитель, который замечательно прячет все подробности разбиения на страницы. Например, так:
def records
Enumerator.new do |yielder|
has_more = true
page = 1
while has_more
response = fetch(page)
response.records.each { |record| yielder record }
page += 1
has_more = response.has_more
end
end
end
Заключение
Мы дали характеристику использованию памяти в Ruby, рассмотрели несколько основных инструментов для отслеживания проблем с памятью, разобрали частые ситуации и способы оптимизации. Рассмотренные ситуации не претендуют на полноту охвата и иллюстрируют самые разные проблемы, с которыми я лично сталкивался. Однако главный результат статьи — попытка задуматься о том, как код влияет на потребление памяти.
