[Перевод] Руководство по использованию pandas для анализа больших наборов данных
При использовании библиотеки pandas для анализа маленьких наборов данных, размер которых не превышает 100 мегабайт, производительность редко становится проблемой. Но когда речь идёт об исследовании наборов данных, размеры которых могут достигать нескольких гигабайт, проблемы с производительностью могут приводить к значительному увеличению длительности анализа данных и даже могут становиться причиной невозможности проведения анализа из-за нехватки памяти.
В то время как инструменты наподобие Spark могут эффективно обрабатывать большие наборы данных (от сотен гигабайт до нескольких терабайт), для того чтобы полноценно пользоваться их возможностями обычно нужно достаточно мощное и дорогое аппаратное обеспечение. И, в сравнении с pandas, они не отличаются богатыми наборами средств для качественного проведения очистки, исследования и анализа данных. Для наборов данных средних размеров лучше всего попытаться более эффективно использовать pandas, а не переходить на другие инструменты.

В материале, перевод которого мы публикуем сегодня, мы поговорим об особенностях работы с памятью при использовании pandas, и о том, как, просто подбирая подходящие типы данных, хранящихся в столбцах табличных структур данных DataFrame, снизить потребление памяти почти на 90%.
Работа с данными о бейсбольных матчах
Мы будем работать с данными по бейсбольным играм Главной лиги, собранными за 130 лет и взятыми с Retrosheet.
Изначально эти данные были представлены в виде 127 CSV-файлов, но мы объединили их в один набор данных с помощью csvkit и добавили, в качестве первой строки получившейся таблицы, строку с названиями столбцов. Если хотите, можете загрузить нашу версию этих данных и экспериментировать с ними, читая статью.
Начнём с импорта набора данных и взглянем на его первые пять строк. Их вы можете найти в этой таблице, на листе Фрагмент исходного набора данных.
import pandas as pd
gl = pd.read_csv('game_logs.csv')
gl.head()
Ниже приведены сведения о наиболее важных столбцах таблицы с этими данными. Если вы хотите почитать пояснения по всем столбцам — здесь вы можете найти словарь данных для всего набора данных.
date— Дата проведения игры.v_name— Название команды гостей.v_league— Лига команды гостей.h_name— Название команды хозяев.h_league— Лига команды хозяев.v_score— Очки команды гостей.h_score— Очки команды хозяев.v_line_score— Сводка по очкам команды гостей, например —010000(10)00.h_line_score— Сводка по очкам команды хозяев, например —010000(10)0X.park_id— Идентификатор поля, на котором проводилась игра.attendance— Количество зрителей.
Для того чтобы узнать общие сведения об объекте DataFrame, можно воспользоваться методом DataFrame.info (). Благодаря этому методу можно узнать о размере объекта, о типах данных и об использовании памяти.
По умолчанию pandas, ради экономии времени, указывает приблизительные сведения об использовании памяти объектом DataFrame. Нас интересуют точные сведения, поэтому мы установим параметр memory_usage в значение 'deep'.
gl.info(memory_usage='deep')
Вот какие сведения нам удалось получить:
RangeIndex: 171907 entries, 0 to 171906
Columns: 161 entries, date to acquisition_info
dtypes: float64(77), int64(6), object(78)
memory usage: 861.6 MB
Как оказалось, у нас имеется 171,907 строк и 161 столбец. Библиотека pandas автоматически выяснила типы данных. Здесь присутствует 83 столбца с числовыми данными и 78 столбцов с объектами. Объектные столбцы используются для хранения строковых данных, и в тех случаях, когда столбец содержит данные разных типов.
Теперь, для того, чтобы лучше понять то, как можно оптимизировать использование памяти этим объектом DataFrame, давайте поговорим о том, как pandas хранит данные в памяти.
Внутреннее представление объекта DataFrame
Внутри pandas столбцы данных группируются в блоки со значениями одинакового типа. Вот пример того, как в pandas хранятся первые 12 столбцов объекта DataFrame.
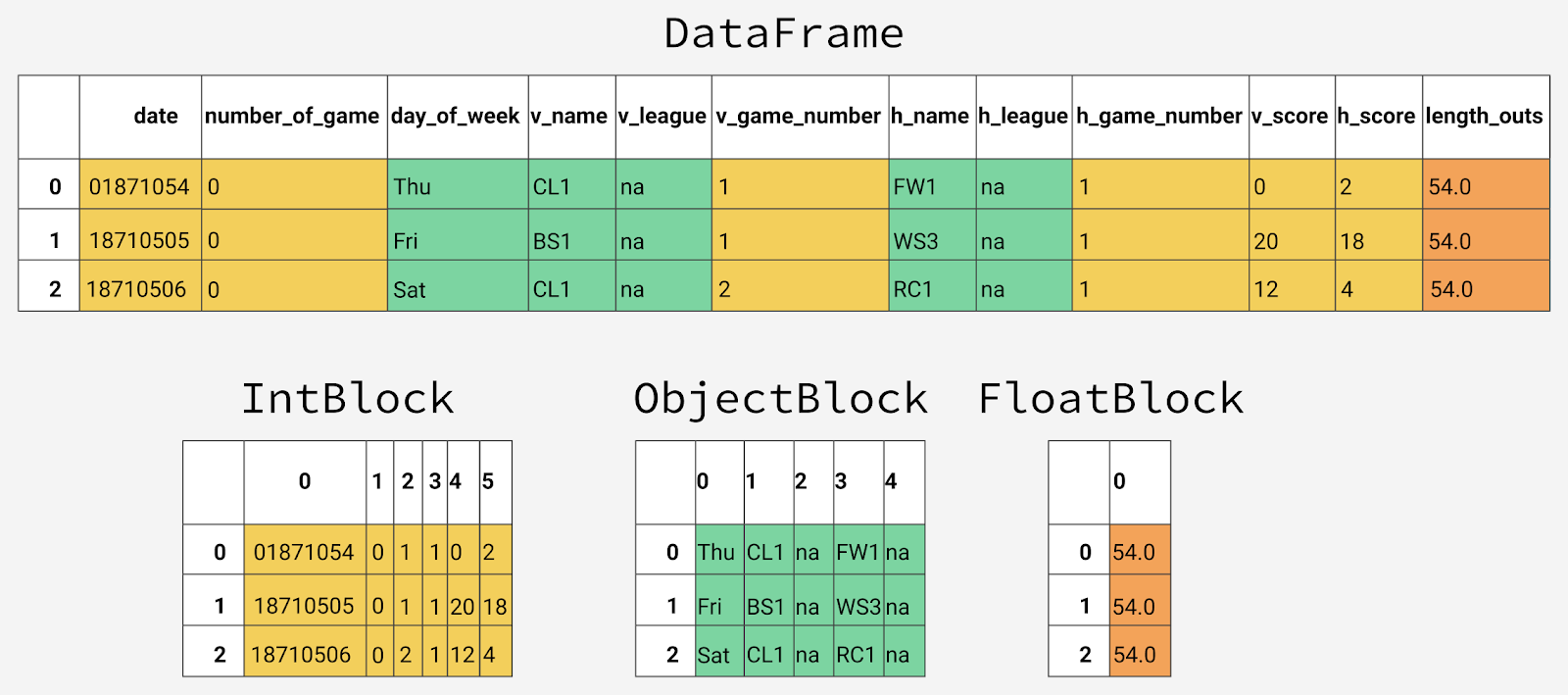
Внутреннее представление данных разных типов в pandas
Можно заметить, что блоки не хранят сведения об именах столбцов. Происходит это из-за того, что блоки оптимизированы для хранения значений, имеющихся в ячейках таблицы объекта DataFrame. За хранение сведений о соответствии между индексами строк и столбцов набора данных и того, что хранится в блоках однотипных данных, отвечает класс BlockManager. Он играет роль API, который предоставляет доступ к базовым данным. Когда мы читаем, редактируем или удаляем значения, класс DataFrame взаимодействует с классом BlockManager для преобразования наших запросов в вызовы функций и методов.
Каждый тип данных имеет специализированный класс в модуле pandas.core.internals. Например, pandas использует класс ObjectBlock для представления блоков, содержащих строковые столбцы, и класс FloatBlock для представления блоков, содержащих столбцы, хранящие числа с плавающей точкой. Для блоков, представляющих числовые значения, выглядящие как целые числа или числа с плавающей точкой, pandas комбинирует столбцы и хранит их в виде структуры данных ndarray библиотеки NumPy. Эта структура данных построена на основе массива C, значения хранятся в непрерывном блоке памяти. Благодаря такой схеме хранения данных доступ к фрагментам данных осуществляется очень быстро.
Так как данные разных типов хранятся раздельно, мы исследуем использование памяти разными типами данных. Начнём со среднего показателя использования памяти по разным типам данных.
for dtype in ['float','int','object']:
selected_dtype = gl.select_dtypes(include=[dtype])
mean_usage_b = selected_dtype.memory_usage(deep=True).mean()
mean_usage_mb = mean_usage_b / 1024 ** 2
print("Average memory usage for {} columns: {:03.2f} MB".format(dtype,mean_usage_mb))
В результате оказывается, что средние показатели по использованию памяти для данных разных типов выглядят так:
Average memory usage for float columns: 1.29 MB
Average memory usage for int columns: 1.12 MB
Average memory usage for object columns: 9.53 MB
Эти сведения дают нам понять то, что большая часть памяти уходит на 78 столбцов, хранящих объектные значения. Мы ещё поговорим об этом позже, а сейчас давайте подумаем о том, можем ли мы улучшить использование памяти столбцами, хранящими числовые данные.
Подтипы
Как мы уже говорили, pandas представляет числовые значения в виде структур данных ndarray NumPy и хранит их в непрерывных блоках памяти. Эта модель хранения данных позволяет экономно расходовать память и быстро получать доступ к значениям. Так как pandas представляет каждое значение одного и того же типа, используя одинаковое число байт, и структуры ndarray хранят сведения о числе значений, pandas может быстро и точно выдать сведения об объёме памяти, потребляемых столбцами, хранящими числовые значения.
У многих типов данных в pandas есть множество подтипов, которые могут использовать меньшее число байт для представления каждого значения. Например тип float имеет подтипы float16, float32 и float64. Число в имени типа указывает на количество бит, которые подтип использует для представления значений. Например, в только что перечисленных подтипах для хранения данных используется, соответственно, 2, 4, 8 и 16 байт. В следующей таблице представлены подтипы наиболее часто используемых в pandas типов данных.
| Использование памяти, байт |
Число с плавающей точкой |
Целое число |
Беззнаковое целое число |
Дата и время |
Логическое значение |
Объект |
| 1 |
int8 |
uint8 |
bool |
|||
| 2 |
float16 |
int16 |
uint16 |
|||
| 4 |
float32 |
int32 |
uint32 |
|||
| 8 |
float64 |
int64 |
uint64 |
datetime64 |
||
| Переменный объём памяти |
object |
Значение типа int8 использует 1 байт (8 бит) для хранения числа и может представлять 256 двоичных значений (2 в 8 степени). Это означает, что этот подтип можно использовать для хранения значений в диапазоне от -128 до 127 (включая 0).
Для проверки минимального и максимального значения, подходящего для хранения с использованием каждого целочисленного подтипа, можно воспользоваться методом numpy.iinfo(). Рассмотрим пример:
import numpy as np
int_types = ["uint8", "int8", "int16"]
for it in int_types:
print(np.iinfo(it))
Выполнив этот код, мы получаем следующие данные:
Machine parameters for uint8
---------------------------------------------------------------
min = 0
max = 255
---------------------------------------------------------------
Machine parameters for int8
---------------------------------------------------------------
min = -128
max = 127
---------------------------------------------------------------
Machine parameters for int16
---------------------------------------------------------------
min = -32768
max = 32767
---------------------------------------------------------------
Тут можно обратить внимание на различие между типами uint (беззнаковое целое) и int (целое число со знаком). Оба типа имеют одинаковую ёмкость, но, при хранении в столбцах только положительных значений, беззнаковые типы позволяют эффективнее расходовать память.
Оптимизация хранения числовых данных с использованием подтипов
Функцию pd.to_numeric() можно использовать для нисходящего преобразования числовых типов. Для выбора целочисленных столбцов воспользуемся методом DataFrame.select_dtypes(), затем оптимизируем их и сравним использование памяти до и после оптимизации.
# Мы будем часто выяснять то, сколько памяти используется,
# поэтому создадим функцию, которая поможет нам сэкономить немного времени.
def mem_usage(pandas_obj):
if isinstance(pandas_obj,pd.DataFrame):
usage_b = pandas_obj.memory_usage(deep=True).sum()
else: # исходим из предположения о том, что если это не DataFrame, то это Series
usage_b = pandas_obj.memory_usage(deep=True)
usage_mb = usage_b / 1024 ** 2 # преобразуем байты в мегабайты
return "{:03.2f} MB".format(usage_mb)
gl_int = gl.select_dtypes(include=['int'])
converted_int = gl_int.apply(pd.to_numeric,downcast='unsigned')
print(mem_usage(gl_int))
print(mem_usage(converted_int))
compare_ints = pd.concat([gl_int.dtypes,converted_int.dtypes],axis=1)
compare_ints.columns = ['before','after']
compare_ints.apply(pd.Series.value_counts)
Вот что получается в результате исследования потребления памяти:
7.87 MB
1.48 MB
| До |
После |
|
| uint8 |
NaN |
5.0 |
| uint32 |
NaN |
1.0 |
| int64 |
6.0 |
NaN |
В результате можно видеть падение использования памяти с 7.9 до 1.5 мегабайт, то есть — мы снизили потребление памяти больше, чем на 80%. Общее воздействие этой оптимизации на исходный объект DataFrame, однако, не является особенно сильным, так как в нём очень мало целочисленных столбцов.
Сделаем то же самое со столбцами, содержащими числа с плавающей точкой.
gl_float = gl.select_dtypes(include=['float'])
converted_float = gl_float.apply(pd.to_numeric,downcast='float')
print(mem_usage(gl_float))
print(mem_usage(converted_float))
compare_floats = pd.concat([gl_float.dtypes,converted_float.dtypes],axis=1)
compare_floats.columns = ['before','after']
compare_floats.apply(pd.Series.value_counts)
В результате получается следующее:
100.99 MB
50.49 MB
| До |
После |
|
| float32 |
NaN |
77.0 |
| float64 |
77.0 |
NaN |
В результате все столбцы, хранившие числа с плавающей точкой с типом данных float64, теперь хранят числа типа float32, что дало нам 50% уменьшение использования памяти.
Создадим копию исходного объекта DataFrame, используем эти оптимизированные числовые столбцы вместо тех, что присутствовали в нём изначально, и посмотрим на общий показатель использования памяти после оптимизации.
optimized_gl = gl.copy()
optimized_gl[converted_int.columns] = converted_int
optimized_gl[converted_float.columns] = converted_float
print(mem_usage(gl))
print(mem_usage(optimized_gl))
Вот что у нас получилось:
861.57 MB
804.69 MB
Хотя мы значительно уменьшили потребление памяти столбцами, хранящими числовые данные, в целом, по всему объекту DataFrame, потребление памяти снизилось лишь на 7%. Источником куда более серьёзного улучшения ситуации может стать оптимизация хранения объектных типов.
Прежде чем мы займёмся такой оптимизацией, поближе познакомимся с тем, как в pandas хранятся строки, и сравним это с тем, как здесь хранятся числа.
Сравнение механизмов хранения чисел и строк
Тип object представляет значения с использованием строковых объектов Python. Отчасти это так от того, что NumPy не поддерживает представление отсутствующих строковых значений. Так как Python — это высокоуровневый интерпретируемый язык, он не даёт программисту инструментов для тонкого управления тем, как данные хранятся в памяти.
Это ограничение ведёт к тому, что строки хранятся не в непрерывных фрагментах памяти, их представление в памяти фрагментировано. Это ведёт к увеличению потребления памяти и к замедлению скорости работы со строковыми значениями. Каждый элемент в столбце, хранящем объектный тип данных, на самом деле, представляет собой указатель, который содержит «адрес», по которому настоящее значение расположено в памяти.
Ниже показана схема, созданная на основе этого материала, на которой сравнивается хранение числовых данных с использованием типов данных NumPy и хранение строк с применением встроенных типов данных Python.

Хранение числовых и строковых данных
Тут вы можете вспомнить о том, что выше, в одной из таблиц, было показано, что для хранения данных объектных типов используется переменный объём памяти. Хотя каждый указатель занимает 1 байт памяти, каждое конкретное строковое значение занимает тот же объём памяти, который использовался бы для хранения отдельно взятой строки в Python. Для того чтобы это подтвердить, воспользуемся методом sys.getsizeof(). Сначала взглянем на отдельные строки, а затем на объект Series pandas, хранящий строковые данные.
Итак, сначала исследуем обычные строки:
from sys import getsizeof
s1 = 'working out'
s2 = 'memory usage for'
s3 = 'strings in python is fun!'
s4 = 'strings in python is fun!'
for s in [s1, s2, s3, s4]:
print(getsizeof(s))
Здесь данные по использованию памяти выглядят так:
60
65
74
74
Теперь посмотрим на то, как выглядит использование строк в объекте Series:
obj_series = pd.Series(['working out',
'memory usage for',
'strings in python is fun!',
'strings in python is fun!'])
obj_series.apply(getsizeof)
Здесь мы получаем следующее:
0 60
1 65
2 74
3 74
dtype: int64
Тут можно видеть, что размеры строк, хранящихся в объектах Series pandas, аналогичны их размерам при работе с ними в Python и при представлении их в виде самостоятельных сущностей.
Оптимизация хранения данных объектных типов с использованием категориальных переменных
Категориальные переменные появились в pandas версии 0.15. Соответствующий тип, category, использует в своих внутренних механизмах, вместо исходных значений, хранящихся в столбцах таблицы, целочисленные значения. Pandas использует отдельный словарь, устанавливающий соответствия целочисленных и исходных значений. Такой подход полезен в тех случаях, когда столбцы содержат значения из ограниченного набора. Когда данные, хранящиеся в столбце, конвертируют в тип category, pandas использует подтип int, который позволяет эффективнее всего распорядиться памятью и способен представить все уникальные значения, встречающиеся в столбце.
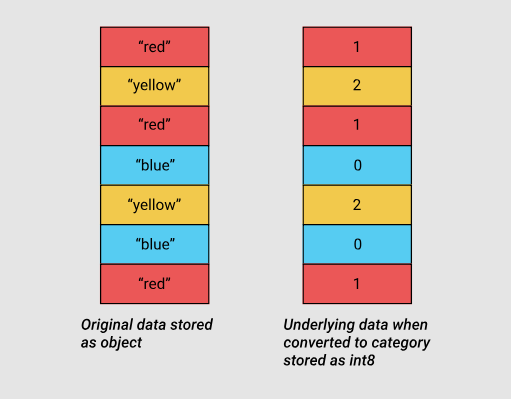
Исходные данные и категориальные данные, использующие подтип int8
Для того чтобы понять, где именно мы сможем воспользоваться категориальными данными для снижения потребления памяти, выясним количество уникальных значений в столбцах, хранящих значения объектных типов:
gl_obj = gl.select_dtypes(include=['object']).copy()
gl_obj.describe()
То, что у нас получилось, вы может найти в этой таблице, на листе Количество уникальных значений в столбцах.
Например, в столбце day_of_week, представляющем собой день недели, в который проводилась игра, имеется 171907 значений. Среди них всего 7 уникальных. В целом же, одного взгляда на этот отчёт достаточно для того, чтобы понять, что во многих столбцах для представления данных примерно 172000 игр используется довольно-таки мало уникальных значений.
Прежде чем мы займёмся полномасштабной оптимизацией, давайте выберем какой-нибудь один столбец, хранящий объектные данные, да хотя бы day_of_week, и посмотрим, что происходит внутри программы при преобразовании его в категориальный тип.
Как уже было сказано, в этом столбце содержится всего 7 уникальных значений. Для преобразования его в категориальный тип воспользуемся методом .astype().
dow = gl_obj.day_of_week
print(dow.head())
dow_cat = dow.astype('category')
print(dow_cat.head())
Вот что у нас получилось:
0 Thu
1 Fri
2 Sat
3 Mon
4 Tue
Name: day_of_week, dtype: object
0 Thu
1 Fri
2 Sat
3 Mon
4 Tue
Name: day_of_week, dtype: category
Categories (7, object): [Fri, Mon, Sat, Sun, Thu, Tue, Wed]
Как видите, хотя тип столбца изменился, данные, хранящиеся в нём, выглядят так же, как и раньше. Посмотрим теперь на то, что происходит внутри программы.
В следующем коде мы используем атрибут Series.cat.codes для того, чтобы выяснить то, какие целочисленные значения тип category использует для представления каждого из дней недели:
dow_cat.head().cat.codes
Нам удаётся выяснить следующее:
0 4
1 0
2 2
3 1
4 5
dtype: int8
Тут можно заметить то, что каждому уникальному значению назначено целочисленное значение, и то, что столбец теперь имеет тип int8. Здесь нет отсутствующих значений, но если бы это было так, для указания таких значений использовалось бы число -1.
Теперь давайте сравним потребление памяти до и после преобразования столбца day_of_week к типу category.
print(mem_usage(dow))
print(mem_usage(dow_cat))
Вот что тут получается:
9.84 MB
0.16 MB
Как видно, сначала потреблялось 9.84 мегабайт памяти, а после оптимизации — лишь 0.16 мегабайт, что означает 98% улучшение этого показателя. Обратите внимание на то, что работа с этим столбцом, вероятно, демонстрирует один из наиболее выгодных сценариев оптимизации, когда в столбце, содержащем примерно 172000 элементов, используется лишь 7 уникальных значений.
Хотя идея преобразования всех столбцов к этому типу данных выглядит привлекательно, прежде чем это делать, стоит учитывать негативные побочные эффекты такого преобразования. Так, наиболее серьёзный минус этого преобразования заключается в невозможности выполнения арифметических операций над категориальными данными. Это касается и обычных арифметических операций, и использования методов наподобие Series.min() и Series.max() без предварительного преобразования данных к настоящему числовому типу.
Нам стоит ограничить использование типа category, в основном, столбцами, хранящими данные типа object, в которых уникальными являются менее 50% значений. Если все значения в столбце уникальны, то использование типа category приведёт к повышению уровня использования памяти. Это происходит из-за того, что в памяти приходится хранить, в дополнение к числовым кодам категорий, ещё и исходные строковые значения. Подробности об ограничениях типа category можно почитать в документации к pandas.
Создадим цикл, который перебирает все столбцы, хранящие данные типа object, выясняет, не превышает ли число уникальных значений в столбцах 50%, и если это так, преобразует их в тип category.
converted_obj = pd.DataFrame()
for col in gl_obj.columns:
num_unique_values = len(gl_obj[col].unique())
num_total_values = len(gl_obj[col])
if num_unique_values / num_total_values < 0.5:
converted_obj.loc[:,col] = gl_obj[col].astype('category')
else:
converted_obj.loc[:,col] = gl_obj[col]
Теперь сравним то, что получилось после оптимизации, с тем, что было раньше:
print(mem_usage(gl_obj))
print(mem_usage(converted_obj))
compare_obj = pd.concat([gl_obj.dtypes,converted_obj.dtypes],axis=1)
compare_obj.columns = ['before','after']
compare_obj.apply(pd.Series.value_counts)
Получим следующее:
752.72 MB
51.67 MB
| До |
После |
|
| object |
78.0 |
NaN |
| category |
NaN |
78.0 |
В нашем случае все обрабатываемые столбцы были преобразованы к типу category, однако нельзя говорить о том, что то же самое произойдёт при обработке любого набора данных, поэтому, обрабатывая по этой методике свои данные, не забывайте о сравнениях того, что было до оптимизации, с тем, что получилось после её выполнения.
Как видно, объём памяти, необходимый для работы со столбцами, хранящими данные типа object, снизился с 752 мегабайт до 52 мегабайт, то есть на 93%. Теперь давайте посмотрим на то, как нам удалось оптимизировать потребление памяти по всему набору данных. Проанализируем то, на какой уровень использования памяти мы вышли, если сравнить то, что получилось, с исходным показателем в 891 мегабайт.
optimized_gl[converted_obj.columns] = converted_obj
mem_usage(optimized_gl)
Вот что у нас получилось:
'103.64 MB'
Результат впечатляет. Но мы ещё можем кое-что улучшить. Как было показано выше, в нашей таблице имеются данные типа datetime, столбец, хранящий которые, можно использовать в качестве первого столбца набора данных.
date = optimized_gl.date
print(mem_usage(date))
date.head()
В плане использования памяти здесь получается следующее:
0.66 MB
Вот сводка по данным:
0 18710504
1 18710505
2 18710506
3 18710508
4 18710509
Name: date, dtype: uint32
Можно вспомнить, что исходные данные были представлены в целочисленном виде и уже оптимизированы с использованием типа uint32. Из-за этого преобразование этих данных в тип datetime приведёт к удвоению потребления памяти, так как этот тип использует для хранения данных 64 бита. Однако в преобразовании данных к типу datetime, всё равно, есть смысл, так как это позволит нам легче выполнять анализ временных рядов.
Преобразование выполняется с использованием функции to_datetime(), параметр format которой указывает на то, что данные хранятся в формате YYYY-MM-DD.
optimized_gl['date'] = pd.to_datetime(date,format='%Y%m%d')
print(mem_usage(optimized_gl))
optimized_gl.date.head()
В результате получается следующее:
104.29 MB
Данные теперь выглядят так:
0 1871-05-04
1 1871-05-05
2 1871-05-06
3 1871-05-08
4 1871-05-09
Name: date, dtype: datetime64[ns]
Выбор типов при загрузке данных
До сих пор мы исследовали способы уменьшения потребления памяти существующим объектом DataFrame. Мы сначала считывали данные в их исходном виде, затем, пошагово, занимались их оптимизацией, сравнивая то, что получилось, с тем, что было. Это позволило как следует разобраться с тем, чего можно ожидать от тех или иных оптимизаций. Как уже было сказано, часто для представления всех значений, входящих в некий набор данных, может попросту не хватить памяти. В связи с этим возникает вопрос о том, как применить методики экономии памяти в том случае, если нельзя даже создать объект DataFrame, который предполагается оптимизировать.
К счастью, оптимальные типы данных для отдельных столбцов можно указать ещё до фактической загрузки данных. Функция pandas.read_csv () имеет несколько параметров, позволяющих это сделать. Так, параметр dtype принимает словарь, в котором присутствуют, в виде ключей, строковые имена столбцов, и в виде значений — типы NumPy.
Для того чтобы воспользоваться этой методикой, мы сохраним итоговые типы всех столбцов в словаре с ключами, представленными именами столбцов. Но для начала уберём столбец с датой проведения игры, так как его нужно обрабатывать отдельно.
dtypes = optimized_gl.drop('date',axis=1).dtypes
dtypes_col = dtypes.index
dtypes_type = [i.name for i in dtypes.values]
column_types = dict(zip(dtypes_col, dtypes_type))
# вместо вывода всех 161 элементов, мы
# возьмём 10 пар ключ/значение из словаря
# и аккуратно их выведем
preview = first2pairs = {key:value for key,value in list(column_types.items())[:10]}
import pprint
pp = pp = pprint.PrettyPrinter(indent=4)
pp.pprint(preview)
Вот что у нас получится:
{ 'acquisition_info': 'category',
'h_caught_stealing': 'float32',
'h_player_1_name': 'category',
'h_player_9_name': 'category',
'v_assists': 'float32',
'v_first_catcher_interference': 'float32',
'v_grounded_into_double': 'float32',
'v_player_1_id': 'category',
'v_player_3_id': 'category',
'v_player_5_id': 'category'}
Теперь мы сможем воспользоваться этим словарём вместе с несколькими параметрами, касающимися данных о датах проведения игр, в ходе загрузки данных.
Соответствующий код получается довольно-таки компактным:
read_and_optimized = pd.read_csv('game_logs.csv',dtype=column_types,parse_dates=['date'],infer_datetime_format=True)
print(mem_usage(read_and_optimized))
read_and_optimized.head()
В результате объём использования памяти выглядит так:
104.28 MB
Данные теперь выглядят так, как показано на листе Фрагмент оптимизированного набора данных в этой таблице.
Внешне таблицы, приведённые на листах Фрагмент оптимизированного набора данных и Фрагмент исходного набора данных, за исключением столбца с датами, выглядят одинаково, но это касается лишь их внешнего вида. Благодаря оптимизации использования памяти в pandas нам удалось снизить потребление памяти с 861.6 Мбайт до 104.28 Мбайт, получив впечатляющий результат экономии 88% памяти.
Анализ бейсбольных матчей
Теперь, после того, как мы оптимизировали данные, мы можем заняться их анализом. Взглянем на распределение игровых дней.
optimized_gl['year'] = optimized_gl.date.dt.year
games_per_day = optimized_gl.pivot_table(index='year',columns='day_of_week',values='date',aggfunc=len)
games_per_day = games_per_day.divide(games_per_day.sum(axis=1),axis=0)
ax = games_per_day.plot(kind='area',stacked='true')
ax.legend(loc='upper right')
ax.set_ylim(0,1)
plt.show()

Дни, в которые проводились игры
Как видно, до 1920-х годов игры редко проводились по воскресеньям, после чего, примерно в течение 50 лет, игры в этот день постепенно проводились всё чаще.
Кроме того, можно заметить, что распределение дней недели, в которые проводились игры последние 50 лет, является практически неизменным.
Теперь взглянем на то, как со временем менялась длительность игр.
game_lengths = optimized_gl.pivot_table(index='year', values='length_minutes')
game_lengths.reset_index().plot.scatter('year','length_minutes')
plt.show()
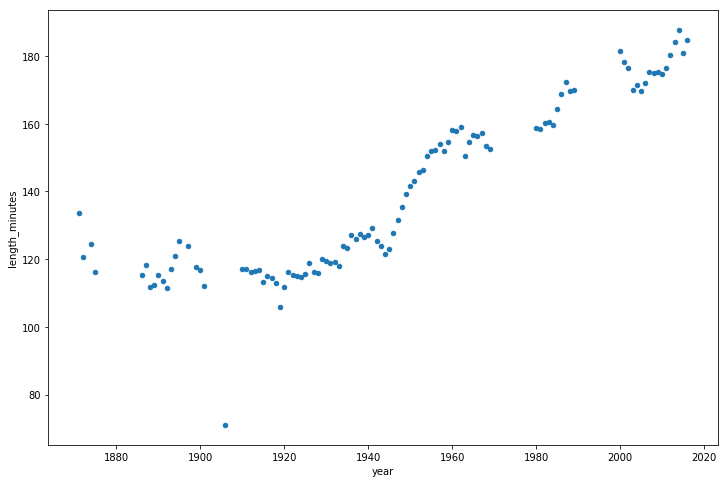
Длительность игр
Возникает такое ощущение, что с 1940-х годов по настоящее время матчи становятся всё более длительными.
Итоги
В этом материале мы обсудили особенности хранения данных разных типов в pandas, после чего воспользовались полученными знаниями для уменьшения объёма памяти, необходимого для хранения объекта DataFrame, почти на 90%. Для этого мы применили две простые методики:
- Мы произвели нисходящее преобразование типов числовых данных, хранящихся в столбцах, выбрав более эффективные, в плане использования памяти, типы.
- Мы преобразовали строковые данные к категориальному типу данных.
Нельзя сказать, что оптимизация любого набора данных способна привести к столь же впечатляющим результатам, но, особенно учитывая возможность выполнения оптимизации на этапе загрузки данных, можно говорить о том, что любому, кто занимается анализом данных с помощью pandas, полезно владеть методиками работы, которые мы здесь обсудили.
Уважаемые читатели! Перевести эту статью нам порекомендовал наш читатель eugene_bb. Если вам известны какие-нибудь интересные материалы, которые стоит перевести — расскажите нам о них.

