[Перевод] Руководство для начинающих: Масштабирование приложений на Ruby до 1000 rpm
Мы в 1cloud занимаемся построением облачного сервиса — наши пользователи могут заказывать у нас виртуальные серверы, и очень часто на них запускаются различные приложения. И периодически у компаний, разрабатывающих такие приложения, возникают проблемы с их масштабированием. Избежать распространенных ошибок при масштабировании приложений поможет руководство «для начинающих» от эксперта по Ruby Нейта Беркопеца (Nate Berkopec) — мы представляем вашему вниманию адаптированный перевод заметки.
Примечание: Это технически сложный текст, так что если вы заметите ошибку или неточность перевода — напишите нам, и мы все поправим, чтобы сделать материал лучше.
Большинство инструментов для масштабирования приложений на Ruby было разработано компаниями, которым приходится обрабатывать по несколько сотен запросов в секунду. Как же проводить масштабирование всем остальным?
Масштабирование — тема достаточно острая. Блоги и другие интернет-ресурсы о масштабировании приложений на Ruby обычно ориентированы на обработку нескольких тысяч запросов в минуту. Читать о масштабировании, например, Twitter и Shopify, конечно, интересно, так как важно представлять, какого предела может достичь приложение на Ruby. Однако это не так актуально для большинства разработчиков, в распоряжении которых имеется лишь от одного до ста серверов.
Рассмотрим руководство по масштабированию «для начинающих».
Итак, большинство инструментов для масштабирования, имеющихся у разработчиков приложений на Ruby, совершенно не удовлетворяют их потребностям. Методы, использованные компанией Twitter для перехода с 10 на 600 запросов в секунду, не подойдут для перевода приложения с 10 на 1000 запросов в минуту.
У чрезмерного масштабирования имеется ряд отдельных проблем: в частности, возникает проблема с вводом/выводом в базе данных, так как приложения чаще всего масштабируются горизонтально (увеличивая количество процессов и машин), в то время как базы данных масштабируются вертикально (увеличивая мощности обработки и размер оперативной памяти). Все это усложняет процесс масштабирования для многих разработчиков приложений на Rails.
Так когда же нужно расширяться, а когда — нет?
Раз уж я ограничился обсуждением обработки 1000 и менее запросов в минуту, то вот о чем я не буду рассказывать: масштабирование базы данных или других хранилищ данных вроде Memcached или Redis, использование высокопроизводительных очередей сообщений вроде RabbitMQ или Kafka, а также распределение объектов. Кроме того, в этом посте я не буду говорить о том, как сократить время отклика, не-смотря на то, что это было бы полезно знать для проведения масштабирования.
Также я не буду рассказывать о DevOps и обо всем, что выходит за рамки вашего сервера приложений (Unicorn, Puma и т. д.). Во-первых, как ни странно, на протяжении всей своей профессиональной карьеры я занимался развертыванием приложений на платформе Heroku, так что у меня нет опыта масштабирования нестандартных решений (постороенных на Docker, Chef и т. п.) на других платформах. Во-вторых, когда ваше приложение обрабатывает менее 1000 запросов в минуту, рабочие процессы DevOps не должны быть чересчур специализированными. Весь материал этого поста применим к любым приложениям на Ruby вне зависимости от используемых решений в DevOps.
Я работаю с небольшими стартапами, которые обрабатывают менее 1000 запросов в минуту. Как правило, это отдельные разработчики или члены небольшой команды. В таких малых группах платформа Heroku, на мой взгляд, как нельзя лучше подойдет для проведения масштабирования.
Во время работы консультантом я сталкивался с разными приложениями на Ruby, и в большинстве из них было проведено чрезмерное масштабирование, на которое зря тратились деньги.
Dyno-слайдеры Heroku и многие сервисы AWS упрощают весь процесс, делая его доступным, даже когда это не нужно. Многие разработчики на Rails считают, что масштабирование Dyno (динамических контейнеров) или увеличение числа своих экземпляров сделает их приложение быстрее.
Когда они видят, что их приложение работает медленно, они сразу начинают проводить масштабирование контейнеров Dyno или увеличивать число своих экземпляров (да и служба поддержки Heroku обычно всех к этому призывает: тратьте больше денег, и ваша проблема будет решена). Так или иначе, такой способ редко помогает им справиться с проблемой: их сайт продолжает работать медленно.
Ясно, что масштабирование контейнеров Dyno на Heroku не увеличит скорость работы вашего приложения, если в нем нет очередей запросов и частого ожидания (поясняется ниже). Даже контейнеры типа PX Dyno могут лишь увеличить надежность приложения, но никак не скорость его работы. Хотя смена типа экземпляра на AWS (к примеру, с T2 на M4) может повлиять на производительность экземпляров приложения.
Несколько слов о понятиях, используемых в данном посте. Хостом мы будем называть виртуальную или физическую хост-машину. На платформе Heroku хостом является Dyno. Иногда люди называют его сервером, но в данном посте я хочу, чтобы вы видели разницу между хост-машиной и сервером приложений, работающим на этой машине.
Один хост может запускать несколько серверов приложений, таких как Unicorn или Puma. На Heroku один хост может запускать только один сервер приложений. У сервера приложений есть несколько экземпляров приложения, которыми могут являться отдельные «worker» процессы (как, например, в Unicorn) или потоки (многопоточность сервера Puma, запущенного на JRuby).
В рамках этого поста многопоточный веб-сервер с одним экземпляром приложения на MRI (например, Puma) не является экземпляром приложения, так как потоки не могут исполняться одновременно. Таким образом, стандартная схема Heroku может включать в себя один хост/Dyno с одним сервером приложений (один главный процесс Puma) с 3–4 экземплярами приложения (кластерные worker-процессы Puma).
Масштабирование увеличивает производительность, не скорость. Масштабирование хостов сокращает время ожидания только в том случае, если существует очередь на обработку запросов к приложению. Если очередей не возникает, то все превращается в пустую трату денег.
Для того чтобы понять, как правильно масштабировать приложения на Ruby с одного до 1000 запросов в минуту, нам придется углубиться в принципы работы сервера приложений и маршрутизации HTTP.
Я буду использовать в качестве примера Heroku, хотя многие специализированные схемы DevOps работают похожим образом. Хотели узнать, какой была «сетка маршрутизации» или где именно образовалась очередь запросов перед их отправлением к серверу? Значит, сейчас узнаете.
Как запросы направляются к серверам приложений
Одно из главных решений, которое вам необходимо принять при масштабировании веб-приложения на Ruby, состоит в выборе сервера приложений. Так, большинство статей о масштабировании для Ruby уже устарели, потому что мир серверов приложений на Ruby сильно изменился за последние пять лет, и основные изменения произошли лишь в этом году.
Однако, для того чтобы узнать все преимущества и недостатки каждого сервера приложений, нам прежде всего нужно выяснить, как запросы к нему направляются.

«Так все-таки нагрузка на маршрутизаторы выравнивается Единорогами (Unicorns) или Пумами (Pumas)?»
Вполне объяснимо, почему многие разработчики не понимают, как именно производится маршрутизация запросов и образуются очереди. Это не так-то просто.
Вот что большинство программистов на Rails знает о работе Heroku:
- «Мне кажется, маршрут сменился на отрезке между стеками Bamboo и Cedar».
- «Когда-то давно полетел сайт RapGenius. Думаю, это произошло из-за некорректных сообщений об очередях запросов».
- «Мне нужно воспользоваться Unicorn. Хотя подождите, по-моему, Heroku подсказывает мне, что теперь нужно использовать Puma. Не знаю зачем».
- «Где-то здесь образовалась очередь из запросов. Не знаю, где именно».
Чтение документации Heroku по маршрутизации HTTP — уже хорошее начало, но она не объясняет всей картины. К примеру, не совсем понятно, почему Heroku рекомендует в качестве сервера приложений Unicorn или Puma.
Также не совсем ясно, где именно запросы «встают в очередь» и какие очереди важнее. Итак, давайте проследим движение запроса от начала до конца.
Движение запроса
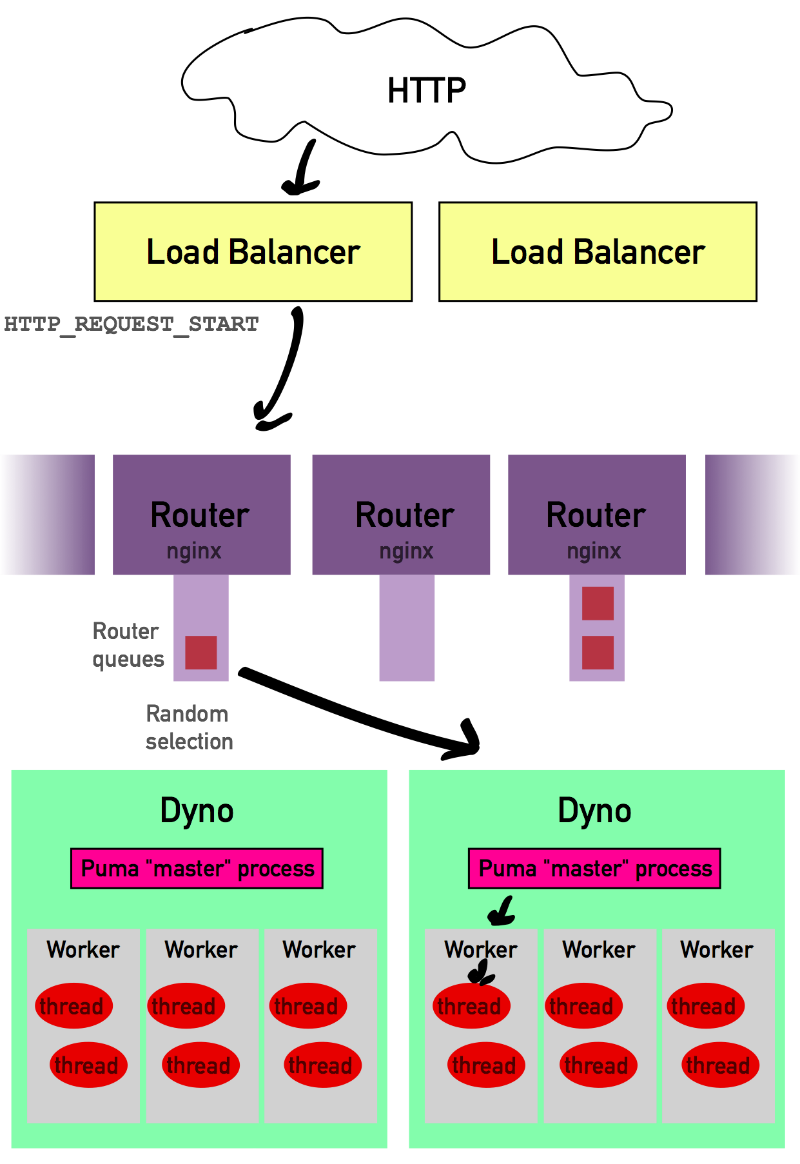
Когда запрос отправлен на yourapp.herokuapp.com, в первую очередь он проходит через балансировщик нагрузки. Задача этих балансировщиков нагрузки — обеспечить равное распределение нагрузки между маршрутизаторами Heroku, то есть они не делают ничего, кроме как решают, к какому маршрутизатору направить данный запрос.
Затем балансировщик нагрузки отправляет ваш запрос к тому маршрутизатору, который, по его мнению, подходит лучше всего (Heroku открыто не объясняет, как именно работают его балансировщики нагрузки и как они принимают эти решения).
Теперь запрос находится в маршрутизаторе Heroku. Количество имеющихся в Heroku маршрутизаторов не разглашается, но мы можем с уверенностью сказать, что их число достаточно велико (больше ста).
Задача маршрутизатора — найти контейнеры Dyno вашего приложения и передать в Dyno запрос. Затем после определения местоположения ваших контейнеров Dyno в течение 1–5 миллисекунд маршрутизатор пытается связаться со случайным Dyno в вашем приложении.
Да-да, со случайным. Именно здесь несколько лет назад на сайте RapGenius начались проблемы (тогда Heroku в лучшем случае не объяснял, а в худшем — дезинформировал нас о том, как маршрутизатор выбирает, в какой Dyno следует отправить ваш запрос).
После того, как Heroku случайным образом выбрал Dyno, он подождет не более пяти секунд, пока этот Dyno не примет запрос и не откроет соединение. Пока запрос находится в ожидании, его помещают в очередь маршрутизатора.
Однако у каждого маршрутизатора имеется своя очередь запросов, и раз Heroku не говорит нам, сколько у него маршрутизаторов, то число очередей маршрутизаторов для вашего приложения в данный момент времени может быть просто огромным.
Heroku начнет отбрасывать запросы из очереди, если она станет слишком длинной, а также попытается изолировать не отвечающие контейнеры Dyno (но, опять же, Heroku поступает так в рамках конкретного маршрутизатора, поэтому каждый его маршрутизатор в отдельности должен изолировать неработающие Dyno).
Весь этот процесс, по сути, описывает, как большинство инструментов для инициализации использует nginx. Иногда nginx играет роль и балансировщика нагрузки, и обратного прокси-сервера в подобных конфигурациях.
Все эти действия можно повторить с помощью особых конфигураций nginx, хотя вы, наверняка, захотите задать более «агрессивные» настройки. Вообще говоря, nginx может активно посылать health-check запросы на последующие серверы приложений, чтобы проверить, находятся ли они в рабочем состоянии. Однако определенные конфигурации nginx, как правило, имеют собственные очереди запросов.
Два очень важных замечания для пользователей Heroku: маршрутизатор будет ждать успешного подключения к вашему Dyno до пяти секунд, и, пока он ждет, другие запросы в очереди этого маршрутизатора будут также находится в ожидании.
Подключение к серверу — важность выбора сервера
Попытка маршрутизатора подключиться к серверу — это самый важный для вас этап, и дальнейшие события будут в значительной степени зависеть от выбора вашего веб-сервера. Вот что происходит дальше в зависимости от выбранного вами сервера.Webrick (по умолчанию поставляется с Rails)
Webrick — это однопоточный, однопроцессный веб-сервер. Он будет поддерживать соединение маршрутизатора открытым до тех пор, пока полностью не загрузит запрос с маршрутизатора.
Затем маршрутизатор перейдет к следующему запросу. После этого ваш сервер Webrick примет этот запрос, запустит код вашего приложения и затем отправит ответ маршрутизатору.
Все это время ваш хост будет загружен и не будет принимать подключения от других маршрутизаторов. Если маршрутизатор пытается подключится к этому хосту, пока обрабатывается запрос, то ему придется подождать (на Heroku до пяти секунд), пока хост не освободится.
Пока маршрутизатор находится в ожидании, он не будет пытаться подключиться к другим Dyno. Проблемы, возникающие при работе с Webrick, усугубляются медленными запросами и загрузкой файлов на сервер.
Если кто-то пытается выгрузить видео своего кота в формате HD с расширением 4K с помощью модема 56K, то вам не повезло: Webrick будет находиться в ожидании, пока этот файл загружается, и ничего не сможет с этим поделать.
Пользователь работает с 3G-смартфона? Это плохо: Webrick будет находится в ожидании и не примет других запросов, пока чрезвычайно медленный запрос этого пользователя не будет обработан до конца.
Webrick неудачно обрабатывает медленные запросы клиентов и медленные отклики приложения.
Thin
Thin — это событийно управляемый однопроцессный веб-сервер. Можно запустить несколько серверов Thin на одном хосте, однако все они должны «прослушивать» несколько разных сокетов, а не один, как, например, в случае с Unicorn. Из-за этого такая конфигурация не совместима с Heroku.
Thin использует движок EventMachine (иногда этот процесс называют Evented I/O, принцип его работы схож с Node.js), который в теории дает вам несколько преимуществ. Thin открывает соединение с маршрутизатором и начинает принимать запрос по частям.
Однако здесь возникает проблема: если вдруг этот запрос начинает обрабатываться медленнее или данные перестают передаваться по сокету, Thin разорвет соединение и будет выполнять другую операцию.
Таким образом, Thin защищен от медленных клиентов, так как вне зависимости от того, как медленно работает этот клиент, Thin может прервать с ним соединение и создать в это время другое соединение с другим маршрутизатором.
Только когда запрос будет загружен полностью, Thin передаст ваш запрос в приложение. Интересно, что даже довольно крупные запросы (например, выгрузка файла) Thin записывает во временный файл на диске.
Thin многопоточный, но не многозадачный, и его потоки передаются в MRI по одному. Поэтому при фактическом запуске вашего приложения ваш хост становится недоступным, в связи с чем возникает ряд негативных последствий, описанных в предыдущем разделе о сервере Webrick. Если вы не владеете всеми тонкостями работы с EventMachine, то Thin не сможет принять другие запросы, пока ожидает завер-шения операций ввода/вывода.
Например, если ваше приложение отправляет POST запрос в платежную систему для авторизации кредитной карты, Thin по умолчанию не сможет принять новые запросы, пока не завершит операцию. Фактически вам понадобилось бы перестроить код сво-его приложения, для того чтобы отправить события обратно в EventMachine и сказать серверу Thin: «Слушай, я все еще жду, пока завершится операция ввода/вывода, сделай что-нибудь другое». Подробнее о том, как это работает, можно узнать здесь.
Thin хорошо отрабатывает ситуации с медленными запросами, но при этом пасует перед медленными ответами приложения или операциями ввода/вывода без дополнительных доработок.
Unicorn
Unicorn — однопоточный, многозадачный веб-сервер. Unicorn порождает несколько «worker процессов» (экземпляров приложения), и эти процессы «прослушивают» один сокет Unix, регулируемый главным процессом.
Когда с хоста поступает запрос на подключение, он идет не через главный процесс, а напрямую к сокету Unicorn, где его ожидают и «прослушивают» рабочие процессы. Это главная особенность Unicorn: никакой другой веб-сервер (из тех, что я знаю) не использует сокет домена Unix в качестве «рабочего хранилища» без вмешательства главного процесса.
Рабочий процесс (который всего лишь «прослушивает» сокет, так как в данный момент он не обрабатывает запрос) принимает запрос от сокета. Этот запрос находится в сокете до тех пор, пока не загрузится полностью (ничего не настораживает?), и затем прекращает прослушивание сокета, чтобы перейти к обработке запроса. После того, как запрос обработан и ответ отправлен, он снова начинает «прослушивать» сокет.
Unicorn чувствителен к медленным клиентам так же, как и Webrick: во время загрузки запроса из сокета worker-процессы Unicorn не могут принимать новые соединения, а сам процесс становится недоступным.
В принципе вы можете обработать лишь столько медленных запросов, сколько worker«ов имеется на вашем сервере Unicorn. Если у вас есть три worker«а и четыре медленных запроса, на загрузку каждого из которых уходит 1000 миллисекунд, четвертому запросу необходимо будет подождать, пока не обработаются другие запросы.
Этот метод иногда называют многозадачной блокировкой операции ввода/вывода. Таким образом, Unicorn может справиться с медленными откликами приложения (так как свободные worker«ы все еще могут принимать подключения, пока другой worker находится в режиме ожидания), но лишь с небольшим их количеством.
Обратите внимание, что модель работы Unicorn, основанная на сокетах, представляет собой одну из форм интеллектуальной маршрутизации, потому что только доступные экземпляры приложений будут принимать запросы от сокета.
Для избежания проблем с медленными клиентами путем буферизации запросов, в нестандартных решениях может использоваться nginx. Именно этим и занимается Passenger.
Phusion Passenger 5
Passenger использует гибридную модель ввода/вывода: этот инструмент, подобно Unicorn, имеет многозадачную структуру на основе worker«ов, но также включает в себя обратный буферный прокси-сервер.
Это важный момент. Работа Passenger, в некоторой степени, напоминает nginx, стоящего перед worker«ми вашего приложения. Кроме того, если вы приобретете вер-сию Passenger Enterprise, вы сможете запускать по несколько потоков приложения на каждом worker«е (как Puma, описанный ниже).
Чтобы понять, насколько важен встроенный в Phusion Passenger 5 обратный прокси-сервер (специальный экземпляр nginx, написанный на C++, не на Ruby), попытаемся отследить движение запроса к серверу Passenger. Вместо того, чтобы использовать сокеты, маршрутизатор Heroku напрямую подключается к nginx и отправляет на него запрос.
Этот nginx представляет собой специально оптимизированную сборку с множеством нестандартных функций, которые значительно повышают его эффективность при работе с веб-приложениями на Ruby. Перед тем, как отправить запрос на следующий этап, nginx должен загрузить его полностью, защищая таким образом ваши рабочие процессы от медленных загрузок и других медленных клиентов.
По завершении загрузки запроса nginx передает его в процесс HelperAgent, определяющий, какой worker должен обрабатывать данный запрос. Passenger 5 может работать и с медленными откликами приложения (так как его HelperAgent будет направлять запросы в неиспользуемые worker’ы), и с медленными клиентами (так как он запускает свой экземпляр nginx, который копирует их в буфер).
Puma (в потоковом режиме)
В стандартном режиме работы Puma является многопоточным, однопроцессным сервером.
Когда приложение подключается к вашему хосту, оно устанавливает связь с похожим на EventMachine потоком Reactor, который отвечает за загрузку запроса и может асинхронно ожидать, пока медленные клиенты не отправят весь запрос (так же, как в случае с Thin).
После загрузки запроса Reactor порождает новый Thread (поток), который взаимодействует с кодом вашего приложения и обрабатывает ваш запрос. Вы можете указать максимальное число потоков Thread в приложении, которые можно запустить в каждый отдельный момент времени.
Опять же, в данной конфигурации Puma является многопоточным, но не многозадачным веб-сервером, а в единицу времени выполняется только один поток на MRI Ruby. Особенность Puma заключается в том, что, в отличие от Thin, вам не нужно перестраивать код вашего приложения, чтобы получить пользу от многопоточности. Puma автоматически передает управление обратно worker«у, когда поток приложения находится в режиме ожидания ввода/вывода.
Если, к примеру, ваше приложение ожидает HTTP-отклика от провайдера платежного сервиса, Puma все еще может принимать запросы в поток Reactor или даже завершать исполнение других запросов в различных потоках приложения. Поэтому, несмотря на то, что Puma может обеспечить высокий рост производительности во время ожидания операции ввода/вывода (например, при запросах к базам данных и сетевых запросах) при запущенном приложении, ваш хост становится недоступным в процессе обработки запроса, что приводит к негативным последствиям, описанным выше в разделе о сервере Webrick.
Puma (в потоковом режиме) может справиться с запросами медленных клиентов, но не может справиться с медленными откликами приложения, ограниченного работой процессора.
Puma (в кластерном режиме)
У Puma также есть «кластерный» режим, который представляет собой комбинацию его многопоточной модели и многозадачной модели Unicorn.
В кластерном режиме маршрутизаторы Heroku соединяются с «главным процессом» сервера Puma, который в сущности является потоком Reactor из приведенного выше примера Puma. Reactor главного worker«а загружает и копирует в буфер входящие запросы, а затем передает их на любой доступный worker Puma, слушающий сокет (подобно Unicorn). В данном режиме Puma может работать с медленными запросами (благодаря отдельному главному процессу, который отвечает за загрузку и передачу запросов) и медленными откликами приложения (благодаря порождению нескольких рабочих процессов).
Что все это значит?
Итак, если вы читали внимательно, то, наверняка, заметили, что масштабируемое веб-приложение на Ruby требует защиты от медленного клиента в виде буферизации запроса и защиты от медленного отклика в виде определенного типа параллелизма — либо многопоточности, либо многозадачности/разветвления (желательно и то, и другое).
В этом случае только Puma в кластерном режиме и Phusion Passenger 5 могут считаться масштабируемыми решениями для приложений Ruby на платформе Heroku, работающей на базе MRI/C Ruby. При использовании нестандартных решений, вполне подойдет Unicorn, в связке с nginx.
Все веб-серверы по-разному говорят о своей «скорости» — я бы не стал обращать на это слишком много внимания. Все они могут обработать несколько тысяч запросов в минуту, то есть на обработку запроса фактически им требуется меньше 1 миллисе-кунды.
Если Puma быстрее, чем Unicorn, на 0,001 миллисекунды, это, конечно, здорово, но это никак вам не поможет, если вашему приложению на Ruby требуется в среднем 100 миллисекунд на обработку запроса. Главным отличием между серверами приложений на Ruby является не скорость, а их различия в моделях ввода/вывода и их характеристиках.
Как я говорил ранее, я считаю, что Puma в кластерном режиме и Phusion Passenger 5 — единственные по-настоящему мощные веб-серверы для масштабирования приложений на Ruby, потому что их модели ввода/вывода отлично справляются с медленными клиентами и медленными приложениями. Оба они сильно отличаются функциональностью, причем Phusion предлагает корпоративную поддержку Passenger, поэтому для того, чтобы выяснить, какой сервер подходит лично вам, придется провести полное сравнение их функциональности.
Что значит «время ожидания»?
Как ясно из описанного выше, у нас имеется не одна «очередь запросов». На самом деле ваше приложение может взаимодействовать с сотнями «очередей».
Вот несколько мест, где запросы могут «образовать очередь»:
- В балансировщике нагрузки, что происходит довольно редко, так как балансировщик нагрузки настроен на быструю работу (всего около 10 очередей)
- В любом из более чем ста маршрутизаторов Heroku. Помните, что в каждом маршрутизаторе образуются отдельные очереди (всего более 100 очередей)
- Если используется многопроцессный сервер, такой как Unicorn, Puma или, в против-ном случае, Phusion Passenger, то очереди могут образовываться в «главном процессе» или где-то внутри хоста (по одной очереди в хосте).
Так как же New Relic узнает о времени ожидания в очереди?
Вообще говоря, именно так и полетел сайт RapGenius.
В 2013 году сайт RapGenius перестал работать, когда сотрудники компании обнаружили, что «интеллектуальная маршрутизация» на самом деле не такая уж и интеллектуальная: как оказалось, она производилась абсолютно случайным образом.
Когда Heroku переходил со стека Bamboo на Cedar, они также изменили инфраструктуру балансировщика нагрузки/маршрутизатора для обоих — и для стека Bamboo, и для Cedar. Поэтому приложения стека Bamboo, в числе которых был и RapGenius, внезапно начали проводить случайную маршрутизацию вместо интеллектуальной.
Под интеллектуальной маршрутизацией мы имеем ввиду что-то получше чистой случайной маршрутизации. Обычно суть интеллектуальной маршрутизации заключается в активной проверке соединения с вышестоящими серверами приложений, позволяя определить, доступны ли они для принятия нового запроса. Такой подход снижает время ожидания.
Что еще хуже, инфраструктура Heroku продолжала сообщать о том, что она проводит интеллектуальную маршрутизацию (с единственной очередью запросов, а не одной очередью на маршрутизатор). Heroku сообщал время ожидания в очереди на New Relic в виде заголовка HTTP, и оно записывалось как «общее время ожидания».
Этот заголовок сообщал лишь время, в течение которого данный запрос находился в очереди маршрутизатора. Данный показатель, учитывая сотни маршрутизаторов, мог быть чрезвычайно низким, хотя нагрузка на хост была!
Представьте, что Heroku подключается к главному сокету Unicorn и передает запрос на этот сокет. Теперь этот запрос проведет на сокете 500 миллисекунд, ожидая, когда его «подберет» рабочий процесс приложения. В описанном выше случае данные 500 миллисекунд не будут учтены, так как в NewRelic передавалось только время, проведенное в очереди маршрутизатора.
По состоянию на сегодняшний день, New Relic считает время ожидания на основании заголовка HTTP REQUEST_START, который ему приходит от Heroku. Этот заголовок отмечает тот момент, когда Heroku принял запрос в балансировщик нагрузки. Чтобы вычислить время ожидания, New Relic берет лишь разницу между моментом, когда worker вашего приложения начал обрабатывать запрос, и значением REQUEST_START.
Таким образом, если значение REQUEST_START равно 12:00:00, и ваше приложение начало обрабатывать запрос только в 12:00:00,010, то New Relic сообщает о том, что время ожидания составляет 10 миллисекунд. Радует, что здесь учитывается время на каждом из уровней: время в балансировщике нагрузки, время в маршрутизаторах Heroku и время ожидания в хосте (независимо от того, где находится запрос — в главном процессе Puma, рабочем сокете Unicorn или где-то еще).
Естественно, что, установив подходящие заголовки на своем экземпляре nginx/apache, вы можете получить точное время ожидания запроса для нестандартных решений.
Когда нужно масштабировать экземпляры приложений?
Не масштабируйте свое приложение только на основании времени его отклика. Скорость работы вашего приложения может снижаться из-за большого времени ожидания в очереди, а может и не из-за него.
Если ваши запросы не образуют очередь, а вы проводите масштабирование хостов, вы попросту зря тратите свои деньги. Перед тем, как проводить масштабирование, проверьте время, проведенное запросом в очереди.
То же относится и к хостам worker«ов. Их масштабирование следует проводить лишь на основании глубины очереди ваших заданий. Если в очереди нет ни одного задания, проводить масштабирование хостов worker«ов бессмысленно.
На деле ваши рабочие Dyno и Web-Dyno ничем не отличаются: у каждого из них есть входящие задания или запросы, которые им нужно обработать, и их следует масштабировать на основании числа заданий, ожидающих своей обработки.
New Relic сообщает время, проведенное запросом в очереди, однако для этих целей есть также несколько сторонних библиотек, которые могут помочь вам измерить его самостоятельно.
Если вы тратите не так много времени (время отклика вашего сервера в среднем составляет не более 5–10 миллисекунд) в очереди запросов, то пользы от масштабирования будет немного.
Количество контейнеров Dyno должно подчиняться закону Литтла
Обычно я встречаюсь с излишним масштабированием приложений, когда разработчик не понимает, сколько запросов его сервер может обработать в секунду. Он не представляет «сколько запросов в минуту соответствует скольким Dyno».
Я уже говорил о том, как можно это рассчитать на практике — путем измерения и реагирования на изменения времени ожидания в очереди. Но, помимо этого, мы можем воспользоваться таким теоретическим инструментом, как закон Литтла. В Википедии его описание будет понятно не каждому, поэтому я несколько изменил его формулировку:
Число необходимых экземпляров приложения = Среднее число запросов в секунду * Среднее время отклика (в секундах)
Для начала несколько пояснений. Как упоминалось выше, экземпляр приложения — это неделимая часть вашей системы. Его задача состоит в обработке отдельного запроса и его отправке обратно клиенту.
Когда вы используете Webrick, экземпляром вашего приложения является весь процесс Webrick. Когда вы используете Puma в потоковом режиме, вместе с MRI, экземпляром вашего приложения будет весь процесс Puma.
В случае с JRuby, экземпляром приложения считается каждый поток. При работе с Unicorn, Puma (кластерный режим) или Passenger, экземпляром вашего приложения является каждый «worker».
На самом деле многопоточный процесс Puma на MRI следует считать за полтора экземпляра приложения, так как он может работать, находясь в ожидании операции ввода/вывода. Для простоты будем считать его одним.
Давайте проведем расчет для обычного приложения на Ruby с типичным решением — Unicorn. Будем считать, что каждый процесс Unicorn разветвлен на три worker«а. В итоге наше приложение с одним сервером имеет три экземпляра.
Если это приложение принимает по одному запросу в секунду, а среднее время отклика сервера составляет 300 миллисекунд, то для того, чтобы справиться с нагрузкой, потребуется 1×0,3 = 0,3 экземпляра приложений.
В данном случае получается, что мы используем лишь 10% доступной мощности сервера. Какова же максимальная теоретическая производительность нашего приложения? Стоит лишь заменить неизвестные в уравнении:
Максимальная производительность = Число экземпляров приложения / Среднее время отклика
Таким образом, в примере с нашим приложением максимальная теоретическая производительность составляет 3 / 0,3, или 10 запросов в секунду. Впечатляюще!
Но теория и практика не одно и то же. К сожалению, закон Литтла верен лишь в долгосрочной перспективе: это означает, что уравнение может оказаться неверным из-за таких факторов, как широкий разброс времени отклика сервера (обработка одних запросов может занять 0,1 секунды, обработка других — одну секунду) или широкий разброс времени поступления запроса. Но, тем не менее, это хороший «ориентир» для определения избыточного масштабирования.
Кроме того, стоит подумать о том, как эти условия повлияют на масштабирование. Вы можете получить максимум фактической производительности только в случае, если запросы достаточно близки к среднему значению. Масштабировать стоит лишь приложение с предсказуемым временем отклика.
Вы можете получить еще более точные результаты, исходя из закона Литтла, если вместо среднего времени отклика сервера вы возьмете 95-й перцентиль вашего времени отклика. Если время отклика вашего сервера непредсказуемо и сильно разнится, то ваша производительность будет в большей степени зависеть от самых медленных откликов.
Как снизить время отклика с 95-м перцентилем? Нужно активно передавать задачи в фоновые процессы, например, Sidekiq или DelayedJob.
Не забывайте, что масштабирование хостов не увеличивает время отклика сервера напрямую: оно может лишь увеличить число серверов, доступных для работы с вашими очередями запросов. Если среднее число запросов, ожидающих в очереди, меньше одного, то ваши серверы работают не на все 100%, и польза от масштабирования хостов мала (то есть меньше 100%).
Максимальную пользу можно получить лишь в том случае, когда в очереди всегда находится как минимум один запрос. Возможно, по некоторым причинам стоит начать масштабирование до этого момента, особенно если время отклика вашего сервера достаточно большое. Однако следует понимать, как быстро польза от таких действий может исчезнуть.
Поэтому когда расчитываете количество хостов, попробуйте провести расчет по закону Литтла. Если вы масштабируете хосты в тот момент, когда производительность находится на уровне 25% или меньше, то, согласно закону Литтла, вероятно вы начали масштабирование слишком рано.
С другой стороны, как упоминалось ранее, слишком большое время ожидания в очереди, измеренное с помощью New Relic, является признаком того, что пришла пора провести масштабирование хостов.
Проверка расчетов
В апреле 2007 года один из разработчиков Twitter выступил на SDForum в Кремниевой долине на тему того, как проводилось масштабирование Twitter. В то время Twitter полностью работал на Rails.
В этой презентации разработчик представил следующую статистику:
- 600 запросов в секунду
- 180 экземпляров приложения (в mongrel)
- Среднее время отклика сервера — около 300 миллисекунд
В теории выходит, что Twitter в 2007 году требовалось 600×0.3, или 180 экземпляров приложения. Так, судя по всему, и работало их приложение.
Twitter, работающий на 100% мощности, кажется гиблым делом — и у Twitter в то время действительно возникало много проблем с масштабированием. Вполне вероятно, что они не могли провести масштабирование до большего числа экземпляров из-за то
