[Перевод] RED: Улучшение качества звука с помощью резервирования

Еще в апреле 2020 года Citizenlab сообщил о довольно слабом шифровании Zoom и заявил, что Zoom использует аудиокодек SILK. К сожалению, статья не содержала исходных данных, чтобы это подтвердить и дать мне возможность обращаться к ней в дальнейшем. Однако благодаря Натали Сильванович из Google Project Zero и инструменту трассировки Frida я смог получить дамп некоторых необработанных кадров SILK. Их анализ вдохновил меня взглянуть на то, как WebRTC обрабатывает звук. Что касается восприятия качества вызова в целом, больше всего на него влияет качество звука, поскольку мы склонны замечать даже небольшие сбои. Всего десяти секунд анализа было достаточно, чтобы отправиться в настоящее приключение — на поиски возможных улучшений качества звука, обеспечиваемых WebRTC.
Я имел дело с нативным клиентом Zoom еще в 2017 году (до поста DataChannel) и обратил внимание, что его аудиопакеты иногда были очень большими в сравнении с пакетами решений на базе WebRTC:

На приведенном выше графике показано количество пакетов с определенной длиной полезной нагрузки UDP. Пакеты длиной от 150 до 300 байт — необычное явление, если сравнивать с типичным вызовом WebRTC. Они намного длиннее, чем пакеты, которые мы обычно получаем от Opus. Мы заподозрили наличие упреждающего контроля ошибок (FEC) или резервирования, но без доступа к незашифрованным кадрам было трудно сделать еще какие-то выводы или что-то предпринять.
Незашифрованные кадры SILK в новом дампе показали очень похожее распределение. После конвертации кадров в файл и последующего воспроизведения короткого сообщения (спасибо Джакомо Вакке за очень полезный пост в блоге, описывающий необходимые шаги) я вернулся в Wireshark и посмотрел на пакеты. Вот пример из трех пакетов, который мне показался особенно интересным:
packet 7:
e9e4ab17ad8b9b5176b1659995972ac9b63737f8aa4d83ffc3073d3037b452fe6e1ee
5e6e68e6bcd73adbd59d3d31ea5fdda955cbb7f
packet 8:
e790ba4908639115e02b457676ea75bfe50727bb1c44144d37f74756f90e1ab926ef
930a3ffc36c6a8e773a780202af790acfbd6a4dff79698ea2d96365271c3dff86ce6396
203453951f00065ec7d26a03420496f
packet 9:
e93997d503c0601e918d1445e5e985d2f57736614e7f1201711760e4772b020212dc
854000ac6a80fb9a5538741ddd2b5159070ebbf79d5d83363be59f10ef
e790ba4908639115e02b457676ea75bfe50727bb1c44144d37f74756f90e1ab926ef
930a3ffc36c6a8e773a780202af790acfbd6a4dff79698ea2d96365271c3dff86ce6396
203453951f00065ec7d26a03420496f
e9e4ab17ad8b9b5176b1659995972ac9b63737f8aa4d83ffc3073d3037b452fe6e1ee
5e6e68e6bcd73adbd59d3d31ea5fdda955cbaef
Пакет 9 содержит два предыдущих пакета, пакет 8 — 1 предыдущий пакет. Такая избыточность вызвана использованием формата LBRR — Low Bit-Rate Redundancy, как показало глубокое изучение декодера SILK (который можно найти в интернет-проекте, представленном командой Skype или в репозитории GitHub):

Zoom использует SKP_SILK_LBRR_VER1, но с двумя резервными пакетами. Если каждый UDP пакет содержит не только текущий аудиокадр, но и два предыдущих, он будет устойчивым, даже если вы потеряете два из трех пакетов. Так, может быть, ключ к качеству звука Zoom — это секретный рецепт бабушкиного Skype?
Opus FEC
Как добиться того же с помощью WebRTC? Следующим очевидным шагом было рассмотрение Opus FEC.
LBRR, низкоскоростное резервирование, от SILK, также есть и в Opus (помните, что Opus — это гибридный кодек, который использует SILK для нижнего конца диапазона битрейта). Тем не менее Opus SILK сильно отличается от оригинального SILK, исходный код которого когда-то открыл Skype, как и часть LBRR, которая используется в режиме контроля ошибок.
В Opus контроль ошибок не просто добавляется после исходного аудиокадра, он предшествует ему и кодируется в потоке битов. Мы пробовали экспериментировать с добавлением нашего собственного контроля ошибок с помощью Insertable Streams API, но это требовало полного перекодирования для вставки информации в битовый поток перед фактическим пакетом.
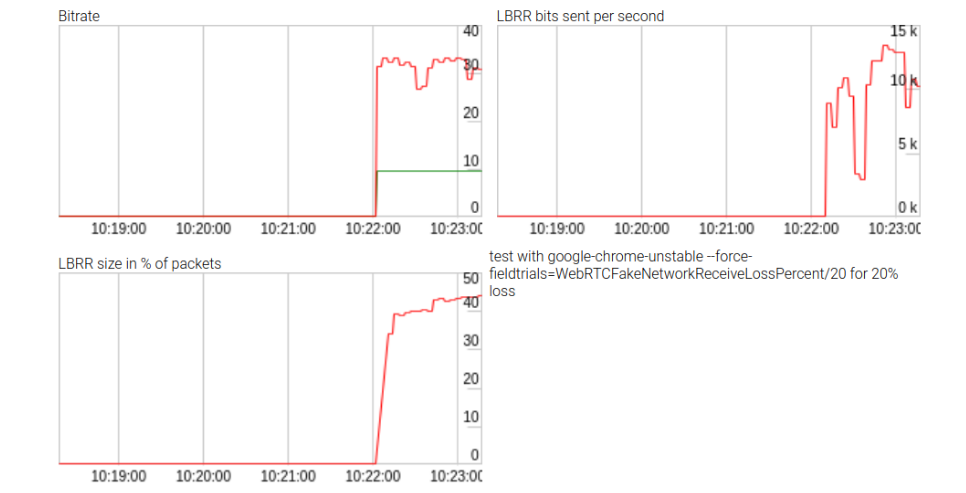
Хотя усилия и не увенчались успехом, они позволили собрать некоторые статистические данные о влиянии LBRR, которые продемонстрированы на рисунке выше. LBRR использует битрейт до 10 кбит/с (или две трети скорости передачи данных) при больших потерях пакетов. Репозиторий доступен по ссылке. Данная статистика не отображается при вызове WebRTC getStats()API, поэтому результаты оказались весьма занимательными.
Помимо проблемы с необходимостью перекодировки, Opus FEC в WebRTC, как выяснилось, настроен несколько бесполезно:
- Он активируется только при потере пакетов, а мы хотели бы, чтобы резервная информация хранилась и до возникновения каких-либо проблем. Ребята из Slack писали об этом еще в 2016 году. Это означает, что мы не можем включить его по умолчанию и защитить себя от случайных нерегулярных потерь.
- Объем прямого исправления ошибок ограничен 25%. Выше этого значения оно неэффективно.
- Битрейт для FEC вычитается из целевого максимального битрейта (см. здесь).
Вычитание битрейта FEC из целевого максимального битрейта совершенно не имеет смысла — FEC активно снижает битрейт основного потока. Поток с более низким битрейтом обычно приводит к снижению качества. Если нет потери пакетов, которую можно исправить с помощью FEC, то FEC только ухудшит качество, а не улучшит его. Почему так происходит? Основная теория состоит в том, что одной из причин потери пакетов является перегрузка. Если вы столкнулись с перегрузкой, вы не захотите отправлять больше данных, потому что это только усугубит проблему. Однако, как описывает Эмиль Ивов в своем замечательном выступлении на KrankyGeek от 2017 года, перегрузка не всегда является причиной потери пакетов. Кроме того, этот подход также игнорирует любые сопутствующие видеопотоки. Стратегия FEC на основе перегрузок для аудио Opus не имеет особого смысла, когда вы отправляете сотни килобит видео вместе с относительно небольшим потоком Opus со скоростью 50 кбит/с. Возможно, в будущем мы увидим какие-то изменения в libopus, а пока хотелось бы попробовать отключить его, ведь в настоящее время он включен в WebRTC по умолчанию.
Делаем вывод, что это не работает…
RED
Если нам нужно реальное резервирование, у RTP есть решение под названием RTP Payload for Redundant Audio Data, или RED. Оно довольно старое, RFC 2198 был написан в 1997 году. Решение позволяет помещать несколько полезных нагрузок RTP с различными временными метками в один и тот же RTP пакет при относительно небольших затратах.
Использование RED для помещения одного или двух резервных аудиокадров в каждый пакет дало бы гораздо большую устойчивость к потере пакетов, чем Opus FEC. Но это возможно лишь путем удвоения или утроения битрейта аудио с 30 кбит/с до 60 или 90 кбит/с (с дополнительными 10 кбит/с для заголовка). Хотя по сравнению с более чем 1 мегабитом видеоданных в секунду это не так уж плохо.
Библиотека WebRTC включала в себя второй кодер и декодер для RED, что теперь стало излишним! Несмотря на попытки удалить неиспользуемый audio-RED-code, мне удалось применить этот кодер, прилагая относительно небольшие усилия. Полная история решения есть в системе отслеживания багов WebRTC.
И оно доступно в виде пробной версии, включаемой при запуске Chrome со следующими флагами:
--force-fieldtrials=WebRTC-Audio-Red-For-Opus/Enabled/
Затем RED может быть включен через SDP согласование; он отобразится следующим образом:
a=rtpmap:someid red/48000/2
По умолчанию он не включен, поскольку есть среды, где использование дополнительной пропускной способности не очень хорошая идея. Чтобы использовать RED, измените порядок следования кодеков так, чтобы он был перед кодеком Opus. Это можно сделать, используя API RTCRtpTransceiver.setCodecPreferences, как показано здесь. Очевидно, что другой альтернативой является изменение SDP вручную. Формат SDP также мог бы обеспечить способ настройки максимального уровня резервирования, но семантика «предложение-ответ» в RFC 2198 была не до конца ясна, поэтому я решил отложить это на время.
Продемонстрировать, как это все работает можно с помощью запуска в аудиопримере. Так выглядит ранняя версия с одним пакетом резервирования:
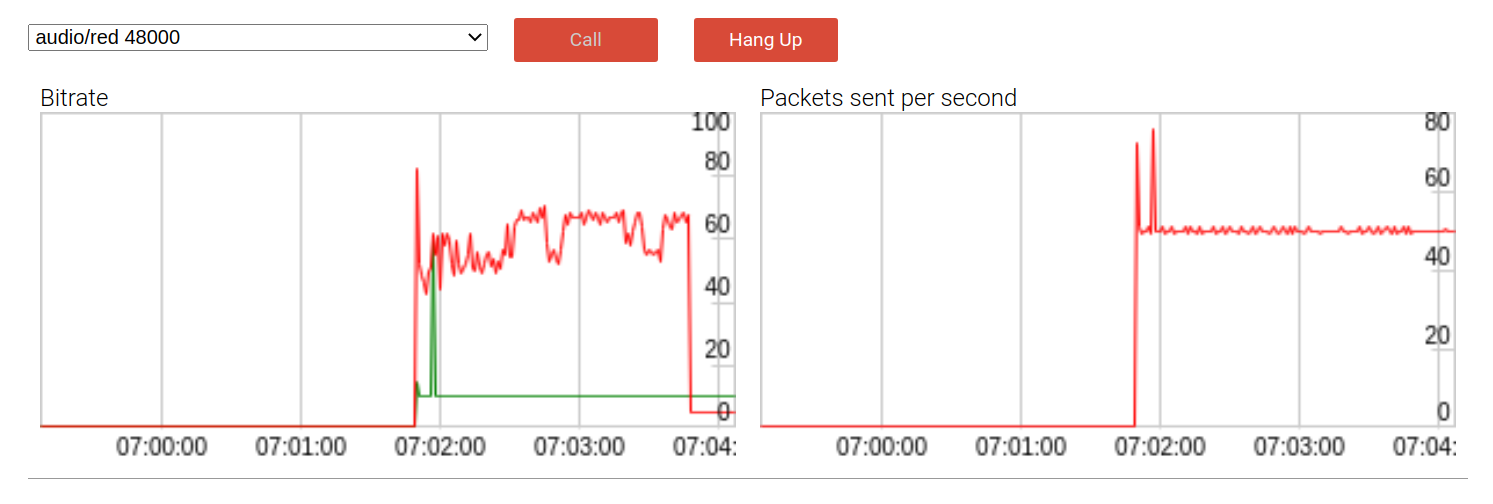
По умолчанию битрейт полезной нагрузки (красная линия) почти в два раза выше, чем без резервирования на скорости почти 60 кбит/сек. DTX (прерывистая передача) — это механизм сохранения пропускной способности, который посылает пакеты только при обнаружении голоса. Как и ожидалось, при использовании DTX влияние битрейта несколько смягчается, как мы видим в конце вызова.
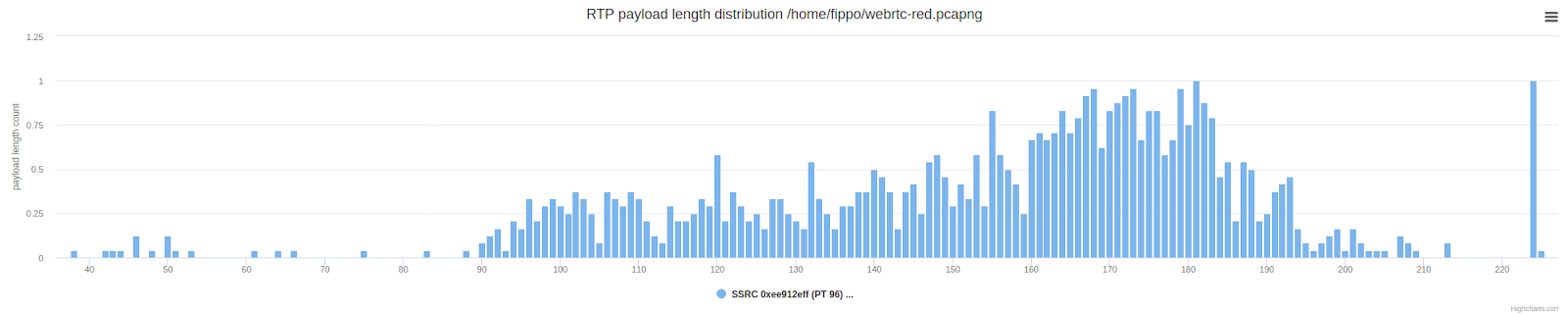
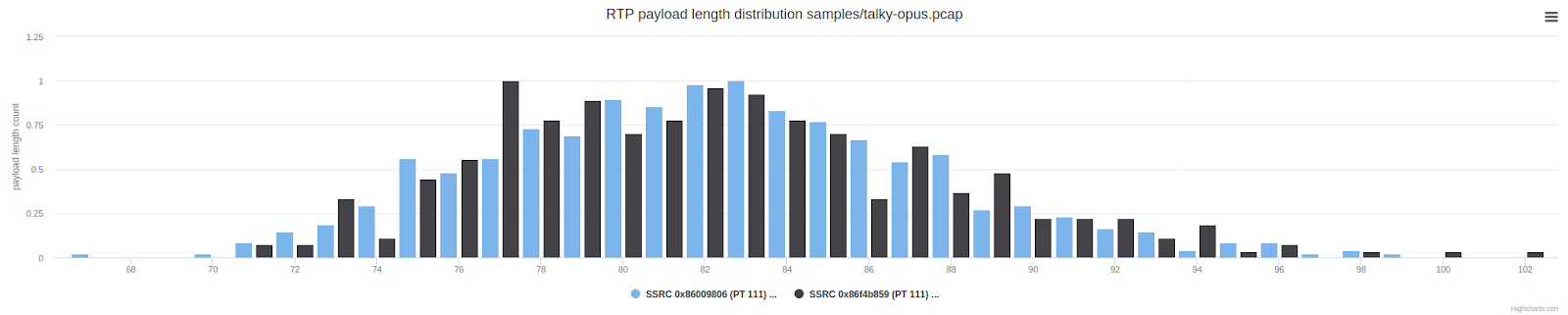
Проверка длины пакетов демонстрирует ожидаемый результат: пакеты в среднем в два раза длиннее (выше) по сравнению с нормальным распределением длины полезной нагрузки, показанным ниже.
Это все еще немного отличается от того, что делает Zoom, где мы наблюдали частичное резервирование. Давайте повторим график длины пакетов Zoom, приведенный ранее, чтобы посмотреть на них в сравнении:
Добавление поддержки обнаружения голосовой активности (VAD)
Opus FEC отправляет резервные данные только в том случае, если в пакете присутствует голосовая активность. То же самое должно быть применено и к реализации RED. Для этого кодировщик Opus должен быть изменён для отображения корректной информации о VAD, которая определяется на уровне SILK. При такой настройке битрейт достигает 60 кбит/с только при наличии речи (в сравнении с постоянными 60+ кбит/с):

и «спектр» становится больше похож на то, что мы видели у Zoom:

Изменение, позволяющее этого достичь, еще не появилось.
Поиск правильного расстояния
«Расстояние» — это количество резервных пакетов, то есть количество предыдущих пакетов в текущем. В процессе работы над поиском правильного расстояния мы обнаружили, что если RED с расстоянием 1 — это круто, то RED с расстоянием 2 — еще круче. Наша лабораторная оценка моделировала случайную потерю пакетов = 60%. В этой среде Opus + RED воспроизводил отличный звук, в то время как Opus без RED показывал себя сильно хуже. WebRTC getStats () API дает очень полезную возможность измерить это, сравнивая процент скрытых сэмплов, получаемый путем деления concealedSamples на totalSamplesReceived.
На странице аудиосэмплов эти данные легко получить с помощью данного фрагмента кода JavaScript, вставленного в консоль:
(await pc2.getReceivers()[0].getStats()).forEach(report => {
if(report.type === "track") console.log(report.concealmentEvents, report.concealedSamples, report.totalSamplesReceived, report.concealedSamples / report.totalSamplesReceived)})
Я провел пару тестов с потерей пакетов, используя не очень известный, но очень полезный флаг WebRTCFakeNetworkReceiveLossPercent:
--force-fieldtrials=WebRTC-Audio-Red-For-Opus/Enabled/WebRTCFakeNetworkReceiveLossPercent/20/
При 20% потерях пакетов и включенном по умолчанию FEC не было большой разницы в качестве звука, но была небольшая разница в метрике:
Без RED или FEC метрика почти совпадает с запрошенной потерей пакетов. Есть эффект от FEC, но он невелик.
Без RED при потере 60% качество звука стало довольно плохим, немного металлическим, а слова — трудными для понимания:
Были некоторые слышимые артефакты при RED с расстоянием = 1, но почти идеальный звук с расстоянием 2 (что является количеством избыточности, которое используется в настоящее время).
Есть ощущение, что человеческий мозг может выдержать какой-то определенный уровень тишины, возникающей нерегулярно. (А Google Duo, судя по всему, использует алгоритм машинного обучения, чтобы чем-то тишину заполнить).
Измерение производительности в реальном мире
Мы надеемся, что включение RED в Opus улучшит качество звука, хотя в отдельных случаях может сделать и хуже. Эмиль Ивов вызвался провести пару тестов прослушивания по методу POLQA-MOS. Это было сделано в прошлом для Opus, так что у нас есть исходные данные для сравнения.
Если первоначальные тесты покажут многообещающий результат, то мы проведем масштабный эксперимент на основной развертке Jitsi Meet, применяя процентные метрики потерь, которые мы использовали выше.
Обратите внимание, что для медиасерверов и SFU включение RED происходит немного сложнее, поскольку серверу может потребоваться управлять RED ретрансляцией для выбора клиентов, как в случае, если не у всех клиентов поддерживаются конференции RED. Также некоторые клиенты могут находиться на канале с ограниченной пропускной способностью, где RED не требуется. Если конечная точка не поддерживает RED, SFU может удалить ненужное кодирование и отправить Opus без обертки. Аналогичным образом он может реализовать сам RED и использовать его при повторной отправке пакетов от конечной точки, передающей Opus, на конечную точку, поддерживающую RED.
Большое спасибо Jitsi/8×8 Inc за спонсирование этого приключения и ребятам из Google, которые рассмотрели/предоставили фидбек о необходимых изменениях.
А без Натали Сильванович я бы так и застрял, глядя на зашифрованные байты!
