[Перевод] Разбираемся с алгоритмом коллапса волновой функции

После появления DeBroglie и Tessera меня много раз просили объяснить, как они работают. Генерирование может выглядеть как волшебство, но лежащие в его основе правила на самом деле просты.
Так что такое алгоритм коллапса волновой функции (Wave Function Collapse, WFC)? Его разработал Максим Гумин для создания «плиточных» изображений на основе простой конфигурации или образцов изображений. Алгоритм умеет многое: полистайте приведённые Максимом примеры и Твиттер #wavefunctioncollapse, посмотрите это видео. Разнообразие потрясает.
Your browser does not support HTML5 video.
Максим в README вкратце объяснил работу WFC, но мне кажется, что этот вопрос требует более подробного раскрытия, с самых основ. Поскольку алгоритм имеет отношение к программированию в ограничениях, то большая часть статьи посвящена объяснению концепции программирования в ограничениях, а в конце мы вернёмся к WFC.
Программирование в ограничениях — это способ инструктирования компьютеров. В отличие от императивного программирования, когда вы задаёте список явных функций, или функционального программирования, когда вы задаёте математические функции, здесь вы предоставляете компьютеру строгое описание задачи, а он с помощью встроенных алгоритмов ищет решение.
Примечание: в этом руководстве описываются различные концепции, а не методы и код. Если вас больше интересует реализация, то можете воспользоваться моей opensource-библиотекой WFC (github, документация). Хотя начать изучение лучше с реализации Максима. Если вы используете Unity, то можете купить Tessera, это мой инструмент для применения WFC в этом движке.
Мини-судоку
В качестве иллюстративной задачи я взял мини-Судоку. Это головоломка, которая выглядит как сетка 4×4, в некоторые клетки которой вписаны числа.

Цель — заполнить каждую пустую клетку числом от 1 до 4 в соответствии с правилами:
- Каждое число от 1 до 4 должно присутствовать в каждом ряду в единственном экземпляре.
- Каждое число от 1 до 4 должно присутствовать в каждой колонке в единственном экземпляре.
- Каждое число от 1 до 4 должно присутствовать в каждом угловом квадрате 2×2 в единственном экземпляре.
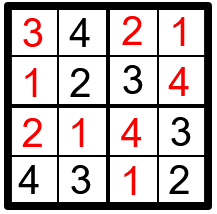
Согласно этим правилам решение будет таким:

Возможно, вы с лёгкостью решили эту головоломку. Но нас интересует, как это может сделать компьютер. Задачу можно разделить на две части: описание условий для компьютера, а затем решение с помощью алгоритма.
Описание условий
Обычно для этого используется язык программирования в ограничениях. Таких языков несколько, и принципы действия у них схожи.
Сначала определим переменные. Здесь они не такие, как в обычном программировании. В контексте решателя задач удовлетворения ограничений переменная является неизвестным значением, которое нужно решить для решения задачи. В нашем примере с судоку мы создадим переменные для всех пустых клеток. Ради удобства также можно создать переменные и для заполненных клеток.
Затем для каждой переменной определим домен: набор возможных значений. В нашем судоку для каждой пустой клетки доменом будет {1, 2, 3, 4}. А для клетки, в которой уже вписана 1, доменом будет {1}.
Наконец, зададим ограничения: правила, связывающие наши переменные. В большинстве языков программирования в ограничениях уже есть функция all_distinct(..), которой требуется передавать уникальные значения. Так что правила судоку можно перевести в 12 ограничений all_distinct — по одному на каждый ряд и столбец, а также на угловые квадраты 2×2. Нам нужен лишь один вид ограничений для решения этой задачи, однако решатели задач удовлетворения ограничений, обычно поставляются с большой библиотекой разных видов ограничений для описания вашей задачи.
Примечание: на практике языки программирования в ограничениях поддерживают массивы, поэтому есть более аккуратные способы формулирования этой задачи. В сети есть много статей про решение судоку.
Алгоритмы решения задач удовлетворения ограничений
Есть несколько различных методик решения. Но я рассмотрю простейшую из них, чтобы продемонстрировать вам принцип их работы. Здесь показаны домены для каждой клетки:
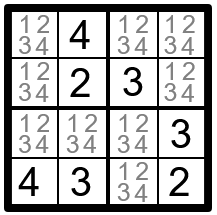
Это все возможные значения в доменах переменных.
Теперь возьмём первое ограничение. Оно требует, чтобы все значения в верхнем ряду были уникальными. В одной клетке уже вписано значение 4, поэтому в других клетках ряда этого значения быть не может. Удалим его из доменов этих клеток.
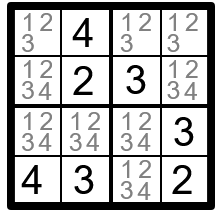
Повторим эту процедуру со всеми 12 ограничениями. Этот называется распространением ограничений, потому что информация распространяется от переменной к другой через ограничения.

И глянь-ка, у нас появились переменные, в доменах которых осталось по одному значению. Это должны быть корректные решения для этих переменных.
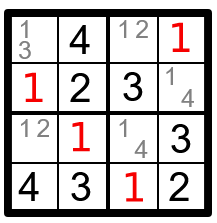
Похоже, мы можем извлечь из распространения ограничений ещё больше пользы: новые красные единицы говорят о том, что у нас будет ещё больше переменных с одиночным доменом, и это тоже будет способствовать распространению. Повторяем процедуру до тех пор, пока головоломка не будет решена.
Усложняем задачу
К сожалению, не все логические головоломки можно решить так быстро. Вот большая судоку, она работает так же, за исключением того, что теперь у нас 9 разных значений, 9 рядов, 9 столбцов и 9 квадратов размером 3×3.

Если мы попробуем применить вышеописанную методику, то застрянем:

Сейчас все ограничения распространены, однако ещё остались неопределённые переменные.
Человек это решит, а компьютерный алгоритм не сможет. В руководствах для людей говорится, что теперь нужно искать всё более усложняющиеся логические выводы. Но нам не нужно, чтобы компьютерный алгоритм этим занимался, потому что это сложно, а нам нужен универсальный алгоритм, который сможет работать с любым набором ограничений, а не только по правилам судоку.
Поэтому компьютеры поступают самым глупым образом: они предполагают. Сначала мы записываем текущее состояние головоломки. Затем выбираем произвольную переменную и задаём ей одно из возможных значений. Скажем, центральной клетке присвоим значение 1.
Теперь мы можем ещё немного распространить ограничения. Вот что у меня получилось для центрального столбца:

Синие значения — это выводы, которые мы сделали после предположения. Как видите, кое-что произошло. Мы проставили ещё несколько переменных, но взгляните на среднюю верхнюю клетку. Она пуста: в её домене нет возможных значений, удовлетворяющих ограничениям (здесь не может быть 5, потому что это значение уже есть в том же квадрате 3×3, а все другие числа уже есть в этом столбце).
Если мы получаем переменную с пустым доменом, это означает, что мы не можем присвоить ей какое-либо значение. То есть головоломку не решить. Получается, наше предположение было ошибочным.
Столкнувшись с таким противоречием, мы выполняем процедуру перебора с возвратом (backtracking). Сначала восстанавливаем состояние, которое было перед нашим предположением. Затем удаляем из домена значение, которое мы использовали в качестве предположения — оно уже не может быть правильным ответом.
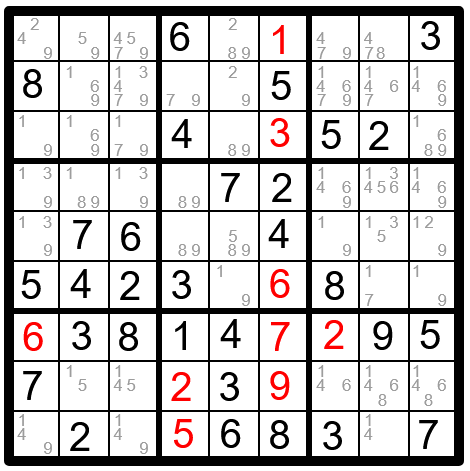
Работы проделали много, но зато продвинулись вперёд. Впрочем, даже после исключения 1 из центральной клетки мы всё ещё стоим на мёртвой точке. Пора опять делать предположение, и опять, и опять.
Здесь не так уж много алгоритмических действий. Каждый раз, когда мы не можем распространять ограничения, мы делаем предположение и движемся дальше. И поскольку вы можете застрять несколько раз, прежде чем столкнётесь с противоречием, то у вас накопится несколько сохранённых состояний и предположений.
При каждом переборе с возвратом вы уменьшаете домен как минимум на одну переменную, так что, несмотря на многочисленные откаты назад, алгоритм в конце концов завершит работу.
Эта тема гораздо обширнее, чем я описываю. На практике огромное влияние на исполнение программы могут оказывать такие оптимизации, как выбор предположений, понимание, когда нужно распространять, а также когда делать более сложные логические выводы. И поскольку задачи с ограничениями, как правило, растут экспоненциально, то получить ответ можно завтра, а можно и через 5000 лет.
Возвращаемся к коллапсу волновой функции
Коллапс волновой функции — это хитрая задача с ограничением: существуют тысячи возможных решений. Если делать предположения случайным образом, то вместо решателя мы получаем генератор. При этом он всё равно будет соответствовать всем заданным ограничениям, то есть будет гораздо более управляемым, чем большинство других процедурных генераторов.
Задачей алгоритма WFC является заполнение клеток плитками таким образом, чтобы изображения на плитках сочетались друг с другом. В рамках использованной выше терминологии каждая плитка является значением, каждая клетка — переменной, а правила размещения плиток — ограничениями.
Максим, автор WFC, обнаружил, что при разумном выборе плиток и целесообразной рандомизации редко приходится использовать перебор с возвратом, так что эту процедуру можно не реализовывать. Таким образом, суть WFC заключается в следующем:
- Для каждой клетки создаётся булев массив, который представляет собой домен этой переменной. В доменах содержится по одной записи на каждую плитку, и все они инициализируются со значением
true. Плитка попадает в домен, если её значение равноtrue. - При этом есть клетки, у которых домены содержат несколько элементов:
- Выбор случайной клетки с помощью эвристического метода «наименьшей энтропии».
- Выбор случайной плитки из домена клетки и удаление оттуда всех остальных плиток.
- Обновление доменов других клеток на основе этой новой информации — распространение ограничения по клеткам. Это нужно делать многократно, поскольку изменения в клетках могут иметь дальнейшие последствия.
Примечание: мои термины отличаются от терминов Максима. Он называет массив доменов волной, а выбор случайной плитки — наблюдением. То есть проводится аналогия с квантовой механикой. Но сравнение поверхностное, поэтому будем его игнорировать.
Есть много дополнений к вышеприведённым принципам, добавляющие алгоритму изящества и производительности. Но давайте сначала рассмотрим описанные этапы.
Пример
Допустим, нам нужно заполнить сетку 3 на 3 плитками четырёх видов:

Ограничения такие: цвета смежных плиток должны соответствовать друг другу.
Как и в примере с судоку, я буду иллюстрировать содержимое доменов с помощью монохромных картинок. Когда в домене остаётся только один элемент, я увеличу его в размерах и покажу в цвете.
Сначала у нас в каждой клетке может располагаться плитка любого вида:

Выполним основной цикл WFC. Случайным образом выберем клетку, например, верхнюю левую. Теперь выберем в домене плитку и удалим все остальные.

Распространим ограничения. Единственное правило относится к смежным плиткам, так что нам нужно обновить две клетки:

Можем ли мы обновить другие плитки, учитывая уменьшившиеся домены? Да! Хотя мы и не уверены насчёт выбора первой плитки, но мы видим, что оставшиеся варианты ведут вправо. То есть некоторые виды плиток нельзя положить в правом верхнем углу. То же самое и с нижним левым углом.

Больше мы не можем распространить ограничения, поэтому повторим основной цикл: выбор клетки, выбор плитки и распространение. На этот раз возьмём верхнюю среднюю клетку:

Ещё один цикл: возьмём левую среднюю клетку. После распространения ограничений для центральной клетки осталось одно возможное значение.
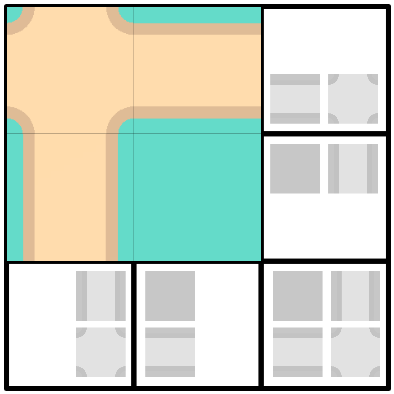
В общем, вы поняли идею. Можете сами заполнить остальные клетки.
Если хотите поэкспериментировать с более сложным интерактивным примером, то рекомендую этот.
Наименьшая энтропия
При выборе следующей клетки для заполнения некоторые варианты будут предпочтительнее. Если случайным образом выбирать из любого места сетки, то может возникнуть ситуация, когда одновременно у вас будут заполнены разные области сетки. Это может повлечь проблемы: в зависимости от доступных плиток заполненные области не удастся соединить. Так что лучше выбирать клетки, которые в дальнейшем с меньшей вероятностью приведут к таким проблемам. Иными словами, нужно брать клетки с наименьшим количеством возможных значений в домене (но не меньше двух значений):
- Вероятнее всего, они будут рядом с уже заполненными клетками.
- Если мы оставим их на будущее, то могут возникнуть трудности, потому что доступных значений уже мало.
Подход с наименьшим доменом хорошо работает в том случае, если все плитки одинаково вероятны. Но если выбираешь из взвешенного случайного распределения, то нужно учитывать кое-что другое. Максима рекомендует «минимальную энтропию», то есть выбирать клетку, которая минимизирует:

Это суммирование плиток в домене, где  — вероятность для данной плитки.
— вероятность для данной плитки.
Эффективное вычисление
Хотя я не хочу вдаваться в детали, однако есть две оптимизации, позволяют так сильно повысить скорость, что о них нельзя не упомянуть.
Поскольку единственное наше правило связано со смежными плитками, мы можем проверять только те ограничения, которые могут дать результаты, отличающиеся от предыдущих. То есть при обновлении клетки мы добавляем её в очередь клеток, ожидающих решения. Затем удаляем из очереди по одной клетке, каждый раз проверяя её смежные клетки. Если такие проверки приведут к обновлению других клеток, они тоже попадают в очередь. Повторяя эту процедуру до тех пор, пока очередь не опустеет, мы убеждаемся, что проверили все ограничения. Но мы не проверяем их до тех пор, пока меняется домен хотя бы у одной клетки, связанной с этими ограничениями.
Далее, чтобы проверить ограничение по смежности, нам нужно ответить на вопрос: «Учитывая плитки в домене клетки А, какие возможны плитки в домене клетки Б, если клетки являются смежными?».
Иногда этот вопрос называют «поддержкой» клетки А. Для заданной плитки «б» в домене Б легко вычислить циклы для плиток в домене А. Если в А есть хотя бы одна плитка, которую можно положить рядом с «б», значит «б» всё ещё подходит, как минимум для рассматриваемой пары плиток. Если же в А такой плитки нет, то нельзя положить плитку «б» из домена Б, и мы можем её отбросить.
Циклы позволяют легко реализовать это в коде, но работать будет крайне медленно. А если мы будем сохранять информацию в дополнительной структуре данных, то сможем быстро отвечать на вопрос по мере необходимости. Новые данные представляют собой большой массив с записями для каждой стороны каждой клетки и каждой плитки. В нашем примере 9 клеток, у каждой 4 стороны, и 4 вида плиток. Значит, нам нужно 9×4 * 4 записей. В массиве мы будем сохранять счётчики поддержки: для каждой клетки/плитки/стороны считаем количество плиток в домене смежной клетки, которые можно положить рядом с рассматриваемой плиткой. Если счётчик падает до нуля, то эту плитку нельзя положить, ведь с ней никто не может быть смежен.
Расширения алгоритма
Поскольку WFC основан на более общем понимании решения задач с ограничениями, существует много способов расширения алгоритма за счёт изменений используемых ограничений.
Одно из очевидных изменений заключается в том, что никто не заставляет нас использовать квадратные клетки. WFC прекрасно работает на шестиугольных клетках, в трёх измерениях или ещё более необычных поверхностях.


Можно ввести дополнительные ограничения: фиксировать определённые плитки, или создавать «модули» из нескольких клеток.
Введение дополнительных ограничений может играть очень важную роль с практической точки зрения. Поскольку WFC ограничивает лишь соседние плитки, он редко генерирует большие структуры, обеспечивающие высокий уровень гомогенности и необычно выглядящие. Лучше всего этот алгоритм работает при выборе плиток, но для работы с какими-то крупными структурами лучше применять другую методику или вводить иные ограничения.
В другой своей статье я рассказал, как можно добиться от WFC наилучшего результата.
Перекрывающийся WFC
Одним из интересных расширений алгоритма является «перекрывающийся» WFC. В приведённых выше примерах главное ограничение относилось к парам смежных плиток. Этого достаточно, чтобы обеспечивать соединение линий и создавать простые структуры вроде пещер, комнат и т. д. Но при этом теряется много информации. Если нам нужно, скажем, чтобы красные плитки всегда располагались рядом с синими, но никогда не были смежными с ними, то это будет трудно выразить с точки зрения одной лишь смежности.
Максим предложил концепцию перекрывающегося WFC: мы заменяем ограничение по смежности новым ограничением, которое влияет сразу на несколько плиток. Например, чтобы на выходе каждая группа клеток 3×3 соответствовала группе 3×3 из образца сетки. Паттерны, присутствующие в образце, будут раз за разом повторяться в разных вариациях на выходе:
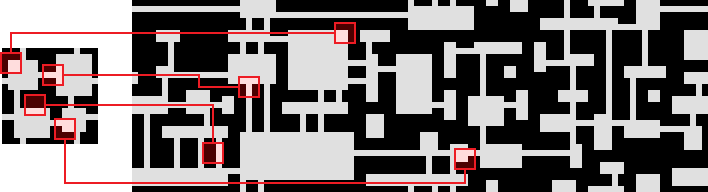
Это ограничение гораздо чувствительнее «простых» ограничений по смежности. А поскольку оно зависит от заданного образца, то очень подходит для решения каких-то художественных задач. До сих пор мне не попадалось ничего столь же интересного. Возможно, причина в том, что такой алгоритм труднее реализовать, или он медленнее работает, или иногда слишком хорошо воспроизводит исходный образец, из-за чего теряется некая натуральность, естественность.
Что дальше?
Решение задач с ограничениями — это большая и активно развивающаяся сфера информатики, и я лишь затронул её. WFC — как и любой другой алгоритм процедурного генерирования для решения задач с ограничениями, — пока ещё в новинку. Рекомендую почитать r/proceduralgeneration, #wavefunctioncollapse, @exutumno и @osksta, чтобы получить представление о свежих примерах использования.
Также можете почитать мою статью про WFC, поэкспериментировать с моей opensource-библиотекой или Unity-инструментом. Не забудьте и про другие мои статьи о процедурном генерировании.
