[Перевод] Расследуем фантомные чтения с диска в Linux
Не так давно один из наших пользователей сообщил нам о случае странного использования оборудования. Он при помощи с нашего клиента ILP (InfluxDB Line Protocol) вставлял строки в свою базу данных QuestDB, но вместе с операциями записи на диск также наблюдались существенные объёмы чтения с диска. Этого никак не ожидаешь от нагрузки, рассчитанной только на запись, поэтому нам нужно было докопаться до причины этой проблемы. Сегодня мы поделимся этой историей, полной взлётов и падений, а также магии ядра Linux.

▍ Проблема: неожиданные операции записи
Как вы, возможно, уже знаете, QuestDB имеет столбчатый формат хранения данных только для добавления (append-only). На практике это значит, что когда база данных записывает новую строку, она добавляет значения его столбца во множество файлов столбцов.
Это обеспечивает высокий уровень записи на диск из-за паттерна последовательной записи. При обработке нагрузки только с записью на диск от базы данных не ждёшь, что она будет много читать с диска. Именно поэтому такая проблема стала для нас сюрпризом.
Сделав несколько попыток, мы смогли воссоздать проблему. Симптомы выглядели как вот этот вывод iostat:
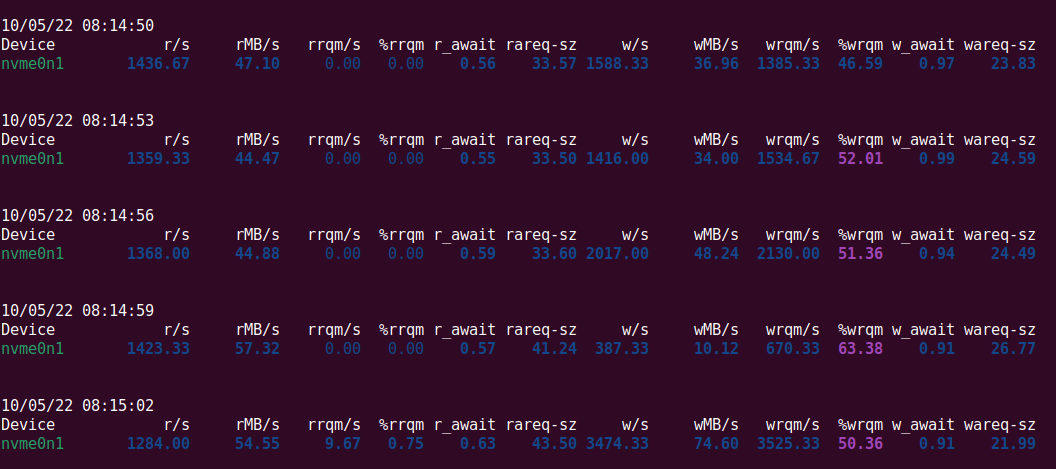
Здесь мы видим 10–70 МБ/с записей на диск, в то время как чтение составляет аж целых 40–50 МБ/с. В ситуациях, когда выполняется только запись данных, использование операций чтения должно быть близко к нулю. Поэтому высокий объём чтения очень неожидан.
▍ Используем утилиты Linux для расследования
Первым делом мы хотели понять, какие конкретно файлы считывала база данных. К счастью, в Linux нет ничего невозможного. Для сбора информации обо всех операциях чтения выбранного диска можно использовать утилиту blktrace в сочетании с blkparse:
sudo blktrace -d /dev/nvme0n1 -a read -o - | blkparse -i -
Показанная выше команда выводит все события чтения диска в системе. Её вывод выглядит примерно так:
259,0 7 4618 5.943408644 425548 Q RA 536514808 + 8 [questdb-ilpwrit]
259,0 7 4619 5.943408967 425548 G RA 536514808 + 8 [questdb-ilpwrit]
259,0 7 4620 5.943409085 425548 P N [questdb-ilpwrit]
259,0 7 4621 5.943410717 425548 A RA 536514832 + 8 <- (259,7) 6699280
259,0 7 4622 5.943410836 425548 Q RA 536514832 + 8 [questdb-ilpwrit]
259,0 7 4623 5.943411176 425548 G RA 536514832 + 8 [questdb-ilpwrit]
259,0 7 4624 5.943411707 425548 UT N [questdb-ilpwrit] 2
259,0 7 4625 5.943411781 425548 I RA 536514832 + 8 [questdb-ilpwrit]
259,0 7 4626 5.943411865 425548 I RA 536514808 + 8 [questdb-ilpwrit]
259,0 7 4627 5.943414234 264 D RA 536514832 + 8 [kworker/7:1H]
259,0 7 4628 5.943414565 264 D RA 536514808 + 8 [kworker/7:1H]
259,0 7 4629 5.943472169 425550 C RA 536514808 + 8 [0]
259,0 7 4630 5.943473856 425550 C RA 536514832 + 8 [0]
... и множество других событий
Каждая строка здесь обозначает отдельное событие. Для простоты рассмотрим первую строку:
259,0 7 4618 5.943408644 425548 Q RA 536514808 + 8 [questdb-ilpwrit]
Нам важны следующие её части:
- 425548 — это событие было сгенерировано с pid 425548.
- Q RA — это событие соответствует запросу чтения с диска, добавленного в очередь ввода-вывода. Суффикс «A» плохо задокументирован, но известно, что он обозначает потенциальную операцию упреждающего чтения (readahead). Что такое «упреждающее чтение», мы узнаем чуть позже.
- 536514808 + 8 — эта операция чтения начинается с блока 536514808 и имеет размер 8 блоков.
- [questdb-ilpwrit] — операция была запущена потоком ILP writer базы данных QuestDB.
Вооружённые этим знанием, мы можем использовать debugfs, чтобы проследовать по номеру блока и найти соответствующий inode:
$ sudo debugfs -R 'icheck 536514808' /dev/nvme0n1
debugfs 1.46.5 (30-Dec-2021)
Block Inode number
536514808 8270377
Наконец, мы можем проверить, что обозначает inode 8270377:
$ sudo debugfs -R 'ncheck 8270377' /dev/nvme0n1
debugfs 1.46.5 (30-Dec-2021)
Inode Pathname
8270377 /home/ubuntu/.questdb/db/table_name/2022-10-04/symbol_col9.d.1092
Эти шаги необходимо выполнять для каждого события чтения, однако можно легко написать скрипт для их автоматизации. Изучив события, мы обнаружили, что чтения с диска соответствуют файлам столбцов. Итак, хотя база данных записывает эти файлы только с добавлением (append-only), каким-то образом возникают операции чтения с диска.
Ещё один интересный факт заключается в том, что у пользователя довольно много таблиц (примерно пятьдесят), и в каждой хранится несколько сотен столбцов. Поэтому базе данных приходится иметь дело со множеством файлов столбцов. Мы были уверены, что наш код ILP должен был только записывать в эти файлы, но не читать из них.
Кто же может читать эти файлы? Может быть, операционная система?
▍ На сцене появляется ядро Linux
Как и многие другие базы данных, для работы с дисковыми операциями QuestDB использует буферизованный ввод-вывод, например, mmap, read и write. Это значит, что когда мы записываем что-то в файл, ядро записывает модифицированные данные в несколько страниц в страничном кэше и помечает их как «грязные».
Страничный кэш — это особый прозрачный кэш в памяти, используемый Linux для хранения недавно считанных с диска данных и недавно модифицированных данных, которые должны быть записаны на диск. Кэшированные данные упорядочены в страницы, в большинстве дистрибутивов и архитектур CPU имеющие размер 4 КБ.
Кроме того, невозможно ограничить количество ОЗУ для страничного кэша, поскольку ядро пытается использовать под него всю доступную ОЗУ. Старые страницы удаляются из страничного кэша, чтобы приложения или операционная система могли распределять новые страницы. В большинстве случаев это происходит прозрачно для приложения.
При стандартном значении cairo.commit.mode QuestDB не выполняет явных вызовов fsync/msync для сброса файлов столбцов на диск, поэтому сбросом целиком занимается ядро. Значит, нам следует лучше разобраться в том, чего ожидать от ядра, прежде чем гипотетически рассуждать о нашей ситуации с «фантомными чтениями».
Как мы уже знаем, операционная система не записывает модификации файловых данных на диск сразу же. Вместо этого она записывает их в страничный кэш. Это называется стратегией кэширования с отложенной записью (write-back caching). Отложенная запись подразумевает, что за запись «грязных» страниц на диск отвечает фоновый процесс. В Linux этим занимается pdflush — множество потоков ядра, отвечающих за отложенную запись «грязных» страниц.
pdflush имеет множество параметров для конфигурирования. Вот самые важные:
dirty_background_ratio— если процент «грязных» страниц меньше этого параметра, «грязные» страницы остаются в памяти, пока не устареют. Когда количество «грязных» страниц превосходит этот параметр, то ядро проактивно запускаетpdflush. В Ubuntu и других дистрибутивах Linux этот параметр по умолчанию равен10(10%).dirty_ratio— когда процент «грязных» страниц превосходит этот параметр, операции записи перестают быть асинхронными. Это значит, что выполняющий запись процесс (в нашем случае процесс базы данных) будет записывать страницы на диск синхронно. Когда такое происходит, соответствующий поток помещается в состояние «непрерываемого сна» (код состоянияDв утилитеtop). По умолчанию этот параметр имеет значение20(20%).dirty_expire_centisecs— этот параметр определяет время в сантисекундах, после которого они становятся слишком старыми для отложенной записи. Обычно по умолчанию этот параметр имеет значение3000(30 секунд).dirty_writeback_centisecs— определяет интервал пробуждения процесса pdflush. Обычно по умолчанию этот параметр имеет значение500(5 секунд).
Текущие значения приведённых выше параметров можно проверить через виртуальную файловую систему /proc:
$ cat /proc/sys/vm/dirty_background_ratio
10
$ cat /proc/sys/vm/dirty_ratio
20
$ cat /proc/sys/vm/dirty_expire_centisecs
3000
$ cat /proc/sys/vm/dirty_writeback_centisecs
500
Также важно упомянуть, что приведённые выше проценты вычисляются на основе общей восстанавливаемой памяти, а не общей доступной на машине ОЗУ. Если ваше приложение не создаёт множество «грязных» страниц, а объём ОЗУ большой, все операции записи на диск выполняются pdflush асинхронно.
Однако если количество доступной для страничного кэша памяти мало, то pdflush будет чаще всего записывать данные, с высоким шансом того, что приложение будет переведено в состояние «непрерываемого сна» и блокировано для записей.
Настройка этих параметров не особо нам помогла. Вы ведь помните, что пользователь выполняет запись в большое количество столбцов? Это значит, что для обработки внеочередных записей (out-of-order, O3) базе данных нужно распределять память для каждого столбца, что оставляет меньше памяти для страничного кэша. Мы в первую очередь проверили это: и в самом деле, основная часть ОЗУ использовалась процессом базы данных. Изменение параметра cairo.o3.column.memory.size со стандартных 16 МБ до 256 КБ помогло существенно снизить частоту чтения с диска, то есть проблема как-то была связана с давлением на память. Не волнуйтесь, если не поймёте этот абзац полностью. Самое важное заключается в следующем: снижение используемой базой данных памяти снизило объём операций записи. Это полезная подсказка.
Но в чём же была причина чтения с диска?
Чтобы ответить на этот вопрос, нам нужно лучше понять аспект чтения с диска страничного кэша. Чтобы не усложнять, мы рассмотрим ввод-вывод на основе mmap. Как только вы выполняете mmap для файла, ядро распределяет записи таблицы страниц (PTE) для виртуальной памяти, чтобы зарезервировать диапазон адресов для этого файла, но пока не читает содержимое файла. Сами данные считываются на страницу, когда вы выполняете доступ к распределённой памяти, то есть начинаете чтение (команда LOAD в наборе x86) или запись (команда STORE в наборе x86) в память.
Когда это происходит впервые, блок управления памятью (memory management unit, MMU) вашего CPU сигнализирует специальное событие под названием «page fault». Page fault означает, что память, к которой выполняется доступ, принадлежит к PTE, у которой не распределено физической памяти. Ядро обрабатывает page fault двумя способами:
- Если страничный кэш уже содержит данные соответствующего файла в памяти, например, принадлежащие тому же файлу, открытому другим процессом, то ядро просто обновляет PTE, чтобы выполнить отображение на существующую страницу. Это называется minor page fault.
- Если данные файла ещё не кэшированы, ядро должно заблокировать приложение, считать страницу, и только потом обновить PTE. Это называется major page fault.
Как можно догадаться, major page fault гораздо затратнее, чем minor page fault, поэтому Linux стремится минимизировать их количество при помощи оптимизации под названием readahead («упреждающее чтение»; иногда её также называют «fault-ahead» или «pre-fault»).
На концептуальном уровне упреждающее чтение отвечает за считывание данных, которые приложение запрашивало явным образом. При первом доступе (для чтения или записи) к нескольким байтам только что открытого файла происходит major page fault, и операционная система считывает данные, соответствующие запрошенной странице плюс множество страниц до и после файла. Это называется «read-around». Если продолжить выполнять доступ к последующим страницам файла, ядро распознаёт паттерн последовательного доступа и начинает упреждающее чтение, пытаясь заранее считать группу последующих страниц.
Благодаря этому, Linux пытается выполнить оптимизацию под паттерны последовательного доступа, а также увеличить шансы попадания в уже кэшированную страницу в случае произвольного доступа.
Помните событие чтения с диска из вывода blktrace? Суффикс «A» в типе операции «RA» означает, что чтение с диска было частью упреждающего чтения. Однако мы знаем, что нагрузка заключалась только в чтении, работающем с большим количеством файлов. Проблема гораздо заметнее, когда для задач страничного кэша остаётся не так много памяти.
Что, если страницы удаляются из страничного кэша слишком рано, что приводит к избыточному объёму упреждающего чтения при последующем доступе к памяти?
Мы можем проверить эту гипотезу, отключив упреждающее чтение. Для этого достаточно выполнить системный вызов madvise с флагом MADV_RANDOM. Это сообщает ядру, что приложение будет выполнять доступ к подвергнутому mmap файлу произвольным образом, то есть для этого файла упреждающее значение должно отключиться.
И проблема решилась! Больше не было никаких «фантомных чтений»:
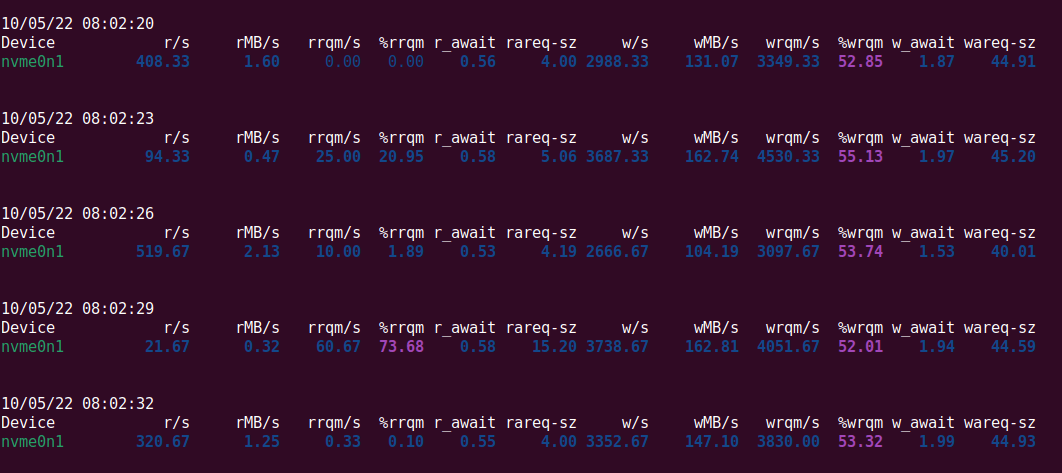
▍ Счастливый конец
В результате мы выявили неоптимальное поведение упреждающего чтения ядра. Потребление большого количества файлов столбцов при высоком давлении на память приводило к тому, что ядро начинало операции упреждающего чтения с диска, которых не ожидаешь от нагрузки только с записью. Дальше нам просто нужно было применитьmadvise в нашем коде для отключения упреждающего чтения в table writer.
В чём же мораль истории? Во-первых, мы не смогли бы устранить эту проблему, если бы не знали, как работает буферизированный ввод-вывод в Linux. Когда знаешь, чего ожидать от операционной системы и куда смотреть, то подбор и использование нужных утилит становится тривиальной задачей. Во-вторых, любые жалобы пользователей, даже те, что сложно воспроизвести, становятся возможностью узнать что-то новое и сделать QuestDB лучше.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх
