[Перевод] Рассказ о решении проблемы с производительностью Moment.js
Moment.js — это одна из самых популярных JavaScript-библиотек для разбора и форматирования дат. В компании WhereTo используют Node.js, поэтому для них применение этой библиотеки было совершенно естественным ходом. Проблем с серверным использованием Moment.js не ожидалось. В конце концов, они с самого начала использовали эту библиотеку во фронтенде для вывода дат и были довольны её работой. Однако то, что библиотека хорошо показала себя на клиенте, ещё не означало, что и на сервере с ней проблем не будет.

Материал, перевод которого мы публикуем сегодня, посвящён рассказу решении проблемы с производительностью Moment.js.
Рост проекта и падение производительности
Недавно число записей о самолётных рейсах, которые возвращает система WhereTo, выросло примерно в десять раз. Тогда мы столкнулись с очень сильным падением производительности. Оказалось, что цикл рендеринга, который занимал менее 100 миллисекунд, теперь, для вывода около 5000 результатов поиска, выполняется более 3 секунд. Наша команда занялась исследованиями. После нескольких сеансов профилирования мы заметили, что более 99% этого времени тратится в единственной функции, которая называется createInZone.
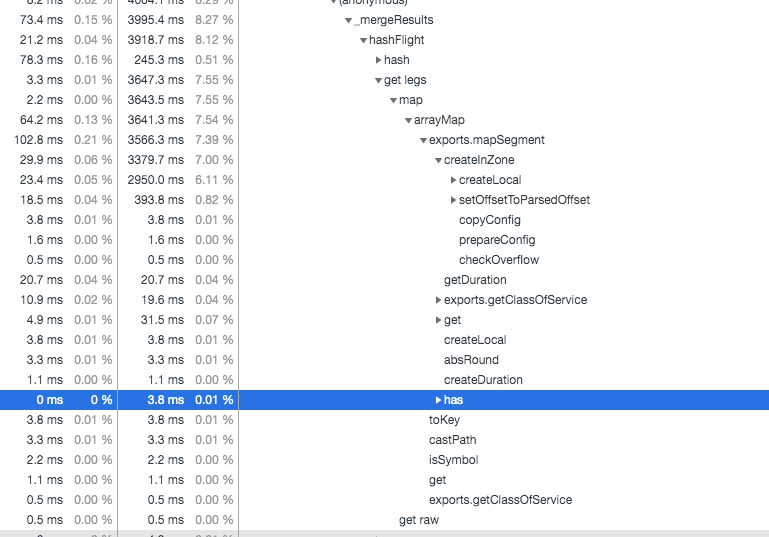
На выполнение функции createInZone приходится около 3.3 секунд
Продолжив исследование ситуации, мы обнаружили, что эта функция вызывается функцией Moment.js parseZone. Почему она такая медленная? У нас было такое ощущение, что библиотека Moment.js была создана в расчёте на распространённые сценарии её использования, и в результате она будет пытаться обработать входную строку различными способами. Может быть стоит ограничить её? После того, как мы вчитались в документацию, мы выяснили, что функция parseZone принимает необязательный аргумент, задающий формат даты:
moment.parseZone(input, [format])
Первым, что мы сделали, была попытка использовать функцию parseZone с передачей ей информации о формате даты, но это, как показали тесты производительности, ни к чему не привело:
$ node bench.js
moment#parseZone x 22,999 ops/sec ±7.57% (68 runs sampled)
moment#parseZone (with format) x 30,010 ops/sec ±8.09% (77 runs sampled)
Хотя теперь функция parseZone и работала немного быстрее, для наших нужд такой скорости было явно недостаточно.
Оптимизация с учётом особенностей проекта
Мы использовали Moment.js для парсинга дат, получаемых из API нашего провайдера (Travelport). Мы поняли, что он всегда возвращает данные в одном и том же формате:
"2019-12-03T14:05:00.000-07:00"
Зная это, мы начали разбираться во внутреннем устройстве Moment.js для того, чтобы (как мы надеялись) написать гораздо более эффективную функцию, выдающую те же результаты.
Создание более быстрой альтернативы parseZone
Для начала нам нужно было разобраться в том, как выглядят объекты Moment.js. Понять это было довольно просто:
> const m = moment()
> console.log(m)
Moment {
_isAMomentObject: true,
_i: '2019-12-03T14:05:00.000-07:00',
_f: 'YYYY-MM-DDTHH:mm:ss.SSSSZ',
_tzm: -420,
_isUTC: true,
_pf: { ...snip },
_locale: [object Locale],
_d: 2019-12-03T14:05:00.000Z,
_isValid: true,
_offset: -420
}
Следующим шагом было создание экземпляра Moment без использования конструктора:
export function parseTravelportTimestamp(input: string) {
const m = {}
// $FlowIgnore
m.__proto__ = moment.prototype
return m
}
Теперь возникало такое ощущение, что у нас имеется множество свойств экземпляра Moment, которые мы можем просто установить (я не вдаюсь в детали того, как мы об этом узнали, но если вы посмотрите исходный код Moment.js — вы это поймёте):
const FAKE = moment()
const TRAVELPORT_FORMAT = 'YYYY-MM-DDTHH:mm:ss.SSSSZ'
export function parseTravelportTimestamp(input: string) {
const m = {}
// $FlowIgnore
m.__proto__ = moment.prototype
const offset = 0 // TODO
const date = new Date(input.slice(0, 23))
m._isAMomentObject = true
m._i = input
m._f = TRAVELPORT_FORMAT
m._tzm = offset
m._isUTC = true
m._locale = FAKE._locale
m._d = date
m._isValid = true
m._offset = offset
return m
}
Последний шаг нашей работы заключался в том, чтобы выяснить то, как надо разбирать значение offset отметки времени. Оказалось, что это — всегда одна и та же позиция в строке. В результате мы смогли оптимизировать и это:
function parseTravelportDateOffset(input: string) {
const hrs = +input.slice(23, 26)
const mins = +input.slice(27, 29)
return hrs * 60 + (hrs < 0 ? -mins : mins)
}
Вот что получилось после того, как мы всё это собрали:
const FAKE = moment()
const TRAVELPORT_FORMAT = 'YYYY-MM-DDTHH:mm:ss.SSSSZ'
function parseTravelportDateOffset(input: string) {
const hrs = +input.slice(23, 26)
const mins = +input.slice(27, 29)
return hrs * 60 + (hrs < 0 ? -mins : mins)
}
/**
* Обрабатываются только даты формата ISO-8601, представленные в следующем виде:
* - "2019-12-03T12:30:00.000-07:00"
*/
export function parseTravelportTimestamp(input: string): moment {
const m = {}
// $FlowIgnore
m.__proto__ = moment.prototype
const offset = parseTravelportDateOffset(input)
const date = new Date(input.slice(0, 23))
m._isAMomentObject = true
m._i = input
m._f = TRAVELPORT_FORMAT
m._tzm = offset
m._isUTC = true
m._locale = FAKE._locale
m._d = date
m._isValid = true
m._offset = offset
return m
}Испытания производительности
Мы провели испытания производительности получившегося решения с использованием npm-модуля benchmark. Вот код бенчмарка:
const FAKE = moment()
const TRAVELPORT_FORMAT = 'YYYY-MM-DDTHH:mm:ss.SSSSZ'
function parseTravelportDateOffset(input: string) {
const hrs = +input.slice(23, 26)
const mins = +input.slice(27, 29)
return hrs * 60 + (hrs < 0 ? -mins : mins)
}
/**
* Обрабатываются только даты формата ISO-8601, представленные в следующем виде:
* - "2019-12-03T12:30:00.000-07:00"
*/
export function parseTravelportTimestamp(input: string): moment {
const m = {}
// $FlowIgnore
m.__proto__ = moment.prototype
const offset = parseTravelportDateOffset(input)
const date = new Date(input.slice(0, 23))
m._isAMomentObject = true
m._i = input
m._f = TRAVELPORT_FORMAT
m._tzm = offset
m._isUTC = true
m._locale = FAKE._locale
m._d = date
m._isValid = true
m._offset = offset
return m
}
Вот какие результаты исследования производительности у нас получились:
$ node fastMoment.bench.js
moment#parseZone x 21,063 ops/sec ±7.62% (73 runs sampled)
moment#parseZone (with format) x 24,620 ops/sec ±6.11% (71 runs sampled)
fast#parseTravelportTimestamp x 1,357,870 ops/sec ±5.24% (79 runs sampled)
Fastest is fast#parseTravelportTimestamp
Как оказалось, нам удалось ускорить разбор отметок времени примерно в 64 раза. Но как это повлияло на реальную работу системы? Вот что получилось в результате профилирования.
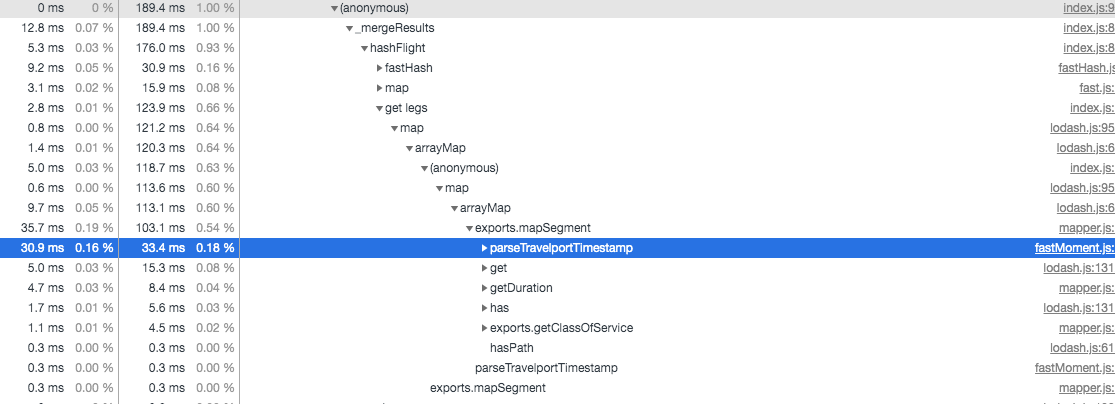
Общее время выполнения parseTravelportTimestamp составляет менее 40 мс.
Результаты оказались просто потрясающими: мы начинали с 3.3 секунд, уходящих на разбор дат, а пришли к менее чем 40 миллисекундам.
Итоги
Когда мы начинали работать над нашей платформой, нам предстояло решить просто страшное количество задач. Мы только и знали, что повторяли себе: «Пусть сначала заработает, а заняться оптимизацией можно и позже».
За последние несколько лет сложность нашего проекта очень сильно выросла. К счастью, теперь мы пришли туда, где можно переходить ко второй части нашей «мантры» — к оптимизации.
Библиотечные решения помогли проекту добраться до того места, где он находится в наши дни. Но мы столкнулись с «библиотечной» проблемой. Решая её, мы узнали о том, что, создав собственный механизм, ориентированный на наши нужды, мы можем сделать код «легче» в плане потребления системных ресурсов и сэкономить ценное время наших пользователей.
Уважаемые читатели! Сталкивались ли вы с проблемами, подобными той, о которой шла речь в этом материале?


